基于改进VGGNet的羊个体疼痛识别方法
2022-08-05侯越诚田虎强张世龙
韩 丁 王 斌 王 亮,3 侯越诚 田虎强 张世龙
(1.内蒙古大学草原家畜生殖调控与繁育国家重点实验室,呼和浩特 010030;2.内蒙古大学电子信息工程学院,呼和浩特 010021;3.复旦大学信息科学与工程学院,上海 200433)
0 引言
在羊养殖业中,羊的疼痛往往是由疾病引起的,所以疼痛检测对羊的福利化养殖和健康生长非常重要,而找到快速、准确的疼痛检测方法成为关键[1-2]。LANGFORD等[3]最早对动物面部疼痛识别进行了研究。对于羊的疼痛,2009年STUBSJØEN等[4]利用红外热成像法(Infrared thermography,IRT)和心率变化法(Heart rate variability,HRV)检测眼睛温度变化和心率变化来进行识别,但是以上方法检测速度较慢并且需要耗费大量人力。由于疼痛往往会导致羊的面部表情发生变化,所以在2016年,一种人工评估羊疼痛的标准方法——羊表情疼痛量表(Sheep pain facial expression scale,SPFES)被提出,这是一种利用羊的面部表情来检测羊疼痛的标准方法,该方法根据耳旋程度、鼻孔形状、眼睛的收缩程度等对每个区域可能存在的疼痛进行单独评分,例如眼睛完全睁开表示没有痛苦记为0分,半闭合表示可能存在痛苦记为1分,几乎完全闭合表示存在痛苦的可能性较大记为2分,然后将眼窝、脸颊、耳朵、唇颚、鼻子5个区域的评分相加,如果大于1.5分,则认为该羊存在痛苦,这种方法已被证明能够高准确性地识别羊的面部疼痛[5]。SPFES的提出证明了利用羊面部表情检测疼痛是可行的,但是评分人员需要经过专业的培训,而且可能会存在个体间标准的差异,这种对疼痛评分的人工检测方法还存在时间长和效率低的问题。
计算机视觉技术在人脸识别、疾病诊断等领域得到了非常好的应用效果[6-8]。在牧场养殖中,计算机视觉技术也能解决许多相关问题[9-10]。在2020年,NOOR等[11]利用计算机视觉技术,提出了基于迁移学习的羊痛苦表情自动分类方法,将羊脸图像作为输入,训练了深度学习模型。数据集图像中具有复杂的背景环境,但是羊的痛苦表情仅与部分面部特征有关。因此卷积神经网络会提取到许多无关的特征,对识别的准确率产生影响。在实际的畜牧养殖业中,牧场的养殖规模较大,微小的识别错误也会导致牧场的管理秩序产生混乱,因此提升识别的准确率意义重大。然而NOOR等的方法并未将与痛苦无关的面部特征去除或者减弱无关面部特征对分类准确率的影响。
本文在VGGNet(Visual geometry group network)中引入空间变换网络(Spatial transformer nets,STN)组成STVGGNet,提高对具有复杂背景的羊脸痛苦表情图像的识别准确率。针对羊脸表情数据集中图像较少的问题,对羊脸表情数据集进行扩充。利用从牧场和网络上采集的羊脸痛苦表情的真实图像对训练好的检测模型进行评价。
1 材料和方法
1.1 数据集与预处理
为了将三线插值特征法(Triplet interpolated features,TIF)引入羊脸识别中,YANG等[12]制作了一个包含600幅羊脸图像的数据集,手动标记了羊脸的边界框和特征点,该羊脸数据集没有包含表情标签,随后LU等[13]为该数据集添加了相应的表情标签。2020年,NOOR等开发了一个高分辨率的羊脸数据集,其中羊脸图像来自于ImageNet、NADIS、Pixabay、Flickr和Gettyimages等不同的网站。在该数据集中,无痛苦的羊脸表情图像被称为正常羊脸图像,具有痛苦的羊脸表情图像被称为异常羊脸图像。该数据集按照SPFES标准将2 350幅图像划分为1 407幅图像组成的正常羊脸数据集和943幅图像组成的异常羊脸数据集。
本文制作了一个符合SPFES标准的新数据集。SPFES定义的羊面部疼痛特征与耳朵、鼻子、眼睛有关。对于耳朵,SPFES定义了羊脸部正面和侧面耳朵旋转代表的疼痛程度,耳廓可见、部分可见和不可见分别代表没有疼痛、低痛和高痛。对于鼻子,用鼻孔的形状定义了疼痛程度,“U”形鼻孔代表没有疼痛,“V”形鼻孔代表有痛。对于眼睛,完全睁开表示没有疼痛,而半闭则有疼痛。本文数据集在NOOR等提出的989幅正常图像和154幅异常图像组成的部分数据集基础上,增加了887幅图像,其中435幅新增图像来自Pixabay、VCG、VEER和百度网站,其余452幅新增图像为牧场实地拍摄图像,数据采集地为内蒙古自治区鄂尔多斯市鄂托克旗亿维养殖基地。数据采集装备为佳能PowerShot-G7-X- MarkⅡ型相机,分辨率为2 400像素×1 600像素。数据采集对象为阿尔巴斯绒山羊,数量为226只,其中成年公羊56只,幼龄断奶公羊20只,成年母羊125只,幼龄断奶母羊25只,每只羊选择拍摄效果较好的2幅为数据集图像。本文将收集的图像按照SPFES标准进行了评分和分类,评分结果如表1所示,评分小于1.5分的图像总计841幅,为正常羊脸图像,评分大于1.5分的图像总计46幅为异常羊脸图像。新的数据集一共由2 030幅图像组成,其中正常羊脸图像1 830幅,异常羊脸图像200幅。图1为本文数据集部分图像。

