基于深度学习的铁路客站视频融合智能监控系统的图像处理优化技术研究
2022-08-08何志超范余华沈斌涛
何志超,范余华,秦 川,沈斌涛
(1. 中国铁路上海局集团有限公司 南京铁路枢纽工程建设指挥部,南京 210000;2. 上海理工大学 光电信息与计算机工程学院,上海 200020)
随着铁路改革的不断推进,通过物联网、云计算、全景视频融合等技术提高铁路系统智慧程度和动态感知能力,对铁路客站的信息化发展具有重要意义。2021年,南京铁路枢纽工程建设指挥部在连云港—镇江高速铁路(简称:连镇高铁)扬州东站对建设铁路客站视频融合智能监控系统展开研究,实现将建筑物“掀顶式”透明显示,以便车站监管人员进行全局指挥及对突发事件快速处置。但在系统实际使用过程中,由于影像的获取条件、拍摄条件及拍摄角度等存在很大的差异性[1],给影像拼接工作带来很大困难。
深度学习算法尤其是卷积神经网络(CNN,Convolutional Neural Network)已在图像处理、目标检测等方向取得了较大成果。研究表明,利用CNN深度学习能够得到更好的特征描述能力[2],这给图像匹配算法的优化带来了新的思路。目前,图像匹配的主流方法是设计特征确定算法来提取特定的局部特征[3],通过比较从2幅图像提取的局部特征得到匹配结果。但这一方案选取的特征受算法参数影响大、抗干扰能力小,从而可能导致局部特征表述能力有限[4];另外,特征点的匹配通常采用线性距离作为相似性度量,难以适应匹配图像间可能存在的复杂变换关系[5]。对此,王红尧等人[6]提出改进特征描述子后进行图像拼接的方法,获得了较好的效果,但仍难以充分构建和利用特征与度量之间的关系。为解决以上问题,Zagoruyko等人[7]提出深度匹配方法,采用中心环绕双流网络和空间金字塔池化提升性能;Han等人[8]提出的匹配神经网络,采用3个全连接层组成的度量网络计算特征对的匹配分数,进一步提升了配对成功率;Balntas等人[9]提出PN-Net引入正负样本对,具有更高效的描述子提取及匹配性能,能显著减少训练和执行时间。
