基于特征融合的棉花幼苗计数算法
2022-08-06李亚楠徐文霞
祁 洋,李亚楠,孙 明,徐文霞
(1.武汉工程大学计算机科学与工程学院、人工智能学院,武汉 430205; 2.武汉工程大学智能机器人湖北省重点实验室,武汉 430073)
0 引 言
中国是世界第一大棉花消费国和进口国,也是世界第二大棉花生产国,棉花高质量生产与经济发展息息相关。幼苗作为棉花生长期内的一个重要阶段,幼苗数量直接关系到其播种成活率、出苗率等苗情信息的获取,间接影响棉花的发育监测与产量估计。然而,目前幼苗数量的统计手段还主要依赖于人工观测。这种方式不仅效率低,主观性强,而且很难满足现代化大型农业的发展需要。因此,有必要利用智能化技术代替繁杂的人工观测,助力棉花高质量生产。得益于深度学习技术的快速发展,基于计算机视觉的目标计数方法为获取田间幼苗数量提供了新的技术手段。
在农业领域,目标计数方法常被用来解决农作物的空间分布、种植密度、以及产量预估等问题。传统的目标计数方法主要包括基于检测和基于回归两类。基于检测的方法通过累加图像中检测框的数量获取计数结果,或通过视频序列统计前景目标的数量得到计数结果。陈锋军等在无人机航拍图像的云杉计数问题上,提出了基于改进YOLOv3的检测方法,梁习卉子等在棉花行数的计数问题上尝试了基于视频序列图像,利用方向梯度直方图(Histogram of Oriented Gradient, HOG)特征和支持向量机(Support Vector Machine, SVM)分类器来检测棉花行数。上述基于检测的方法在应对清晰的大尺寸目标取得较好效果,然而却不能有效解决尺度变化大的小目标计数问题。并且,该方法需要繁琐的边界框标注或像素级注释。因此,基于检测的方法并不适用于棉花幼苗这种小目标的计数问题。基于回归的计数方法通过学习目标颜色、纹理等浅层特征与数量间的映射关系,建立回归模型直接输出计数结果。Ramos等通过对单面图像中的咖啡豆颜色形态等特征构建一个线性回归模型,估计出整条枝干上的咖啡豆数量。尽管基于回归的方法能在一定程度上解决小目标以及尺度变化带来的问题,但是却忽略了目标的空间位置信息。在针对棉花幼苗图像这种高分辨率以及空间分布具有一定规律性的计数问题上,忽略位置信息可能导致计数精度的降低。
近年来,一种基于密度图的计数方法能通过学习特征与密度图之间的映射关系,生成高质量密度图以获取目标数量,大幅提升了计数精度。在人群计数领域,Zhang等提出多列卷积神经网络(Multi-column Convolutional Neural Network, MCNN)方法,利用大小不同的滤波器获取不同的感受野,以适应人群的尺度变化,估计出人群密度图。Li等提出拥挤场景识别网络(Congested Scene Recognition Network, CSRNet)方法,使用VGG-16的前十层提取图像特征,用膨胀卷积层代替池化层和全连接层,在不增加计算量的情况,扩大感受野,提取更细致的特征。以及其他一些典型的基于密度图的方法都取得了较好的效果。在农作物计数领域,这种方法也表现出良好的性能。