科研行为主体信用评分卡技术研究
2022-08-06刘君亮
刘君亮,毛 阳
(北京交通大学,北京 100044)
信用有广义、狭义之分。广义的信用从社会道德层面上表现为自觉遵守社会规则或人与人之间的约定。现代市场经济条件下的信用概念是狭义的信用,狭义的信用是指建立在信任基础上,不用马上付款或担保就可获得资金、物资或服务的能力。科研信用是广义社会信用在科研管理领域应用的产物,主要是指从事科研活动人员的职业信用,是对科研人员在从事科研活动时遵守正式承诺、履行约定义务、遵守科研界公认行为准则的能力和表现的一种评价。随着国内科研投入逐年增加,科研项目和论文的产出也逐年递增,但同时科研人员学术不端的案例也在逐渐增多,为了保障国家的科研环境和声誉,科研诚信建设研究急需加强。
国内科研信用研究多采用专家打分法、AHP 和模糊综合评价法进行信用评价,常用的个人信用评价模型方法研究主要集中在金融信贷领域,在科研人员信用研究方面较少。信用评分卡模型是一种成熟且广泛应用于金融风险控制领域信用风险评估的模型方法,其原理是将模型变量WOE 编码方式离散化之后运用Logistic 回归模型进行的一种二分类变量的广义线性模型。利用信用评分卡技术建立基于科研人员信用大数据的信用评价模型,从而将科研人员信用信息转化为科研信用评价依据,可以解决铁路科研活动中的信息不对称问题,既可以为铁路科研项目的审核提供依据,也可以促进科研人员信用水平透明化,有利于对铁路科研诚信问题进行统一规范与治理,因此深度挖掘科研人员信用信息,开发基于信用大数据的科研人员信用评分卡模型,具有十分重要的理论和现实意义。
1 科研人员信用指标体系
对科研人员信用数据进行建模之前,需要解决科研人员信用量化指标的选取问题,科研人员信用量化指标需要用数值型指标或分类型指标抽象出一个科研人员的科研信用信息全貌,通过查阅国内外文献和相关政策文件,得到科研人员信用量化指标可分为两类,一类是科研人员科研资历信用指标,另一类是科研人员科研历史信用指标,具体指标见表1。

表1 科研人员信用量化指标
2 数据预处理
在用数据进行建模之前还需对科研人员信用数据进行预处理,使数据满足建模的要求,数据预处理主要的技术环节如下。
2.1 样本数据的获取
从相关科研数据库获取科研人员信用指标的相关数据。
2.2 数据清洗
数据清洗是指将获取的原始数据转化为可用作模型开发的格式化数据,首先是缺失值处理。缺失值处理通常有两种处理方法,直接删除含有缺失值的样本或者是根据样本之间的相似性或者相关关系填补缺失值。
缺失值处理完后进行异常值的处理。异常值是指某些样本明显偏离大多数样本数据,比如科研人员的年龄为0 时,通常认为该值为异常值。异常值的检测一般采用箱线图。
2.3 探索性数据分析
在建立模型之前,我们通常会对数据进行探索性数据分析,该步骤的目的是了解样本数据的大概总体情况,即对已有的数据在尽量少的先验假定下进行探索。常用的探索性数据分析方法有直方图、散点图和箱线图等。
