基于少样本学习的钢轨表面缺陷检测方法
2022-08-09刘俊博杜馨瑜王胜春顾子晨
刘俊博,杜馨瑜,王胜春,顾子晨,王 凡,戴 鹏
(1.中国铁道科学研究院集团有限公司 基础设施检测研究所,北京 100081;2.北京铁科英迈技术有限公司,北京 100081)
近年来,我国铁路高速化和重载化程度不断提升,如果线路中钢轨出现病害,将严重影响铁路运输安全,因此,亟需研究更高效、更准确的钢轨表面缺陷检测方法,为铁路管理部门制定维修养护计划提供数据支撑,以保障铁路运输安全。
基于机器视觉的无损检测技术具有成本低、速度快、客观性强等优点,一直受到学术界和工业界的广泛关注,已成功应用于高铁接触网部件检测[1]、轨道结构病害识别[2]、钢轨扣件检测[3-4]和钢轨表面缺陷检测[5-8]等领域。在钢轨表面缺陷检测方面,传统的机器视觉检测方法可以分为有监督式和无监督式两类。有监督式方法通常采用滑动窗口从原始钢轨图像中提取子区域,然后使用光谱特征[5]、最大稳定极值区域[6]等提取子区域特征,最后,训练K-近邻或支撑向量机识别子区域是否存在缺陷。无监督式方法通常采用局部归一化[7]、迈克尔逊对比度[8]等方法增强原始图像,然后利用轮廓投影、比例强调最大熵等自动阈值方法定位缺陷区域。然而,上述方法均依赖图像局部纹理特征,在实际检测任务中容易受到光照条件、图像噪声、轨道环境等因素的干扰,存在鲁棒性差的问题。
近年来,Faster-RCNN[9]、SSD[10]、YOLOv3[11]等目标检测方法在铁路基础设施病害检测任务中得到广泛应用。得益于深度卷积神经网络(Deep Convolutional Neural Network,DCNN)强大的学习能力和公开的目标检测数据集中千万级的已标注图像,该类目标检测方法能够自动地从大量训练样本中学习目标物体潜在的特征模式,极大地提高了目标检测的鲁棒性和检测速度。然而,现有方法应用于钢轨表面缺陷检测任务时仍难以满足“零漏报、低误报”的性能需求,其原因主要在于以下3个方面:
(1)缺陷样本数量少。基于DCNN的目标检测方法属于有监督式学习方法,通常分为目标定位和目标分类两个阶段,需要输入大量已标注数据进行训练;然而,实际检测任务中,有缺陷钢轨图像的数量相对稀缺,导致无法手动收集和标注足够的训练样本。
(2)不同类别缺陷样本数量差异大。现有方法训练目标分类阶段时,各类别的训练样本数量需要大致平衡;然而,实际检测任务中,无法保证每类有缺陷钢轨的图像样本数量平衡,导致影响网络的分类性能。
(3)缺陷区域面积小易漏检。每幅有缺陷钢轨图像一般只包含1~2处缺陷区域,并且缺陷区域面积通常较小;而现有方法对小目标对象的定位精度不足,因此对于小面积的钢轨表面缺陷区域存在漏检现象。
