中红外光谱和支持向量机的梅花鹿角帽粉假冒与掺假识别模型
2022-08-07杨承恩武海巍袁月明张爱武宋子洋
杨承恩, 武海巍*, 杨 宇, 苏 玲, 袁月明, 刘 浩, 张爱武, 宋子洋
1. 吉林农业大学工程技术学院, 吉林 长春 130118
2. 吉林农业大学食药用菌教育部工程研究中心, 吉林 长春 130118
3. 吉林农业大学动物科学技术学院, 吉林 长春 130118
引 言
鹿角帽又称鹿茸盘, 鹿角盘, 具有温肾补虚、 强筋壮骨、 活血、 下乳消散瘀等功效[1]。 鹿角帽质地坚硬, 一般是研磨为细粉服用。 近年来随着鹿药材市场的火热, 再加上鹿角帽本身是含有鹿茸成份的骨质物, 所以一些不良商家利用马鹿角帽粉与梅花鹿骨粉假冒梅花鹿角帽粉, 或用便宜的动物骨头粉, 特别是牛骨粉对梅花鹿角帽粉进行掺假来欺骗消费者。 消费者很难从外观上去识别, 因此有必要研究梅花鹿角帽粉的质量检测方法, 规范鹿角帽市场。
傅里叶变换红外光谱(Fourier translation infrared spectroscopy, FTIR)技术是一种高效, 环保, 可实时在线解析的方法。 目前, 红外光谱分析已经成为发展最快、 最引人瞩目的一门独立分析技术[2-3], 其在中药材检测方面具有广泛的应用前景[4]。 孙飞等通过红外光谱对姜半夏进行识别[5]; 张久旭等利用红外光谱显微成像识别当归粉末[6]; 郑洁等利用红外光谱图像对苦杏仁和桃仁药材进行鉴别[7]。 目前国内外使用中红外光谱对鹿角帽的检测研究进展不多, 存在以下不足: (1)实验得到的光谱图像没有经过处理而是直接进行人为的与以自身规定的标准光谱对比, 需完全一致才确定是正品。 (2)若相似或有较小区别还需进行其他人为实验对比。 (3)没有对市场上鹿角帽粉的假冒和掺假问题进行研究。 (4)中红外光谱本身很难具备一模一样的光谱重复性, 测试精确度要求很高, 不适应现在鹿角帽市场要求的高效, 快速, 准确检测特点。
找到一种高效, 快速, 准确的梅花鹿角帽粉质量在线检测方法是鹿角帽市场急需解决的关键问题。 本研究采用中红外光谱以梅花鹿角帽粉为正品鹿角帽粉, 马鹿角帽粉与梅花鹿骨粉为假冒伪品, 牛骨粉掺假梅花鹿角帽粉为掺假次品作为研究对象, 采集它们的光谱数据, 对数据进行多元散射校正(multiplicative scatter correction, MSC)处理[8], 并把MSC全光谱(FS)数据采用归一化和主成分分析(principal component analysis, PCA)进行优化[9], 最后将全光谱(FS)数据与进行主成分分析(PCA)后的光谱数据, 二者结合支持向量机(support vector machine, SVM), 随机森林(random forest, RF), 极限学习机(extreme learning machine, ELM)建立模型进行判别比较[10-11], 得出最优识别模型, 从而实现对梅花鹿角帽粉假冒与掺假的快速、 无损检测。
1 实验部分
1.1 材料与设备
样品梅花鹿角帽, 马鹿角帽, 梅花鹿骨采购于黑龙江, 吉林, 辽宁3省共5个地区, 样品分布如表1, 牛骨采购于长春市南关区农贸市场。 将以上材料烘干、 粉碎, 过200目筛供光谱测试用。 将纯梅花鹿角帽粉与纯马鹿角帽粉, 纯梅花鹿骨粉样品各120份, 共360份。 再将5个地区纯梅花鹿角帽粉与牛骨粉制备掺假样品, 比例分别为5%, 10%, 20%, 30%, 40%和50%, 每个地区每种比例4份, 共120份掺假样品。
主要设备: Nicolet is10 傅里叶变换红外光谱仪(美国Thermo scientific), HY-12型压片机(天津天光光学仪器有限公司), CS-700型超帅高速多功能粉碎机(武义海纳电器有限公司), 200目不锈钢筛等等。
数据采用Omnic v8.2光谱采集软件、 The unscrambler x 10.4、 Matlab2014b、 Origin2019b、 Python3.7数据处理软件进行处理。