2.4 指标的分箱和编码
把变量进行分组处理,即分箱或者离散化,之后用WOE(Weight of Evidence)进行编码,作用在于对指标进行分箱和编码,不仅可以避免指标无意义的波动给预测带来的波动,还能避免极端值的影响。WOE 的计算公式为:
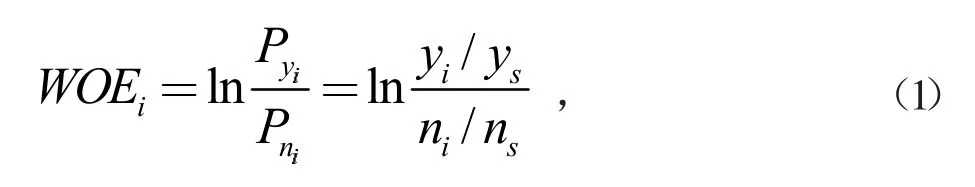
其中,yi代表第i 组失信科研人员数量,ys代表所有失信科研人员数量,ni代表第i 组没有失信科研人员数量,ns代表所有没有失信科研人员数量,WOE 表示的含义即是“当前分组中失信科研人员占所有失信科研人员的比例”和“当前分组中没有失信科研人员占所有没有失信科研人员的比例”的差异。计算得出WOE 后自变量指标可用WOE 值编码取代。
3 信用模型建立
理想的科研人员信用评价模型应该是可以输入所有的有关该科研人员信用的各方面维度的特征,并预测出科研人员所属于的类别,即科研人员是否会失信。Logistic 回归模型主要用来计算一组自变量与离散型因变量间的关系,应用在个人信用评价方面有比较高的精准度,常用于信用问题的二分类预测。离散型因变量是指取值为0,1,2……等离散值的变量,在个人信用评估的内容中,因变量是取值分别为0 和1 的二元变量,通常用y 表示,当科研人员出现失信行为记为y=1,没有出现失信行为则记为y=0。
考虑具有m 个独立向量的向量x=(x1,x2,x3,…,xm),设条件概率P(y=1|x)。
为根据观测量相对于某事件发生的概率,Logistic模型可以表示为:
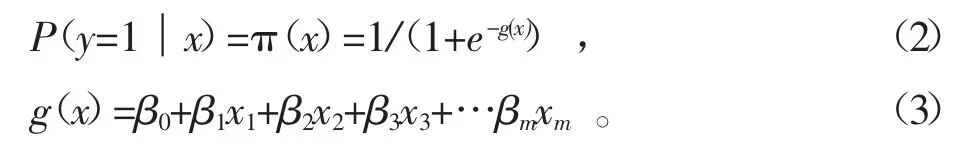
在x 条件下,y 不发生的概率(即y=0)的概率为:
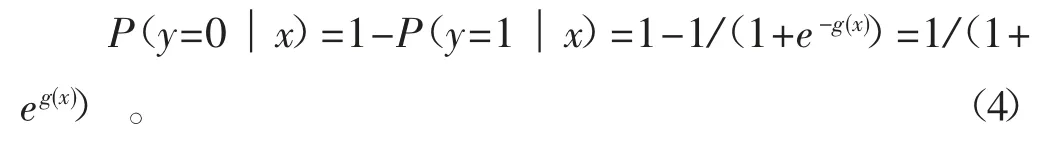
所以,科研人员失信与科研人员不失信的概率之比为:
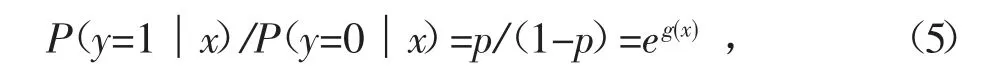
这个比值记为优势比,实际上可以认为是失信人与非失信人的发生比。对其取自然对数,则得到:
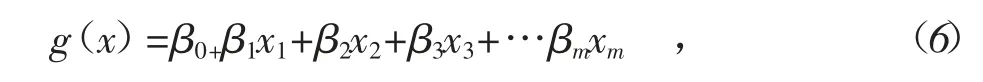
Logistic 回归模型最终的目的是要求解β1,β2,…,βm这组权值,而β1,β2,…,βm的估计,则需要使用极大似然估计来进行。
4 模型分析
4.1 性能验证
模型性能的验证,是信用评分卡模型开发的十分重要的一个环节,常见的技术方法是ROC 曲线。