针对以上问题,本文通过数据增益、损失函数优化和网络结构优化3个方面的改进,提出一种基于少样本学习的钢轨表面缺陷检测方法,利用相对少的缺陷样本实现端到端的钢轨表面缺陷检测。基于少样本学习的钢轨表面缺陷检测方法整体流程见图1。
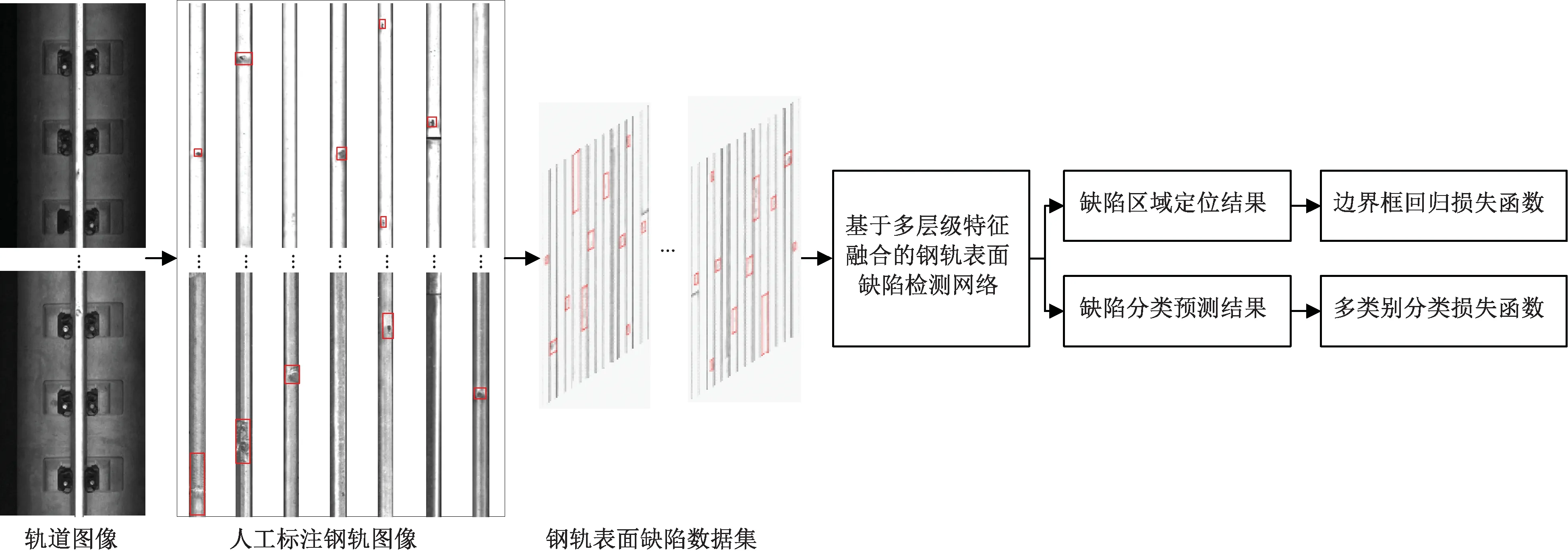
图1 基于少样本学习的钢轨表面缺陷检测方法整体流程
首先,设计样本随机组合策略,构建钢轨表面缺陷数据集,将少量已标注的钢轨图像随机拼接,解决有缺陷样本数量稀缺的问题;然后,提出一种图像代表性特征学习算法,改进深度网络的分类损失函数,降低各类别样本数量不平衡对网络分类性能的影响;最后,基于多层级特征融合的钢轨表面缺陷检测网络,提升小面积钢轨缺陷区域的检测性能。试验结果表明:该方法在2种钢轨类型的数据集中均取得最优性能,并在实际线路检测任务中,检测率达到100%,能够满足钢轨表面缺陷检测任务“零漏报、低误报”的性能需求。
1 钢轨表面缺陷数据集构建
钢轨表面缺陷数据集构建包含3个部分:钢轨图像提取、钢轨图像预处理和样本随机组合策略。该方法能够利用少量已标注的钢轨图像快速生成大量的训练样本图像,解决训练样本不足的问题。
1.1 钢轨图像提取
轨道图像是利用检测车的高速线阵相机动态拍摄获得的,包含钢轨、钢轨扣件、轨枕或混凝土基座、道砟,以及其他轨道基础设施等。为降低不相干物体对检测结果的影响,需要从原始轨道图像中提取出钢轨区域,再针对钢轨图像执行表面缺陷检测。
对每一帧轨道图像,钢轨区域具有固定的宽度W和长度L,且必定垂直于图像的X轴。其中,长度L等于轨道图像的高度,为840像素;宽度W需要根据钢轨类型选取,对于60 kg/m钢轨,W=60像素,对于75 kg/m钢轨,W=65像素。基于以上先验知识,首先利用LSD[12]算法检测图像中所有的直线;然后,两两计算垂直于图像X轴的直线的间距,如果间距小于θ,则进行合并;最后,找到间距在[W-γ,W+γ]区间的两条最长直线视为钢轨区域两侧边界,即可提取出钢轨区域图像。上述θ和γ为预设阈值,是手工选取的经验参数。
1.2 钢轨图像预处理
检测车通常在夜间天窗时间执行钢轨病害检测任务,拍摄轨道的光源强度和角度相对固定。钢轨中间区域与车轮踏面接触最频繁,较为光滑,在图像中灰度值较高;钢轨边缘区域由于存在锈迹和污物,在图像中灰度值较低;缺陷区域由于凹陷,在图像中灰度值也较低。因此,可以利用图像处理方法进一步扩大有缺陷区域与正常区域的像素值差异。
首先,计算钢轨图像中各像素值的对数,计算方式为
(1)
然后,进行Z-Score标准化,计算方式为
(2)