鲍文霞等先对田间麦穗图像进行均衡化和分割处理,通过迁移学习训练田间麦穗密度图估计模型,实现了灌浆期田间麦穗的数量估计。黄紫云等通过对图像中棉铃密度等级进行分类,将分类信息与特征相结合,生成高质量密度图解决了复杂背景下棉铃的计数问题。Lu等通过对图像划分区块,从区块密度图中得到的局部计数,最后合并归一化获取整幅图像中玉米须的数量。尽管基于密度图的方法在解决小目标、多尺度等问题上取得了较好的计数效果,但是却忽略了目标对象特征之间的关联性,一定程度上限制了计数性能。
综上所述,本文在CSRNet密度图生成框架下,结合幼苗图像全局特征信息与特征之间的关联性,提出了一种基于特征融合的棉花幼苗计数算法。该算法通过注意力模块对棉花幼苗全局特征信息进行增强,并将丢弃(Dropout)方法用于特征融合过程,最后通过去冗余和归一化操作生成密度图获取计数结果。此外,本文对不同时间图像进行了测试,并且对比了不同的计数方法,以验证本文算法的有效性。
1 材料与方法
1.1 棉花幼苗数据集
本文的棉花幼苗图像采集试验田位于新疆乌兰乌苏、阿瓦提和库尔勒等地。从2017-2018年,连续采集了所有棉花生长期内的可见光图像(分辨率为3 088像素×2 056像素)。本文在上述图像中选取了从出苗期到三真叶期的部分图像序列构成棉花幼苗数据(Cotton Seedling Counting Dataset,CSC数据集),其中幼苗图像示例如图1a和图1b所示。CSC数据集大小为1.36 GB,一共包含399张棉花幼苗图像,使用labelme3.16.2对每幅棉花幼苗图像进行了手工标注点标签,得到真值图(ground-truth image,人工标记好的数据,用于测试试验结果),如图1c与图1d所示。CSC数据集共标注了212 572株棉花幼苗,其中,单幅图像最多幼苗标注数量为1 541,最少为196,平均每幅图像标注数量为532.76。此外,为了说明本文算法的有效性,将数据集划分为训练集和测试集,其中,训练集包含300幅图像,测试集包含99幅图像。

图1 棉花幼苗图像与真值图像示例 Fig.1 Samples of cotton seedling image and ground-truth image
1.2 棉花幼苗计数算法
本文的计数算法由VGG基础模块、注意力模块、特征融合模块以及去冗余归一化操作4个部分组成,如图2所示。首先,输入图像经过VGG基础模块生成特征图像。之后,注意力模块对通道和空间维度上的特征图像空间位置信息进行增强。特征融合模块将增强后的特征与基础模块中的特征进行融合,最后去除冗余信息和归一化操作,输出计数结果。
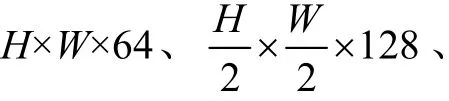
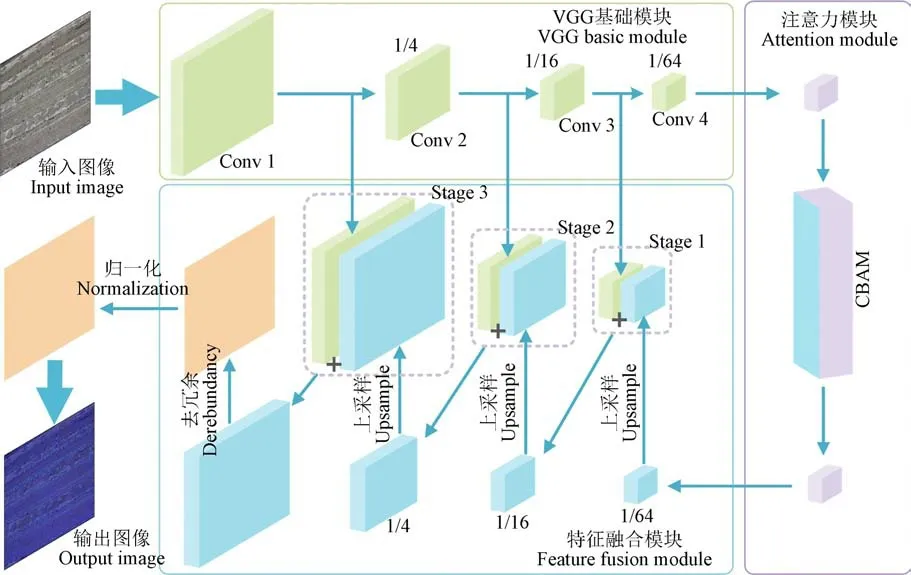
图2 棉花幼苗计数算法框架 Fig.2 The framework of cotton seedling counting algorithm
