农产品标准领域知识图谱实体关系抽取及关联性分析
2022-08-06吕东东陈俊华毛典辉张青川郝治昊
吕东东,陈俊华,毛典辉※,张青川,赵 敏,郝治昊,4
(1.北京工商大学农产品质量安全追溯技术及应用国家工程实验室,北京 100048; 2.北京工商大学食品安全大数据技术北京重点实验室,北京100048; 3.中国标准化研究院标准化理论战略研究所,北京100088; 4.澳门大学智慧城市物联网国家重点实验室,澳门 999078)
0 引 言
农产品安全关系到人民群众身体健康和生命安全,中国政府出台了实施农产品安全战略的纲领性文件《中共中央国务院关于深化改革加强食品安全工作的意见》,指出要加快建立农产品安全领域现代化治理体系,提高从农田到餐桌全过程的监管能力,提升农产品全链条质量安全保障水平。农产品标准作为衡量农产品安全的尺度与农产品安全监管的重要依据,在农产品全链条质量安全保障中发挥着举足轻重的作用。当前农产品标准及相关词条过于分散化,往往以信息孤岛的形式存在,没有得到系统性的关联与复用,知识图谱能够将农产品标准及其各类信息连接形成一个关系网络,从而为人们提供从“关系”角度分析问题的能力。因此凭借智能语义分析与知识图谱技术,将海量农产品领域数据与知识图谱关联,逐步形成基于农产品标准领域知识图谱的监管辅助分析手段十分必要。
农产品领域知识图谱相关研究工作主要分为作物与制品两个主题,作物主题主要围绕科普、病虫害防治及预测为目标进行知识构建;制品主题主要围绕农产品制品安全主题新闻、农产品及其制品中的仅限用物质限量、农产品标准的相互引用关系等展开。其最终目标是实现农产品安全领域知识图谱的本体构建、实体关系抽取以及基于知识图谱的下游任务农产品安全领域问答系统、推荐系统、社区网络挖掘等。当前农产品标准领域知识图谱构建研究存在标准文件内容繁杂以及内容格式不统一(如国家标准、行业标准、地方标准等)等问题,从而对图谱实体关系抽取造成了极大不便。
在实体关系抽取相关研究工作中,限定域关系抽取研究方法主要分为Pipeline方法与联合抽取方法,基础分析模型主要有循环神经网络(Recurrent Neural Network, RNN)、长短期记忆网络(Long Short-Term Memory, LSTM)、源自转换器的双向编码器表征向量(Bidirectional Encoder Representation from Transformers, BERT)以及上述网络与条件随机场(Conditional Random Field, CRF)的组合等。Pipeline方法是将实体关系抽取分解为命名实体识别与关系分类任务;而联合抽取方法主要是考虑命名实体识别与关系分类之间的约束,如CASREL模型,其先识别语料中的主语,然后共享主语信息同时识别对应的客体及关系。在开放式关系抽取领域,国外已经发展出了诸如ReVerb、RnnOIE等系列高性能模型,而国内发展相对缓慢,文献[30]通过分析语义进而提出ZORE开放关系抽取模型,其通过双重传播算法迭代地识别语义关系模式,文献[31]基于依存句法分析提出了一套通用的关系抽取范式DSNFs。