基于Sentinel-2A的棉花种植面积提取及产量预测
2022-08-06王汇涵康孝岩印彩霞马露露黄长平
王汇涵,张 泽,康孝岩,林 皎,印彩霞,马露露, 黄长平,吕 新※
(1.石河子大学农学院/新疆生产建设兵团绿洲生态农业重点实验室,石河子 832000; 2.中国科学院空天信息创新研究院,北京 100094;3.塔里木大学农学院,阿拉尔 843300)
0 引 言
棉花是重要的经济作物。新疆作为中国最大的棉花种植基地,2021年棉花产量512.9万t,占全国棉花产量的89.5%,在棉花产业中发挥着举足轻重的作用。棉花产量是指导田间管理的指标之一。及时、准确地预测棉花产量在棉田经营管理、农业决策制定等方面具有重要的价值和意义。
遥感技术具有快速、宏观、动态、成本低等优点,能够克服传统作物估产方法的局限性,已成为产量估测的新技术。目前,已有学者对植被指数和作物产量的模型进行了大量的研究,基于时间序列MODIS_NDVI的农作物产量预测研究较为广泛。赵文亮等根据 NOAA/AVHRR NDVI时间序列得出作物生长期内的归一化植被指数(Normalized Difference Vegetation Index, NDVI)累计值或最大值,通过线性拟合,建立作物产量遥感预测模型。Ji等利用MOD09Q1数据产品计算NDVI时间序列,用于作物大规模产量预测。由于地物类型复杂多样,MODIS数据受空间分辨率的限制,对预测效果具有负面影响,低空间分辨率仍然是遥感技术预测产量应用中的一个问题。刘焕军等利用30 m空间分辨率的Landsat_5_TM与Landsat_7_ETM影像构建非多天合成的NDVI时间序列数据建立棉花估产模型。鲁新新等以Landsat 8遥感影像为数据源,确定NDVI与棉花产量相关性最优的算法模型。这些研究证明了传统植被指数与产量之间的关系,避免了MODIS数据低空间分辨率、多天合成产生混合像元的问题。但也有研究表明,单一植被指数NDVI在较大的叶面积指数(Leaf Area Index,LAI)下易出现饱和现象,并受土壤背景影响,与棉花产量相关性较低(=0.47),Zhao等认为,皮棉产量与棉花生长早期测得的冠层反射率指数相关性最好(为0.56~0.89)。朱婉雪等基于冬小麦不同生育期影像数据和植被指数,构建了多个估产模型,最终确定最佳估产时期和植被指数为抽穗灌浆期和增强型植被指数(Enhanced Vegetation Index,EVI),决定系数达到0.70。