经过上述4层卷积层,特征图变为原图的1/64,通道维数升至512,为了避免幼苗空间关系特征以及颜色、纹理等细节特征的丢失,并提高计数精度,本文采用了注意力模块CBAM。该模块包含通道注意力模块CAM(Channel Attention Module)和空间注意力模块SAM(Spatial Attention Module),如图3所示。
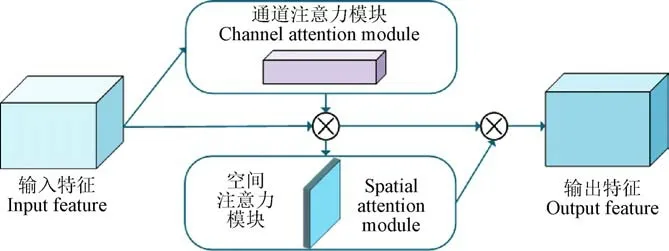
图3 CBAM结构图 Fig.3 CBAM structure diagram
其中,CAM对输入的特征图进行通道维度上的重新整合和优化。SAM采用自适应的平均池化和最大池化,将图像中棉花幼苗空间特征连接起来。因此,CBAM模块从通道和空间维度上对幼苗全局特征信息进行增强。需要强调的是,该模块的输出特征图与输入特征图保持相同的大小和通道数。为了细化基础模块生成的特征图以及为后续融合模块保留更多更重要的融合信息,本文将CBAM模块置于特征提取基础模块与特征融合模块之间。 活函数ReLU(修正线性单元,Rectified Linear Unit)。其中,为了实现通道维度上的信息交互,以及保证特征融合时的通道数量一致性,本文将此处的1×1卷积的输出通道数量设置为输入通道数量的二分之一。值得注意的是,在完成上一次的特征融合后,1×1卷积块会对融合的特征图进行预处理,将语义信息和细节信息凸显化,进而准备下一阶段的融合。之后,对经过卷积块操作的特征图像通过双线性插值进行上采样(Upsample),上采样率设置为2,即与浅层特征图保持相同的尺寸,保证在特征融合时的大小一致性。
一般来说,浅层特征图具有复杂的细节信息,而深层特征图包含丰富的语义信息。深层特征与浅层特征的融合不仅可以避免细节信息的丢失,还能加快模型训练损失的收敛。因此,在MobileCount的启发下,本文提出一种特征融合模式,如图2特征融合模块所示。对经过注意力模块增强后的特征与VGG基础模块提取的前3层(Conv1-Conv3)特征进行3个阶段的融合,增强幼苗特征信息表达。然而,尽管浅层特征图具有复杂的细节信息,但同时也包含较多的噪声。此前,Lin等提出了较为成熟的特征融合方法,但这种方法并不能有效避免浅层特征图中的噪声。为解决这一问题,本文设计了一种特征融合方法,具体过程如图4所示。需要注意的是,在特征融合时,应保证两端输入的特征图具有一致的尺寸大小和通道数量。
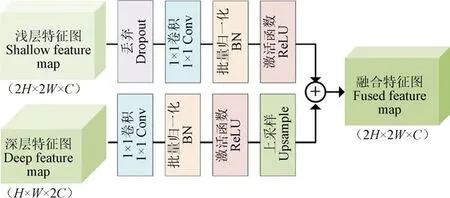
图4 特征融合方法的过程 Fig.4 The process of feature fusion method
特征融合方法首先采用1×1卷积块对深层特征图进行操作。该卷积块包括一层1×1卷积(1×1Convolution),一层批量归一化(Batch Normalization,BN)和一层激
其次,对于噪声较大的浅层特征图,在进行融合之前,使用Dropout随机丢弃其中一部分信息(只用于训练,且Dropout概率设置为50%),从而避免噪声的干扰,同时也防止模型在训练时过拟合。之后,再对保留下来的特征进行1×1卷积块的操作,完成与深层特征图的融合,并进入下一阶段。此时,1×1卷积块中的卷积操作只是对保留的特征信息进行重新整合,并没有改变特征图的通道数目。
