行李安检智能检测最难分样本集选取方法研究
2022-08-08胡靖雪徐力恒吕晓军刘跃虎
胡靖雪,张 驰,徐力恒,吕晓军,刘跃虎
(1. 西安交通大学 人工智能学院,西安 710049;2. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
安检智能检测软件(简称:智能检测软件)采用深度学习模型,自动识别行李X光图像中的危险品,减轻了安检人员作业劳动强度,同时也提高了安检效率[1]。
在实际业务场景中,由于旅客行李中携带的危险品种类繁多,且有些危险品实物形态不固定,智能检测软件可能难以识别出其中一些危险品,降低了识别准确率。对于基于深度神经网络模型的检测软件,样本数据会直接影响神经网络学习模型的预测准确率。因此,如何有效利用现场行李安检系统运行过程中的新增图像数据,提升智能检测软件的性能,使智能检测软件能够适应车站行李安检现场的复杂业务场景,满足行李安检系统产品上线应用的技术指标要求,是一道亟待攻克的技术难题。
1 行李X光图像数据的最难分样本集
智能检测软件需要应对行李X光图像数据呈“长尾分布”特征[2],即旅客行李中不携带危险物品的安全场景占绝大多数,而小概率出现的危险物品或疑似物品复杂多样,通过有限次数据采集无法获取完备的危险品图像样本数据。
为此,从现场行李安检系统采集的行李X光图像数据中,找出智能检测软件会错误识别的难分样本集,作为增量样本数据,支持智能检测软件的增量式学习,实现模型更新。这种通过数据分析来改进业务模型的迭代策略被称为“数据分析闭环”,已在无人驾驶智能系统研发领域得到广泛应用[3-4]。
行李安检智能检测数据分析闭环流程,如图1所示。
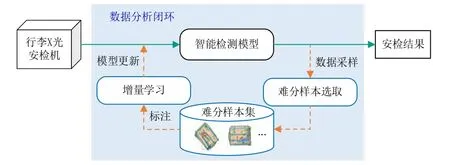
图1 行李安检智能检测数据闭环流程
实例研究表明,业务模型的最难分样本对改善系统的边界决策能力起决定性作用[5],即基于最难分样本的训练可以有效提升模型处理边界问题的能力。如何高效、准确地从现场行李图像数据中选取最难分样本集,最大程度地改善智能检测软件性能,是本文重点研究的问题。
2 行李X光图像数据最难分样本选取方法
2.1 方法框架
受数据增强(AutoAugment)策略的自动搜索方法启发[6],本文提出行李X光图像数据最难分样本集选取方法,其框架如图2所示。
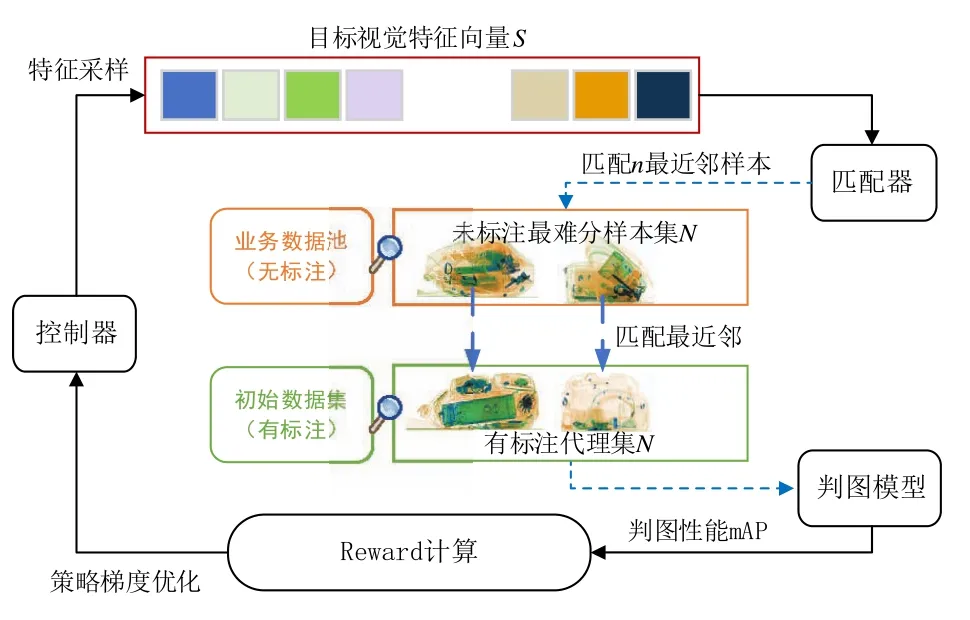
图2 行李X光图像数据最难分样本集选取方法框架
基于强化学习框架,通过迭代计算,可选取出行李X光图像的最难分样本集。即将最难分样本集选取问题转化为长短期记忆循环神经网络(LSTMRNN,Long Short Term Memory Recurrent Neural Network)控制器的样本图像特征空间离散搜索问题,使用最差性能奖励约束的策略梯度方法优化搜索过程;利用预计算的K-reciprocal重排序技术[6],查找预测样本在有标注数据集中的最近邻样本;将最近邻有标注样本作为代理计算奖励函数,驱动无标注行李X光图像数据(即业务数据池)的最难分样本选取。具体步骤如下:
(1)LSTM-RNN控制器从图像特征空间中采样,得到视觉特征向量S;