上述的开放域关系抽取模型在公共数据上均表现良好,但在领域数据上表现差强人意,主要原因是领域数据有较强的领域特性,词法句法均与公共数据存在较大差异。若要在领域数据上取得好的效果,传统基于深度模型的限定域关系抽取方案需要重新引入大量领域标注语料进行训练;而基于依存句法分析的开放关系抽取方案只需标注少量的初始化种子或定义少量抽取模板,并具有较强的迁移能力,对领域数据处理更为适用。
因此,本研究针对现有农产品标准文件难以关联复用及知识图谱构建过程面临的文件格式不统一、信息抽取困难等问题,依据标准化文件的起草规范对文件内容进行了本体规范化,并为半结构化数据设计了正则包装器,为非结构化文本提出了一个基于依存句法分析的农产品领域开放关系抽取模型(Open Relation Extraction Model In Agricultural Products Field, OREM-AF),实现了领域知识自动抽取。依托抽取数据构建了农产品标准领域知识图谱,并在知识图谱的相互关联网络上进行了社区挖掘,获得的标准文件间的关联知识能够为农产品安全监管提供辅助分析支撑。
1 农产品标准实体关系模式层构建
1.1 数据获取
农产品标准领域数据主要由农产品标准文件与百科数据两部分构成。其中标准文件来源于食品标准伙伴网(http://down.foodmate.net/standard/)与中国食品安全标准网(http://www.cnspbzw.com/);百科数据来源于百度百科相关农产品介绍页;模型训练的公共语料源自影评及新闻,公共数据用于测试模型的泛化能力。具体数据构成见表1所示。
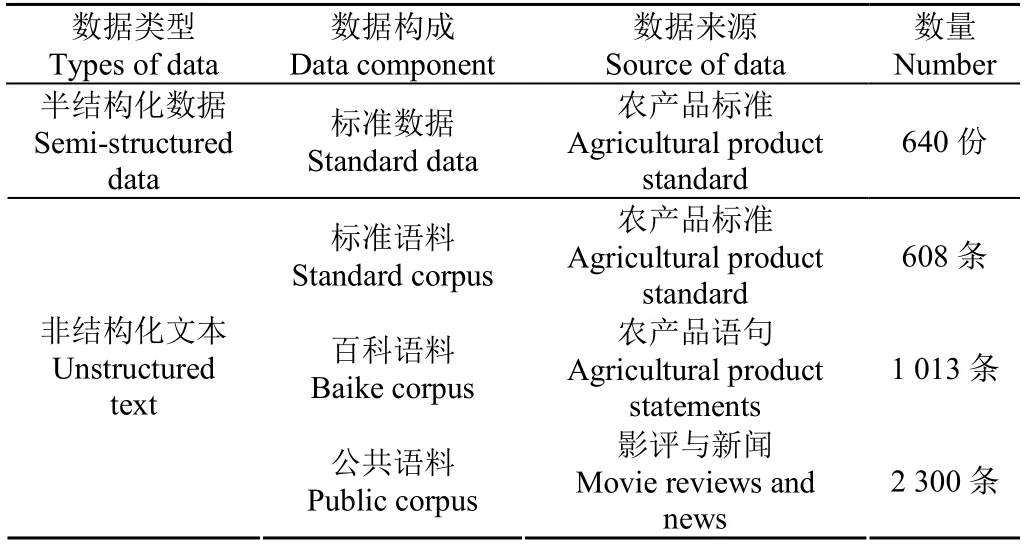
表1 数据构成表 Table 1 Table of data components
1.2 农产品标准本体规则构建
本体规则构建是知识图谱实体关系抽取的核心工作之一。在农产品科普内容中,公众较为关注的信息有:农产品的科、属、别称、分布地区及相应的功能效果。在农产品标准文件中,大家较为关注的信息有:1)规范性引用信息:大部分标准文件的描述信息中会引用其他标准文件,以GB/T 29370-2012(柠檬)为例,其卫生指标描述为“按GB 2762、GB 2763规定执行”,这些规范性引用标准是形成标准图谱网络结构的基石;2)适用范围信息:该部分能直观给出具体的适用品类或相关操作。以国家标准GB 9827-1988(香蕉)为例,其适用范围描述为“本标准适用于香蕉果品的条蕉、梳蕉的收购质量规格”,可知该标准文件不仅适用于条蕉的收购质量规格,也适用于梳蕉的收购质量规格;3)标准基础属性信息:该部分包含标准文件名称、发布时间、实施时间、主要起草人、起草单位、归口单位等信息。
本文结合标准化文件的起草规范将农产品标准及相关百科词条关系模式分为16类,具体类别如表2所示(以金桔相关词条及其相关的推荐性国家标准GB/T 33470-2016部分信息为例)。