经过多层融合后得到的特征图像的通道数为64,包含了大量的通道冗余信息,直接进行预测输出很大程度上会影响最终的计数精度。因此,本文先使用三个3×3卷积对融合后的特征信息进行归纳和整合,然后再用一个1×1卷积对特征图每一像素位置通道维度上的特征向量进行压缩,生成一张单通道的特征图,以去除冗余信息。受尺度融合计数分类网络(Scale-Fusion Counting Classification Network, SFC Net)的启发,去冗余之后,本文对单通道特征图进行计数归一化(Normalization),将每一个像素位置的计数数量与该位置被计数次数相除,生成密度图像输出并获取最终计数结果。
1.3 训练细节与评价指标
本文算法试验环境为:Ubuntu20.04系统、Pytorch1.7.1开源框架、Python3.8编程语言、Intel Core i9-10900X CPU@3.70GHz以及GeForce RTX 3090。训练时,为了减少计算量以及扩大训练样本数量,将训练图像进行随机裁剪(尺寸为256像素×1 024像素)、翻转以及标准化预处理(均值减法和标准差除法),之后与ground-truth一起被加载训练。设置训练时的批样本大小(batch size)为10,即每批次从训练集中加载10幅图像。测试时batch size设置为1,每批次从测试集中加载1幅图像。迭代训练次数(epoch)设置为500,从图5可以看出,在模型迭代训练100次之前,训练损失下降明显,之后逐渐趋于平稳,并在第200次和第400次时,将学习率进行调整为当前学习率的十分之一,以保证模型收敛且接近于最优。采用Adam算法对模型参数进行优化,使用L1损失函数对模型训练进行监督。损失函数L1Loss定义如式(1)~式(2)所示。
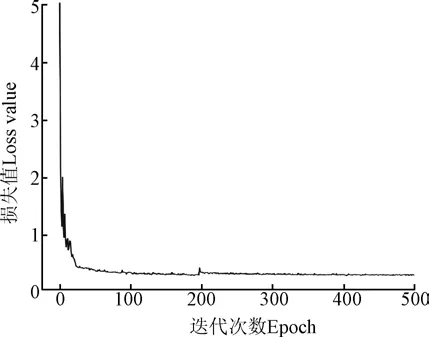
图5 模型训练损失曲线 Fig.5 Model training loss curve
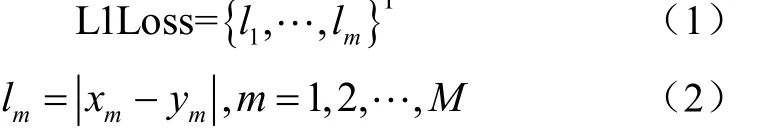
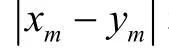
本文使用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)来评估算法模型的性能。定义如下:
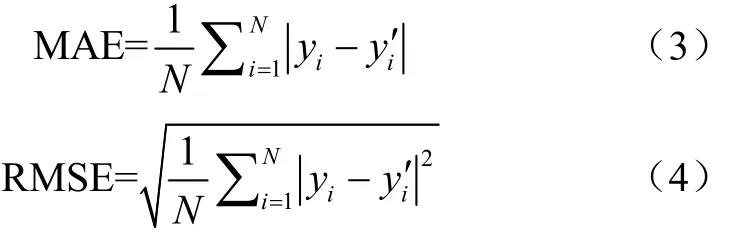
式中代表测试集中图像的总数量,y表示第张图像中幼苗的真实数量,y′表示第张图像中幼苗的估计数量。平均绝对误差与均方根误差越低,从某种程度上可以反映出算法的性能越强。
2 试验结果与分析
2.1 不同时间测试结果分析