表1 鹿材料样品采集信息
1.2 数据采集
精密称取每份待测样品1.8 mg和溴化钾190 mg将其放置在75 ℃恒温干燥箱内烘8 h以后取出, 置于玛瑙研钵中研磨均匀; 将研细后的粉末平铺于红外压片模具中压制成片, 将制好的薄片置于中红外光谱仪上, 采用Omnic v8.2软件采集光谱信息。 波数范围4 000~400 cm-1, 分辨率为4 cm-1, 扫描次数为16次, 每个样本重复扫描3次, 取平均光谱。 光谱采集过程中, 保持室内温度25 ℃, 湿度40度。 实验采集梅花鹿角帽粉假冒对比样品360份, 掺假样品120份, 共计480份样品数据。
1.3 数据预处理
光谱信息易受高频随机噪声、 基线漂移和光散射等影响, 需对原始光谱进行预处理, 减少这些干扰。 采用The unscrambler x 10.4软件对采集的原始光谱进行多元散射校正(MSC), 标准正态化(standard normal variable transformation, SNV), 平滑(smoothing, SG), 一阶导数, 二阶导数等数据处理, 再与原始光谱进行对比。
2 结果与讨论
2.1 光谱分析
经过光谱对比, 可看出经过多元散射校正(MSC)处理的光谱差异性更为明显如图1。 在中红外光谱中特征峰是判断光谱区别的主要方式[12-13]。 由图1可以看出梅花鹿角帽粉正品与假冒伪品, 掺假次品在波段1 300~1 800和2 800~3 600 cm-1波峰有一定差异。 尤其是掺假比例达到10%以上的梅花鹿角帽粉与纯梅花鹿角帽粉有着明显差异, 但掺假10%的梅花鹿角帽粉与马鹿角帽粉差距不大。
2.2 样本集划分
对MSC光谱数据进行样品划分, 在数据选择上使用Kennard-stone(K-S)法抽样, 将训练集与测试集比例定为3∶1进行划分480份样品, 得训练集360份(梅花鹿角帽粉, 马鹿角帽粉, 梅花鹿骨粉, 牛骨粉掺假鹿角帽粉各90份)。 测试集120份(梅花鹿角帽粉, 马鹿角帽粉, 梅花鹿骨粉, 牛骨粉掺假鹿角帽粉各30份)。 此处牛骨粉掺假鹿角帽粉样品按掺假比例划分, 其中每种比例20份, 训练集15份, 测试集5份。
2.3 降维方法
中红外光谱是有机物和无机离子的基频吸收带, 是分子吸收能力最强的振动谱区。 中红外光谱数据的特点是波段多、 数据量大、 冗余性强。 因此需要对MSC光谱数据进行处理。 使用matlab2014b软件中的Map minmax函数把光谱数据进行归一化处理, 将数据映射到0~1范围内如图2[14]。

图1 样品红外光谱图

图2 归一化后的不同样品平均光谱图
主成分分析(PCA)是将高维度数据保留下最重要的一些特征, 去除噪声和不重要的特征, 从而实现提升数据处理速度的方法。 这里将归一化后的光谱数据采用基于python3.7平台pandas库中的PCA函数进行主成分分析降维。 此处展示MSC全光谱训练集前10个主成分特征值和贡献率如表2。 在MSC全光谱中PCA1的贡献率最大为51.75%, PCA2的贡献率为18.94%, 前3个PCA的累积贡献率为82.49%, 直到前7个PCA的累积贡献率为97.81%, 之后的各PCA贡献率都小于1%且累积贡献率提高速度逐步变小。 MSC全光谱主成分分析降维后的训练集第一, 第二主成分得分散点图, 如图3。
主成分个数选择极大的影响算法建模结果。 这里采用主成分个数累积贡献率≥85%原则结合主成分特征值≥1原则, 选择经PCA降维后的前7个主成分。 将光谱数据从480行7 469列, 降低为480行7列, 极大减少数据冗余, 提高建模识别效率。