综上所述,以往研究主要通过建立单一植被指数与棉花产量的线性或非线性回归方程,比较分析其相关性,选用相关性最高的某一植被指数与棉花产量的回归方程作为棉花产量预测模型,而棉花产量形成是一个连续变化的动态过程,受冠层结构、生物量和叶绿素含量等因素的影响。单一植被指数的应用简化了棉花产量预测的复杂性,增加了模型的误差和不稳定性。针对该问题,本研究以新疆莫索湾垦区为研究区,基于Google Earth Engine(GEE)平台,获取棉花3个生育时期的Sentinel-2A影像,并进行预处理,重采样至10 m空间分辨率,计算14种植被指数,探讨不同指数预测棉花产量的能力,确定棉花产量预测的最佳生育时期,建立最优的棉花产量预测模型,实现莫索湾垦区棉花产量预测制图,以期为棉花精准管理提供决策信息。
1 研究区与数据来源
1.1 研究区概况
研究区位于新疆兵团第八师莫索湾垦区,地处天山北麓中段,准噶尔盆地南部,东经84°58′~86°24′,北纬43°26′~45°20′,平均海拔300~500 m,属典型的温带大陆性气候,冬季长而严寒,夏季短而炎热,年平均降水量180~270 mm,年平均气温7.5~8.2 ℃,光热资源丰富,日照2 318~2 732 h,无霜期147~191 d。研究区域内种植少量小麦、苜蓿等作物,以棉花为主栽作物。
1.2 数据来源
以2020年Sentinel-2A影像数据为主要数据源,包含13个光谱波段,具体波段参数如表1所示。在GEE平台中,利用JavaScript编程计算云信息波段QA60的Bit10和Bit11的值,设置二者的值均为0得到云掩膜,使用云掩膜去除影像中的云信息,得到无云影像,并重采样至10 m分辨率。
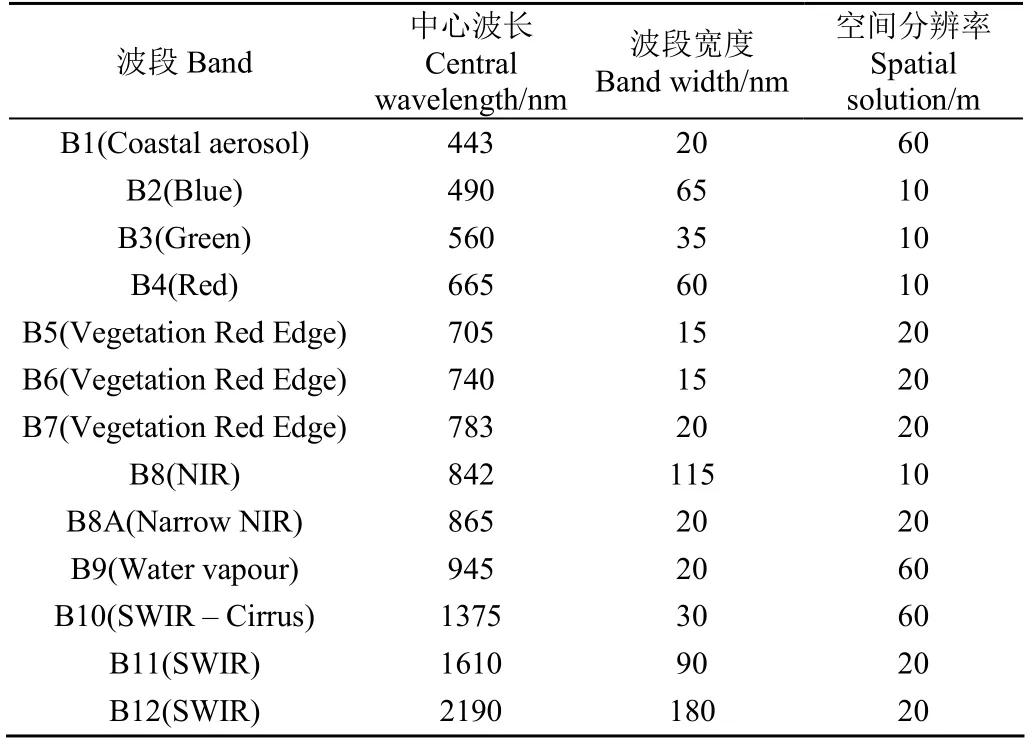
表1 Sentinel-2A波段信息 Table 1 Band information of Sentinel 2A
地物分类数据:数据来自Google Earth 高分辨率影像和野外调查。为了充分掌握研究区域内的地物类型及其典型样本的空间位置,调查时利用Google Earth 高分辨率影像记录代表性地块的经纬度坐标及相应的植被类型。样本数据分布均匀,覆盖研究区域范围,用于农田提取的样本共计609,包括非农田样本282,农田样本327;用于棉花提取的样本共计207,其中非棉花样本74,棉花样本133。
棉花实测产量数据:在棉花收获期开展测产工作,在研究区内,每个团场选择4~5个采样站点,每个站点附近范围内选取5个样点,共计95个样点进行模型构建,同时选择21个样点进行模型验证(图1)。按照五点采样法,调查株数、铃数,取一膜一米的棉絮称干质量,计算平均铃质量。

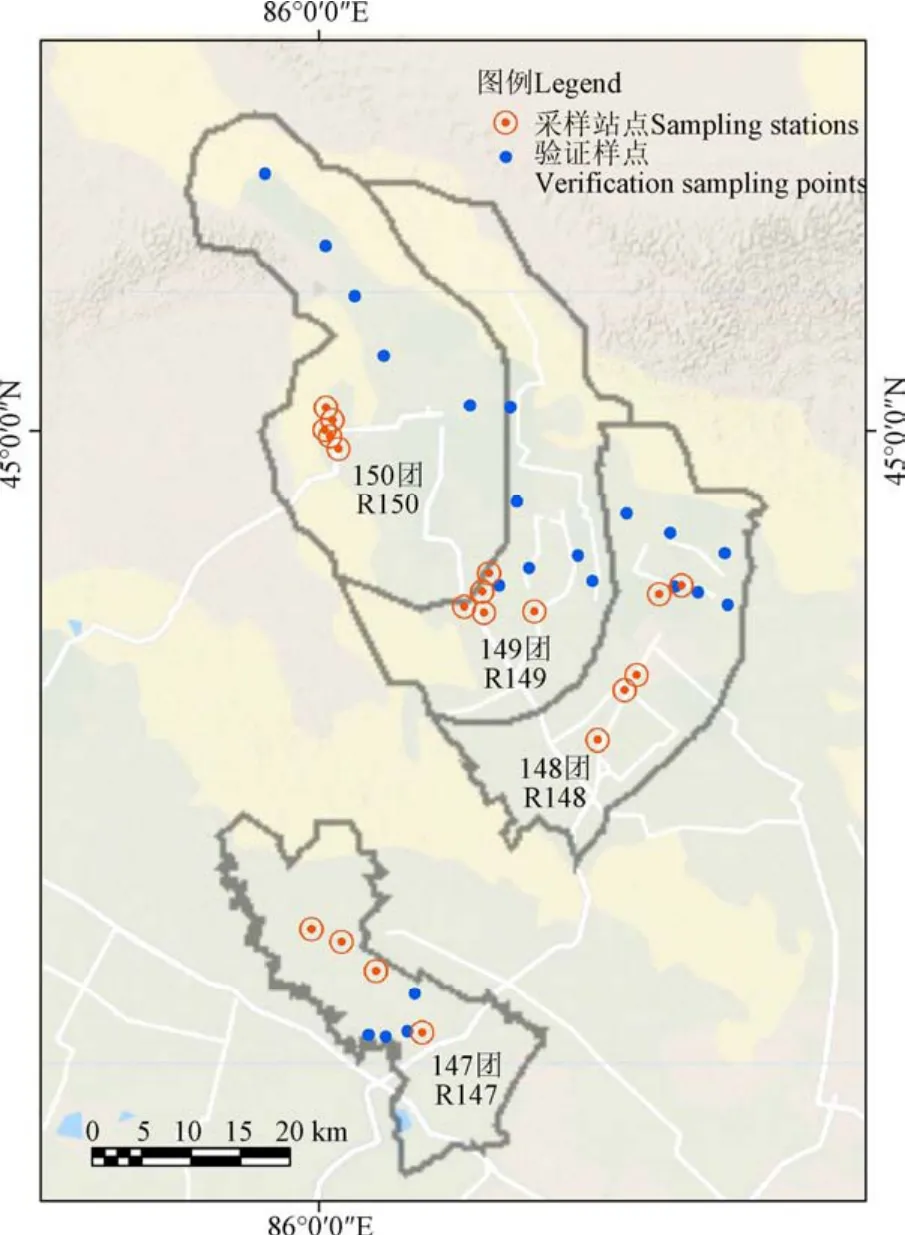
图1 研究区域及样点分布图 Fig.1 Study area and distributions of sample points