本文在棉花幼苗图像上进行实际计数估计,并输出密度图及计数结果。图6列举了一些拍摄于不同时间段的棉花幼苗图像计数预测结果。其中,真值密度图是对标注的真值图利用热力图显示得到,其幼苗数量通过点标签的数量确定。预测密度图中的幼苗数量是通过对模型输出密度图中的所有像素点(包括稀疏像素点)进行积分求和得到的。值得注意的是,在图6的列举结果中,拍摄于2018年5月6日14:00的图像,即使在噪声(图中电线杆和摄像头的阴影区域)的干扰下,算法预测的幼苗数量与实际幼苗数量相差仅为1株,较为准确的估计出了幼苗的数量,另外3幅图像的预测数量与真实数量之间相差均不超过10株,这说明本文算法表现出较好的性能。并且,算法预测的密度图不仅能够获取棉花幼苗数量,也能在一定程度上反应出棉花幼苗的种植密度。此外,在图6的列举结果中,拍摄于2018年5月6日14:00的图像,即使在阴影噪声的干扰下,本文算法依然能够较为准确的估计出幼苗的数量,也能反映出该算法具有一定的有效性。

图6 不同时间计数结果 Fig.6 Counting results at different times
此外,本文将测试集图像分为中午组和早晚组。中午组为拍摄于12:00和14:00的图像,此段时间阳光充足,光照条件较好,共计52张。早晚组为拍摄于8:00、9:00、10:00以及16:00、18:00的图像,这些时间光线斜射,光照条件相对较弱,共计47张。不同组别的验证结果如表1所示,可以看出,在不同的光照条件下,本文算法模型的性能变化并不大,说明了本文算法具有较强的鲁棒性和稳定性。
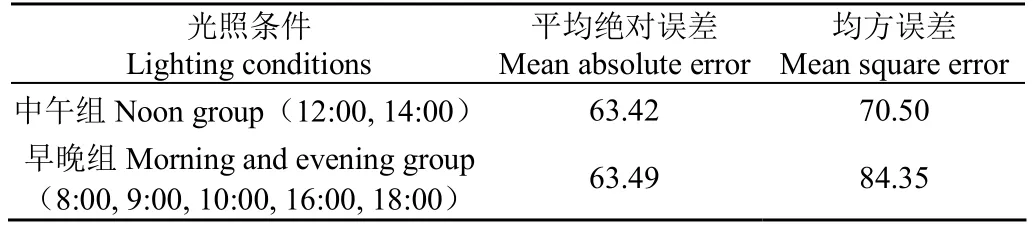
表1 不同光照条件的幼苗计数对比结果 Table 1 Comparison results of seedling counting under different lighting conditions
2.2 不同计数算法的定量分析
为了进一步说明本文方法的有效性,选择了4种典型的基于密度图的目标计数方法进行对比,对比试验的训练数据、测试数据(全部测试集)以及训练细节均保持一致。
在目标计数领域,MCNN和CSRNet这两种方法非常具有典型性,虽然其研究对象为人群,但是其基于CNN的计数模型与本文算法具有一定的相似性。TasselNet是Lu等提出的针对田间玉米穗计数方法,本文对比试验使用TasselNet中具有最佳计数性能的基于AlexNet-Like架构的方法作为对比。MobileCount是Wang提出的方法,其在Lin等提出的轻量级模型方法的基础上,利用多层知识蒸馏和特征融合,进一步提高了计数性能。因本文特征融合的思想来源于它,所以将其加入对比试验。
本文方法与其他方法进行对比的结果如表2所示。为了合理的进行对比,所有结果均取自测试集上的最优数据。从表2的数据中可以看出,MCNN和CSRNet这两种典型的目标计数方法表现出的性能并不好,这可能与没有考虑目标的空间信息有关,并不适用于田间棉花幼苗的计数。MobileCount利用知识蒸馏融合特征,从而达到了较好的计数效果,与TasselNet相比,MAE和RMSE下降幅度(计算方式参考Liu等的方法)均超过40%。与MobileCount方法相比,本文算法MAE和RMSE分别降低了10.89%和10.34%。相较于MCNN、CSRNet、TasselNet和MobileCount 4个对比方法,本文算法MAE和RMSE分别为63.46、81.33, MAE平均下降了48.8%,RMSE平均下降了45.3%,这证明了本文所提方法的有效性。