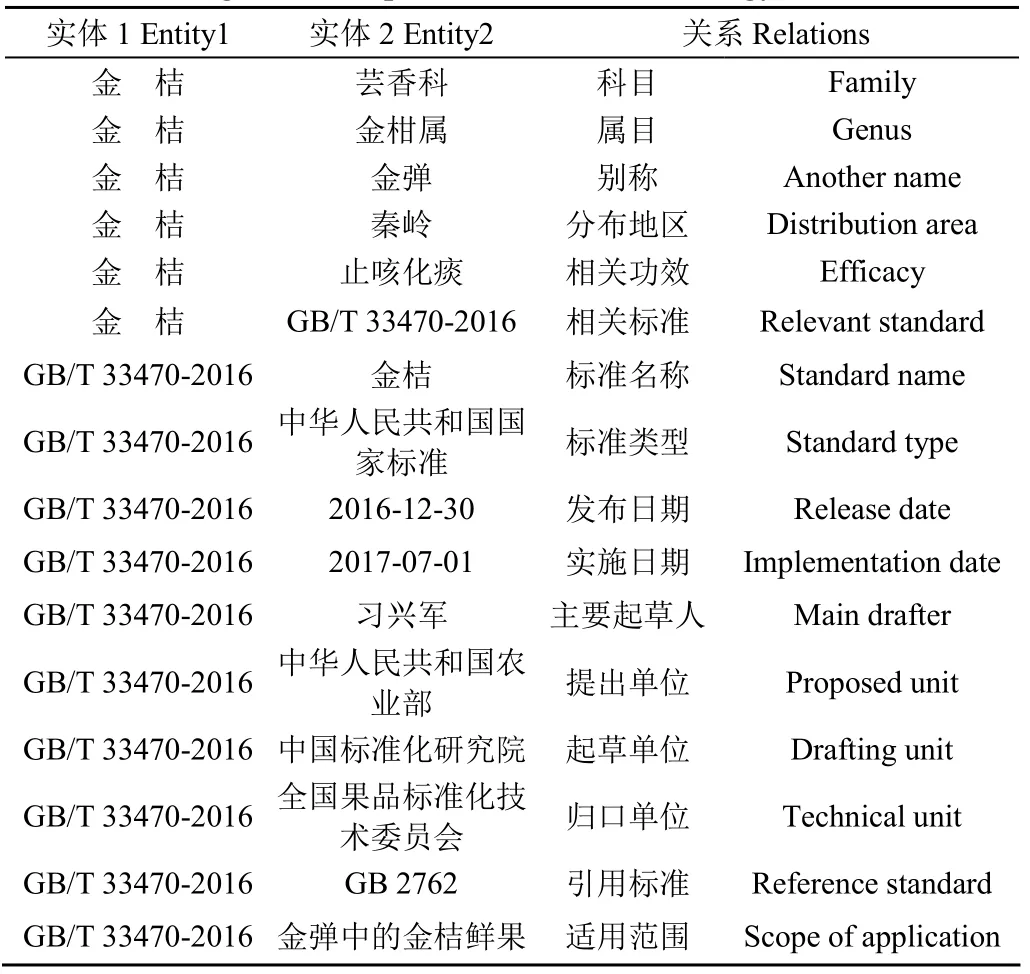
表2 农产品标准本体关系规则 Table 2 Agricultural product standard ontology relation rules
2 农产品标准领域图谱知识抽取
2.1 农产品标准半结构化知识抽取
在表2中,实体关系为Standard name、Standard type、Release date、Implementation date、Main drafter、Proposed unit、Drafting unit、Technical unit的属性关系以及实体关系为Reference standard的相互引用关系内容主要以半结构化数据形式存在于标准文件首页及文件头部,如图1所示。

图1 农产品标准半结构化数据 Fig.1 Semi-structured data of agricultural products standard
本文依据标准化文件的起草规范,通过构建正则包装器来抽取半结构化数据实体关系。以标准GB/T 5835-2009(干制红枣)为例,其中有“本标准由中华全国供销合作总社提出。本标准由中华全国供销合作总社济南果品研究院归口”。依据该表述格式制作正则表达式可从中抽取出两个三元组:(GB/T 5835-2009,提出部门,中华全国供销合作总社)、(GB/T 5835-2009,归口部门,中华全国供销合作总社济南果品研究院)。
2.2 农产品标准非结构化知识抽取
在表2中,实体关系为Family、Genus、Another name、Distribution area、Efficacy、Relevant standard、Scope of application的内容主要以标准文件及百科信息中的非结构化文本形式呈现,这类文本与关系抽取领域常见的语料相比,具有主体单一、客体分布密集以及客体存在多并列关系特征。针对此类特征,本文提出了一个基于依存句法分析(Language Technology Platform,LTP)的农产品领域开放关系抽取模型(OREM-AF)实现非结 构化文本实体关系抽取。依存句法分析的作用是识别出句子中的短语结构以及短语之间的层次句法关系,具体的关系种类见表3所示。其工作流程首先将语料进行分词,接着对词汇进行词性标记,最后将词汇及词性送入LTP中得到语料的依存句法结构,以标准GB/T 9827-1988(香蕉)为例,其中有“本标准适用于香蕉果品的条蕉、梳蕉的收购质量规格”,该语句经依存句法分析后如图2所示。
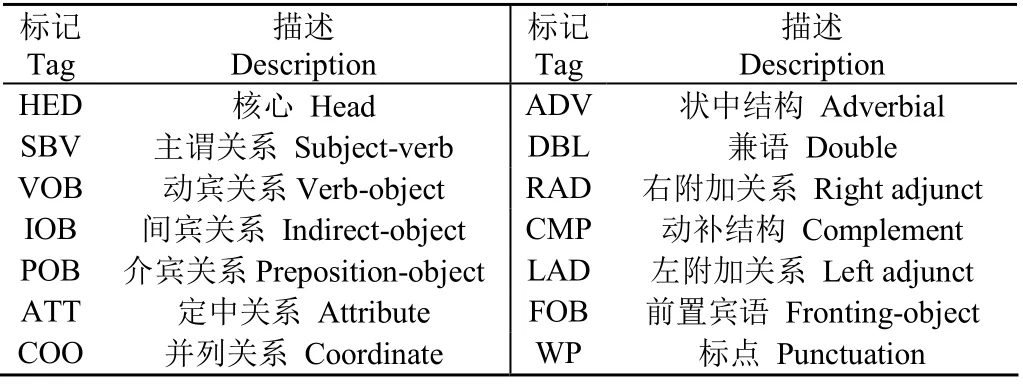
表3 依存句法关系表 Table 3 Dependency syntactic relation table

图2 依存句法分析示例 Fig.2 Example of dependent syntactic analysis
