基于非光滑经验似然的低收入比例推断
2022-08-09杨夕冉
杨夕冉
(西南交通大学数学学院,四川 成都 610031)
低收入比例是世界各国公认的用于描述收入分配不平等的一个重要指标,它常被用来评价人类社会的经济和贫困状况,这一指标的准确估计对政府制定经济政策有着重要作用。设X为非负的连续收入随机变量,其分布函数为F(x),密度函数为f(x),随机变量X的分位数是ξβ,即ξβ=F-1(β)。低收入比例是指ξβ的关于给定α部分的人口收入的比例,其中0<α,β<1,低收入比例的表达式为θαβ=P(X≤αξβ)=F(αξβ),其中αξβ定义为低收入线[1]。
低收入比例的准确估计对政府制定经济政策有着重要作用,因此许多学者对低收入比例进行了研究,如Preston[1]和Zheng[2]根据经验分布函数得到了低收入比例的估计,并且证明了低收入比例在大样本情况下其估计具有渐近正态性。然而在实际数据分析中效果往往并不理想,因为收入常常是有偏数据,在此基础上产生了经验似然方法。有关经验似然更详细的介绍推荐Owen[3]所撰写的专著,Lei等[4]在此基础上使用了Bootstrap方法对低收入比例进行估计。Yang等[5]在Lei的基础上考虑使用经验似然方法来对低收入比例进行估计,并证明了经验似然比的极限分布是服从带未知参数的卡方分布。Yin[6]对有删失数据的低收入比例使用刀切经验似然法来构造置信区间。Luo等[7]提出了使用刀切法来处理低收入比例,并且证明了在光滑的刀切经验似然情况下低收入比例的经验似然比的极限分布是服从标准的卡方分布。文献[7]中提出的刀切经验似然方法需要使用交叉验证进行核函数窗宽的估计,为了避免对窗宽进行选取,通过查阅文献发现Molanes等[8]证明了当目标函数在估计值附近为非光滑,其期望在估计值附近为光滑时,目标函数估计值的经验似然比函数是服从标准的卡方分布。
文献[8]中提出的方法避免了核函数以及窗宽的选择,借鉴文献[8]中的方法,我们证明了低收入比例的经验似然比是服从标准的卡方分布。