植被指数是多个光谱带和波长的转换,可以解释冠层结构和光合作用的变化。根据光谱特性,本文研究了产量预测中常用的14种光谱植被指数,包括6个冠层结构指数及8个叶绿素相关指数(表2)。
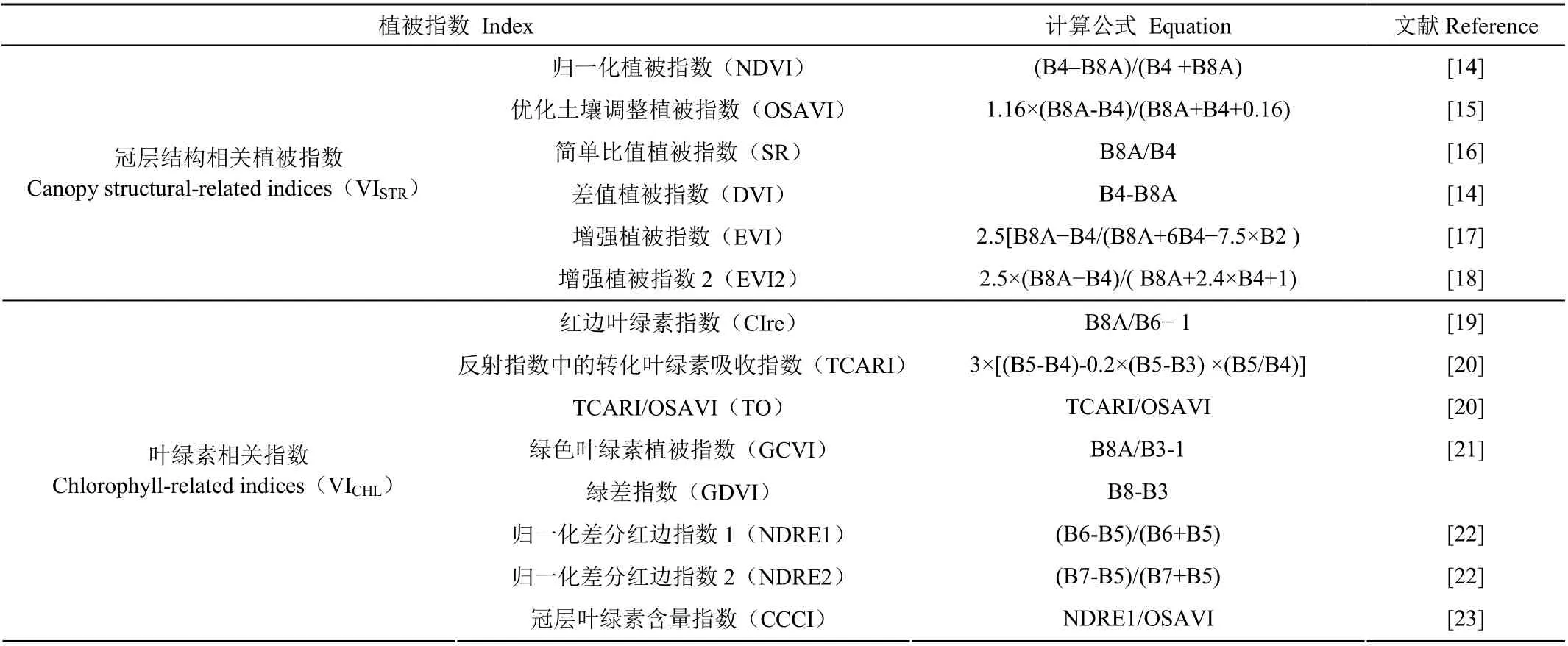
表2 文中选用的植被指数 Table 2 The selected vegetation index
2 数据处理及分析方法
利用GEE平台对Sentinel-2A影像进行预处理。采用两步分级制图策略,利用分类算法剔除非农作物分布区域,合成棉花不同生育时期的影像,实现棉田与非棉田的划分。利用顺序向前算法(Sequential Forward Selection,SFS)对波段和植被指数进行特征筛选,基于偏最小二乘回归模型(Partial Least Squares Regression,PLSR)构建不同生育时期的棉花产量预测模型,以确定棉花估产最佳时期,并将模型应用到棉花产量制图中。
2.1 两步分级棉花种植区域提取策略
本研究中实施两步分级策略用于棉花种植区域提取。第一步,将研究区域划分为5个主要的土地覆盖类别(农田、荒漠、建筑、城市绿地和水体),基于10 m空间分辨率Sentinel-2A影像,选择17个特征用于农田提取,包括12个光谱特征、3个植被指数特征、2个地形特征(Digital Elevation Model ,DEM)特征剔除非农作物分布区域,得到准确的农田掩膜。第二步,将农田划分为棉花区和非棉花区。对研究区影像进行掩膜处理得到农田植被的总体分布,确定棉花5个生育时期,将各生育期的5幅合成图像组合,形成包括12个光谱特征、3个植被指数特征、2个DEM特征的新图像,进行棉花种植区提取。
2.2 分类方法
利用随机森林(Radom Forest, RF)、支持向量机(Support Vector Machine, SVM)算法和决策树(Classification and Regression Tree, CART)三种分类方法,结合研究区域及算法本身的特点,在样本数据中随机选取 70%作为训练数据,剩下的30%作为验证数据。分类性能的评估基于混淆矩阵(Confusion Matrix),用行列的矩阵形式表示。每一行代表参考数据中的实际类,每一列代表预测类,对角线元素表示正确分类的像素个数。混淆矩阵中较常使用的具体评价指标有总体精度(Overall Accuracy, OA)、制图精度(Producer’s Accuracy, PA)、用户精度(User’s Accuracy, UA)以及Kappa系数(Kappa Coefficient, KC)等,这些指标从不同的角度反映作物分类的精度。