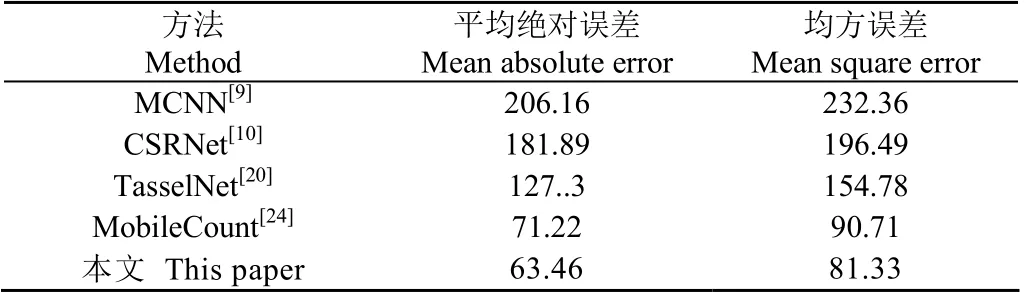
表2 不同计数算法的定量分析 Table 2 Quantitative analysis of different counting algorithms
2.3 消融试验
为了验证本文算法设计的合理性和有效性,分别从Dropout对特征融合的影响和不同模块对本文算法的影响两方面进行消融试验,试验结果分别如表3和表4所示。
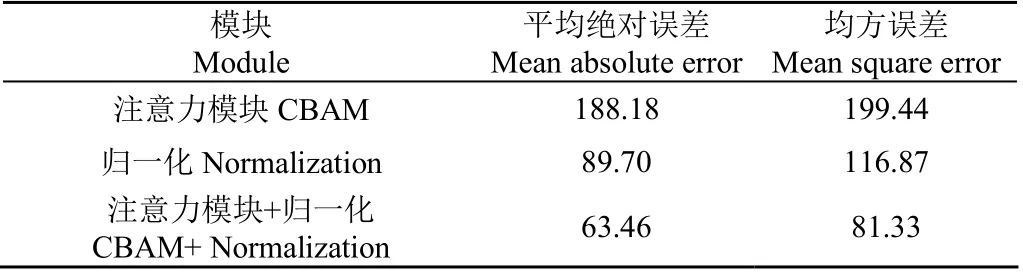
表4 不同模块对本文算法的影响 Table 4 The effect of different modules on the algorithm of this article
表3中,无Dropout的融合方法是保持原有的融合策略,直接使用VGG基础模块中的特征进行融合。反之,则为本文提出的融合方法,即在融合过程中添加了Dropout,随机丢弃一部分噪声较大的浅层特征图。从表3中可以看出,Dropout在融合过程中发挥了积极的作用。相比于无Dropout的融合方法,本文融合方法的MAE和RMSE都下降约16%。

表3 Dropout对特征融合的影响 Table 3 The effect of Dropout on the feature fusion
表4验证了不同模块对本文算法的影响,其结果表明,相较于单独使用CBAM和归一化中任意一个模块,本文算法MAE平均下降47.8%,RMSE平均下降44.8%。因此,将注意力模块CBAM与去冗余(Normalization)操作引入本文算法是有效的。
3 结 论
本文提出的棉花计数算法,采用VGG-16作为骨干网络提取图像特征,引入注意力机制模块CBAM增强基础特征,随后将这些特征一并融合,进一步强化幼苗特征表示,最后通过去冗余和使用归一化模块获得较为精确的计数结果。与目标计数方法MCNN、CSRNet、TasselNet以及MobileCount的对比试验结果表明,本文算法MAE和RMSE分别为63.46、81.33,相较于对比方法,MAE平均下降了48.8%,RMSE平均下降了45.3%,验证了本文算法的有效性。即使存在阴影噪声干扰和光照强弱变化,该算法仍然能够较为准确地估计出图像中的幼苗数量,进一步说明该算法具有较强的鲁棒性。此外,消融试验结果表明:添加Dropout特征融合方法、引入注意力模块CBAM以及归一化操作是有效的。
由于本文棉花幼苗数据采集于实际农田环境,幼苗在生长过程中呈现多样的姿态和尺度,这可能是导致少数测试图像的预测数量与实际数量相差较大的原因。在今后的研究中,将从上述不足和算法的可迁移性等方向进一步优化算法,以提升其计数性能和适用性。