最后,将各像素的z值归一化到[0,255]区间,得到预处理后的钢轨图像。钢轨图像预处理结果见图2。

图2 钢轨图像预处理结果
1.3 样本随机组合策略
样本随机组合策略的具体步骤如下:
Step1以数字表示钢轨图像类别:0为“正常钢轨”;1为“钢轨掉块”;2为“钢轨表面擦伤”;3为“钢轨表面塌陷”;4为“钢轨表面有异物”。
Step2各类别的钢轨图像数量记为N0、N1、N2、N3、N4,其中N0为最大值。
Step3为每种类别创建一个长度为T×N0的有编号图像列表,并乱序排列。
Step4循环读取每种类型列表中的编号i,与此类型的图像数量取余得到索引值;然后根据索引值找到对应的钢轨图像,并随机执行翻转、添加噪声等操作;最后将处理后的钢轨图像添加到此类型列表中。
Step5将所有类型的图像列表合并,并乱序排列,每次读取T幅钢轨图像横向拼接为一幅训练样本图像,共获得5×N0幅训练样本图像。
上述步骤中,T为一幅训练样本图像中钢轨图像数量,对于60 kg/m钢轨,T=14,对于75 kg/m钢轨,T=13。基于本样本随机组合策略生成的钢轨表面缺陷训练样本图像见图3。