(2)匹配器从业务数据池中查找到视觉特征最接近S的n个无标注样本,作为候选最难分样本集N;并使用重排序技术,来保证匹配数据集的内部特征一致性;
(3)对候选最难分样本集N中的每个样本,在初始数据集中搜索其最近邻样本,生成代理样本集N;
(4)计算智能检测软件对代理样本集N的检测准确度mAP,根据mAP计算奖励值R,并将奖励值R发送回控制器,用于更新LSTM-RNN控制器的权重;使用策略梯度优化,解决因奖励值R不可导造成的控制器无法完成训练的问题。
2.2 策略梯度搜索算法
在最难分样本集的迭代搜索过程中,控制器采用基于强化学习的策略梯度算法进行网络训练。
控制器采样得到图像视觉特征的过程可视为动作列表a1:T,其中,T是控制器采样的视觉特征向量维数。根据控制器采样的图像视觉特征,在业务数据池中选取样本集N,在已标注数据集上生成其代理样本集N;根据智能检测软件在样本集N上的检测准确度mAP,计算用于训练控制器的奖励值R

为了从业务数据池中挑选出最难分样本集,控制器的训练目标是使智能检测软件的性能表现最小化,并使整个蒙特卡洛过程中最大奖励期望值最大化,即有

其中, θc是控制器的网络参数。
求梯度的经验近似公式通常可表示为
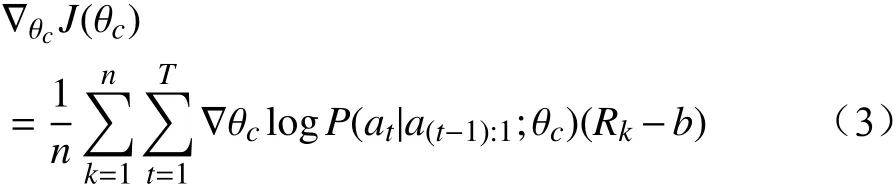
其中,Rk对应代理样本集中第k个样本的奖励值;基线函数b是前序迭代奖励值的指数滑动平均,用以降低策略梯度优化过程奖励值的期望方差。
最后,策略梯度算法通过策略性能的随机梯度提升迭代更新 θc,使控制器训练收敛,更新迭代过程可表示为

2.3 基于重排序的最近邻样本集匹配
在最难分样本集迭代搜索过程中,需要检索与控制器所生成的视觉特征S最为接近的有标注数据集。为了高效地匹配到准确性高、内聚性强的有标注数据,可使用K-reciprocal重排序技术,并结合最近邻匹配方法,将无标注样本转化为有标注样本集。
使用K-reciprocal重排序技术,可搜索到最近邻的匹配数据集,并保证匹配数据集的内部特征一致。但在迭代过程中,动态重排序会占用大量内存,且耗时较长,降低了样本匹配速度,影响了最难分样本集的搜索效率。为此,提出基于预计算重排序的匹配器设计,即预先对所有图像的视觉特征进行重排序计算,并把结果记入静态重排序表,用于快速查询视觉特征S的最近邻样本[7];静态重排序表的生成过程见算法1。
算法1
静态重排序表生成
输入:
离散特征空间Φ
有标注样本集特征 Θ1,Θ1⊂Φ
无标注样本集特征 Θ2,Θ2⊂Φ
匹配样本数n
输出:静态重排序列表T
for eachs2Θ2do
设置S为目标特征
使用K-reciprocal,计算n个最近邻的有标注样本特征p2Θ1
将键值S和包含n个样本的列表存储于T中
end for
在此基础上,在静态重排序表中查找最接近目标视觉特征的前K个最近邻特征行,可获得相应的重排序结果;最近邻有标注样本集查询过程见算法2。
算法2
最近邻有标注样本子集查询输入:
离散特征空间Φ
控制器生成的目标特征S,S2Φ
静态重排序列表T
匹配样本数n
输出:对应目标特征S的前n个最近邻有标注样本子集N