进行非结构化文本实体关系抽取时,本文需要结合该领域语料特征、语料依存句法分析结构树并依据表2中的本体关系规则进行三元组标注,具体的标注方式如下:1)由专业人员依据本体关系规则标注出语料中存在的三元组;2)通过LTP工具解析语料的依存句法分析结构树,根据步骤1)中标注的三元组及结构树标注出不含ATT定中关系的伪三元组;3)将三元组与伪三元组以(关系,伪宾语,宾语,伪主语,主语)五元组的形式合并。以图2为例,根据上述步骤最终标注的五元组为(适用,规格,香蕉果品的条蕉的收购质量规格,标准,本标准)。为保障试验效果,本文从表1的公共语料中随机选取1 300条制作公共数据集;从标准语料与百科语料中随机选取1 300条制作农产品数据集;并将两类数据集分别以10:3的比例划分成训练集与测试集,数据集示例如图3所示。

图3 农产品非结构化数据集 Fig.3 Unstructured data set of agricultural products
OREM-AF农产品领域开放关系抽取模型的基本思想是从领域标注语料中学习实体与关系之间的依存树结构,判断两者根节点关系的一致性或同级性来生成实体关系抽取依存范式,通过依存分析与实体关系抽取依存范式集匹配,实现农产品相关语料实体关系三元组自动抽取。模型的总体框架如图4所示,包含数据预处理、实体关系依存范式学习、三元组抽取3个阶段。
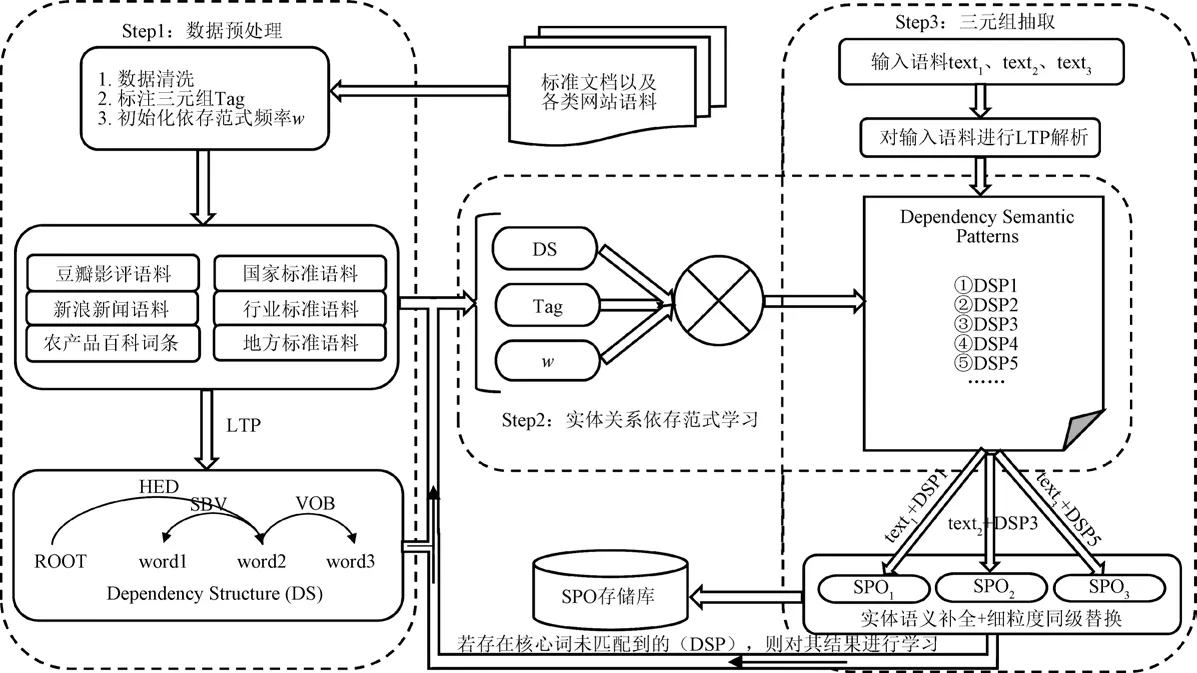
图4 OREM-AF模型框架 Fig.4 Framework of OREM-AF model
1)数据预处理
数据预处理阶段将文本语料解析为依存句法树(如图2所示),为了提高分词的准确率,本文从食品标准伙伴网、中国植物主题数据库等网站爬取了科、属、品种及仅限用物质等专有名词46 157个以提高模型的准确率与召回率。
2)实体关系依存范式学习
实体关系依存范式学习阶段是从依存树结构(Dependency Tree, DT)中学习标注的五元组中伪实体对(伪主语,伪宾语)之间的依存关系结构。学习算法步骤为:首先通过依存树结构DT,找出该文本中以“HED”为首,并与其保持“COO”关系的所有词汇,构成该文本的核心词汇链;通过伪主语逆向找出与其相关的依存树结构DT_1;通过伪宾语逆向找出与其相关的依存树结构DT_2;判断DT_1与DT_2的根节点是否一致或是否为“COO”结构,若是则将二者的关系树按文本的原生树结构进行填充合并,并将原核心词汇替换成“关系”,生成三元组(伪主语,关系,伪宾语)。
以图2为例,核心词汇链仅有一个成员“适用”,其伪主语与伪宾语分别为“标准”、“规格”。通过查找“标准”与“适用”之间的依存树结构DT_1,可以确定“标准”与“适用”之间仅有“SBV”一层主谓结构直接关系;通过查找“规格”与“适用”之间的依存树结构DT_2,可以确定“规格”与“适用”之间有“CMP”动补结构与“POB”介宾结构两层关系,DT_1与DT_2依存树根节点同为“适用”,因此可以依据原生依存树结构,生成属于该核心词汇的依存范式表达式,见表4中的DSP3关系抽取范式。
