通用词向量模型在文本多目标分类中的性能比较
2022-08-10王德志梁俊艳
王德志 梁俊艳
1(华北科技学院计算机学院 河北 廊坊 065201) 2(华北科技学院图书馆 河北 廊坊 065201)
0 引 言
文本数据多目标分类中,神经网络模型一般是基于经典的多层感知器(Multilayer Perceptron,MLP)、卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Network, RNN)和长短期记忆网络(Long Short-Term Memory, LSTM)[1-2]。通过对这些网络进行修改和优化,构建各种不同应用领域的文本分析神经网络模型。所有的神经网络模型均需要对输入的文本数据进行预处理,把文本数据转换为向量数据然后进行处理。而在文本数据转换为向量的研究中,主要集中在词向量模型上[3]。谷歌公司基于词袋模型原理于2013年发布了Word2vec模型,它是将词表征为实数值向量的高效工具, 利用深度学习的思想,通过大量数据训练,把对应文本中词处理简化为K维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度[4-5]。2014年斯坦福大学学者提出了基于全局矩阵分解方法(Matrix Factorization)和局部文本框捕捉方法的GloVe模型,该模型利用了全局词共现矩阵中的非零数据来训练,而不是只用了某词的局部窗口信息。Facebook于2016年开源了基于CBOW模型原理的利用上下文来预测文本的类别的词向量与文本分类模型工具fastText,其典型应用场景是带监督的文本分类问题。fastText结合了自然语言处理和机器学习中最成功的理念,使用词袋、n-gram袋表征语句和子字信息,并通过隐藏表征在类别间共享信息,从而提升自然语言情感分类的准确性和速度[6]。ELMo模型是AllenNLP在2018年8月发布的一个上下文无关模型,其是一种双层双向的 LSTM 结构[7]。2018年10月,谷歌公司发布了基于所有层中的左、右语境进行联合调整来预训练深层双向表征的新语言表示模型BERT,其特点是可以更长的捕捉句子内词与词之间的关系,从而提升文本预测的准确性[8-9]。这些模型都实现了文本分词的向量化,从不同的角度对词语进行了量化。但是,这些通用词向量模型在相同的神经网络结构中能否体现出相同的性能,尚缺少对比分析。
