基于词袋模型与几何不变特征的笔迹鉴别
2022-08-10李新德阿依夏木力提甫熊闻心
李新德 阿依夏木·力提甫 杨 天 熊闻心
1(国网湖北省电力有限公司信息通信公司 湖北 武汉 430077) 2(武汉大学电子信息学院 湖北 武汉 430072) 3(新疆师范大学物理与电子工程学院 新疆 乌鲁木齐 838054)
0 引 言
人类的生物特征可以分为生理特征和行为特征两种类型,前者包括指纹、面像、虹膜、掌纹等静态特性,后者主要指的是步态、声音、笔迹等动态特性[1]。其中,笔迹反映书写人长期以来形成的特殊书写行为,与其他行为特征相比,笔迹图片具有相对稳定性、获取方便,并且利用特定的模式识别技术可以确定书写人的身份[2]。
最近几十年来,笔迹鉴别技术在历史文件分析、司法嫌疑人身份识别和古代手稿分类等方面发挥着重要作用。然而,鉴于书写文字的多样性、个人写作风格的随意性以及笔迹样式易受到外部因素的影响等原因,笔迹鉴别具有很大的难度,尤其对于文档字数比较少以及内容各异的实际场景。
人工智能和模式识别领域的发展在很大程度上促进了笔迹鉴别的发展,各种信息编码技术也给文字处理提供了新思路[3]。最近十年比较流行的是局部特征提取方法和基于码本的笔迹鉴别算法[4]。李昕等[5]提出的网格微结构特征虽然适用于多文种,但对笔迹样本的字符数量有较高要求。陈睿等[6]提出了基于关键词的文本依存笔迹鉴别技术,该方法通用性低、稳定性差。谢鹏飞等[7]提取以图像边缘为基础的方向比重特征,研究了维吾尔文笔迹。由于每个微切分窗口提取的笔迹特征较少,该方法并不适合内容篇幅很少的笔迹样本。鄢煜尘等[8]提出了双因子方差分析方法,并利用数据挖掘技术提高了鉴别准确率。全志楠等[9]提出了在小样本数据情况下提取邻环结构特征的方法。文献[10]利用的SIFT描述符在图像检索以及图像取证相关领域有着强大的功能,但需要组合能力强的编码方式。文献[11]提出了局部二进制模式的游程长度(LBPruns)和线分布云(COLD)特征,是基于纹理的无曲率特征。文献[12]采用字符碎片码本及文献[13]提出的集成码本,不仅要求的代码数量比较多,而且需要较长的训练时间。文献[14]针对签名验证系统提出了能够代表复杂成分的简单字母或者字母组合生成码本进一步提高了笔迹鉴定效率。随着深度学习算法成功用于笔迹鉴别任务中[15],以上算法称为手工特征,大家开始注重系统的学习能力。然而,深度学习算法的网络结构庞大、训练权值多、需要海量的训练数据,无法满足实际应用需求。
手写文档中的字符外形、字位倾斜度、中心偏移、字符的伸展与伸展平衡度等特征能够反映不同的书写风格[4]。本文深入研究各语种文字的结构特征,搭建基于笔迹书写结构的词袋模型,提出了几何矩的八个特征。低阶几何矩能够描述物体形状的定性特征,并且通过归一化能够减小特征值的动态范围。小样本条件下利用八个矩特征可以表征笔迹风格,比直接用网格窗口遍历整篇样本耗时少、效率高,更重要的是书写人数的增多对实验结果的影响不明显。此外,在预处理阶段,高频模式的切分工作不受窗口大小和形状变换的影响,并且需要提取的子图像数量远比以上文献少。实验表明,对于字符数较少以及内容不受约束的笔迹鉴别任务,该算法具有良好的表征能力。