将公共数据集与农产品数据集的训练集分别输入模型后,得到两类数据中排名前11的高频实体关系抽取范式如表4所示。其中编号DSP0用于处理偏正结构,也可与其他依存范式配合使用;DSP2处理主谓宾结构;DSP3~DSP6处理动补结构、状中结构以及介宾结构等复杂句式;DSP7~DSP10是在以上结构的基础上处理实体及关系之间的并列结构;DSP1情况特殊,并不能从依存范式学习算法中直接获取,但其在子依存树解析阶段出现的概率仅次于DSP0,因此我们手工编辑了该模板,主要用于处理宾语缺失情况,用以生成实体关系二元组。
3)三元组抽取
在得到实体关系抽取范式集之后,可进行三元组抽取。具体步骤如下:将测试语料用LTP工具进行依存句法解析;获取该语料的核心词汇链;获取以核心词为根的依存树并与实体关系抽取范式集匹配得到伪三元组;伪三元组信息可能存在语义放大等情况,因此要对伪主语、伪宾语进行“ATT”定中结构语义补全,并检查“COO”并列结构进行同级替换。
仍以图2为例,该语料核心词汇链中仅有“适用”一词,以“适用”为核心的子依存树与表4中的DSP3相吻合,可得到粗略的三元组(标准,适用于,规格),然后进行主语、宾语语义补全得到三元组(本标准,适用于,香蕉果品的条蕉、梳蕉的收购质量规格),由于该宾语内部存在“条蕉”、“梳蕉”并列结构,因此可以拆分得到两个三元组:(本标准,适用于,香蕉果品的条蕉的收购质量规格)、(本标准,适用于,香蕉果品的梳蕉的收购质量规格)。

表4 高频实体关系依存范式集 Table 4 High frequency entity relationship dependency paradigm set
2.3 农产品标准图谱知识抽取质量评估
模型评测采用准确率(Precision,)、召回率(Recall,)、1值(1-score,1)作为评价指标。

式中CEQ (Correct Extraction Quantity of machine)为机器抽取结果中正确的数量;MEQ(Machine Extraction Quantity)为机器抽取的总数量;MLQ(Manual Labeling Quantity)为人工标注的数量。
半结构化标准数据采用依据本体模式构建的正则包装器进行抽取。评估方案是从640份标准文件中随机选取100份对2.1节中所述的属性三元组及引用三元组分别进行自动抽取,抽取结果如表5所示。
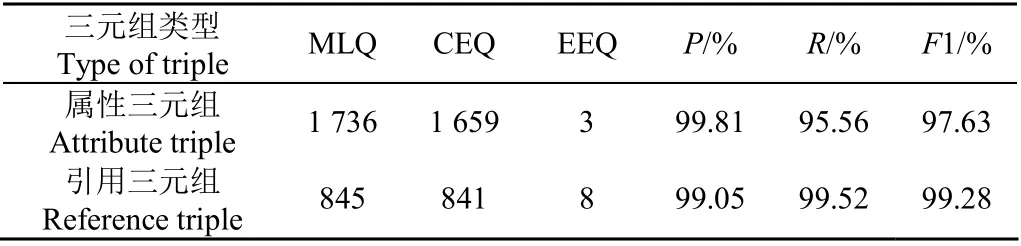
表5 半结构化数据关系抽取结果 Table 5 Relation extraction result of semi-structured standard data
其中用于基础属性三元组抽取的100份标准文件,人工标注共有1 736条,通过机器自动抽取得到1 659条,机器抽取的正确率为99.81%,召回率在95%以上;用于相互引用关系三元组抽取的100份标准文件,人工标注共有845条,通过机器自动抽取得到841条,准确率、召回率、1值均在99%以上。通过以上数据表明,基于正则表达式的包装器抽取方案适用于标准文件半结构化数据抽取,且拥有较高的准确率。