2.3 特征选择
由于棉花早期生长阶段的田间空间变异性小,考虑土壤背景反射率的潜在负面影响,开花后期的棉花产量和植被指数之间的相关性更好,因此本研究选取棉花3个主要生育时期的遥感影像。7月11日-7月20日,7月21日-8月30日,8月31日-9月10日,分别对应棉花花期、铃期、吐絮期。利用SFS方法对波段和植被指数进行筛选。
2.4 棉花产量预测模型
PLSR是一种融合了主成分分析、回归分析和典型相关分析等方法的多元数据统计分析模型,能够同时考虑各特征之间的相关性以及与因变量之间的相关性,实现数据的降维、信息综合与筛选,较好地解决特征共线性问题,有效剔除不重要的变量。本文利用SPXY(sample set partitioning based on joint x-y distance)算法同时计算样本间距离对样品集进行划分,基于PLSR构建不同生育时期棉花产量预测模型,并采用独立验证数据对预测模型进行评估和验证,最终确定棉花最佳估产模型。评价指标包括:决定系数(),均方根误差(RMSE)和相对误差RE(%),其值越大和 RMSE 值越小,说明模型的预测性能和准确性越高。均方根误差(RMSE)和相对误差RE(%)公式如下:
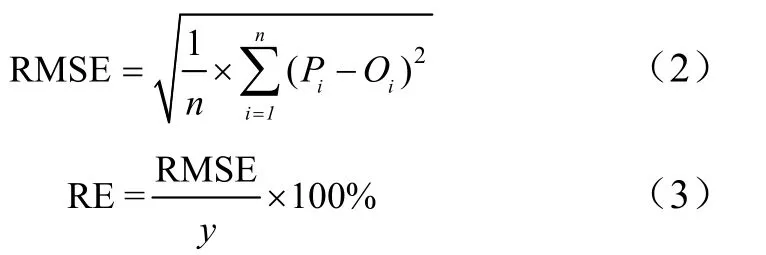
式中P、O和分别为预测值、观测值和实测值的平均值,为样本数量。当RE≤10%时,模型较优,10%<RE≤20%模型适中,RE>20%模型较差。
3 结果与分析
3.1 棉花种植区域提取
结合多种分类特征对莫索湾垦区棉花种植区域进行提取。利用验证点数据对农田与非农田分类进行交叉验证,结果如图2a所示,其中,RF、SVM、CART的UA分别为0.96、0.97、0.91;PA分别为0.92、0.83、0.74;OA精度分别为0.94、0.90、0.83;KC分别为0.89、0.81、0.67。除UA相差较小以外,其他指标差距较大,RF算法分类效果明显优于SVM和CART,更适用于农田与非农田的提取。
在农田掩膜基础上,根据棉花不同生育时期影像,进行棉田与非棉田分类,分类结果如图3b所示。计算分类结果的混淆矩阵,对不同分类方法的分类结果进行精度验证,验证结果如图2b所示,RF算法的PA为0.95,SVM算法PA为0.93,CART的PA为0.90。RF与CART分类精度相差不大,SVM的精度最低,其OA为0.89,KC为0.78。总体而言,RF算法最佳,对2020年莫索湾垦区的棉花种植面积进行计算,并与实际种植面积进行比较,分类结果面积为60 400 hm,实际面积为64 866.7 hm,相对误差为6.9%,与团场棉花的种植现状相吻合。