在铁路系统中,不同站点的摄像头布置各不相同,且具有环境复杂、样本量大等特点,本文深入研究了神经网络的图像呈现和比较方法,通过接收多台摄像机实时反馈的视频,对视频拼接参数进行检测,根据参数对多个视频的每一帧图像进行特征提取、特征匹配、投影变换、图像融合等处理,形成全景式优质图像,改进了基于神经网络特征表述的图像拼接技术,并将该技术应用于铁路客站视频融合智能监控系统,获得了更好的拼接效果。
1 模型设计
1.1 模型神经网络架构
模型结构包括切片层、CNN特征提取层、连接层、相似性度量层和Softmax层,如图1所示。
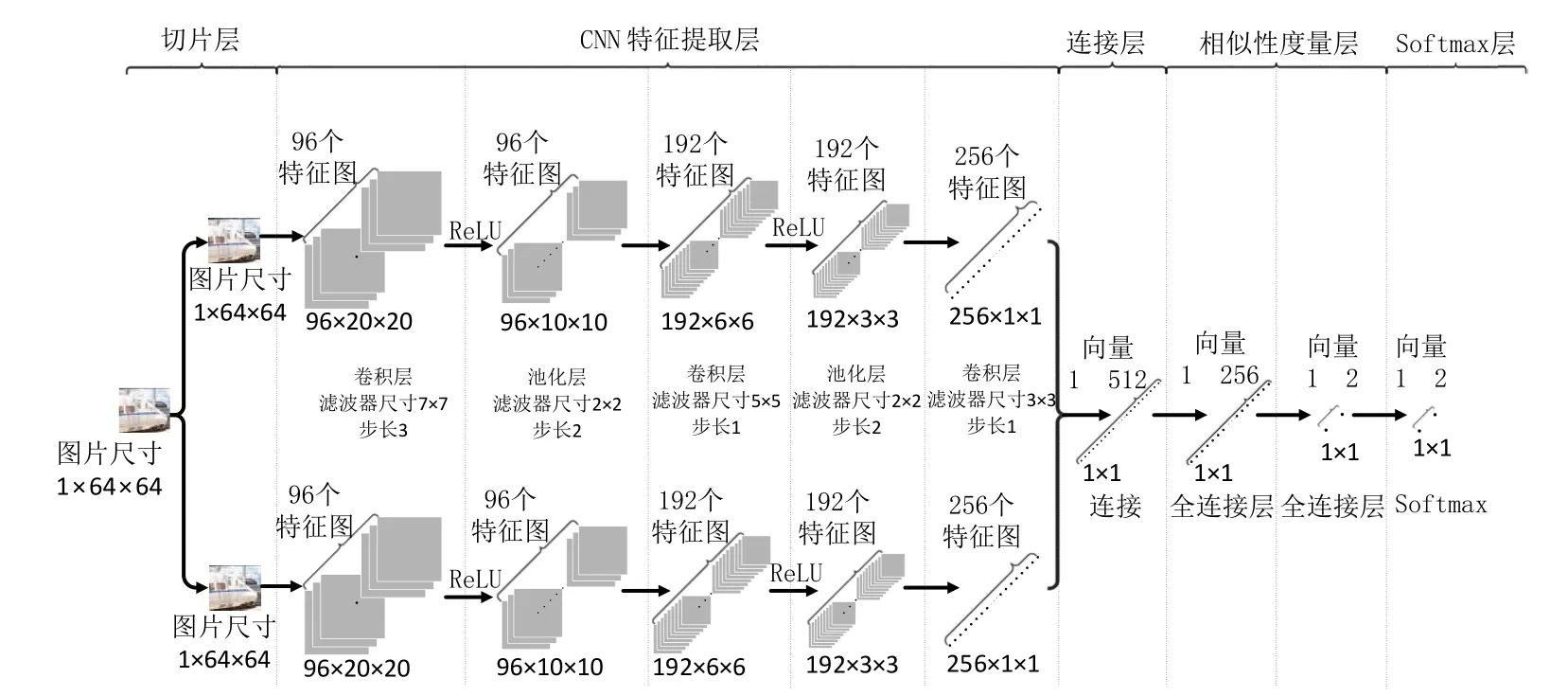
图1 神经网络结构
1.1.1 切片层
将神经网络的输入端设计为双通道,每个通道输入一张图像。在该层将训练样本中的2个图像块作为一对样本输入,而数据库中的样本经过不同的仿射变换,自身带有相似度标签,便于后续进行分类。切片层图片的格式为c·h·w,其中,c是图像数据的通道数,h是图像块的高度,w是图像块的宽度。输出特征图的格式为n·h·w,其中,n是卷积层中滤波器的数量。
1.1.2 CNN特征提取层
该层由2个并行的CNN特征提取网络组成,包括卷积层,池化层和非线性激励层,用于分别提取由切片层输出的不同图像块的特征。
(1)卷积层:对输入数据进行特征提取,通过卷积核遍历图片上的每一个像素点,乘以对应点的权重后求和,加上偏置后得到输出特征值。
例1 (2018年武汉中考第16题)如图1,在△ABC中,∠ACB=60°,AC=1,D是边AB的中点,E是边BC上一点.若DE平分△ABC的周长,则DE的长是________.