1 基于矩特征的笔迹鉴别方法
本文算法通过两个步骤实现:预处理与测试。预处理部分主要包括原始图像的二值化、子图像的提取与标注、搭建词袋模型等三个部分。测试部分主要完成特征提取、特征融合、多分类器组合等操作,其流程如图1所示。

图1 基于矩特征的笔迹鉴别流程
可以看出,本文预处理部分的主要任务是合理切分原始图像,搭建能够代表作者书写风格的词袋。测试部分的主要任务是能够全面提取子图像特征,鉴定作者身份。这两个部分在笔迹鉴别系统中分别由预处理软件和测试软件实现。首先所有扫描好的笔迹图像被分成两大组:参考样本和测试样本。在预处理阶段把所有的图像转换成二值图像,去除各种噪声、行线、格线。然后根据文字的书写特点确定文中出现频率较高的模式,切分高频子图像、归一化并标注。所有已标注的子图像形成了书写人独有的“词袋”,其中子图像的切分是词袋模型的基础;标注是为了便于检索。在测试阶段先检索参考样本与测试样本之间具有相同标注符的子图像;然后对于标注符匹配的子图像,提取八个物理特征并计算相同子图像之间的特征距离;最后经过特征融合找出距离平均值并确定最接近测试样本的笔迹。
1.1 预处理与单词拆分
原始图像用Otsu变换转换成二值图像后,通过任意大小的矩形窗口切分子图像,子图像的大小控制在1~6个字节,并且提取之后归一化成大小为64×64的矩阵。选取子图像的基本原则是根据手稿文字的书写特点,选择具有代表意义的高频模式。本文提取单词级别的子图像,并且通过冗余子图像增加相同成分的匹配概率。所有子图像经过切分、标注、归一化等预处理过程后搭建样本词袋,如图2所示。

图2 文本依存的词袋生成过程
1.2 特征提取
文本依存的笔迹鉴别方法依靠从参考样本与测试样本选取的几组相同子图像获得良好的识别结果。本文从字符图像的几何矩中提取归一化的个体特征,提取的特征在平移、缩放和笔画宽度下是不变的。它们明确对应于人类对形状的感知,并将它们的值分布在小的动态范围内。
对于一个大小为M×N的数字图像f(x,y)(离散函数),p+q阶几何矩的计算公式是:
(1)
从零阶矩M00和一阶几何矩M01与M10可以得到物体的重心(X,Y),即:
(2)
然后,以重心为坐标原点可得到中心矩Upq,此中心矩是相对于位移不变的。
(3)
低阶矩具有明显的物理意义,零阶矩表示图像中所有像素点灰度值和,即对于二值图像则表示黑像素点的个数,就是u前景区域的面积。相应的二、三阶矩能表达一些更复杂的形状特征。二阶矩指的是方差,其中U20和U02表示图像中的黑点分别在水平和垂直方向上的伸展度,且二阶矩U11表示物体的倾斜度。三阶矩U30和U03表示物体在水平和垂直方向上的偏移度。然而,三阶矩U21和U12表示物体在水平和垂直方向上伸展的均衡程度。因为特征值的动态范围太大会严重影响分类器的设计与功能,所以必须对特征值进行归一化处理限制取值范围。通过对二阶、三阶中心矩进行变化可以得到字符的八个归一化形状特征。这些形状特征对字符位移、尺寸和笔画厚度不变,并且特征的取值范围可以控制在[-1,1]内。
这些特征的提取方法和意义介绍如下。
1) 长宽比。字符长宽比归一化表示为:
(4)
3) 惯性比。字符的惯性比等于协方差矩阵的本征值,相应的归一化特征:
