基于Grad-CAM的Mask-FGSM对抗样本攻击
2022-08-10余莉萍
余 莉 萍
(复旦大学计算机科学技术学院 上海 201203)
0 引 言
目前,基于深度学习算法的最新进展已经在很多任务上取得突破(例如图像分类[1]、自然语言处理[2]和语音处理[3]等领域)。但是,目前的方法通常以牺牲可解释性为代价来提升深度神经网络(DNN)模型的性能。如何直观地理解复杂的DNN的推理背后的依据具有挑战性,决策的可解释性是关键的先决条件,而简单的黑盒预测是不可信的。DNN的另一个缺点是其固有的易受对抗性,恶意制作的样本可触发目标DNN失效[4-6],这将造成不可预测的模型行为并阻碍其在对安全敏感的领域中使用。在诸如自动驾驶、医疗和金融决策等高风险领域,利用深度学习进行重大决策时,往往需要知晓算法所给出结果的依据。因此,透明化深度学习的“黑盒子”,使其具有可解释性,具有重要意义。
通过提供模型级别[7-9]或实例级别[10-13]的解释,这些方法的提出推动了DNN可解释性领域的深入研究。这种可解释性帮助用户理解DNN的内部工作原理,启用包括模型验证、模型诊断、辅助分析、知识发现等领域的应用。在本文中,引入可解释性工作Grad-CAM[14],利用Grad-CAM生成热力图观察输出类别和输入的内在关系,图1(a)所示为Grad-CAM的结果,原始输入分类结果为“68.7% goose”,热度越高的区域,表明该输入部分对于类别导向起到越关键的作用。本文定义该热力图为注意力视图,通过在注意力更加集中的地方引入噪声,可以更高效地生成对抗样本。如图1(b)所示,第一排为原始FGSM的对抗样本以及叠加的噪音,对抗并未成功并且需要扰动100%的输入。第二排为本文方法,仅仅需要扰动1.13%的像素便可达到攻击目的。实验验证了本文方法能够潜在地挖掘最佳攻击位置。实验证明,本文方法平均仅需扰动3.821%的输入特征就能达到攻击目的。

(a)
1 相关工作
1.1 可解释性工作