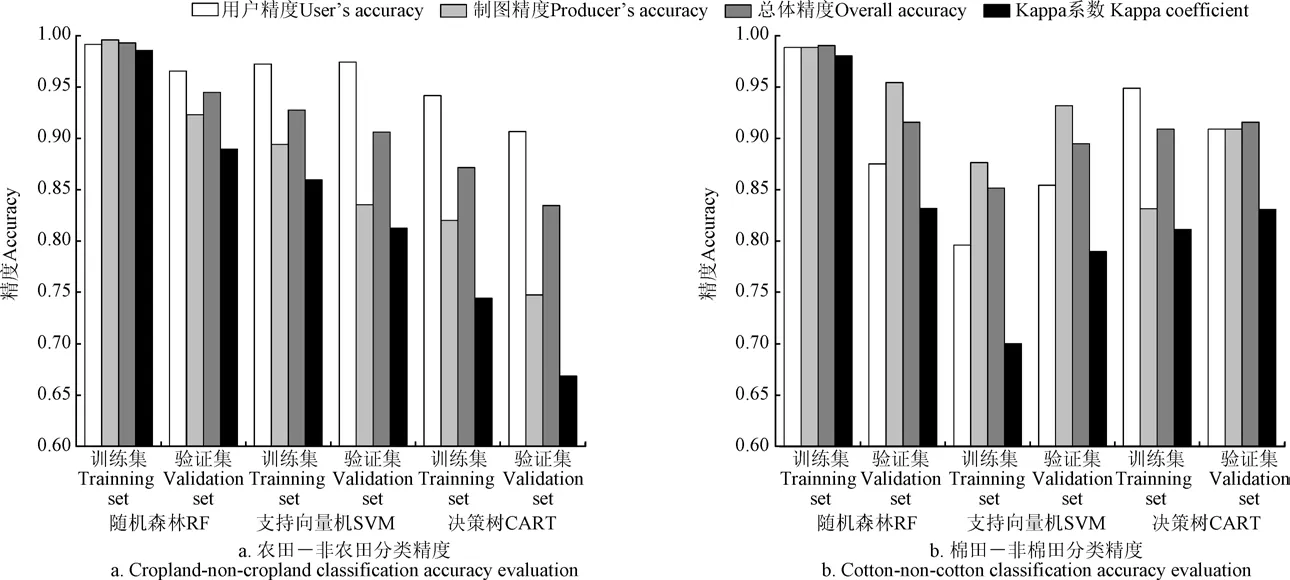
图2 基于不同算法的分类精度评价 Fig.2 Classification accuracy evaluation based on different algorithms

图3 基于随机森林算法的两步分级棉花种植面积提取 Fig.3 Two-step grading cotton planting area extraction based on random forest algorithm
3.2 不同生育时期特征变量选择
为进一步分析不同生育时期波段/植被指数对棉花估产的影响,对研究区棉花产量与不同生育时期波段/植被指数之间的相关性进行统计(图4)。花期、铃期、吐絮期波段/植被指数与产量的相关性趋势基本相同,其中B6波段与产量相关性最高,随着生育时期的推进,相关系数逐渐增大,依次为0.37、0.47、0.53。其次是B7波段,相关系数依次为0.32、0.45、0.51。近红波段仅次于红边波段,B8A波段与产量的相关系数分别为0.31、0.42、0.50。可见,Sentinel-2A特有的红边波段以及近红外波段对棉花产量预测具有一定帮助。

图4 不同特征变量(波段/植被指数)与产量的相关性分析 Fig.4 Correlation analysis between different characteristic variables (Band/Vegetation Index) and yield
相关分析结果能够反映出单个波段/植被指数的预测性能,但并不能有效推断出多波段/植被指数组合的预测能力。利用SFS方法对波段/植被指数进行特征选择,结果如表3所示,就筛选顺序而言,在三个生育时期中筛选的第1个特征都为红边波段(B6波段),进一步证明红边波段在棉花产量预测中的重要性。就数量而言,波段在花期对棉花产量较为敏感,筛选数量多于冠层结构指数和叶绿素相关指数,依次为6个、1个、4个。铃期叶绿素相关植被指数筛选数量(6个)明显多于波段(3个)和冠层结构指数(2个)。吐絮期冠层结构相关指数5个,其次波段4个,叶绿素相关指数2个。冠层结构相关指数随着生育期的推进,对产量的敏感性增大,在棉花生育后期对产量预测模型的贡献较多,叶绿素相关指数则呈现先增长后减小的趋势,在铃期贡献最为突出。弱相关性To指数均被筛选为特征变量,相关系数依次为0.02、0.03、0.10,可见,弱相关性特征的预测性能未必低于独立性弱的强相关性特征组合。对产量预测筛选特征波段时不仅仅考虑单一特征的性能,还要衡量特征之间的独立性和冗余度。

表3 特征变量筛选结果 Table 3 Characteristic band screening results