1 简单随机抽样下非光滑经验似然推断
设X1,X2,…,Xn为来自总体X的简单随机抽样,由低收入比例的定义知
θαβ=P(X≤αξβ)=F(αξβ)=E[I(X≤αξβ)],
即有E[I(X≤αξβ)]-θαβ=0,同理由F(ξβ)=β有E[I(X≤ξβ)]-β=0。为了书写方便,将感兴趣的参数θαβ当成目标参数并记为θ,将不感兴趣的参数ξβ当做多余参数并记为ξ,根据经验似然方法,关于未知参数θ、ξ,经验似然函数可表示为
(1)
其中:g1=I(X≤αξβ)-θαβ,g2=I(X≤ξβ)-β。
利用标准的Lagrange乘数法,可以得到
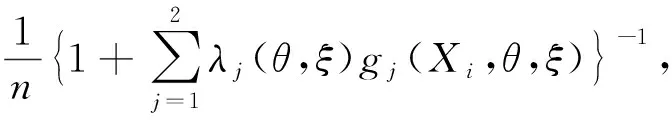
i=1,…,n
(2)
其中:λj(θ,ξ)是Lagrange乘子,满足
(3)
关于未知参数θ、ξ,经验对数似然比函数形式为
l(θ,ξ)=-2log R(θ,ξ)=
(4)
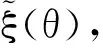

(5)
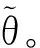
构造矩阵
其中:
记
g(X,θ0,ξ)=(g1(X,θ0,ξ)g2(X,θ0,ξ))。
给出以下正则条件:
(C0) 存在ξ0的一个邻域N,有P(L(θ0,ξ)>0)→1对∀ξ∈N成立;
(C1) 函数gj(x,θ0,ξ),j=1,2在×上一致有界,对所有ξ在ξ0的邻域N附近是连续的,E{g(X,θ0,ξ)/[1+ηtg(X,θ0,ξ)]}对ξ属于ξ0的邻域N附近是可导的,E{g(X,θ0,ξ)gt(X,θ0,ξ)/[1+ηtg(X,θ0,ξ)]2}在ξ属于0到ξ0的部分之间是一致连续的;
(C2) 矩阵V11是严格的正定矩阵;
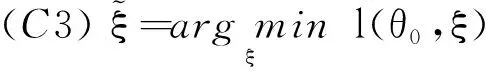
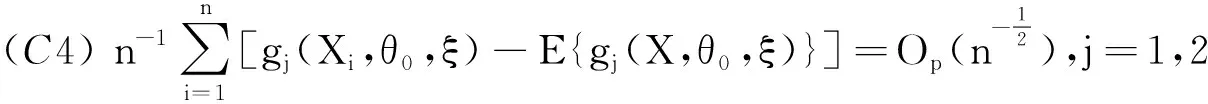