可解释性和辨别力是DNN的两个关键方面[15]。近年来,深度学习已经成功运用在计算机视觉、语音和自然语言处理等相关的特定领域。然而,这种“黑盒”模型在“端到端”的模式下,依赖数据驱动的工作机理,缺乏解释性。研究表明,深度学习的这种模式在数据集存在偏差的情况下依然能对“biased knowledge”进行编码,从而产生决策失误[9]。因此,通过可解释性的工作来可视化隐藏在卷积神经网络(CNN)内部的知识层具有重要意义。
近年来,出现了多种方法来探索CNN内部隐藏的语义[16-17]。已经提出了许多统计方法[18-20]来分析CNN功能的特征。CNN中滤波器的可视化[15]是探索隐藏在神经单元内部的模式的最直接方法。上卷积网络[21]将学习到的特征映射转化为图像。相比之下,基于梯度的可视化[13,22-23]生成能够使得给定单元最大化类别置信度的图像,这更接近于理解DNN的内部机制。Zintgraf等[24]通过可视化对DNN决策贡献最大的区域从而提供视觉解释性。CAM(Class Activation Mapping)[25]利用GAP(Global Average Pooling)的作用,保留空间信息的同时并且达到定位的目的,但是也正是由于GAP的限制,导致在一个新网络的结构上需重新训练模型,在实际应用中受限。Grad-CAM[14]和CAM的基本思路一致,区别在于获取每个特征图的权重时,采用梯度的全局平均来计算权重,该方法可以达到与CAM一样的可解释性效果,并且不受限于网络结构。
1.2 对抗样本生成
尽管深度学习在许多领域的任务中已经取得重大突破,但由于“黑盒”性质,很难确切知道它背后的决策依据,其在安全敏感任务中实际应用饱受质疑。恶意构造的对抗样本可以轻易让DNN决策产生偏差或错误[4-6]。攻击任务一般分为两类:黑盒攻击和白盒攻击。在黑盒攻击中,攻击者无法知悉模型的结构信息,只有模型的输入和输出信息[26]。Papernot等[27]利用模型蒸馏来拟合受攻击的黑盒模型的决策结果,从而完成从黑盒模型到代理模型的知识迁移,然后利用以后的攻击方法生成对抗样本对黑盒模型进行迁移攻击。