1 通用词向量模型
1.1 Word2vec模型
Word2vec词向量可以基于连续词袋模型(CBOW)和跳字模型(skip-gram)获得。其中CBOW模型是基于上下文来预测当前的词,而skip-gram是基于当前的词来预测上下文的词,适用于大型语料库中。在skip-gram模型中,通过给定的单词wt来计算出上下文Swt=(wt-k,…,wt-1,wt+1,…,wt+k)。其中k表示上下文中单词的数量,k≤n,n为文本的大小,则c-skip-n-gram模型为:
(1)
式中:c表示当前词所在上下文的长短;n表示训练文本的数量。其训练目标函数采用最大平均对数函数,表示为:
(2)
利用上述公式进行模型训练,当样本误差最小时,训练得到的每个单词的输入到隐藏层权值参数值就是该输入词的词向量。
1.2 GloVe模型
GloVe模型是一种基于词共现矩阵的词向量表示方法。在共现矩阵X中,坐标为(i,j)处的值xij表示目标词wi与语料库中上下文中词wj共同出现的次数,因此X为全局非零矩阵。GloVe模型采用最小二乘法作为训练损失函数,其表示如下:
(3)
(4)
式中:N为词典的大小,wi和wj表示词i和j的向量。bi和bj为矩阵X中i行和j列的偏移值。P(x)为加权函数,实现对训练中的低频词进行系数衰减操作,从而减少由于低频词造成的误差。在式(4)中β为常量,根据实验经验,一般为0.75。
1.3 fastText模型
fastText模型采用类似CBOW方法,采用三层网络结构,即输入层、隐层和输出层。其中输入层输入的不是简单的单词数据,而是对单词进行深一步的分词结构。设分析文本为S,其由n个单词构成S={w1,w2,…,wn}。则输入的第t个词wt被进一步分解为k个子词wt={c1,c2,…,ck},则最终输入的训练文本为:
(5)
该模型输出为文本的标签。在做输出时模型采用分层Softmax,使用哈夫曼编码对标签进行处理,从而极大地降低了运算的复杂度。