表1 新增羊脸图像评分结果Tab.1 Score results of new sheep face images

图1 羊脸数据集部分图像示例Fig.1 Partial images of sheep face dataset
本文虽然对羊脸表情数据集进行了扩充,但是数据集的尺寸依然较小,存在过拟合的可能。过拟合是指模型将训练数据集中的采样误差,作为数据之间的差异进行拟合,从而导致模型在训练数据集中的训练误差很低,而在测试数据集中的测试误差很高(或者说泛化误差高)[14]。通常可以使用数据增强的方法扩充训练数据,以减少过拟合问题,增加泛化性能[15]。本文数据增强操作有随机旋转、随机翻转、裁剪。样本图像的数量扩充为原来的4倍,即8 120幅羊脸图像。
1.2 STVGGNet结构分析
1.2.1STVGGNet构建动机
在真实牧场环境中,通常使用固定位置的摄像头采集羊脸图像,采集到的图像中包含了许多与羊脸痛苦表情无关的特征,大幅降低了羊脸痛苦表情识别的准确率[16]。而羊脸痛苦表情仅与部分脸部特征有关,需要开发一种能够重点关注与羊脸痛苦表情相关特征区域的模型来提高准确率。因此,本文将空间变换网络加入VGGNet来提高识别羊脸痛苦表情的准确率。
1.2.2实现细节和体系结构可视化
VGGNet由卷积层、池化层和全连接层组成,根据不同的组合方式和网络深度,有多种不同的网络配置[17],本研究选择其中4种作为基础网络。本文依据研究所需的输入尺寸,对VGGNet的网络结构参数进行了优化,如图2所示。
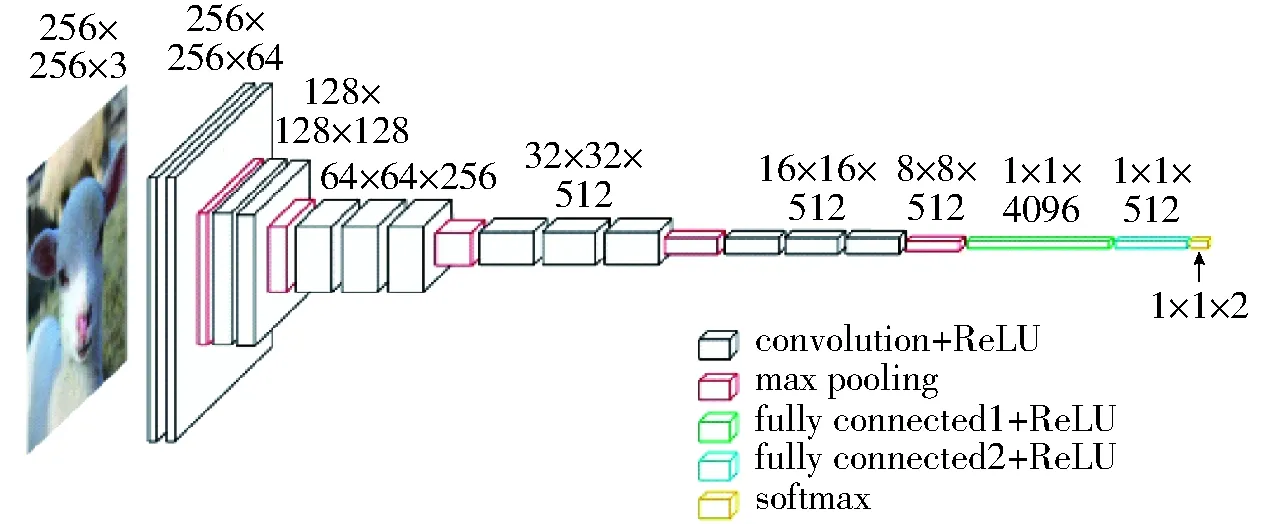
图2 VGG网络结构Fig.2 VGG network structure
在VGGNet的卷积层前加入了空间变换网络。空间变换网络可以在进行图像分类之前先学习到分类对象的特征所在区域,并通过旋转、平移、裁剪等方法生成一个新的图像,然后将新生成的图像作为分类网络的输入。该方法在MNIST手写数据集和街景门牌号数据集(Street view house numbers,SVHN)上被证明有很好的效果[18],本文将空间变换网络作为羊脸表情相关面部特征区域提取器,提取到的区域图将取代原始图像作为羊脸表情分类网络的输入。空间变换网络整体结构如图3所示,包含定位网络、网格生成器、采样器3部分。