(2)池化层:去除杂余信息,简化计算复杂度,同时保证平移、旋转、伸缩等特征不变。本文选用最大值池化操作,随着滤波器滑动,窗口内的特征点只保留一个最大值。
(3)非线性激励层:选用线性整流函数(ReLU,Rectified Linear Unit),该函数使得输出为负数的神经元值转换为0,增加了神经网络各层之间的非线性关系,可缓解过拟合问题的产生。
1.1.3 连接层
用于连接2个CNN输出的特征向量,将不同特征提取模块输出的特征向量连接为一个特征向量输出,便于后续输入全连接层进行相似度分析。
1.1.4 相似性度量层
该层接收上层传来的特征向量,并投射为一个相似性度量值,由全连接层和非线性激励层组成。
1.1.5 Softmax层
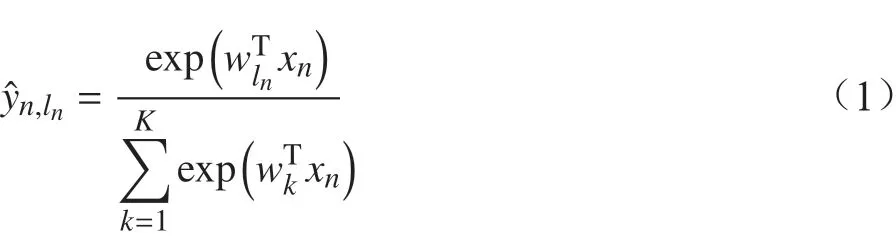
可得出训练过程中使用的代价函数为

其中,N是所有输入样本的数量;ln是输入样本xn所属类的标签;K是类的数目,即ln=1,2,···,K。
1.2 模型训练设置
本文选用 Brown数据库[10],随机选取30 000对图像块用于模型训练,10 000对用于模型测试。其中,训练集和测试集中均有60 %的相似对以及40 %的非相似对。同时,选用BP算法结合随机梯度下降法进行模型的迭代更新[11],在随机梯度下降过程中,学习率设置为0.01,动量设置为0.9,权重衰减指数为0.005。每次训练进行30 000次循环迭代。
2 图像配准
目前,图像配准法中广泛应用的是基于尺度不变特征变换(SIFT,Scale-Invariant Feature Transform)的传统方法,即通过构建高斯金字塔查找特征点,直接匹配关键点进行拉伸、旋转等操作完成配准。但SIFT算法无法很好地表示图像的高维语义,易造成颜色信息缺乏等问题[12]。
本文在使用SIFT确定初步特征点的基础上,对这些特征点周边的图像块进行提取并输入神经网络进行分析。通过CNN神经元局部连接的结构实现了深层次堆叠,可用于描述SIFT算法无法得到的高维特征,从而改进特征点的描述子,有效减少匹配畸形等问题[13]。
2.1 SIFT特征点提取
用SIFT算法提取特征点的流程如图2所示。将数据转换为灰度图像,通过高斯滤波平滑处理后降采样,得到高斯金字塔;推导出高斯差分金字塔,在高斯差分金字塔上对每个点周围的信息检测出极值点;筛选剔除不符合条件的极值点[14]。利用 SIFT确定特征点后,通过CNN提取以特征点为中心的图像块的深度特征,以此作为特征向量。