ROC曲线的全称是受试者工作特征曲线(Receiver Operating Characteristic curve),又称感受性曲线(sensitivity curve),是随着检测阈值变化的检测概率对假报警概率的关系曲线,设某概率值P 作为阈值,如果小于阈值则判断为“失信人”,大于阈值则判断为“非失信人”,计算基于概率值P 的TPR 和FPR,TPR 为真阳性率,是样本中模型正确判断为“失信人”的人数占所有实际为“失信人”的人数的比例,FPR 为伪阳性率,是样本中模型错误判断为“失信人”的人数占所有实际为“非失信人”的人数的比例,接着调整阀值P,得到阈值不一样时的TPR 和FPR,把TPR 当作纵轴,FPR 为横轴,得到的ROC 曲线图如图1 所示。
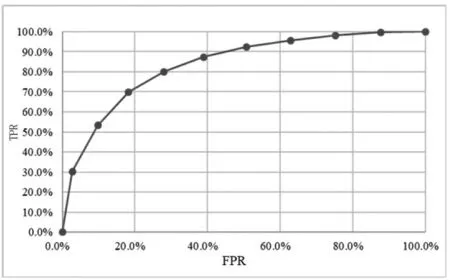
图1 ROC 曲线图
ROC 曲线朝左上角凸的越多,曲线下面积AUC(Area Under Curve)越大,就代表这个模型效果越好,可以计算ROC 曲线下面积即AUC 来量化分类模型的性能。AUC 的值在0 到1 之间,当分类模型为一个完全随机模型时ROC 为一条直线,此时AUC=0.5,所以通常具有实用价值的分类模型的AUC 值会大于0.5,优秀模型的AUC 值通常为0.7 到0.9 之间,如果分类模型的AUC 值在0.9 以上,可能是异常变量使得AUC值偏高。
4.2 评分转换
Logistic 回归模型的结果是回归式,其模型输出结果是科研人员失信与否概率比值的对数值,不易于理解和掌握,实际应用中必须把概率转换为信用分数,主要方法为对科研人员失信与否概率比值的对数值进行线性变换再加上一个常数,使得最终的信用评分落在一个事先设定好的分数范围内,分数越高,科研人员的信用越好,转换公式为:
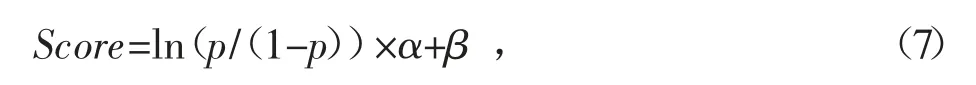
其中,p 表示科研人员失信概率,α 表示线性变换的系数,通常包括一个对数值,β 表示调整常数,使得最终的信用评分落在目标分数范围内。
5 应用展望
通过以上方法建立的科研人员信用评分卡模型,可以在以下方面进行广泛应用。
5.1 科研项目基金审批自动化
随着科研人员科研信用数据的积累以及大数据模型技术和科研信用制度的融合普及,科研人员信用评分卡模型技术可更加广泛地在铁路科研项目和相关科研基金的审批中应用,从科研人员信用的角度为科研项目和基金课题的审批决策提供重要的支持,对于评分低于一定级别的,可以自动拒绝其申请,只有通过信用评分的才能进入人工审核阶段,不但有助于事前降低潜在的科研失信风险,还能提高铁路科研项目和基金课题的审核效率。
5.2 科研信用风险预警精准化
信用评分卡模型技术基于科研人员信用大数据,不仅比起传统的专家打分和人工审核等主观审核方法更加客观,保证了信用评价的公正性,同时评价准确度更加灵敏和精确,提高了铁路科研信用风险预警的精准度。
5.3 科研人员信用水平透明化
信用评分卡模型得出的科研人员信用评分客观透明,可以促进科研人员信用水平透明化,提高科研人员信用意识,还能准确识别风险的原因和来源,方便科研管理者采取针对性的预防措施,有利于对铁路科研诚信问题进行统一规范与治理。