1)OREM-AF模型抽取结果质量评估
非结构化文本语料采用本文的OREM-AF模型进行抽取,该类语料主要涉及2.2节中所述的实体关系,将农产品标准文本以及百科农产品词条输入模型后,抽取结果见表6所示。
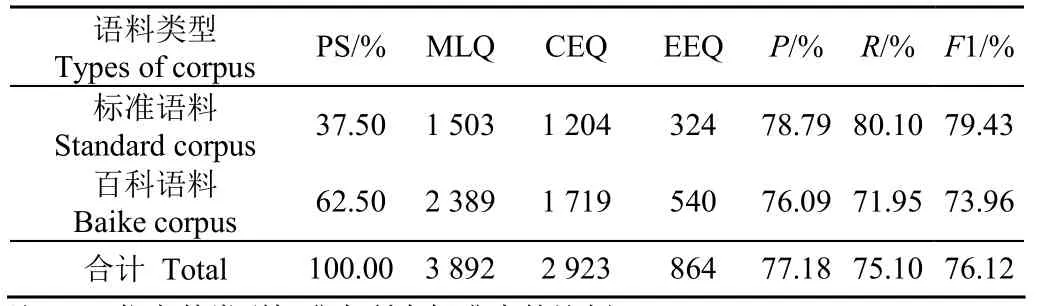
表6 非结构化文本语料关系抽取结果 Table 6 Relationship extraction results of unstructured text
从表6可知,标准语料的抽取结果准确率达到了78.79%,召回率达到了80.10%;百科语料的准确率达到了76.09%,召回率达到了71.95%;总体均在70%以上,能够保证三元组的抽取质量。
2)OREM-AF模型抽取性能对比
为了验证OREM-AF模型的有效性与普适性,本文设计了两组对比试验,将OREM-AF模型与开放域关系抽取模型ZORE、DSNFs在公共数据集与农产品数据集上进行了对比试验,试验结果如表7所示。
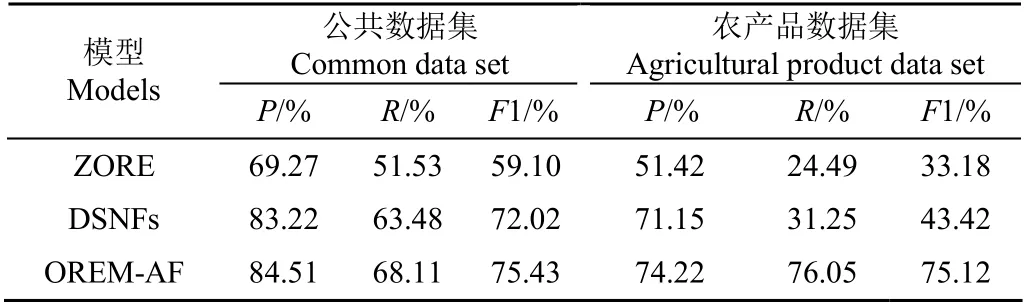
表7 开放关系抽取模型性能对比 Table 7 Performance comparison of open relational extraction models
从表7可以看出在公共数据集上,OREM-AF模型的各项数据表现略好于DSNFs模型;在农产品数据集上,OREM-AF模型的准确率略高于DSNFs模型,但召回率高出较多,主要原因有两个:公共数据集中宾语主体句有大量的同级替换,本文的OREM-AF模型首先能够学习到该类替换模式,并且针对主语宾语制定了深度的同级替换优化策略;DSNFs模型需要先进行命名实体识别,在农产品数据集上效果较差,且识别完成后依靠距离构建实体对,有较高的不确定性,因此其召回率表现较差。ZORE模型总体表现较差可能是因为其自动学习模式策略有较大的不确定性,而DSNFs模型是高度浓缩语义范式的总结,本文的OREM-AF模型相比DSNFs模型具有主动学习、深度语义补全、同级替换等优点,从而表现更好。
3 农产品标准领域知识图谱质量评估
由所有农产品标准文件及相关百科词条构成的半结构化及非结构化数据,经本文提出的正则包装器以及OREM-AF模型抽取并加以清洗与属性矫正共得到19 704条三元组。
三元组知识条目能够较好的表示农产品相关信息,Neo4j数据库可以将三元组这类结构化数据以图的形式存储,从而更加直观的反映农产品标准文件信息之间的关联。因此我们将抽取到的三元组中的实体储存为Neo4j中的节点,将三元组中的关系储存为Neo4j中的边,以形成农产品标准领域知识图谱。当食品安全监管过程需要分析“苹果”相关标准时,通过该图谱可以将所有的苹果相关标准展示出来提供给专家作为参考选择,如图5a所示,这样可以减少大量的人工网络搜索时间等成本;当监管需要获取“鲜苹果”标准的相关内容或需要获取“鲜苹果”与“苹果等级规格”两份标准之间的联系时,农产品标准领域知识图谱也能以此为条件,快速的获取相关内容如图5b、5c所示,从而为农产品全链条监管提供辅助分析手段。