模型的目标函数如式(6)所示。式中:N为语料库数量;yn为第n个输入文本对应的类别;f(x)为softmax损失函数;xn为文本的归一化处理值;A和B为权重矩阵。最终训练得到输入层到隐藏的权重参数就是分词向量。
(6)
1.4 ELMo模型
ELMo采用双向LSTM神经网络模型,其由一个向前和一个向后的LSTM模型构成,目标函数就是取这两个模型的最大似然数。其中,向前LSTM结构为:
(7)
反向LSTM结构为:
(8)
目标函数为:
(9)
ELMo首先通过训练此模型完成一定的任务,达到要求,然后就可以利用输入特定词,通过上述公式获得词向量,即把双向LSTM模型的每一个中间的权重进行求和,最终就得到词向量。
1.5 BERT模型
BERT模型采用类似ELMo结构,采用双向模型。但是它所使用不是LSTM模型,而是Transformer编码器模型,其目标函数为:
P=F(wi|w1,…,wi-1,wi+1,…,wn)
(10)
BERT与传统的注意力模型的区别在于,它采用直接连接注意力机制。通过多层注意力结构,实现多头注意力能力。
2 微博灾害信息文本数据向量化
为实现文本多目标分类目的,本文采用微博灾害数据集为研究对象。微博灾害数据集来自于CrisisNLP网站。其提供了2013年到2015年的2万多条条灾害相关的微博数据,并对微博数据进行了分类标注。为了实现利用各类通用词向量模型对相同灾害数据集处理结果输出格式的标准化,针对5种常用词向量模型,采用离线词向量数据集和词向量生成网络两种模式处理灾害数据集中的关键词。其中,针对Word2vec、GloVe和fastTest三个模型采用官方提供的基于大量新闻信息训练模型生成的通用词向量数据集。通过查询常用词向量数据集的形式,在此数据集中查询提取出灾害数据集中对应的关键词的向量值,并进行存储。对于ELMo和BERT模型,由于没有常用词向量数据集,因此采用官方训练好的模型参数构建词向量神经网络模型,然后对灾害数据集中的关键词利用此神经网络生成对应的词向量值,并进行存储。为了实现标准化对比,5类模型最终生成的每个关键词的词向量维度为(1,300)。如果词向量达不到此维度,则数据进行补零处理,从而保证所有模型处理完后每个关键词都具有(1,300)维度。
3 多目标分类神经网络模型构建