图3 空间变换网络Fig.3 Spatial transformer network
定位网络从输入到输出的变换公式为
θ=fTθ(U)
(1)
式中fTθ——卷积函数
θ——仿射变换矩阵
U——经过数据增强的羊脸图像
fTθ是一个卷积神经网络,用于学习仿射变换矩阵,由2个卷积层、2个最大池化层和2个全连接层组成,一个卷积层使用的卷积核尺寸为8×8,另一个卷积层的卷积核尺寸为7×7。定位网络并不是直接从数据集学习如何转换,而是嵌入在图像分类网络中,根据分类网络的损失最小化原则自动学习仿射变换矩阵参数θ。
根据由定位网络得到的仿射变换矩阵θ,生成一个输入图像和转换图像之间的坐标对照网格。网格生成器生成的转换公式为
(2)




将输入图像按网格的坐标对照关系,转换为一个新图像,转发给分类网络,网格转换图如图4所示。STVGGNet的识别过程如图5所示。VGGNet与STVGGNet的参数数量如表2所示,本文提出的STVGGNet与VGGNet相比,参数数量并没有明显的增加。
2 实验与结果分析
2.1 实验配置
本文实验使用的开发平台为Windows 10,GPU为NVIDA Quadro RTX6000,深度学习框架为Pytorch1.6。进行了多次实验之后选择如下参数:优化方法为随机梯度下降(SGD)算法,动量为0.9,初始学习率为0.01,迭代周期(Epoch)为50。