Li等[26]在文本攻击任务中,通过观察去掉某个词前后模型决策结果的变化来定位文本中的重要单词,进而利用人类无法感知的噪音进行扰动直到达到攻击目标。白盒攻击是黑盒攻击的重要基础,在此类攻击中,攻击者可以知悉受攻击模型的结构参数等信息。Goodfello等[28]通过计算模型输入和输出的敏感性映射(FGSM),并朝着敏感方向添加噪声来生成对抗样本。Papernot等[29]基于雅可比图攻击(JSMA)选择最重要的特征进行攻击。
可解释性本身和攻击是一对攻防对象,可解释性为攻击者提供了对类别敏感的输入特征信息,而这一点正为进一步的研究提供攻击方向的关注焦点。本文提出一种基于Grad-CAM生成类别相关的热力图,在FGSM的基础上仅仅需要少量的噪声扰动就能达到高效的攻击。
2 基于Grad-CAM的对抗样本生成
2.1 Grad-CAM

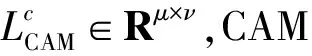
(1)
最后将其归一化到0-1从而达到可视化的目的。但是为了应用CAM需要将全连接层替换为卷积层,并重新训练网络,这是CAM的局限所在。
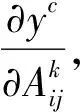
(2)

(3)
2.2 基于FGSM(快速梯度下降法)的噪音图生成
快速梯度下降法。在已知模型结构的情况下,通过求模型对输入的导数,利用符号函数得到具体的梯度方向,可以得到“扰动”后的输入从而得到FGSM攻击下的样本。设θ为模型参数,x为输入,y为对应的标签,训练损失为J(θ,x,y),那么叠加的噪音为:
(4)

2.3 基于Mask-FGSM的对抗样本生成
如图2所示,基于Grad-CAM可以得到对于输入图像扰动的方向,越是对于类别重要的特征,受到攻击越敏感,利用这样的结果本文算法可以对原图施以微弱的扰动,便可进行有效攻击。利用Grad-CAM得到输出样本的热力图,作为掩码Mask,与FGSM生成的噪音图进行叠加,得到最终的对抗样本:
x′=x+F(SGrad-CAM,Pth)·η
(5)
式中:Pth为施加在掩码上的阈值。
F(SGrad-CAM,Pth)的计算如式(6)所示。