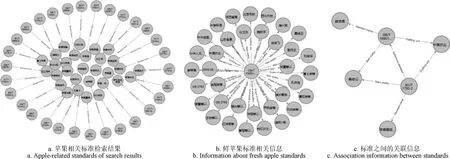
图5 农产品标准领域知识图谱检索结果示例 Fig.5 Example of search results of agricultural product standard domain knowledge graph
4 农产品标准关联性分析
在关系抽取阶段,笔者从农产品标准文件中抽取出了部分农产品标准的相互引用关系,这些相互引用关系使得标准文件之间形成了一个相互引用的关联网络,经过处理后该网络有标准节点1 190个,形成的关系有2 665条。下面本文对该关联网络节点进行了编码处理,并使用Leiden算法结合网络节点的度试图找出一些关联标准的公共性与一致性。
4.1 Leiden社区发现算法
Leiden算法可以视为Louvain算法的改进版,是专门为解决社区联系不紧密而设计的,也就是能够保证所有社区联通。其相对于Louvain算法加入了加速节点局部移动的思想、将节点移动到随机邻居的思想以及分区细化与基于细化分区的网络聚合思想。该算法在初始状态时将每个节点视为单一分区,然后将遵从以下几个步骤:1)节点依据相对增益向与其相连接的社区移动并确定一个相对合理的分区;2)在分区内通过查看是否有断连进行细化分区,基于细化分区创建聚合网络,并使用非细化分区为聚合网络创建初始分区;3)移动聚合后分区的节点并进行细化,直到细化不会改变当前分区。重复上述步骤,直到没有进一步的改进,具体的算法流程如图6所示。
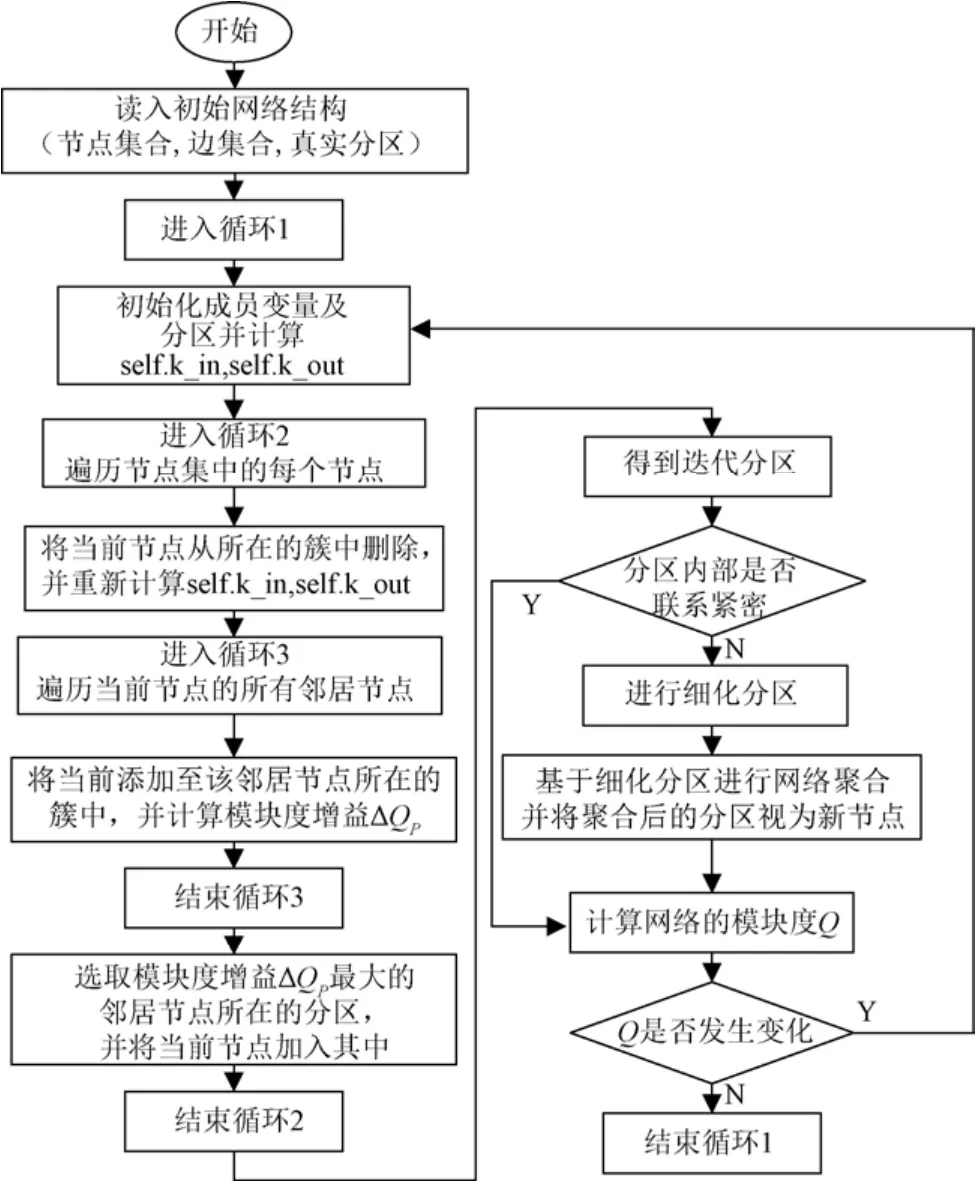
图6 Leiden算法流程图 Fig.6 Flow chart of Leiden’s algorithm
其中,相对增益本文使用的是基于模块度的相对增益,所用到的质量函数如下式所示:
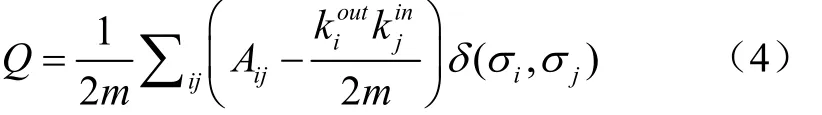
式中表示图中的任意两个节点,A代表节点与节点之间边的权重,k代表所有与节点相连的出度边的和,k代表所有与节点相连的入度边的和,是所有边的权重之和。(,)代表若节点与节点同属一个分区那么返回1,否则返回0。
在算法步骤中将单个节点从一个社区移动到另一个社区依托的是基于模块度的相对增益,表示为
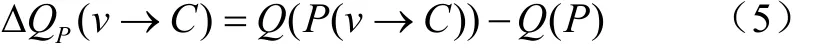
式中(→)表示当前从一个分区开始,然后将节点移动到社区的所获得的分区,因此相对增益就等于将节点移动后的分区质量((→))减去移动之前的分区质量()。
4.2 社区网络挖掘分析
通过上述算法最终将农产品标准规范性引用网络划分为了41个社区,将不同的社区用不同的颜色标记,其中社区节点数小于30的统一用灰色表示;结合节点的出度将节点的大小以及标签的大小与出度的大小成比例放大,最终得到的可视化网络如图7所示。