图2 SIFT特征点确定过程
2.2 整体匹配算法
对上文基于 CNN 表述的特征向量进行匹配,以获得匹配点对,其流程如图3所示。
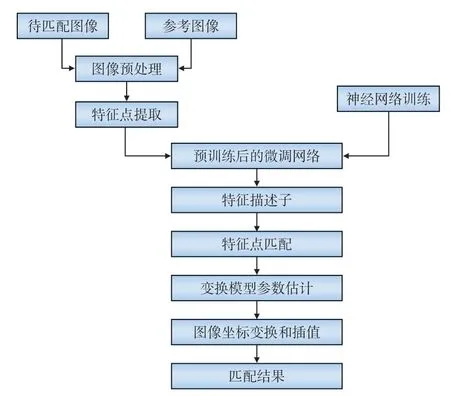
图3 整体匹配算法流程
(1) 提取待匹配图像和参考图像中的特征点,以特征点为中心裁剪 64×64 的图像块,输入预训练过的神经网络模型,经过多个交替的卷积层与池化层后,在高层全连接层得到可表示该图像特征的特征向量,作为CNN下该特征点得到的特征描述子[15];
(2) 根据得到的特征描述子对比待匹配图像与参考图像的特征点;
(3) 根据特征点匹配的结果完成变换模型和参数估计;
(4) 根据所得到的变换模型完成图像的坐标变换和插值, 得到匹配结果。
3 模型优化
3.1 匹配优化
本文使用随机抽样一致性算法(RANSAC,Random Sample Consensus)剔除错配点[16],算法流程如图4所示。
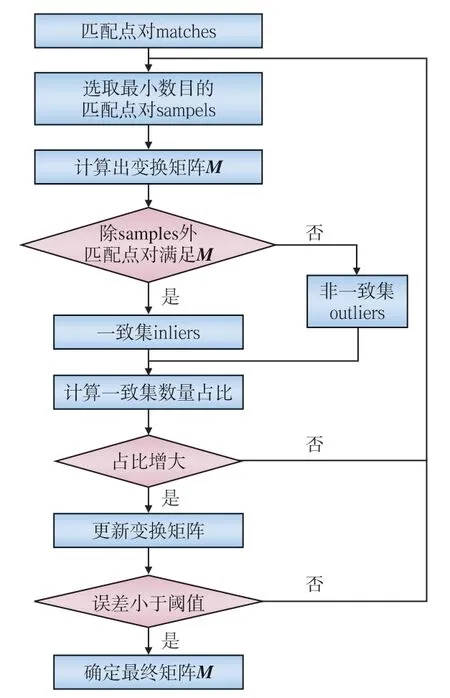
图4 RANSAC算法流程
(1)将整体匹配算法中获得的坐标点匹配点对记为matches;
(2)选取最小数目的初始匹配点对,记为samples,以此计算出变换矩阵M(CNN特征提取网络已经学习了噪声、模糊等不确定性对视频图像的影响,因此这里求解的变换矩阵用的是几何变换模型M);
(3)使用此矩阵去判定剩余匹配点对是否满足M,如果满足,则判定为一致集的数据,记为inliers,计算出一致集在总的匹配点对中的比例;
(4)判断一致集占比是否增大,并判断误差是否在阈值内,若满足则将此矩阵确定为最终结果;若不满足,则重新开始迭代。
3.2 虚影优化
虚影现象的去除是视频融合的关键[17]。多视角摄像机的相机质量差异及摆放的角度不同是造成虚影问题的主要原因。在图像拼接过程中,若视频序列中出现运动的物体,更容易造成虚影现象,影响最终拼接质量。去除运动物体所产生的虚影现象的算法流程如图5所示。
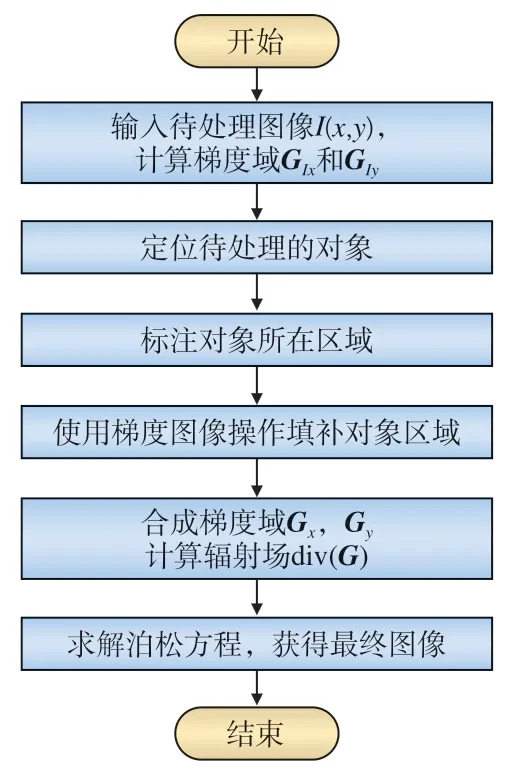
图5 虚影去除算法流程
(1)输入源图像I(x,y)并对输入图像进行梯度域计算从而构建一个梯度向量场。
(2)标注所有待移除虚影的邻域,并从源图像和梯度向量场中移除虚影对象。