针对微博灾害数据集的词向量维度和多目标分类要求,基于四种经典模型(MLP、CNN、RNN和LSTM)分别设计四种多目标分类模型。
3.1 多层神经网络模型(MLP)
MLP模型采用三层结构,输入层节点数目由词向量维度及博文中词个数构成,如式(11)所示。
N=K×MK=LwordM=max(count(textword))
(11)
式中:K代表词向量维度采用固定值,根据分词模型确定,M由博文中分词的数量确定。根据微博灾害数据词向量数据集的维度,MLP输入层为(1,50×300)个神经元,中间层为(1,256)个神经元,输出层为(1,6)个神经元。
输出层函数采用softmax函数,如式(12)所示,隐层输出函数f2采用sigmoid函数,w1和w2分别表示输入层到隐层的全连接网络权重和隐层到输出层的权重。
f(X)=softmax(b2+w2(f2(w1X+b1)))
(12)
f2(a)=1/(1+e-a)
(13)
为了提升模型的泛化能力,设计模型的Dropout正则化参数为0.35,最终输出层为(1,6)。
3.2 卷积神经网络模型(CNN)
为了保障模型的运行效率,根据在灾害数据集的数量和词向量维度,CNN模型采用具有2层卷积层的一维卷积模型结构,如图1所示。模型中卷积层为2层,卷积单元维度为(3,1)结构,输出结果为Conv1D_1-out和Conv1D_2-out。最大池化层单元维度为(2,1)结构,输出结果为MaxPooling_1-out和MaxPooling_2-out。在第2层最大池化层后是平铺层(Flatten-out)和隐藏层(Dense-out),最后为输出层(out-data)。

图1 卷积神经网络
根据微博灾害数据词向量数据集的维度,CNN输入层维度为(50,300)结构, 两个卷积层激活函数采用“ReLU”函数,输出层激活函数采用“sigmoid”函数,优化器采用“Adam”。
3.3 递归神经网络模型(RNN)
循环神经网络采用序列式结构,当前单元的计算结果与前一个周期的单元结果建立关联关系,获得新的结果,同时为一个周期的单元结果提供输入。如此循环构成递归神经网络模型。RNN采用m对n结构,如图2所示。
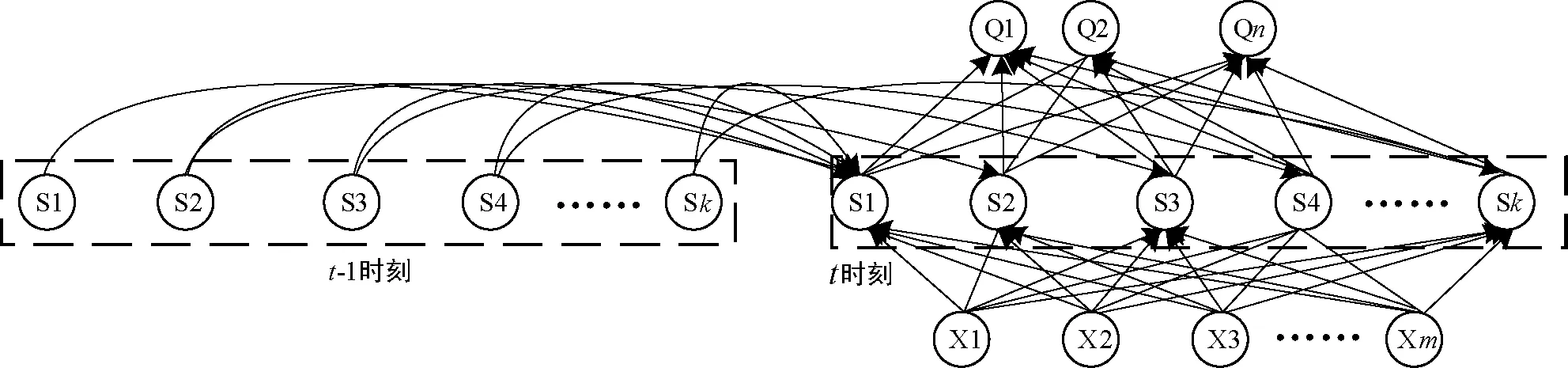