在ξ属于ξ0的o(1)阶邻域部分是一致成立的;
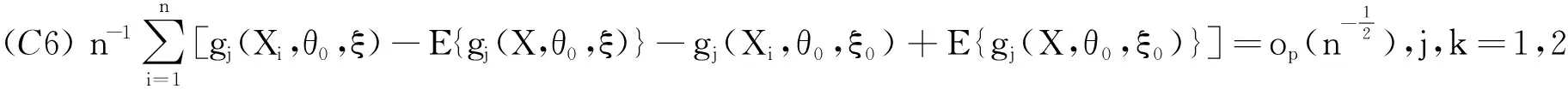
为了证明下面定理,需要证明低收入比例模型满足上面的正则条件:
设X为有分布函数F(x),密度函数f(x)的非负随机变量,由前述知
g1=I(X≤αξβ)-θαβ,g2=I(X≤ξβ)-β,
(0<α<1),(0<β<1)
由低收入比例定义知存在δ>0,使得
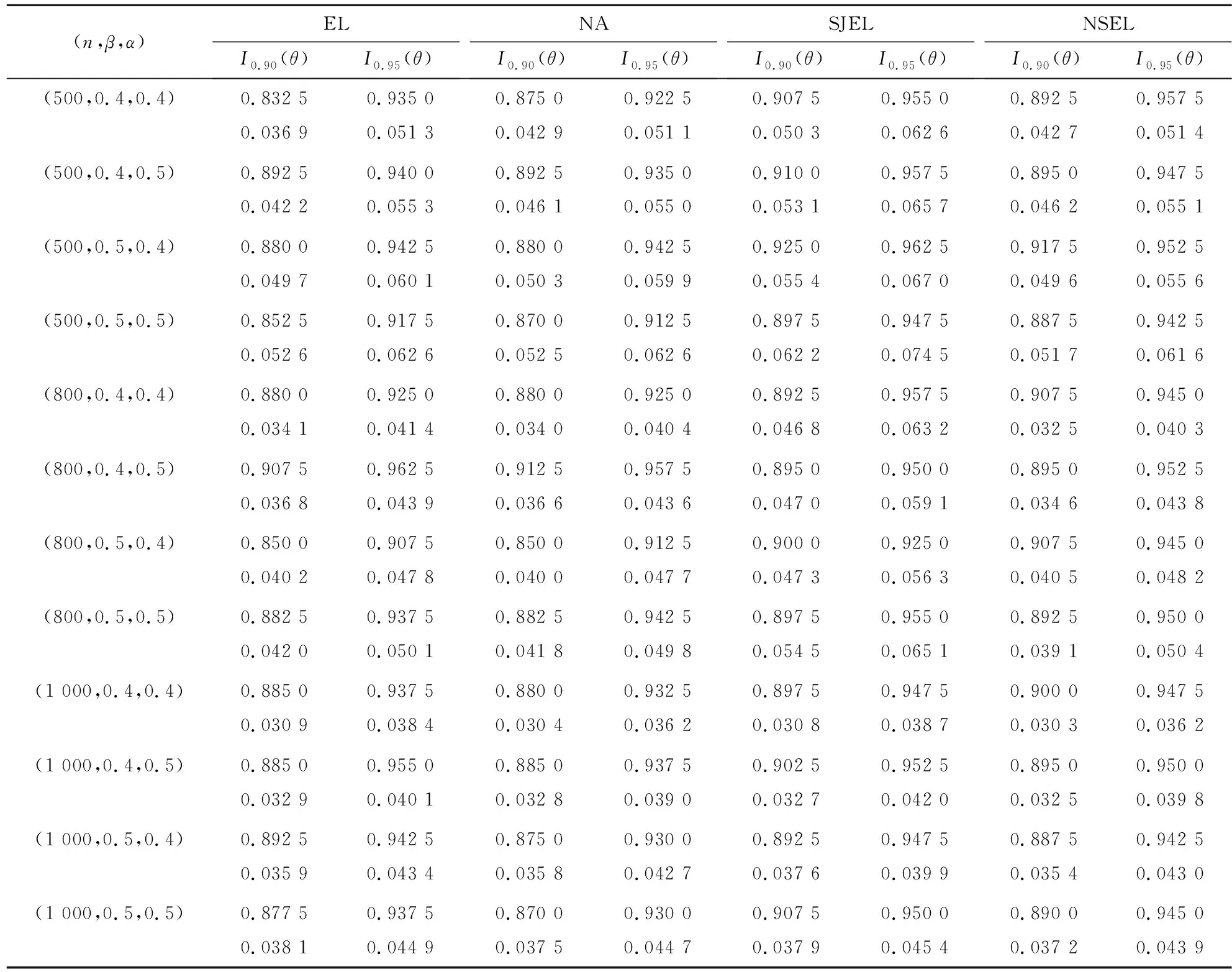
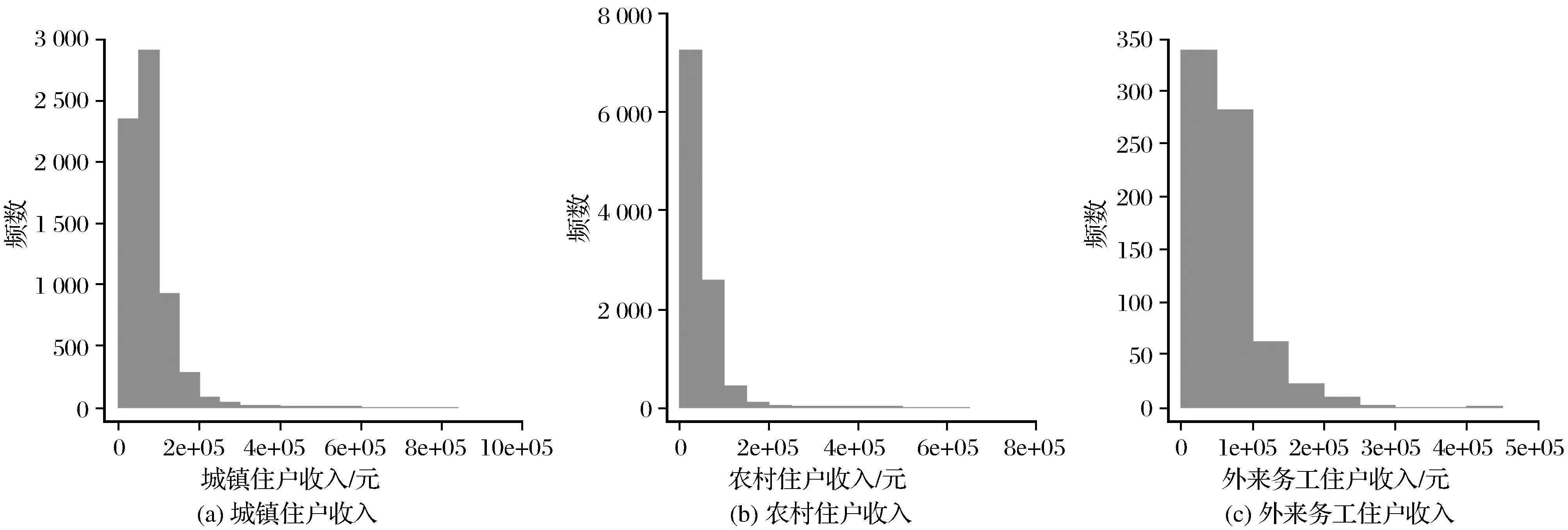
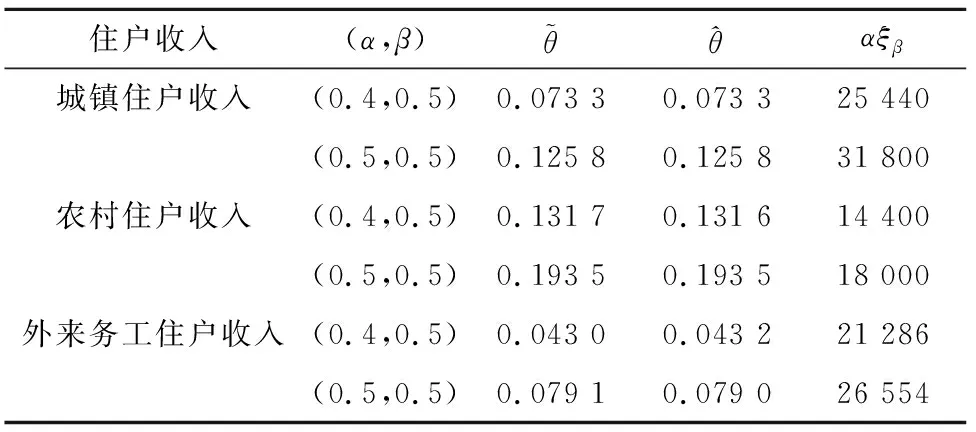
N={ξ:δ 成立,对∀ξ∈N,由(g(X1,θ0,ξ),…,g(Xn,θ0,ξ))所构成的凸形壳依概率1收敛到2上(1-θαβ,1-β),(-θαβ,1-β)及(-θαβ,-β)构成的三角形内部,再由θαβ<β知(0,0)在三角形内部,因此(C0)成立。 由文献[3]可知,当n→∞时有E{g(X,θ0,ξ)}光滑,且F(x)在x=ξ0的邻域附近是二次连续可导的,因此可知(C1)成立。 矩阵V11为正定矩阵: |V11|=E{[I(X≤αξβ)-θαβ]2}· E{[I(X≤ξβ)-β]2}- {E[I(X≤αξβ)-θαβ]· [I(X≤ξβ)-β]}2=D(I(X≤αξβ)- θαβ)·D(I(X≤ξβ)-β)-Cov(I(X≤ αξβ)-θαβ,I(X≤ξβ)-β)。 由柯西施瓦茨不等式知上式大于0,因此可知(C2)成立。 (C4)~(C6)成立则是由经验分布函数的收敛及连续性性质所得的。 下证(C3),对一固定样本X1,…,Xn及ξ使得L(θ0,ξ)>0成立,有 且有 为证明(C3),定义 (6) Γ(ξ)=-E{log[1+γ(ξ)tg(X,θ0,ξ)]}, (7) 其中:γ(ξ)=(γ1(ξ),γ2(ξ))满足 且有l(θ0,ξ)=-2nΓn(ξ),而由隐函数定理及条件(C1)知γ(ξ)存在且在ξ属于ξ0的邻域附近是唯一且连续可微的。 