(3)虚影初步填充。通过梯度域的区域填充操作,使用图像其他部分中能找到的最适合的部分来恢复这些区域。用这种方式获得一个填充到合成梯度向量场的域以及对应的一个初步填充完成的拼接图像If。

(5)用散度向量场作为指导向量来构造泊松方程。设待拼接图像为I(x,y),拉普拉斯算子为 r2,构建的泊松方程公式为
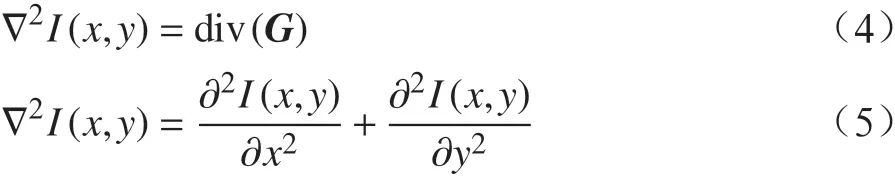
(6)通过求解泊松方程得到结果图像Ic。在处理这一线性偏微分方程的过程中,应用诺伊曼边界条件指定边界情况进行求解。使用图像If作为带入偏微分方程的初始值,这样可以获得更好的虚影去除效果[18]。新的拼接图像恢复后,将这个结果作为最后的拼接图像,解决全景图像拼接过程中运动物体产生虚影现象的问题。
4 实验例证
以连镇高铁扬州东站视频融合智能监控系统使用过程中产生的图像难以拼接以及融合结果畸变的问题为例,本节将传统图像拼接方法与本文提出的基于深度学习的图像融合方法进行对比。选取同一站台不同角度的2张像素分别为522×555和498×561的待匹配图像,如图6所示。2种方法所得到的拼接结果分别如图7和图8所示。可以看出,红色方框内出现了明显的图片失真情况。

图6 待匹配图像

图7 传统方案拼接图像

图8 本文方案拼接图像
本文通过计算特征点坐标的均方根误差(RMSE,Root Mean Square Error)比较算法的准确性。假设共有n个待计算的特征点,其RMSE 公式为
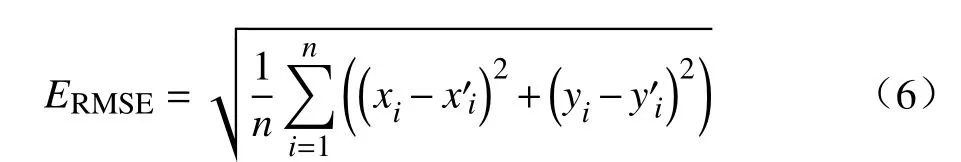
其中,(xi,yi)和(x0i,y0i)分别为待匹配图像与参考图像对应的特征点的坐标[19]。从Liberty数据集中随机抽取10 000张图片进行测试,传统方法下ERMSE=0.828,平均正确匹配特征点数为216,本文方法ERMSE=0.792,平均正确匹配特征点数为287。根据上述计算结果,本文的图像融合方法能获得更好的效果。
5 结束语
本文对基于SIFT的传统图像拼接方案进行了分析,针对实施过程中存在的高维特征缺乏等情况进行优化处理,提出了基于深度学习的图像拼接算法。利用深度学习提高特征描述子的能力,并辅以剔除错配点和去除虚影等算法优化操作。本文的改进算法解决了传统SIFT算法中误匹配对多、匹配结果仿射易失真的问题。经实验证明,改进后的算法对图像配准具有良好的效果。未来还将在平均运行速度和多场景适用性上对算法继续改进。