3.3 不同生育时期棉花产量预测模型
本研究利用SPXY算法对样品集进行划分,以产量为变量,波段/植被指数为变量,将70%的样本训练,剩余30%为预测集样本。基于PLSR将筛选出的特征变量与产量构建模型,结果如图5。铃期模型预测效果最佳(=0.62,RMSE=625.5 kg/hm,RE=8.87%),优于吐絮期(=0.51,RMSE=789.45 kg/hm,RE=11.06%)、花期(=0.48,RMSE=686.4 kg/hm,RE=9.86%)。预测模型的精度随着生育时期的推进有了较大的提升。
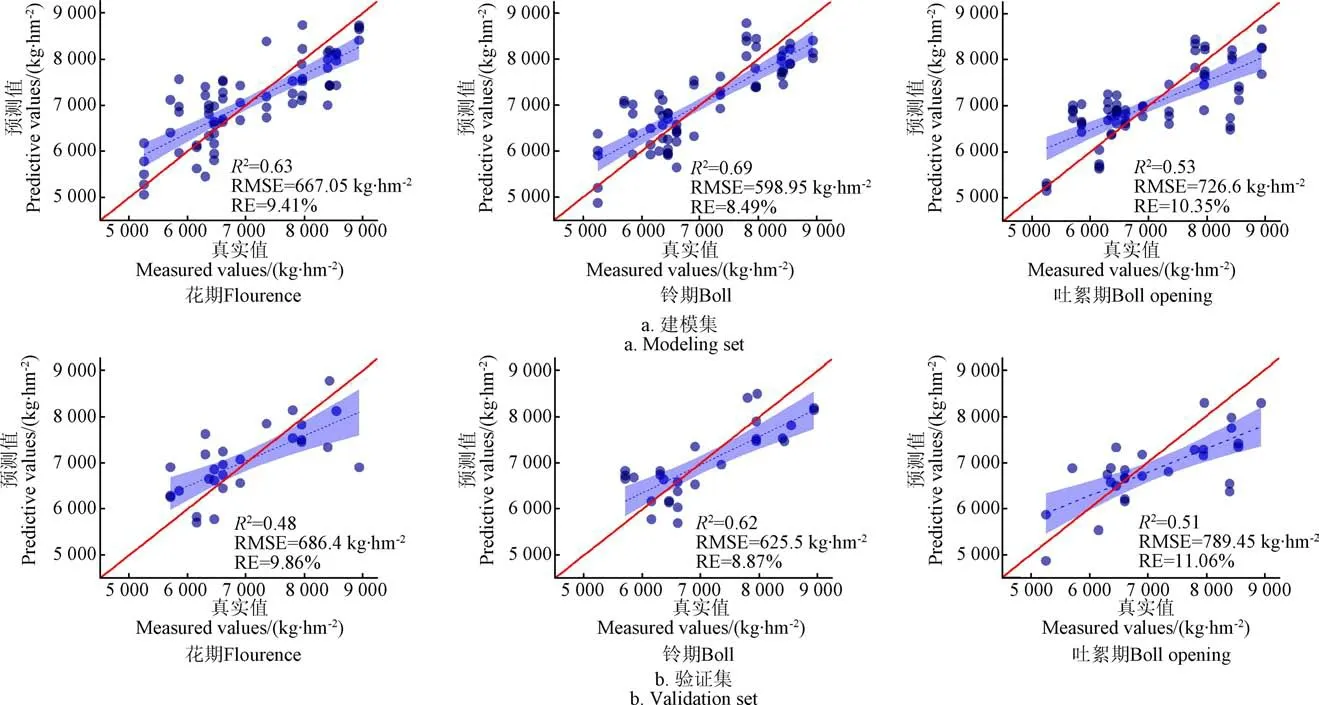
图5 基于偏最小二乘算法不同生育时期产量预测模型评价 Fig.5 Evaluation of yield prediction model for different growth periods based on PLSR algorithm
3.4 棉花产量预测模型测试及制图
利用2020年棉花铃期的遥感影像数据(10 m空间分辨率),基于构建的铃期产量预测模型,选用独立的21个样本点测试模型性能。测试结果如图6所示,=0.61,RMSE=425.25 kg/hm,RE=6.61%,与所建立模型的验证结果接近(=0.62,RMSE=625.5 kg/hm,RE=8.87%),比较理想。
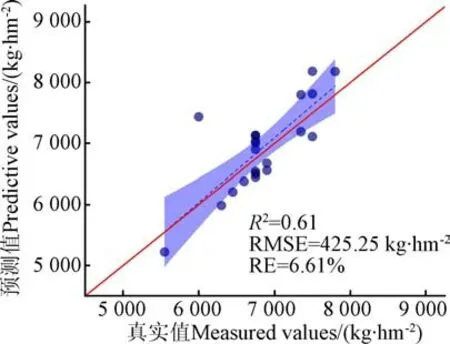
图6 铃期模型预测产量与实测产量的比较 Fig.6 Comparison between predicted yield and measured yield of Boll period model
此外,将已筛选的波段/植被指数作为输入因子,逐像元计算棉花产量,对莫索湾垦区棉花产量分布制图。从图7可以看出,棉花产量分布在3 000~9 000 kg/hm范围内,与实际情况相符,总体而言,棉花产量由北向南逐渐减少,高值区出现在150团,低值区则在147团、148团均有分布。
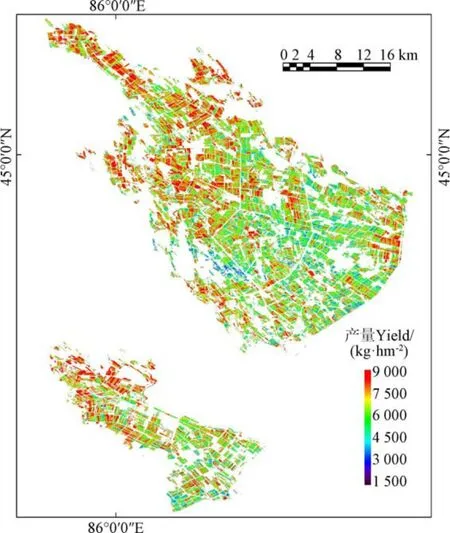
图7 新疆莫索湾垦区棉花产量预测 Fig.7 Prediction of cotton yield in Xinjinag Mosuwan Reclamation Region
4 讨 论
4.1 不同算法提取棉花种植区域精度验证结果