可知上式成立。 上式第二部分由文献[9]中的Z估计量的性质推断其为op(1)。 下证第一部分是一致趋于0,引入类Λ, Λ={x→log(1+ηtg(x,θ0,ξ)):η∈R,ξ∈}, 由L(θ0,ξ)>0且1+λ(θ0,ξ)tg(Xi,θ0,ξ)为严格的正数,因此λ(θ0,ξ)t=(λ1(θ0,ξ),λ2(θ0,ξ))t需要满足以下条件: 这3个半平面相交所构成的图形为一个三角形,因此可知类Λ为Glivenko-Cantelli类,由文献[10]中的定理2.7.5以及函数gj(x,θ0,ξ)(j=1,2)对x的单调性知条件(C3)成立。 证明与式(6)和式(7)的定义类似,定义 (8) M(θ,ξ)=E{log[1+γ(θ,ξ)tg(X,θ,ξ)]}, (9) 其中:γ(θ,ξ)=(γ1(θ,ξ),γ2(θ,ξ))满足 γ(θ,ξ)在ξ属于ξ0,θ属于θ0的邻域附近,且有 l(θ)=2nMn(θ,ξ)。 由函数g(X,θ,ξ)的期望在θ0、ξ0附近为连续函数,可知M(θ,ξ)在θ0、ξ0附近连续,因此可知对∀δ>0,存在ε(δ)>0,有 λ(θ,ξ)tg(Xi,θ,ξ))-E{log(1+ λ(θ,ξ)tg(X,θ,ξ))}]+[E{log(1+ λ(θ,ξ)tg(X,θ,ξ))}-E{log(1+ γ(θ,ξ)tg(X,θ,ξ))}]‖。 类似条件(C3)证明可知 定理2当条件(C0)~(C6)成立时,有 为证明定理2,需引入下述引理。 由于引理1的证明类似于文献[8]中引理5的证明过程,故省略其证明过程。 引理1在满足(C0)~(C6)条件时,有 令 有 其中: 再注意 综上可知定理2成立。 