图2 递归神经网络模型
根据微博灾害数据词向量数据,输入层维度为(1,6),隐藏层维度为(1,256)结构,输出层维度为(1,6)结构。隐藏层激活函数采用“ReLU”函数,输出层激活函数采用“sigmoid”函数,优化器采用“Adam”。为保证模型的泛化性,避免过拟合发生,Dropout正则化参数为0.35。
3.4 长短期记忆网络模型(LSTM)
长短期记忆网络主要为解决RNN网络无长期记忆能力问题而提出。其主体结构与RNN网络相同,但是为实现对数据的长期记忆,在LSTM神经网络中,每一个神经元相当于一个记忆细胞,通过输入闸门、遗忘闸门和输出闸门实现控制记忆细胞状态的功能,如图3所示。

图3 长短期记忆网络神经元结构图
根据微博灾害数据词向量数据,输入层维度为(1,32)。隐藏层维度为(1,256)结构。输出层维度为(1,6)结构。隐藏层激活函数采用“ReLU”函数。输出层激活函数采用“sigmoid”函数。优化器采用“Adam”。
4 实验与结果分析
本实验进行了5个通用词向量模型在4个多目标分类模型中的对比分析。实验中共使用21 125条微博数据,其中70%用来进行模型训练,30%用来模型测试。
4.1 词向量模型在不同分类模型中结果分析
图4展示Word2vec模型在不同分类模型中的处理结果。可以看出,准确率最高为LTSM,CNN和MLP接近,最低为RNN。RNN出现了过拟合现象。CNN准确率波动较大。RNN在后半程的迭代周期,准确率提升明显。
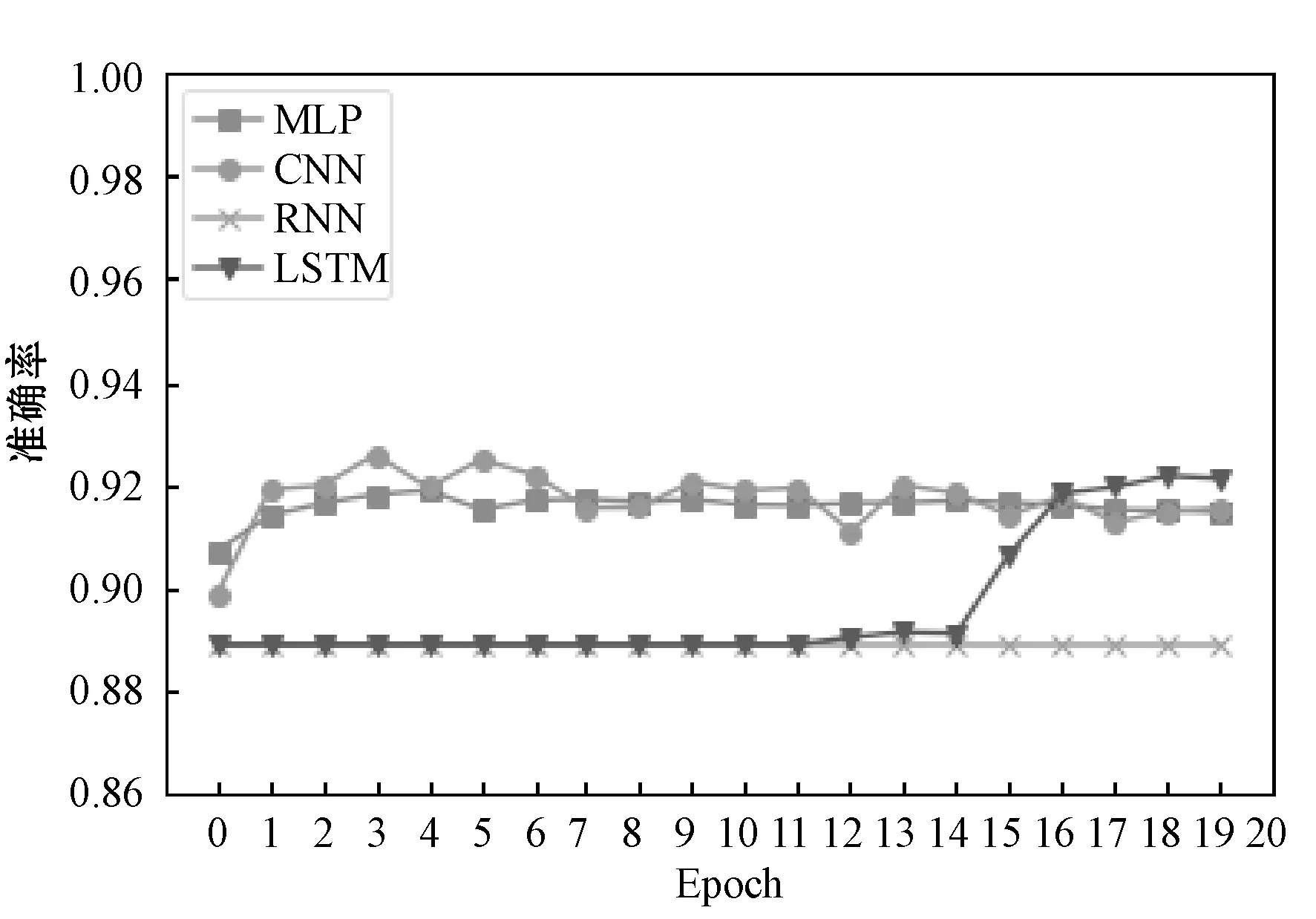
图4 Word2vec模型结果
图5展示GloVe模型在不同多目标分类模型中的处理结果。可以看出,GloVe模型数据在CNN与MLP中性能接近,LSTM次之,RNN最低,RNN模型波动较大。LSTM在最后迭代周期准确率有提升。
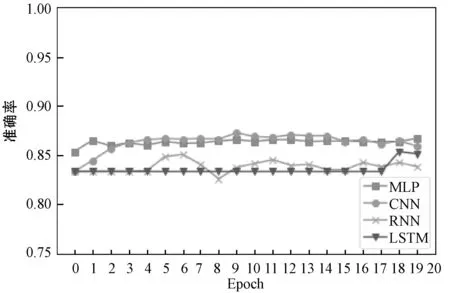
图5 GloVe模型结果
图6展示了fastText模型在不同多目标分类模型中的处理结果。可以看出, CNN具有较高的测试准确率。其他三种模型准确率相似。MLP和LSTM出现了过拟合现象,准确率变化不大。RNN具有明显的波动性。