图3 钢轨表面缺陷训练样本图像
2 图像代表性特征学习算法
钢轨表面缺陷检测任务中,各类别钢轨缺陷的训练样本数量是不平衡的,影响检测网络对钢轨缺陷类别的分类性能。本节首先深入分析深度网络的分类原理,然后有针对性地改进分类损失函数,最后给出损失函数优化步骤。
2.1 深度网络分类原理
现有的基于DCNN的目标检测方法使用Softmax函数作为目标分类阶段的分类器,然后将分类预测结果和真实的类别标签输入到交叉熵函数中计算分类损失值,再通过反向传播算法更新各层网络的参数。Softmax函数和交叉熵函数联合称为Softmax损失函数,对于第i个训练样本的特征向量xi和对应的类别标签yi,Softmax损失函数的定义为
(3)
式中:N为训练样本总数;Wj为第j个类别的权重参数向量;bj为第j个类别的偏置向量;M为类别总数。根据余弦距离公式cos(θ)=WTx/W·x,Softmax损失函数可重写为
(4)
深度网络的训练过程实际上是寻找一组权重参数矩阵和偏置向量使所有训练样本的整体损失达到最小,即,预测的分类概率值越大,损失值就越小,分类准确率也越高。通过观察式(4)可知,影响预测分类概率值大小的变量有4个:权重向量Wyi、特征向量xi、特征向量余弦距离cos(θyi)和偏置向量byi。显然,为提高xi属于yi类的分类概率值,应该增加Wyi、cos(θyi)、byi的值。然而,当yi类的训练样本数量远大于其他类别的样本数量时,Wyi和byi也会远大于其他类别,cos(θyi)的作用会被降低。
此外,低质量的训练样本也会导致网络训练困难。通常来说,同类别图像的特征应该非常相似,其特征向量的方向和范数值应该几乎相同。然而,在实际任务中,训练样本的质量很难保证,同类别图像的特征向量范数xi存在很大差异,其大小与训练样本的图像质量高度相关。
基于以上分析,如果每个类别的权重参数范数Wj相等,且每个训练样本的特征向量范数xi相等,则网络训练时会更关注于优化不同类别特征向量之间的余弦距离,使不同类别图像特征之间的距离更大,相同类别图像特征之间的距离更小,从而学习提取更具代表性的图像特征。
2.2 改进的分类损失函数
当训练数据数量不平衡时,如果第j类的样本数量较多,则第j类对应的Wj、bj也会较大,导致网络模型的预测结果中图像属于第j类的概率较高,因此针对权重参数设置约束损失函数,定义为
(5)
(6)
该损失函数通过约束各类别的权重参数范数等于所有类别权重参数范数的平均值,来降低样本数量不平衡对网络分类性能的影响。
当所有类别的权重参数的范数相等时,如果‖xi‖较小,则xi属于每个类别的预测概率会相似,这也表明xi是图像分类成功的关键因素,因此针对特征向量设置约束损失函数,定义为
(7)
(8)
该损失函数激励每个训练样本特征向量范数尽可能地接近所有训练样本特征向量的范数平均值,减少低质量训练样本对网络分类性能的影响。
此外,偏置向量的大小与样本数量正相关,当训练集中各类别样本数量差异大时,会导致样本数量少的类别置信度低。因此,本文将网络模型中所有偏置向量初始化为0,并设置其学习率为0。
综上,改进的分类损失函数形式化为
Lcls=LSoftmax+λLW+βLX
(9)
式中:λ、β为平衡因子,用于控制每个约束损失函数的敏感程度。
2.3 损失函数优化
改进的分类损失函数使用随机梯度下降法进行优化,梯度
(10)
(11)
为方便书写,先定义符号公式为
(12)
则式(10)和式(11)中的∂LSoftmax/∂Wyi和∂LSoftmax/∂xi可以根据链式法则展开为
(13)
(14)
接着,λ∂LW/∂Wyi和β∂LX/∂xi的计算公式为
(15)
(16)
最后,
(17)
(18)
3 基于多层级特征融合的钢轨表面缺陷检测网络
钢轨表面缺陷区域的面积通常较小,现有方法存在漏检现象。本文提出一种基于多层级特征融合的钢轨表面缺陷检测网络,提升小面积钢轨缺陷区域的检测精度。
3.1 网络架构
现有的基于DCNN的目标检测方法是利用不同感受野的特征图独立地预测目标的边界框和分类概率值,然后使用非极大值抑制(Non-Maximum Suppression,NMS)算法来筛选最优的检测结果。然而,浅层特征图虽包含较多的细节信息,但缺少高层语义信息,预测的边界框位置较精确,分类概率值较低;深层特征图的感受野较大,包含丰富的高层语义信息,预测的边界框分类概率值较高,但位置不精确;使用NMS算法筛选后,分类概率值低但位置精确的边界框会被舍弃。
为此,本文提出基于多层级特征融合的目标检测网络,用于定位和识别钢轨表面缺陷。其网络架构见图4,包括6级特征提取层、3种目标检测器和1个检测结果输出层,共使用55个卷积层和5个最大池化层。

图4 基于多层级特征融合的钢轨表面缺陷检测网络架构
6级特征提取层中,第1级包含1个3×3×32的卷积层;第2级包含2个1×1×64的卷积层和1个3×3×32的卷积层;第3级包含2个1×1×128的卷积层和2个3×3×64的卷积层;第4级包含2个1×1×256的卷积层和8个3×3×128的卷积层;第5级包含2个1×1×512的卷积层和8个3×3×256的卷积层;第6级包含2个1×1×1024的卷积层和4个3×3×512的卷积层。所有卷积层的步长均为1,特征提取层之间的最大池化层用于降采样特征图,其窗口为2×2,步长为2;为防止网络过拟合,每个卷积层都使用批量归一化层[13],并采用Leaky ReLU[14]作为激活函数,以加快网络收敛速度。
目标检测器在特征图上生成6种不同大小的基准定位框,每个基准定位框d使用中心点坐标(dx,dy)和宽高(dw,dh)来表示。基准定位框与真实标注框用于回归学习边界框的4个偏移量(px,py,pw,ph),当输入的待检测图像尺寸为320×320像素时,3个目标检测器共产生12 600个基准定位框。然而,基准定位框中只有很少数量包含钢轨缺陷区域,因此,如果基准定位框与任意真实标注框的IoU值大于0.7,则标记该框为有缺陷样本,并分配对应的真实标注框的标签。得到有缺陷基准定位框后,根据1∶3的比例从IoU值小于0.7的基准定位框中挑选非缺陷样本,并分配标签为正常钢轨区域。
钢轨表面缺陷检测分为以下5个步骤:
Step1待检测图像调整至320×320像素。
Step2根据多层级特征融合策略,先分别将第5、6级特征提取层输出的特征图进行2倍上采样,再分别与第4、5级特征提取层输出的特征图级联,最后对3种不同感受野的特征图分别定义不同的目标检测器,预测不同大小缺陷区域的边界框和分类概率值。