(5)
f3=0对应于字符为圆形的情况λ1=λ2。
4) 伸展度。字符的伸展度是一个旋转不变的特征,其归一化的特征值如下:
(6)
5) 水平偏度。字符在水平方向上的偏度归一化特征为:
(7)
6) 垂直偏度。字符在垂直方向上的偏度归一化特征为:
(8)
7) 水平伸展均衡度。字符水平伸展的上下均衡度的归一化特征为:
(9)
8) 垂直伸展均衡度。字符垂直伸展的左右均衡度的归一化特征为:
(10)
1.3 计算特征距离与因子分离
对于词袋中的每幅子图像计算八个特征值组成一个向量,然后把所有的子特征向量融合成总特征向量。计算特征距离时,先对于每一份测试样本的词袋检索参考样本词袋中具有相同标注的子图像,然后对于每对相同子图像计算修正的街区距离。最后进行双因子方差分析[8]、然后滤除字符因素(标注)并保留书写风格因素,获得了文本独立的笔迹鉴别分类器[1]。这里修正的街区距离计算公式如下:
d(F1,F2)=
(11)

2 实验分析和方法比较
2.1 数据集及评估标准
实验将在维吾尔语2016数据集[1]及英文数据集IAM[16]上进行。
1) 维吾尔语2016数据集:此数据集是本文作者建立。包含180个人,每人书写2页维吾尔文字,书写内容各异。测试中,同一作者提供两份文字分成两组分别用于训练与测试。
2) IAM数据集:此数据集是在手写识别领域广泛使用的英语数据集。包括657名作者提供的手稿,其中356名作者只写了1页字,301名作者至少写了2页字,书写内容不相同。本文只保留前2页进行测试,然后从301份样本中选出180份笔迹用于评估算法。
笔迹检索任务中的主要评估标准有平均准确率均值(mAP)、Soft top-K(Top-k)、Hard top-k等几种[2]。测试也有比较典型的几种对比策略:留一法对比、成对对比、相异特征对比等。本文用留一法对比策略求距离平均值,以Top-k评估标准确定最接近测试样本的参考样本。
2.2 影响因素分析
本文算法中影响测试结果的因素有书写人数、样本字数、子图像数量。
2.2.1书写人数的影响
不少研究者认为随着样本数量的增多鉴别精度普遍下降。而本文算法在保证样本字数的前提下,对于书写人数的增多具有一定的鲁棒性。本文针对维吾尔语数据集和英文数据集中字数不少于60个单词的样本,设计了书写人数对于鉴别精度的影响实验。实验结果如图3所示。

图3 书写人数对鉴别精度的影响
可见,对于维吾尔语2016数据集书写人数的增多对于鉴别精度的影响不明显。对于英文数据集IAM而言,随着书写人数的增多鉴别精度略有下降。这种区别是由两种文字的书写结构引起的。英文中有26个字母,在字数有限的情况下能够提取的子图像以单词和字母为主,然而子图像的匹配率不太高或者表征能力不强。维吾尔文中有32个字母,再加上84个字母变体时共有116个字母形体。在预处理阶段能够切分的子图像不仅包括单词和字母,还包括出现频率较高的音节和字母独立书写格式。针对IAM数据集中人数的增多引起的鉴别精度下降问题,可以采取增多子图像数量的措施提高笔迹鉴别率。
2.2.2子图像数量的影响