本研究采取两步分级提取策略实现了新疆莫索湾垦区2020年棉花种植面积提取。与李方杰等的研究方法相比,本文使用10 m空间分辨率Sentinel-2A影像数据,在影像合成上突出了棉花的特征,且在模型训练时加入植被指数和地形特征,实现较高精度的棉花提取,该提取策略聚焦田间植被,筛选得到的特征针对性更强,理论上所得结果的适用性和推广性更优且不受其他非农地物的影响,在棉花卫星遥感提取中具有重要意义。以往研究表明,机器学习算法与传统算法相比在处理高维复杂数据时可以有效利用数据特征实现更高的分类精度。然而,使用多种机器学习算法进行对象提取的研究较少,在相同数据上比较多种算法有利于在棉花种植面积提取中找到最合适的算法。鉴于此,本研究凭借GEE存储大量遥感数据的优势,获取了2020年覆盖莫索湾垦区的Sentinel-2A数据影像,同时实现了去云、影像镶嵌、裁剪等一系列预处理,有效避免了影像镶嵌带来的色差问题,保证了分类数据源的纯洁度与质量,利用GEE中提供的分类器,对比RF、SVM、CART三种算法在棉花种植区域提取中的分类效果。从PA、UA、OA和KC检验结果来看,RF对农田与非农田分类的PA为0.92,UA为0.96,OA为0.94,KC为0.89,优于SVM和CART。棉田与非棉田分类中,RF与CART表现相似,RF的PA(0.95)略高于CART(0.90),由此可见RF的分类效果最佳,这与哈斯图亚等的研究结果相符。CART容易出现过度拟合现象,而RF是一个决策树的集合,只考虑特征的一个子集,最终结果取决于所有的树,有更好的泛化能力和更少的过度拟合。该分类方法对农作物的识别能力较强,分类精度较高,能够满足精准农业遥感监测的需要。
4.2 波段/植被指数与产量的关系及不同生育时期预测效果
本研究利用GEE平台获取并预处理棉花三个生育时期的Sentinel-2A遥感影像,构建14种植被指数,与产量进行相关性分析。与花期相比,棉花产量和生育后期(铃期/吐絮期)的波段/植被指数之间相关性更高。可能由于现花期田间空间变异较小,土壤背景反射率存在负面影响,这一结果与前人研究一致。由于棉花吐絮后冠层结构变化较大,吐絮期的冠层结构指数与产量的相关性高于其他的生育时期,并且有明显的差异性,而叶绿素相关植被指数则在棉花盛铃期表现较好,冠层结构和叶绿素含量相关植被指数对作物生长过程中的不同方面(即形态和生理)都有反应,因此两者都包括在最终模型中。波段/植被指数与棉花产量的相关分析结果能够反映出单个波段/植被指数的反演性能,但并不能有效推断出多波段/植被指数组合的反演能力。由于波段/植被指数之间有着不同程度的信息重叠、冗余以及相关性,从而独立性强的弱相关特征组合的反演性能未必低于独立性弱的强相关的特征组合。