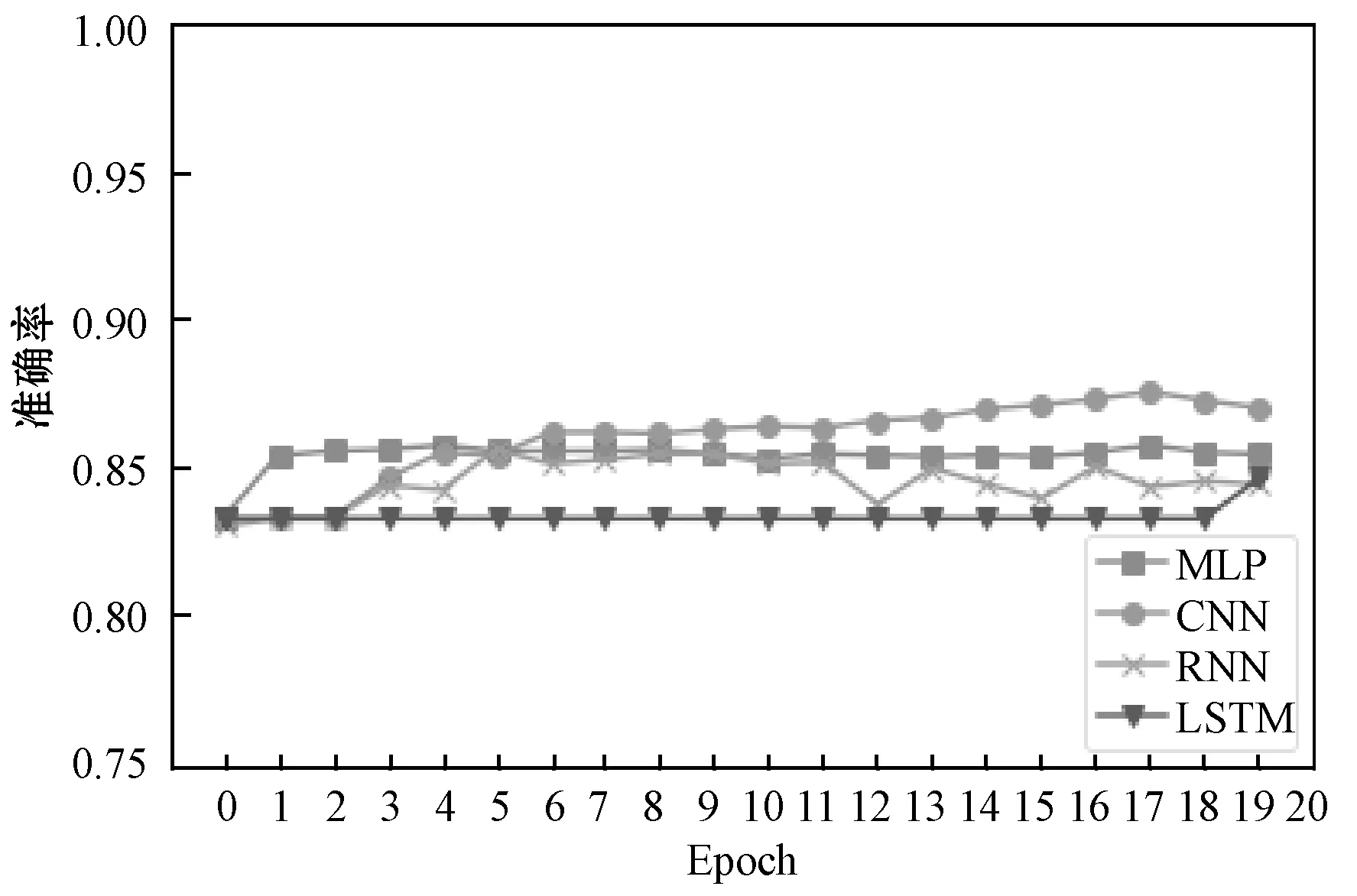
图6 fastText模型结果
图7展示了BERT模型在不同多目标分类模型中的处理结果。可以看出,BERT模型数据在RNN和LSTM中没有出现过拟合现象。在测试准确性方面,RNN的结果是最低的。CNN据具有较好的线性增长和收敛性。
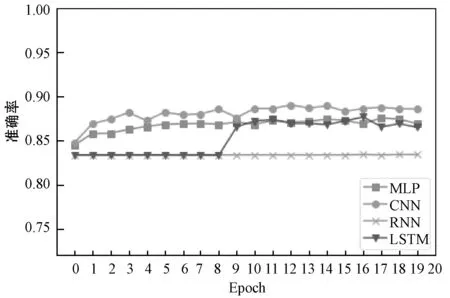
图7 BERT模型结果
图8展示了ELMo模型在不同多目标分类模型中的处理结果。可以看出,ELMo模型数据在神经网络训练方面都出现过早收敛问题,测试数据的准确率基本相同,区分度不是很大。其中LSTM表现的数据变化最不大,没有明显的线性变化过程。

图8 ELMo模型结果
通过上述模型的分析,可以看出相同的通用词向量模型,在不同的多目标分类模型中的结果是不一样的,其中以Word2vec模型表现为最好,GloVe和fastText模型具有相似的表现,BERT模型在LSTM模型数据表现较理想。ELMo模型在相同神经网络初始参数条件下出现了过早收敛现象,测试数据性能变化不大。
4.2 词向量模型在同一分类模型中结果分析
图9展示了4种分词模型在MLP模型中的训练结果比较。可以看出,除ELMo模型外,其他的训练数据较早地出现过拟合和现象。在测试数据方面,Word2vec的准确率远远高于其他4种模型。而ELMo的测试准确率是最低的。

图9 MLP模型结果
图10展示了4种分词模型在CNN模型中的训练结果比较。可以看出,BERT和GloVe都出现了过拟合现象。BERT、fastText和GloVe的训练数据准确率保持了较好的线性增长。在测试准确率方面,Word2vec具有最高的准确率,ELMo准确率最低,BERT和GloVe具有相似的准确率。
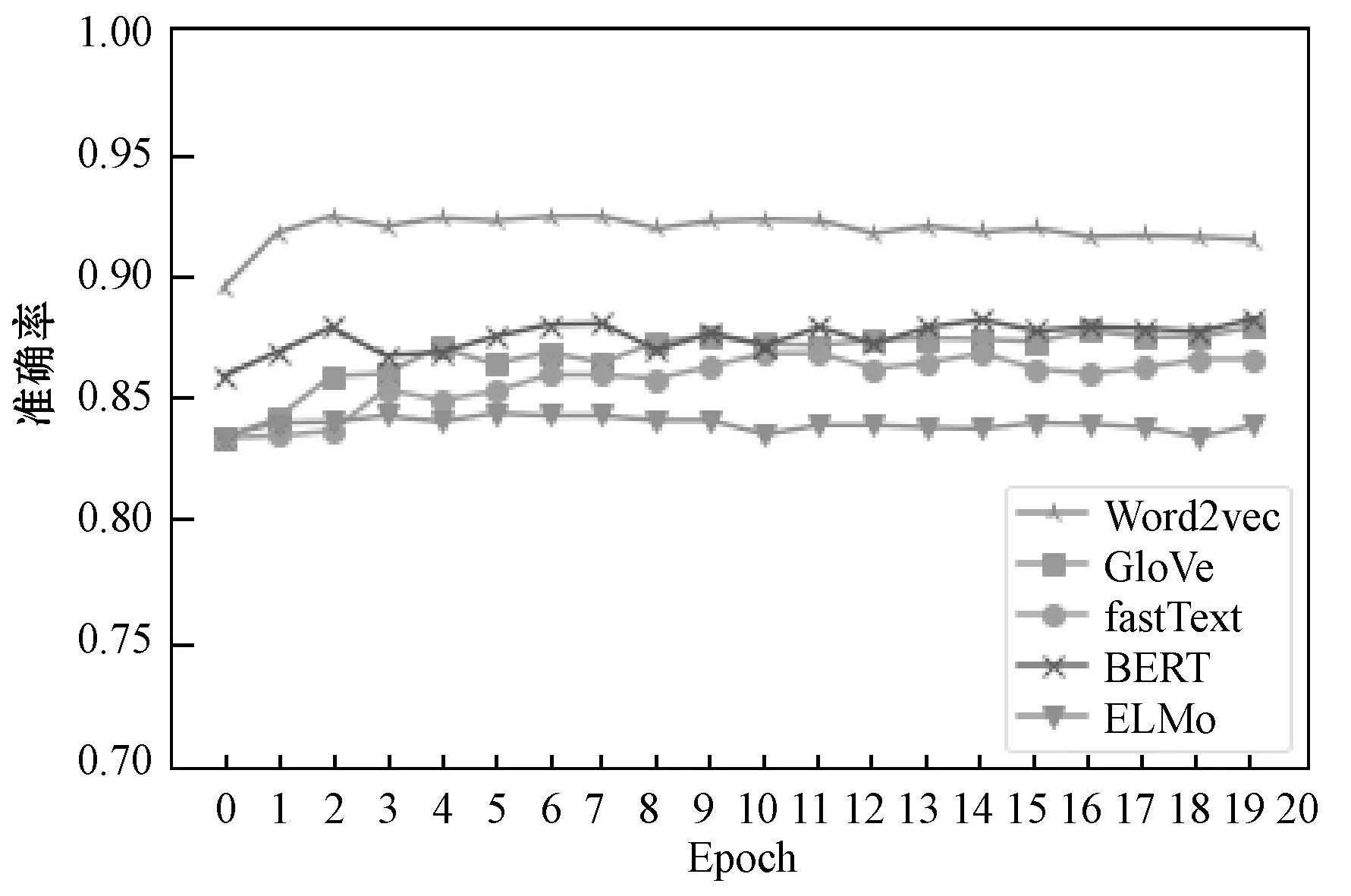
图10 CNN模型结果
图11展示了4种分词模型在RNN模型中的训练结果比较。除GloVe外,其他4种模型数据都没有出现明显的过拟合现象,尤其是ELMo、BERT和fastText模型具有相似的训练数据。GloVe虽然训练数据有一定的线性变化,但是测试数据却出现了下降的现象,说明出现了一定的过拟合现象。