图4 网格转换图Fig.4 Grid transformation diagram

图5 STVGGNet识别过程Fig.5 STVGGNet identification process

表2 参数所占内存Tab.2 Memory occupied by parameter
2.2 迁移学习
在计算机视觉应用领域中,为了达到很好的识别效果,需要很大的数据集,但是大型数据集制作成本非常高,另外从头训练需要非常高的计算性能。使用迁移学习可以满足大型数据集和高计算性能的两大需求,在训练过程中快速地获得较好的识别效果[19-20]。新制作的羊脸表情数据集属于小型数据集,直接进行训练不能达到很好的训练效果,故本文使用迁移学习对所有涉及的网络进行预训练。本文使用ImageNet数据集对VGGNet和STVGGNet进行预训练,然后对于VGGNet预训练模型,冻结全部的卷积层,使用羊脸数据集训练剩余的3个全连接层;对于STVGGNet预训练模型,也冻结全部的卷积层,使用羊脸数据集训练剩余的空间变换网络和3个全连接层。
2.3 实验结果
在本研究中,将数据集的70%用于训练,20%用于验证,10%用于测试评估VGGNet和1.2.2节中提出的STVGGNet。VGGNet和STVGGNet的分类结果如表3所示。图6为在羊脸数据集上对VGGNet和STVGGNet进行训练时的损失值。从表3中可以看出,VGGNet中VGG19的训练准确率最高,达到了99.80%,而STVGGNet中训练准确率最高的是STVGG19,达到了99.95%,比VGG19高0.15个百分点。并且STVGGNet的训练准确率均比VGGNet中对应的网络高,最多高0.44个百分点,最少高0.06个百分点。
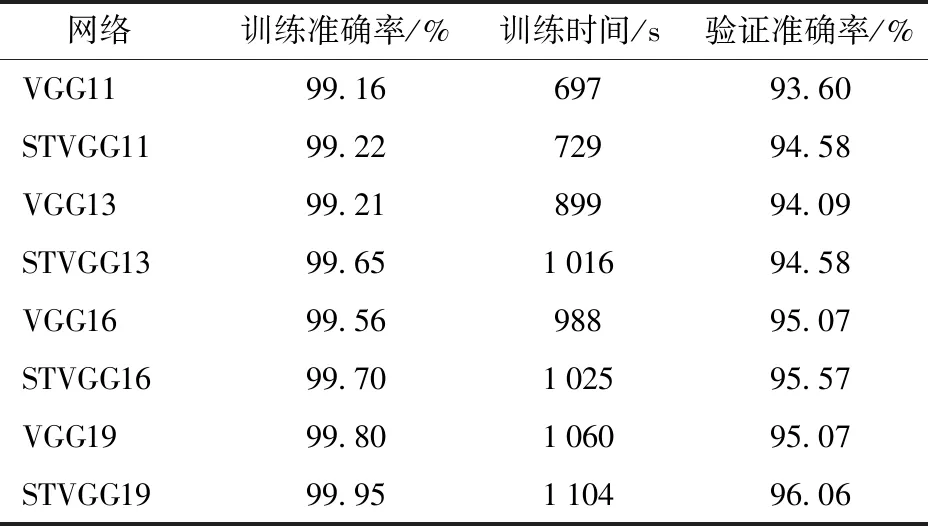
表3 网络训练准确率、训练时间、验证准确率Tab.3 Training accuracy,training time and validation accuracy of networks