(6)
式中:SGrad-CAM为利用Grad-CAM得到输出样本的热力图。

图2 对抗样本生成
2.4 评价指标
值得注意的是,控制对抗样本和原图的最大的L0距离,理论上给出任意距离下的对抗样本。
(7)
一般而言,L0距离越小,扰动越小。但是,本文在保证同一个L0距离下,生成更符合人类视觉感知的扰动,探寻潜在高效的攻击方向。
SSIM(Structural Similarity)结构相似性是一种全参考的图像质量评价指标,它分别从亮度、对比度和结构三方面度量图像相似性。SSIM取值范围为[0,1],值越大,表示图像失真越小。因此,本文引入图像的质量评价指标SSIM,计算式为:
(8)
式中:C1、C2是为了避免当分母为0时造成的不稳定问题引入的常数;μX、σX、μX*、σX*和σXX*分别是输入图像X的亮度均值、亮度标准差、对抗图像X*的亮度均值和亮度标准差,以及它们的相关系数。
(9)
原输入样本是X,目标网络输出是Y,F是网络在训练期间学习的函数,η是针对特征所做的扰动,τ是最大扰动L0距离,Pth是过滤掉热力图里过小的像素值。利用算法1产生对抗样本。
算法1对抗样本生成
输入:X,Y,F,τ,Pth。
1.X*←X;
3.S=GradCAM(F(X*),X*,Y);
4.η=FGSM(J(X*,Y));
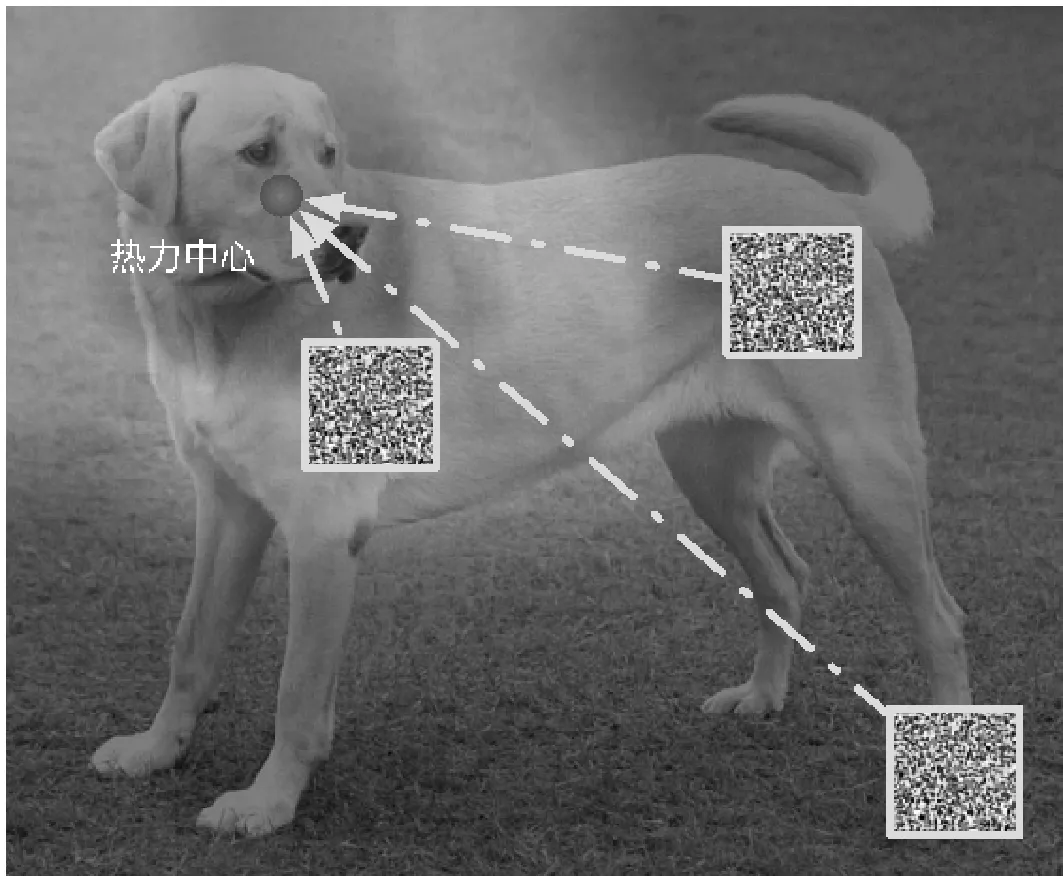
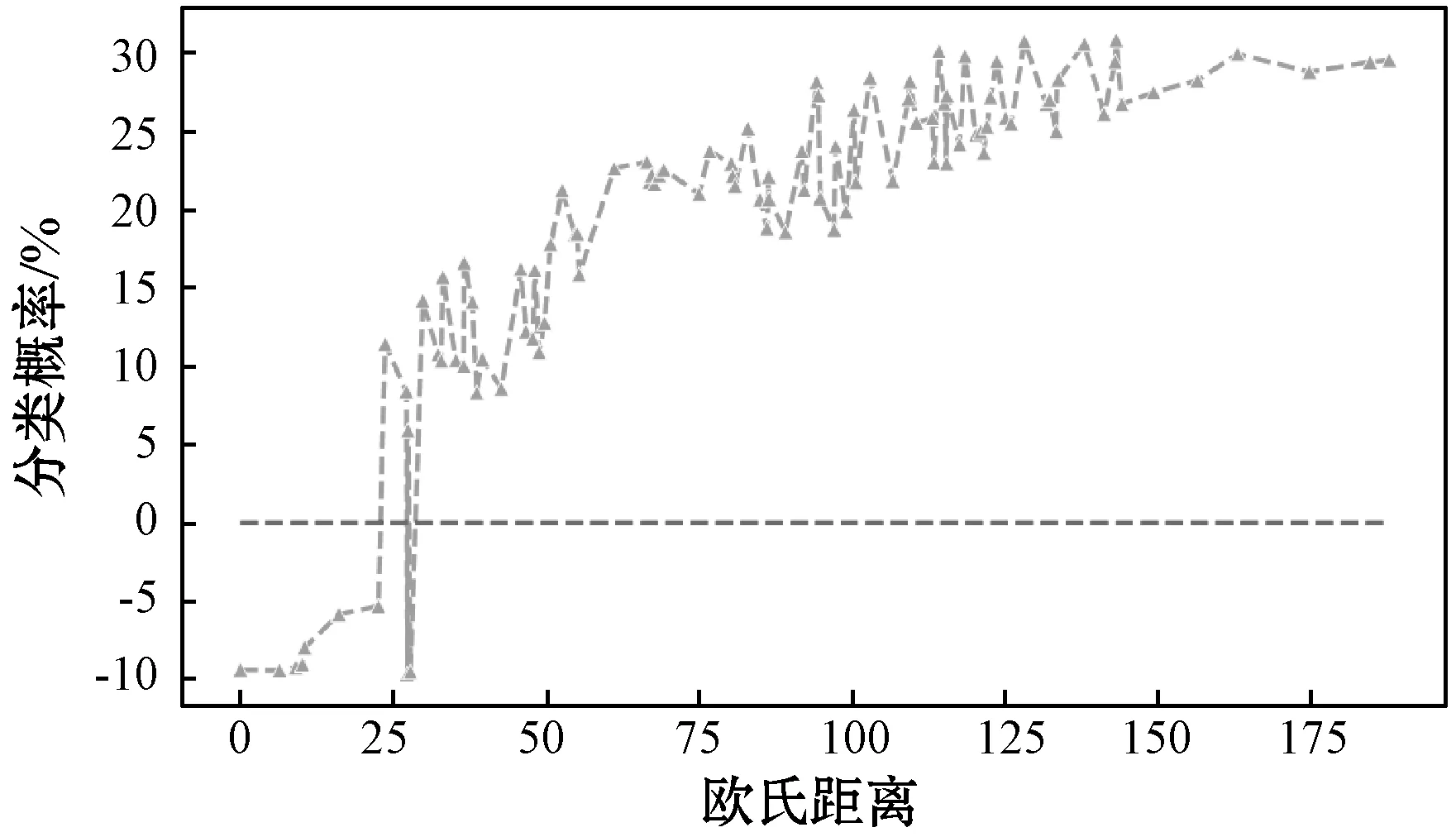
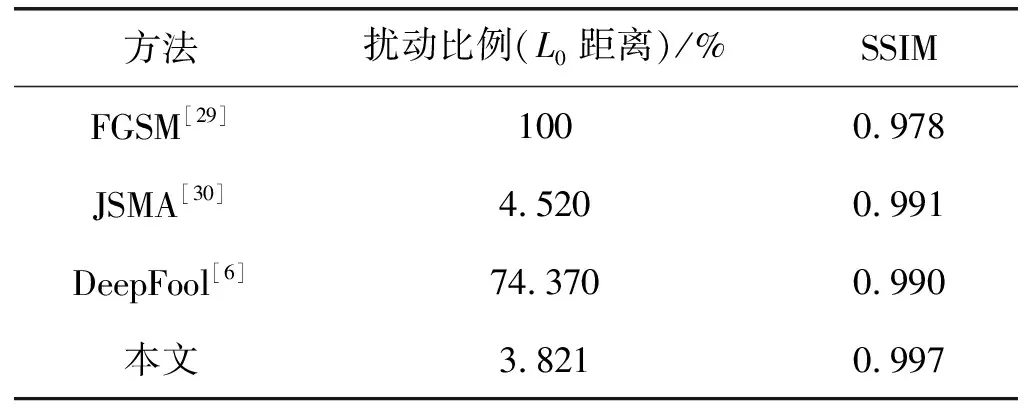
5.S[S 7.δX←X*-X; 8.endwhile 9.returnX* 以Densenet161作为模型结构,ImageNet作为训练集。实验采集了来自ILSVRC2014、网络图像等数据集一共1万幅图片作为测试集,来验证攻击效果。 为了验证本文方法的高效性,即验证Grad-CAM热力中心的攻击效果是否优于非热力中心。如图3所示,通过随机放置噪声块的位置,从而探究攻击位置与热力中心的关系。 