图11 RNN模型结果
图12展示了4种分词模型在LSTM模型中的训练结果比较。BERT模型训练数据准确率有一定的线性增长,但是测试准确率却出现了下降,说明出现了过拟合现象。而其他4种模型训练数据准确率收敛较快,没有明显的线性增长。其中fastText与ELMo数据具有类似的训练结果数据。

图12 LSTM模型结果
通过上述分析可以看出,在MLP和CNN模型中,不同的分词模型具有不同的性能参数,虽然有些模型出现了过拟合现象,但是还保持较高的测试准确率。而RNN和LSTM模型,随着没有出现过拟合现象,但是模型的准确率数据收敛较快,跟后期训练的迭代周期关系不大。而其中fastText和ELMo两种模型RNN和LSTM中具有相似的结果。
4.3 训练时间与准确率分析
图13和图14展示了不同自然语言分析模型的训练时间和最后测试数据的准确率。从训练时间上分析,Word2vec用时最长,GloVe模型用时最短。从测试数据结果分析,Word2vec模型准确率最高,ELMo模型准确率最低。Word2vec模型用的训练时间最长,同时其测试数据准确率也是最高的。用时较少的是ELMo模型,但是其准确率在各个模型中变化不大,也是较小的。Word2vec模型在LSTM模型中测试数据获得实验的最高准确率,达到了0.934 8,而且模型训练时间也远远小于MLP时间,略高于CNN模型。RNN模型虽然具有较短的训练时间,但是各个词分类模型在RNN上的表现不是很理想,一般都低于LSTM模型效果。
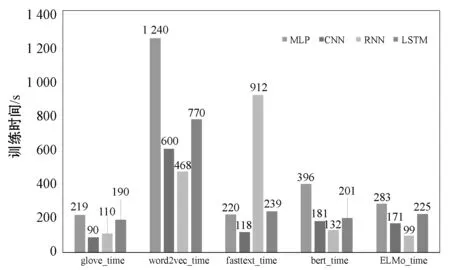
图13 模型训练时间

图14 测试数据结果
4.4 精确率、召回率和F1值比较分析
为验证模型在不同分类样本中的正确情况,对实验数据除准确率外也进行了精确率、召回率和F1值计算。其中精确率和召回率采用加权平均法,如式(14)和式(15)所示。
(14)
(15)
式中:αi为不同分类样本占总样本的比例;N为分类总数,在本实验中共有6个分类。根据精确率和准确率计算了F1值,如式(16)所示,综合评价了模型的性能。实验结果如表1所示。
F1=2×(PR×Rec)/(PR+Rec)
(16)

表1 精确率、召回率和F1值比较