(19)
(20)
式中:k为不同感受野的特征图,k∈[1,2,3]。将特征图的每个位置对应到原图的坐标作为基准定位框的中心坐标,即得到每个位置6种基准定位框。
Step4使用目标检测器预测边界框偏移量并计算分类特征向量。每个目标检测器都采用7个卷积层,前6层用于对级联的多层级特征进行降维和跨通道特征融合,最后1层负责预测每个边界框偏移量和分类特征向量,其通道数量C=6×4+Classes,即6种不同大小的基准定位框乘以4个偏移量再加类别总数Classes。
Step5测试阶段,通过基准定位框与预测的边界框偏移量得到候选边界框,将预测的分类特征向量输入到分类器中计算候选边界框的分类概率,使用NMS算法筛选最终的钢轨缺陷区域检测结果。
3.2 多任务损失函数
本文所提的钢轨表面缺陷检测网络采用多任务损失函数进行端到端的训练,定义为
L=Lloc+Lcls
(21)
(22)
(23)

(24)
4 试验验证
本节试验使用Opencv3.0、CUDA9.0、Cudnn7.5.1、Pytorch0.4等工具库实现,计算服务器的硬件采用2颗Intel E5-2697v4 CPU和2块NVIDIA RTX 2080Ti GPU加速计算卡。
4.1 钢轨表面缺陷数据集
为评估本文方法对不同钢轨类型的检测性能,分别从60、75 kg/m的轨道图像中提取钢轨区域图像,并人工标注缺陷区域位置和类别。钢轨图像详细信息见表1。然后采用本文提出的样本随机组合策略,共获得60 kg/m样本图像137 185幅,75 kg/m样本图像134 835幅。最后以9∶1的比例将样本图像分为训练集和测试集,用于训练和测试网络模型性能。

表1 钢轨图像详细信息 幅
4.2 训练参数选取
本节实验使用ResNet-50[15]和原始钢轨图像数据搭建图像分类网络,以选取合适的训练参数。平衡因子对深度网络模型分类性能的影响见图5。

图5 平衡因子对深度网络模型分类准确率的影响
首先,将β固定为0.01,从0到0.015之间选择λ的值,实验结果如图5(a)所示,当λ=0.008时,分类准确率达到最高值。然后,将λ固定为0.008,从0到0.015之间选择β的值,实验结果如图5(b)所示,随着β从0增加到0.01,分类准确率也随之上升。实验结果表明,权重参数约束函数可减少训练样本不平衡对分类性能的影响;特征向量约束损失函数可使深度网络学习到更具代表性的特征,从而提升深度网络的分类性能。
为更显著地观察图像代表性特征学习算法的作用,本节实验利用LeNet++[16]提取特征,减少MNIST数据集中5个类别的样本数量构建不平衡数据集,并分别使用标准Softmax损失函数和本文提出的图像代表性特征学习算法进行训练,将学习的特征向量可视化。不平衡数据集特征向量可视化结果见图6,其中Baseline是指标准Softmax损失函数学习的特征空间分布。实验结果表明,Baseline结果中每个类别的特征向量呈现不均匀的分布,样本数量多的类别所占据的特征空间远远大于样本数量少的类别。本文方法结果中,每个类别的特征向量均衡地分布在特征空间中,通过提升β的值,同类别特征向量更加聚集,不同类别的特征向量的间距更大。此现象表明,本文提出的图像代表性特征学习算法能够提高特征向量的类内紧密性和类间可分离性,使深度卷积神经网络学习更具代表性的特征。