表2 训练集的主成分总方差解释

图3 训练集前2个主成分的得分
2.4 算法建模结果
直接使用中红外原始光谱数据建模可能会模型性能差、 效率低, 但另一方面数据降维也会减少样品信息, 可能损失关键性特征影响建模效果。 为了更好对比光谱特征的选择, 此处分别将全光谱(FS)数据与经PCA降维后的前7个主成分光谱数据作为输入变量, 建立SVM, RF和ELM梅花鹿角帽粉假冒与掺假识别模型。 图4—图6是不同模型对训练集梅花鹿角帽粉假冒与掺假识别结果; 图5和图6中, 1代表梅花鹿角帽粉, 2代表马鹿角帽粉, 3代表梅花鹿骨粉, 4代表牛骨粉掺假梅花鹿角帽粉。
2.4.1 SVM模型
SVM是一种有坚实理论基础的小样本学习方法。 其适用于小样本的数据分析, 在实际运用中总能取得不错的效果。
训练集使用K-CV交叉验证法, 同时SVM需要确定最佳惩罚因子(c)、 核函数参数(g), 及最优核函数。 这里采用网格搜索法来寻找最优参数c和g, 选择径向基核函数(radial basis function, RBF)作为最优核函数。 分别建立基于FS与PCA数据的SVM识别模型如图4, 表3。

图4 SVM的训练集参数寻优曲线
表3 SVM的测试集识别结果
由图4, 表3可知, FS-SVM, PCA-SVM训练集和测试集识别率均为100%, 但是FS-SVM建模识别时间为4 859.36 s, PCA-SVM建模识别时间仅为19.91 s。 综合比较, PCA-SVM模型效果更好。
2.4.2 RF模型
RF是以集成学习思想为核心的分类、 回归算法。 其具有实现简单, 计算消耗少, 泛化误差小的特点, 能够有效提高对新样本的分类准确度。
RF模型需要确定参数较多, 参数选择又直接影响模型精度, 设置合理参数可以显著提升模型的分类准确性。 这里利用遗传算法优秀的全局寻优能力来寻找RF模型最优参数。 分别建立基于FS与PCA数据的RF识别模型如图5, 表4。

图5 RF的训练集建模识别结果

表4 RF的测试集识别结果
如图5, 表4可知, FS-RF与PCA-RF建模时间分别为1 818.96和16.93 s, 二者训练集识别准确率为100%, 但PCA-RF测试集识别率为96.67%, FS-RF测试集识别率为100%。 在测试集中, PCA-RF模型将4份梅花鹿骨粉识别错误。 整体来说, FS-RF模型识别率高于PCA-RF模型。
2.4.3 ELM模型
ELM是基于前馈神经网络的基础上, 巧妙地将隐含层个数与样本个数进行联系, 建立全新的单隐藏层前馈神经网络。 其解决人工神经网络训练时间较长的缺点, 是一种学习速度快, 泛化性能好的算法。
在ELM模型中, 隐藏节点的设置直接影响建模结果。 这里选择sigmoidal函数作为激活函数, 隐含层神经元个数为1~480, 步长为1。 分别建立基于FS与PCA数据的ELM识别模型如图6, 表5。
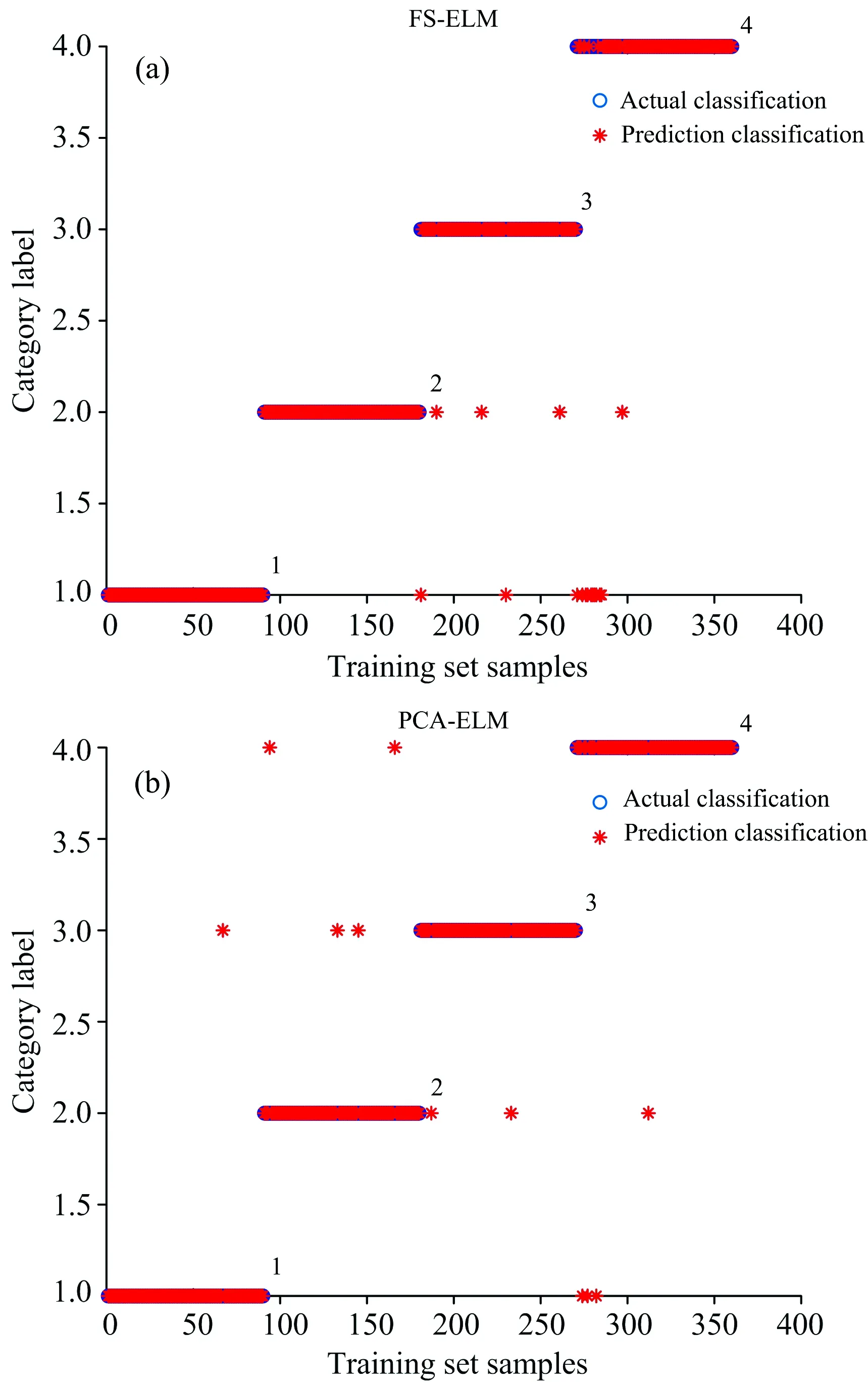
图6 ELM的训练集建模识别结果