从图7中,可以发现GB/T 8855-2008(新鲜水果和蔬菜 取样方法)在该领域的权威性、普适性极高,这也验证了试验所用的标准文件均是农产品中果蔬领域的相关标准文件。黄色区域内较为凸显的是GB 2762-2017(食品安全国家标准 食品中污染物限量)、GB 2763-2021(食品安全国家标准 食品中农药最大残留限量),其同属一个社区且同属于食品国家安全标准,从图中也能看出这两份标准在食品安全标准领域的通用性强,表明了农产品领域高度重视农产品中的农药及污染物残留量。蓝色区域内较为凸显的是GB 5009系列食品卫生检验方法理化标准,引用度较高的前四项分别是GB 5009.17-2014(食品中总汞及有机汞的测定)、GB 5009.12-2017(食品中总铅的测定)、GB 5009.11-2014(食品中总砷及无机砷的测定)、GB 5009.20-2003(食品中有机磷农药残留量的测定)。红色区域内较为凸显的是GB 14881-2013(食品安全国家标准 食品生产通用规范),且引用该标准的多为地方性标准,也能看出地方标准的编写更加注重农产品相关制品生产过程中原材料的采购、加工、包装、储存等准则。该结果不仅对农产品标准的社区网络分布研究有良好的指导意义,而且在实际农产品标准制定过程中,可以依据相关标准的引用网络及其所在社区、被引用标准所在社区等信息,找出类似标准的共性、差异性进而指导标准文件编写。
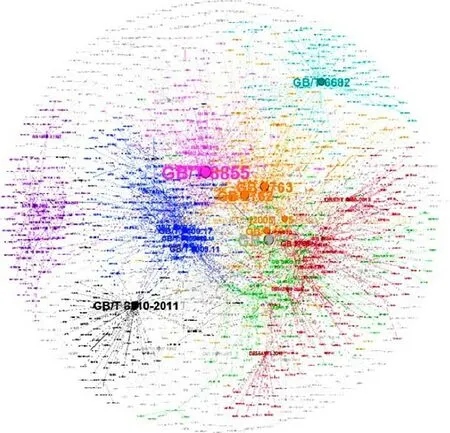
图7 社区网络划分结果 Fig.7 Results of community network division
5 结 论
1)该研究针对难以共享、复用的农产品标准文件半结构化数据,依据本体工程设计了一个可自动化抽取三元组的正则包装器,该包装器抽取评估各项指标达95%以上,能够进行标准文件的大规模信息抽取工作。
2)针对农产品标准文本及相关词条非结构化数据,提出了一种基于依存句法分析的农产品领域开放关系抽取模型(Open Relation Extraction Model In Agricultural Products Field , OREM-AF),该模型能够依据少量的领域样本学习领域内通用的句法结构,进而实现领域非结构化知识的快速自动抽取,试验结果表明在农产品领域数据集上1值达75.12%,该模型同时具有较强的迁移能力,在以影评、新闻为主导的公共数据集上1值达75.43%。
3)将抽取的三元组利用neo4j图数据库形成的农产品标准领域知识图谱能够清晰快速的捕捉当前需要检索的内容联系,并在图谱中的标准相互引用关系关联网络上利用Leiden社区发现算法进行了社区挖掘,从中发现了一些标准文件公共性、一致性与其实际作用范围之间的联系,对农产品的生产销售监管具有一定的指导作用。
当前工作仍存在很多改进空间,未来将会在国内外相关农产品标准图谱的跨模态融合,大规模数据实体关系抽取等方面进行改进。