由于Sentinel-2A特有的红边波段与产量有较高的响应,将与冠层结构和叶绿素含量相关的植被指数结合起来建立模型,在不同生育时期的模型对比中,铃期的模型预测效果最好(=0.62,RMSE=625.5 kg/hm,RE=8.87%),优于吐絮期(=0.51,RMSE=789.45 kg/hm,RE=11.06 %),花期的预测结果较差(=0.48,RMSE=686.4 kg/hm,RE=9.86%)。前人研究也发现随着季节的推进,产量预测效果改善。本研究中的预测模型在铃期时有所改善,主要归因于特征筛选时铃期叶绿素相关指数的贡献更大。棉花吐絮期模型精度低于铃期的原因可能在于棉花在进入吐絮期后,白色棉絮渐渐显露出来,冠层结构发生变化,吐絮前后冠层反射率产生较大差异,植被指数受棉絮影响,导致低估。现蕾营养生长与生殖生长并进,营养物质及环境资源竞争激烈,其中铃期环境条件的影响最明显,该生育期为棉花产量形成的关键期。
4.3 莫索湾垦区棉花产量预测模型测试及制图
基于上述构建的产量预测模型,选用单独的21个样本点对模型性能进行测试,其结果较为理想(=0.61,RMSE=425.25 kg/hm,RE=6.61%),并实现了新疆莫索湾垦区棉花产量预测制图。产量预测值分布在3 000~9 000 kg/hm的范围内,对于每个像元而言,存在高估或低估属于正常现象。前人的研究也表明,由于作物管理投入的差异,也会存在同一区域内产量变异性大,在合理误差范围之中。总体而言,分布呈现出高产集中在北部区域,由北向南递减,这可能与150团紧邻沙漠有关,沙漠增温效应可以使准噶尔盆地100 km内的区域温度有不同程度的提高,距沙漠近的区域有较好的热量资源,促进生理活动,增加产量。
5 结 论
1)本研究采用两步分级提取策略,有效避免了非农田的影响,准确提取莫索湾垦区棉花种植区域。其中随机森林算法表现最佳,农田与非农田分类的制图精度PA和用户精度UA分别达到了0.92和0.96,分类总体精度OA为0.94,Kappa系数KC为0.89,棉田与非棉田分类的PA和UA分别达到了0.95和0.87,分类OA为0.92,KC为0.83。分类结果面积为60 400 hm,实际面积为64 866.7 hm,相对误差为6.9%,表明该分类方法对棉田分类精度较高,能够满足精准农业遥感监测的需要。
2)本研究基于SFS-PLSR算法构建了3个生育时期的棉花产量预测模型,利用实测数据对模型进行验证,结果表明,模型在铃期表现出了最佳产量预测能力(=0.62,RMSE=625.5 kg/hm,RE=8.87%),铃期是新疆莫索湾垦区棉花产量预测的最佳生育时期。根据棉花种植区域图实现棉花产量预测制图,莫索湾垦区的棉花产量范围为3 000~9 000 kg/hm。
本研究提出的两步分级策略能够有效识别棉花种植区域,综合考虑波段/植被指数组合在产量预测中的表现,为新疆莫索湾垦区棉花产量预测提供了一种新的思路,可为合理水肥配置、精准种植、农作物生长过程监测提供数据支撑,促进精准农业快速发展。