①计算T中与S最 临近的n个键值fs1,...,sng
②新建空集合N
for eachsi2fs1,...,sngd o:
①得到T中si对应的列表L
②得到列表L中top1有标注样本ti
③N=N[ftig
end for
3 测试验证
为模拟现场行李安检业务场景,使用一组初始训练集来训练智能检测软件;初始训练集包含电池、瓶子、锤斧等5类危险品图像共6 819张。同时,使用2组测试集作为业务数据池;其中,测试集A与初始训练集在同一场景下采样,包含与其独立同分布的安检图像1704张;测试集B包含与初始训练集中危险品形态迥异的1704张安检图像,用于模拟行李安检运行过程中出现的新增数据。这3个数据集中包含的危险品类别及数目,如表1所示。
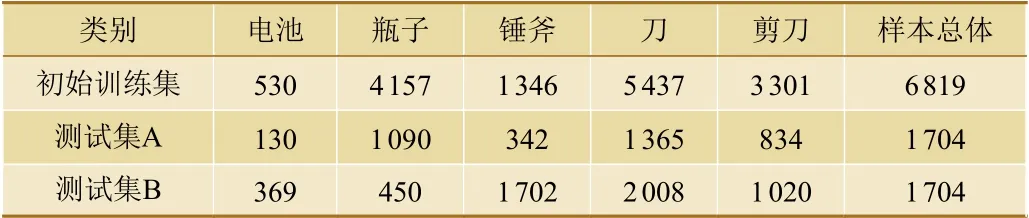
表1 测试数据集各类危险品数目 (单位:张)
最难分样本集选取算法使用LSTM网络作为基本单元,其每层包含60个隐藏神经元;通过30维softmax函数,输出预测的目标视觉特征,并计算其交叉熵损失。基于奖励值R,对控制器的策略梯度进行缩放,以确保控制器能够以较低概率采样到简单样本对应的特征,而以较高概率采样到难分样本对应的特征。控制器采用RMSProp优化器进行优化,学习率为0.001,学习率的指数衰减系数为0.95,衰减步长为50;最大迭代次数设置为300。
选用YOLO v5作为检测模型的骨干网络,其第7层卷积层输出512×20×20维特征,经PCA降维后,所得到的30维特征将作为最难分样本集选取算法中的视觉特征。
为消除实验误差,对每组测试集分别进行100次重复实验,使用全类平均准确率,评价本文算法选取最难分样本集的效果,测试结果见表2。

表2 最难分样本集选取算法实验结果
由表2可知:(1)使用本文提出的最难分样本集选取方法,针对2个不同分布的测试集A和B,所选取的最难分样本集的准确率均远低于其平均准确率,说明该方法对于选取不同分布数据集的最难分样本集均具有良好的适用性;(2)测试集B上的最难分样本集选取效果明显差于测试集A,说明对于测试集与训练集具有不同数据分布的情况,该方法的最难分样本集选取性能仍有提升空间。
4 结束语
本文分析安检智能检测数据分析闭环流程,能够从行李安检系统运行过程中产生的危险品实例图像中持续选取最难分样本,作为增量数据,完成智能检测软件的学习更新,实现车站安检智能检测软件性能的持续成长。本文将最难分样本集选取形式化为LSTM-RNN神经网络控制的样本图像特征空间离散搜索问题,使用最差性能奖励约束的策略梯度方法优化搜索过程。利用预计算的K-reciprocal重排序技术,查找预测样本在有标注数据集中的最近邻样本,将最近邻有标注样本作为代理计算奖励函数,驱动无标注业务数据池的最难分样本集选取。测试表明,该强化学习架构可有效选取业务数据池中智能检测软件的最难分样本集。
在实际的行李安检场景中,行李中包含的危险品可能与训练集处于不同分布,无法选取其最理想的最难分样本集,将影响智能检测数据分析闭环的软件更新效率。因此,如何在测试集与训练集处于不同数据分布的情况下,提高最难分样本集的选取性能,将是下一阶段的研究重点。