图6 不同网络的训练损失值变化曲线Fig.6 Variation curves of training loss value of different networks
采用STVGGNet能够提高训练的准确率,却导致其相较于VGGNet的参数数量有所增加。参数数量上升会导致训练时间的增加。虽然STVGGNet与VGGNet相比训练时间均有所增加,但STVGGNet用较短的时间增加量换取训练准确率的提升是值得的。
STVGGNet的验证准确率得到了明显提升。如表3所示,STVGG19的验证准确率提升最多,相比于VGG19提升了0.99个百分点。STVGG13的提升最少,相比于VGG13也提升了0.49个百分点。验证准确率的提升证明了STVGGNet的泛化性能优于VGGNet。
本文对改进后的STVGGNet与VGGNet在羊脸痛苦表情识别中的表现进行定量评估时,使用混淆矩阵(Confusion matrix)、准确率(Accuracy)、错误率(Error rate)、精确度(Precision)、召回率(Recall)、F1值(F1 score)来评估两种模型。两种模型的测试结果混淆矩阵如图7所示。本文预测了两种可能的类别,分别为正常(没有痛苦)羊脸和异常(有不同程度的痛苦)羊脸。分类器测试了812幅图像,其中732幅没有疼痛,80幅有不同程度的疼痛。统计了分类实验数据的真正样本(True positive,TP)和真负样本(True negative,TN)的数量。此外,也统计了预测出的假正样本(False positive,FP)和假负样本(False negative,FN)数量。VGG19的测试结果中真正样本和真负样本分别有704幅和72幅,假正样本和假负样本分别有8幅和28幅,而改进后泛化性能最好的STVGG19的预测结果中真正样本和真负样本分别有732幅和76幅,假正样本和假负样本分别有4幅和28幅。图8展示了两种模型的部分预测结果。
所有模型对测试集预测的准确率、错误率、精确度、召回率、F1值如表4所示。评估结果表明,在羊脸痛苦表情分类测试任务中,除了STVGG16与VGG16的测试准确率相同以外,STVGGNet的测试准确率均高于对应的VGGNet,且所有的STVGGNet的F1值均高于对应的VGGNet。从整体上看,STVGGNet的分类性能要优于VGGNet。对于分类性能最好的STVGG19和对应的VGG19,虽然STVGG19的训练准确率仅比VGG19高0.15个百分点(表3),但是STVGG19模型的预测准确率高于VGG19模型0.49个百分点(表4),这说明与VGG19模型相比,STVGG19的泛化性能更好。
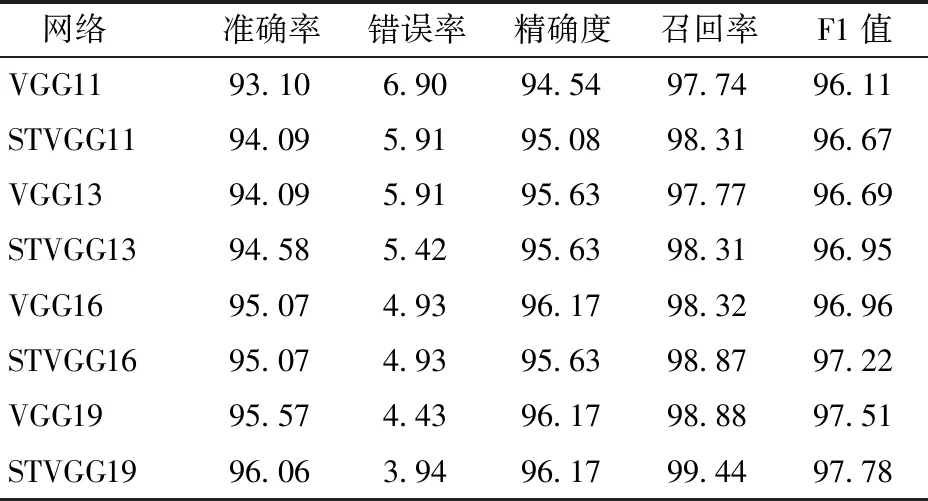
表4 准确率、错误率、精确度、召回率、F1值Tab.4 Accuracy,error rate,precision,recall and F1 value %
2.4 羊个体姿态与年龄段对识别效果的影响
为探究羊个体姿态对识别效果的影响,从数据集中成年羊站立姿态下提取的羊面部图像和躺卧姿态下提取的羊面部图像中随机抽取各30幅面部图像,总计60幅图像。使用VGG19和STVGG19对站姿、卧姿和混合状态3种情况各进行了10次测试,得到的平均测试准确率如表5所示。

表5 站姿、卧姿和混合姿态的平均测试准确率Tab.5 Average accuracy of standing,lying and mixed posture %
由表5可知,网络对站姿和卧姿时羊面部疼痛均有较好的识别效果,且站姿的识别准确率略高于卧姿。
为探究羊年龄段对识别效果的影响,从数据集中站立姿态下幼龄断奶羊提取的面部图像和成年羊提取的羊面部图像中随机抽取各30幅面部图像,总计60幅图像。使用VGG19和STVGG19对幼龄、成年和混合年龄3种情况各进行了10次测试,得到的平均测试准确率如表6所示。

表6 幼龄、成年和混合年龄的平均测试准确率Tab.6 Average accuracy of young,adult and mixed age %
由表6可知,模型对幼龄羊和成年羊面部疼痛均有较好的识别效果,而且不同年龄段的测试结果没有明显区别。
3 结论
(1)为了提高识别模型的准确率,将空间变换网络引入羊脸痛苦表情识别中,提出了STVGGNet,该模型先提取羊脸痛苦表情的相关感官特征区域,再进行分类,降低了复杂环境和痛苦表情无关的面部特征对识别效果的影响。
(2)针对羊脸表情数据集不足的问题,收集了887幅羊脸图像来扩充原有的数据集,通过SPFES方法将图像分为841幅正常羊脸图像和46幅异常羊脸图像。在羊脸表情数据集上使用迁移学习和微调的方法训练STVGGNet,并进行了测试。STVGGNet获得的最佳训练和验证的效果为99.95%和96.06%,比VGGNet分别高0.15、0.99个百分点,并且定量评估表明,STVGGNet中表现最好的STVGG19相比于VGGNet中表现最好的VGG19,除精确度相同外,召回率和F1值均高于VGG19,STVGG19在实际应用场景中性能更好。对于不同姿态和不同年龄段的羊脸图像均有较好的识别效果,站姿提取的羊面部表情识别准确率略高于卧姿,不同年龄段识别效果基本无差异。