构造非光滑经验似然(NSEL,non-smooth empirical likelihood)低收入比例的置信区间,并将所得到的置信区间与文献[5]中提出的低收入比例的经验似然(EL,empirical likelihood)置信区间、文献[7]中针对低收入比例函数提出的θ的刀切渐进正态置信区间(NA,normal approximation)和光滑刀切经验似然(SJEL,smoothed jackknife empirical likelihood)构造的置信区间进行了对比。 根据定理2可构造低收入比例的θ的置信水平为1-α的NSEL置信区间为 (10) 在进行模拟时某些pi(θ0,ξ)可能取值为0,则式(10)不成立,根据文献[3]中第三章的内容将上述约束条件变为 gj(Xi,θ0,ξ)=0,j=1,2 其中: log′*(z)=(∂/∂z)(log*(z)),进行变换后解决了式(10)不成立的问题。 为了比较上述置信区间的有效性,对其进行了模拟设计。假设总体分布函数F(x)为标准的对数正态分布(logN(0,1)),α、β分别取值为0.4和0.5,样本容量n分别取为500、800、1 000,基于400次模拟循环,得出了θ的90%和95%置信区间覆盖率以及平均覆盖长度,其详细结果见表1。表1中每组数据第一行为置信区间覆盖率,第二行为平均覆盖长度。 表1 4种算法模拟结果比较 表1展示了4种算法的90%和95%覆盖度以及平均覆盖长度,可知非光滑经验似然方法明显优于文献[5]中的模拟方法,与文献[7]中的方法进行比较发现,其结果大致相同。但文献[7]中的方法需要使用核函数以及交叉验证程序选择窗宽,核函数窗宽的选取需要花费大量的时间模拟与验证,而非光滑经验似然方法不依赖于窗宽的选取,因此考虑非光滑经验似然方法更具有适用性。 选取数据为中国收入分配研究院在2013年调查所得的中国居民收入,文献[12]中对此数据进行了详细的分析,数据包括7 175户城镇住户样本、11 013户农村住户样本和760户外来务工住户样本共18 948个住户样本,3组数据样本的直方图如图1所示。 图1 3组数据的收入分布直方图Fig.1 Income distribution of three groups of data 表2 各收入层次低收入比例的估计值和低收入线 随着样本容量的增加,所有置信区间的覆盖率都越来越接近90%和95%,平均覆盖长度也随容量的增加而减少。