研究表明,随着子图像数量的增多鉴别精度会升高,并且子图像大小为2~5个字节时系统的性能变得稳定[12-13]。本文分别从两种数据库中的180份样本提取子图像,观察了子图像数量的变化对结果的影响,实验结果如图4所示。
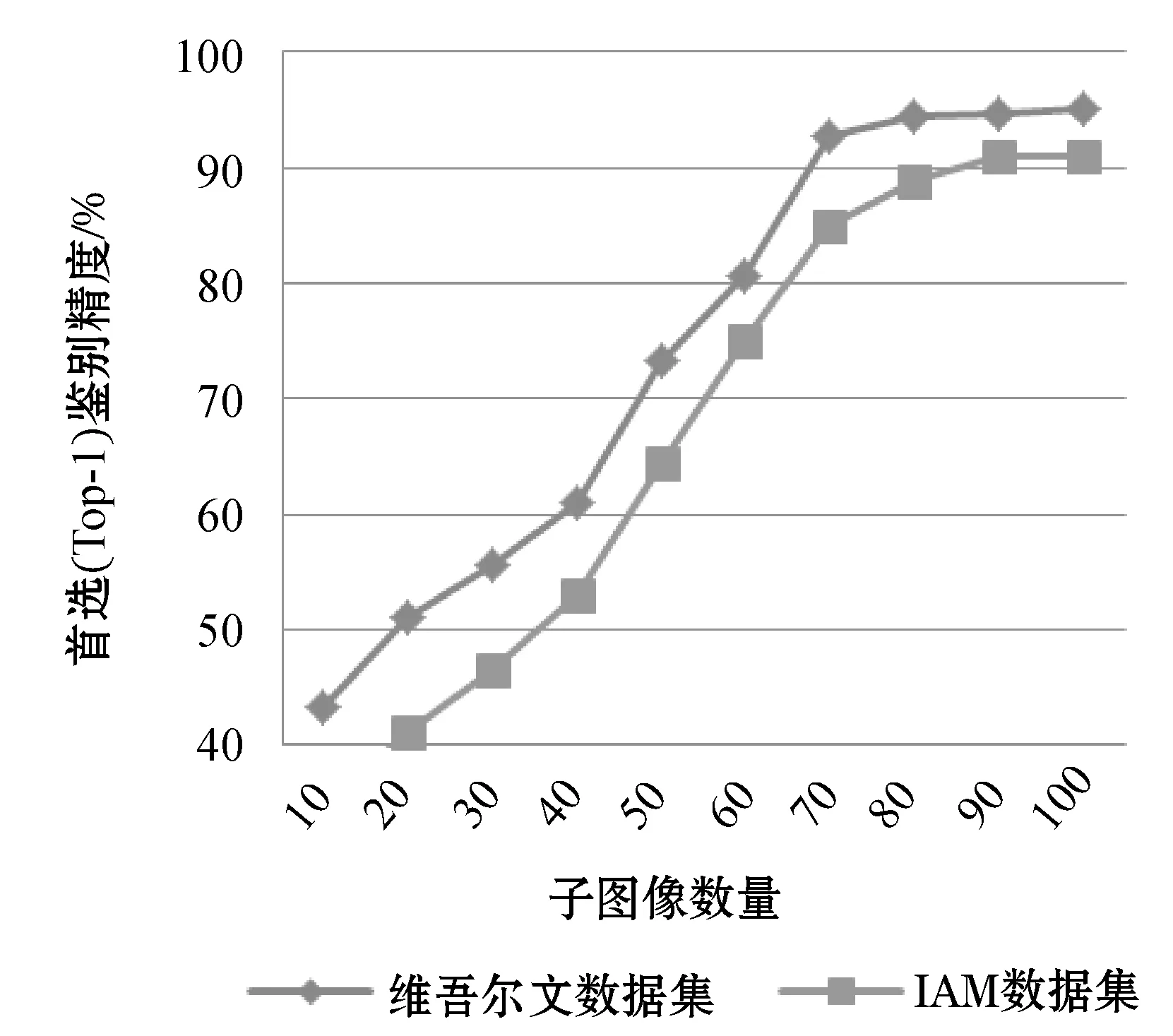
图4 子图像数量对鉴别精度的影响
词袋中的子图像从10逐渐增多到100的时候,鉴别精度从41.1%开始增加到95.2%,并且保持了相对稳定的值。可见,本文算法虽然利用10~20幅子图像可以确定书写人的身份,但是当子图像的数量达到70幅时,鉴别率提高到85%以上并保持稳定值。与文献[10,12-13]相比,本文算法需要的子图像数量少。其主要原因是本文的子图像以字母、音节、单词为单位提取,与以字符碎片相比携带的书写风格信息量比较多。此外,与IAM数据集相比,本文算法在维吾尔语数据集上的鉴别性能高于IAM数据集。其主要原因在于维吾尔文数据集上的样本篇幅大,提取的子图像以单词为主,包含少量字母独立体和音节。然而,IAM数据集上的子图像除了少量单词,其他都是表征能力较弱的独立字母、前缀和后缀。
2.3 鉴别结果
本文先从两种数据集上的每一份样本至少提取70幅子图像搭建了词袋。考虑字数较少的样本,本文中除了选取单词级别的子图像,还提取一定数量的字母和音节增多了冗余子图像。为了提高系统鲁棒性,对于一份样本上重复出现的词语和词语块,采取了完全提取的措施。本文算法的鉴别性能如表1所示。

表1 基于矩特征的笔迹鉴别结果(180份样本)(%)
可以看出,维吾尔语数据集上的鉴别结果比IAM数据集的高一些。其主要原因除了子图像的长度因素,还有子图像的数量和笔迹质量等因素。
2.4 鉴别性能对比
国内在维吾尔文笔迹鉴别方面的研究也不少,本文算法的性能与文献[7]的对比结果如表2所示。
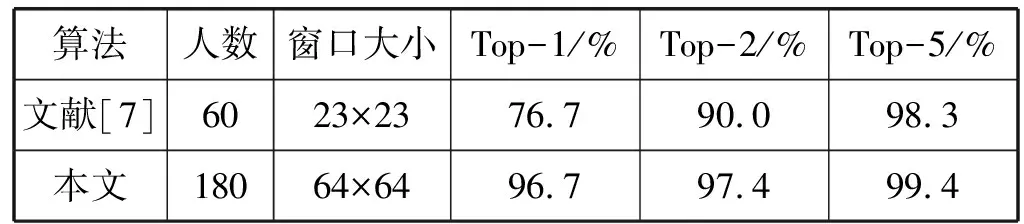
表2 局部特征鉴别性能比较(维吾尔语2016)
从书写人数和首选鉴别率相比,在人数比文献[7]多两倍的情况下,本文算法仍然得到96.7%的首选鉴别率,比文献[7]提高了20百分点。
国际上,使用IAM数据集的研究论文较常见,在测试样本与参考样本的比例为18:65的前提下,本文算法与相似文献的对比结果如表3所示。可以看出,本文方法在IAM数据集中的首选(Top-1)鉴别结果排第四,但前10候选鉴别性能最高, 整体性能比较令人满意。

表3 几种局部特征方法的鉴别性能比(IAM)
本文方法在预处理阶段不受窗口大小的影响。只要以单词、字母或者音节为基础的子图像能够完整地提取,基本上可以满足本文的测试要求。实验结果表明,本文要求的子图像数量较少,并且书写人的增多对实验结果的影响相对不明显。对于字数较多的数据集,本文还可以通过增多子图像的数量进一步提高鉴别精度。
3 结 语
本文提出一种基于词袋模型与矩特征的笔迹鉴别方法。在预处理阶段,本文提取了以单词、字母和音节为主的子图像并标注,建立了词袋模型。对于词袋中的每一个幅图像提取八个几何矩特征生成特征向量,然后利用特征融合的方法求出所有子图像的总特征向量,最后用修正的街区距离公式求距离并进行因子分离。本文利用维吾尔文数据集和英文数据集IAM评估算法,并通过实验验证了本文方法的可行性和鲁棒性。