可以看出,各词向量模型在CNN模型上的分类结果精确率和准确率较高,差异不大,F1值较高。而各模型在RNN上F1值较小,主要是由于精确率较低造成的。相同词向量模型在不同的分类模型中,一般F1值较低对应的准确率也较低,其中以RNN和LSTM表现较为明显,主要是由于精确率较低造成的,其中以fastText在RNN上F1值最低。
4.5 综合分析
为了进行对比分析,本实验过程也在斯坦福情感树银行数据集(Stanford-Sentiment-Treebank)和亚马逊评论数据库(Amazon Review Dataset)进行了验证,取得了相似的结果。但是准确率等指标相对微博灾害数据集较低,区分度不明显。可能原因是微博灾害数据集上各分类数据分布较均匀,同时在文本隐含信息中具有较高的相似性。而另外两个数据集通用性较强,文本隐含信息过多,分类结果不理想。
综上所述,从综合效果上看,Word2vec词向量模型在LSTM网络模型中表现出了最佳的性能。这可能有三方面的原因。首先,在灾害数据集的预处理中,采用了基于词频的关键词提取。这导致降低了分词之间的上下文联系,从而导致基于上下文关系的词向量模型性能的下降,如fastText和ELMo模型。其次,由于LSTM神经网络模型具有长时记忆功能,通过迭代训练,能够发现训练数据集中的共同属性。因此,在特定领域数据集方面,对具有相同特点文本学习能够体现出更好的性能。最后,就是Word2vec词向量模型网络体现结构特点,Word2vec没有过多依赖上下文的关系进行词分量,而是更多依靠多维度的信息描述方法。虽然过多的维度描述导致了词向量数据存储规模的增大,降低了处理速度,但是它具有更强的通用性,因此,在分词上下文关系较弱的自然文本分析中能够体现出更好的性能。
5 结 语
本文基于微博灾害数据集,对五种通用词向量模型在文本多目标分类中进行了比较分析。设计了MLP、CNN、RNN和LSTM多目标分类模型。通过实验分析了五种通用词向量模型在不同分类模型中的特点。实验结果表明,Word2vec模型网络体系结构由于提供了更多的文本隐含信息,因此在微博灾害数据集情感分类中具有较高的准确性。下一步工作可以针对不同通用词向量模型设计特殊的神经网络模型,提升多目标分类的准确率。