非光滑经验似然方法平均覆盖长度比其他方法短且覆盖率更好。 农村住户收入在低收入线下的比例较大,很多农村住户收入还未满足农村住户收入层次的低收入水平线。农村住户低收入线也远低于城镇住户和外来务工住户低收入线,说明城镇与农村之间还存在着较大的收入差距,低收入人群在农村人口中占比很大。
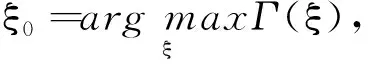
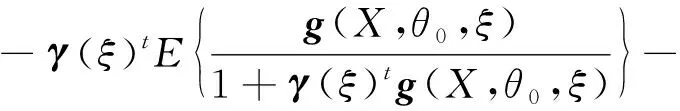
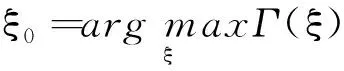
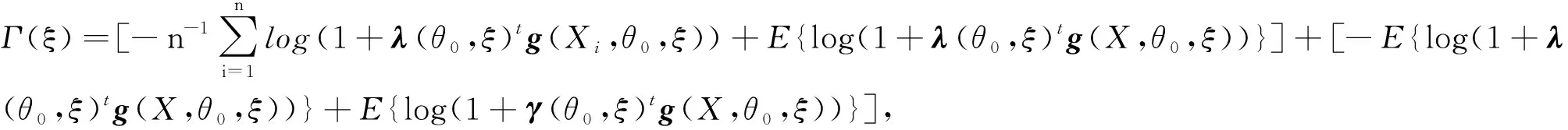
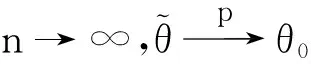


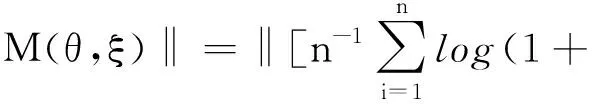
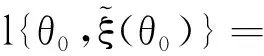
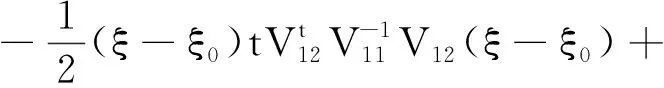
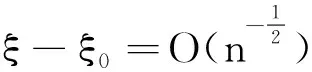
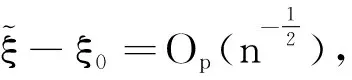
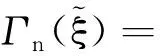

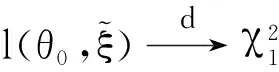
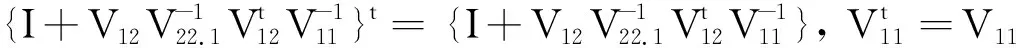
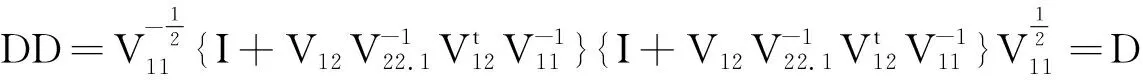
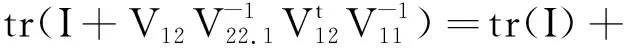
2 低收入比例的置信区间构造及模拟

3 实例运用
4 结论