表5 ELM的测试集识别结果
由图6, 表5可知, 当隐含层神经元个数为381, FS-ELM模型识别效果最好, 建模时间为1 985.39 s, 训练集识别率为95.56%, 将1份马鹿角帽粉与4份梅花鹿骨粉, 11份牛骨粉掺假梅花鹿角帽粉识别错误; 测试集识别率为95.83%, 将1份梅花鹿角帽粉, 4份牛骨粉掺假梅花鹿角帽粉。 当隐含层神经元个数为420, PCA-ELM模型识别效果最好, 建模时间为15.93 s, 训练集识别率为96.94%, 将1份梅花鹿角帽份与4份马鹿角帽粉, 2份梅花鹿骨粉, 4份牛骨粉掺假梅花鹿角帽粉识别错误; 测试集识别率为97.5%, 将1份梅花鹿角帽粉与1份马鹿角帽粉, 1份牛骨粉掺假梅花鹿角帽粉识别错误。 综合来说PCA-ELM模型优于FS-ELM模型。
3 结 论
使用中红外光谱结合支持向量机对梅花鹿角帽粉假冒与掺假进行识别。 结果显示:
(1)同样建模的参数和环境下, FS-SVM, FS-RF, FS-ELM建模时间分别为4 859.36, 1 818.96和1 985.39 s, 而PCA-SVM, PCA-RF, PCA-ELM建模时间为19.91, 16.93和15.93 s。 说明利用PCA降维后的光谱数据建模时间远低于FS数据建模时间, 提高了建模识别的效率。
(2)FS-SVM, PCA-SVM, FS-RF模型训练集与测试集识别率均为100%, 其他模型识别率均低于98%。 但从简化模型的效果上来看PCA-SVM模型最优, 既保证了100%的识别率又提高了建模速度。
(3)利用中红外光谱结合支持向量机对梅花鹿角帽粉假冒与掺假有着良好的识别效果, 为解决鹿角帽的质量控制问题提供了新思路, 可以进一步推广应用于其他类型鹿药材的快速鉴别。