图3 噪声块与热力中心的相对位置 通过实验验证,发现同样大小的一块噪声叠加在原图的攻击效果与距离热力中心的距离呈现图4所示关系,其中:虚线以上表示攻击不成功,虚线以下表示攻击成功。噪声块距离热力中心越近,则攻击效果越好, 表现为模型对于错误预测的类别的置信度的绝对值越高,噪声块距离热力中心越远,则攻击效果越差,表现为模型对于正确预测的类别的置信度的绝对值越高。因此,实验验证了本文方法的高效性和有效性,该方法能挖掘潜在高效的攻击方向。 图4 类别置信度与噪声块距离热力中心距离的关系 本文方法和原始FGSM[29]方法以及DeepFool[6]的生成对抗样本的实验对比如图5所示。从实验结果可以看出,本文方法仅仅需要扰动极为少量的输入便可以达到攻击目的。 图5 攻击效果对比(第一列:Grad-CAM结果以及原输入分类结果;第二列第三列:原始FGSM攻击结果以及叠加的噪声扰动;第四列第五列:DeepFool对抗结果以及叠加的噪声扰动;第六列第七列:本文的方法以及叠加的噪声扰动) 实验表明本文方法仅仅需要扰动极为少量的元素便可以达到攻击目的,表1给出了本文方法与FGSM以及目前典型的对抗样本攻击方法比较结果。可以看出,本文方法无论是在L0距离还是SSIM评价指标上均取得最佳效果。 表1 本文方法效果与经典方法对比 本文引入深度学习可解释性的模型Grad-CAM,针对深度神经网络(DNN)的结构并基于对DNN输入和输出之间映射的关系,结合FGSM方法,平均仅仅需要扰动3.821%的输入便可达到攻击目的。通过与目前已有的经典方法进行实验结果对比,充分验证了本文方法的高效性。本文结合了可解释性领域的成果,将其成功应用在对抗样本领域,实验结果表明本文方法效果显著,发掘了潜在的攻击方向,能够以更少的扰动成本达到攻击目的。此外,本文方法具有良好的普适性,可以进一步推广出更多的攻击思路,具有良好的应用前景。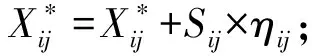
3 实验与结果分析
3.1 实验设置及数据集
3.2 验证攻击方向
3.3 攻击效果

4 结 语