图6 不平衡数据集特征向量可视化结果
4.3 钢轨表面缺陷检测对比试验
本节通过对比试验的方式评价本文方法对钢轨表面缺陷的检测性能,采用精确率、召回率、精确率与召回率的调和平均数F1作为评价指标。对比方法中,MSER+SVM[6]是一种有监督学习的钢轨表面缺陷检测方法,MLC+PEME[8]是一种无监督学习的钢轨表面缺陷检测方法,Faster-RCNN[9]、SSD[10]、YOLOv3[11]是目前最流行的3种基于DCNN的目标检测方法。此外,为了验证本文所提图像代表性特征学习算法的改进效果,采用标准Softmax损失函数结合本文所提的多层级特征融合网络(Multi-level Feature Fusion Network,MLFFN)作为对比方法。
训练过程中采用十折交叉验证的方式分配训练集和验证集的样本数量,即每轮训练开始前,从训练集中随机抽取十分之一的数据作为验证集。样本输入批量大小设置为128,损失函数平衡因子λ=0.008,β=0.01,动量设置为0.9,权重衰减设置为0.000 5,初始学习率为0.015,训练周期为60轮。每训练10轮更改一次输入图像的尺寸,从[320,608]区间内随机选取一个8的倍数的数值作为接下来10轮的输入图像尺寸,每训练20轮次将随机梯度下降法的学习率调整为当前的0.1倍。训练完成后,选择在验证集上性能最好的参数作为网络模型最终的参数。对比试验均在本文方法构建的测试集上进行,试验结果见表2。

表2 钢轨表面缺陷检测方法对比试验结果
根据表2对比试验结果可以得出:
(1)基于DCNN的检测方法的性能远远超过传统机器视觉方法,证明了深度卷积神经网络的强大学习能力。
(2)得益于多层级图像特征融合,SSD、YOLOv3、MLFFN+Softmax和本文方法的性能大幅超越了只使用单层级图像特征进行目标检测的Faster-RCNN方法。
(3)MLFFN+Softmax方法采用本文所提的多层级特征融合网络提升了对小面积缺陷区域的检测性能,在精确率、召回率和F1指标上均高出YOLOv3约0.5%。
(4)本文方法在2种钢轨类型的数据集上均取得了最优的性能指标,超过MLFFN+Softmax约1.2%~1.6%,表明应用图像代表性特征学习算法训练的网络模型正确检测的缺陷区域数量增加了约1 200~1 600处,充分证明了本文方法的优越性。
4.4 实际线路检测对比试验
为了验证本文方法在实际检测任务中的性能,本节采用实际线路中连续100 km的轨道图像进行对比试验。轨道图像共计103 962张,经人工检查,共存在钢轨表面缺陷区域89个。实际线路检测对比试验结果见表3。

表3 实际线路检测对比试验结果
从表3试验结果可以得出:
(1)Faster-RCNN[9]和SSD[10]的错误检测数量较少,但漏检的数量分别为15处和8处,影响检测系统的有效性,威胁铁路运输安全。
(2)YOLOv3[11]的检测率达到了96.63%,但是错检数量也较多,增大了人工复核的工作量,导致检测效率降低。
(3)本文方法不仅能够检测到全部的钢轨缺陷,检测率达到100%,而且错检数量较少,充分证明了本文方法的有效性,能够满足钢轨表面缺陷检测任务“零漏报、低误报”的要求。
5 结论
本文提出一种基于少样本学习的钢轨表面缺陷检测方法。该方法首先利用样本随机组合策略从少量已标注钢轨图像生成大量训练样本图像,从而解决有缺陷钢轨图像数量稀缺的问题;然后,利用图像代表性特征学习算法降低各缺陷类别样本数量不平衡对深度网络模型的影响;最后,利用多个层级网络层中不同尺度的图像特征进行钢轨表面缺陷定位和识别,从而实现少样本条件下钢轨表面缺陷检测。本文进行了大量对比试验,试验结果证明了本文方法的有效性和实用性。
