基于多粒度语义交互的抽取式多文档摘要①
2022-08-04郝文宁靳大尉
田 媛,郝文宁,陈 刚,靳大尉,邹 傲
(陆军工程大学 指挥控制工程学院,南京 210001)
随着网络信息的爆炸式增长,信息过载成为不可避免的问题,为了帮助用户从海量数据中快速挖掘出有价值的信息,提高获取和利用信息的效率,自动文本摘要技术受到越来越多的关注. 自动摘要技术是计算机通过人为制定的算法和输入的文章自动生成摘要的技术[1],其目的是找到输入文本的概括性关键信息. 自动文本摘要可分为几种不同的类型,根据输入文档的数量可将文本摘要分为单文档摘要和多文档摘要; 根据摘要的目的可将其分为一般的文本摘要和面向查询的文本摘要,一般的文本摘要要求在摘要中包含输入文档的全部关键信息,而面向查询的文本摘要在摘要中仅包含输入文档中与特定的用户查询相关的关键信息.
本文研究的对象是一般的多文档摘要,旨在针对单一主题下的多个文本文档生成一个简洁的摘要. 多文档摘要的方法通常分为两类: 抽取式和生成式. 生成式方法需要在理解源文档的基础上生成新的词和句子,Fabbri 等人[2]将输入的多篇文档拼接成一篇长文档作为模型的输入,然后将多文档摘要转换成一个序列到序列的单文档摘要任务; 为了避免过长的输入导致摘要退化的问题,Liu 等人[3]提出了一个层次编码器,使用注意力机制表示跨文档之间的潜在关系,允许文档之间共享信息,而不是简单的将文档拼接. 生成式的方法相对复杂,由于自然语言生成技术的限制,其生成的摘要通常存在语法错误、可读性较差等问题. 抽取式方法是从源文档中直接抽取出具有代表性的句子构成摘要,由于在很大程度上保持了原意,不会出现语法上的错误且相对简单而被广泛使用,常见的有基于质心的方法、基于图的方法以及有监督的方法等. 抽取式摘要的关键问题就是要保证抽取句子的主题覆盖度以及多样性,即摘要中包含各个方面的关键信息,且其中重复内容较少.
本文提出一种基于多粒度语义交互的抽取式多文档摘要模型(multi-granularity semantic interaction extractive multi-document summarization model,MGSI),使用多头注意力机制进行词语、句子以及文档3 种粒度之间的语义交互,使得学习到的句子表示能包含不同粒度的关键信息,以保证在计算句子重要程度时充分考虑其针对主题内容的全面性; 同时结合改进的MMR 算法通过排序学习对输入文档中的各个句子打分,该得分同时考虑句子的主题覆盖度以及与其他句子之间的重复度,选取Top-K个句子作为最终的摘要句并按照在原文中的位置对其进行排列.
1 相关研究
近年来,多文档摘要技术已经成为了NLP 中的研究热点,其相关研究能帮助用户快速筛选出关键信息.由于生成式方法需要理解并重新组织输入文档中的信息,相对复杂,当前的主流方法依然是抽取式. Radev 等人[4]将基于质心的方法应用到多文档摘要中,将文档中的重要信息浓缩成几个关键词,根据聚类中心与簇中句子的相似度以及句子的位置信息来识别重要的句子; 文献[5]在此基础上进行改进,提出用句向量表示代替词向量表示,并通过对句子内容相关性、新颖度和位置3 个指标的线性结合来改进评分函数. 基于图的方法可以利用整个文本的信息来进行排序,TextRank[6]和LexRank[7]是两种常见的图排序算法,Alzuhair 等人[8]提出将多种基于图的方法相结合,在计算边的权重时,对4 种不同的相似度计算方法进行线性组合,此外,结合两种不同的图排序算法: PageRank[9]和HITS[10]; 张云纯等人[11]提出了一种聚类和图模型相结合的方法,首先使用基于密度的两阶段聚类方法为全部句子划分主题,然后在各个子主题下建立图模型完成摘要句的抽取.
深度神经网络随着其不断发展已经被广泛应用于自动文本摘要中,且被证实能有效提高文本摘要的质量,特别地,神经抽取式方法关注学习源文档中句子的向量表示. Cao 等人[12]使用卷积神经网络训练文本分类模型,然后将文档通过分类模型进行分布式表示,利用表示向量来连接文本分类和摘要生成,解决了训练数据不充足的问题; Yasunaga 等人[13]提出使用图卷积网络获取句子嵌入,通过句子关系图来对句子进行重要性评估; Wang 等人[14]构建了一个超图网络进行摘要抽取,在句子级节点的基础上,增加更多的语义单元作为图中额外的节点以丰富句子之间的关系; Cho 等人[15]将行列式点过程(determinantal point process,DPP)应用于抽取式多文档摘要中,并使用胶囊网络[16]对DPP 中句子对之间的相似度计算方法进行改进,以保证摘要中句子的高度多样性; Narayan等人[17]通过强化学习对ROUGE 度量进行全局优化,完成抽取式摘要模型的训练,在训练期间,将最大似然交叉熵损失与强化学习的奖励相结合,直接优化与摘要任务相关的评估指标. 上述方法在对句子编码时,只考虑了句子级的语义信息,缺少对句子中单词、句子所在文档等结构化语义整合的研究. 本文通过将不同粒度的语义信息融合,使得获取的句子表示包含更丰富的语义信息,从而保证抽取出的摘要句包含的关键信息更加全面.
2 多粒度语义交互抽取式多文档摘要
在抽取式多文档摘要中,文本之间的交互对于关键信息的抽取有着重要影响,为此本文提出一种基于多粒度语义交互的神经抽取模型,我们的模型由一个多粒度编码器和一个改进的MMR 模块构成. 整体概述如图1 所示,首先构建单词、句子和文档3 种粒度的语义交互图,在同一文档的各个句子中使用多头自注意力机制self-attention 捕获语义关系,句子与句子中的单词之间使用多头交叉注意力机制cross-attention捕获语义关系,句子所在文档的语义信息通过duplicate进行传递,使用融合机制将多粒度交互信息融合,从而完成句子表示的更新,使得学习到的句向量具有更丰富的特征; 然后使用改进的MMR 算法通过排序学习对输入文档中的全部句子进行排序,完成摘要句的抽取.
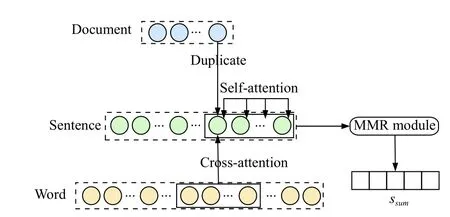
图1 多粒度语义交互抽取式多文档摘要概述图
2.1 多粒度编码器
使用多粒度编码器获取更新的句子表示. 对于输入的文档集,首先构建多粒度语义交互图,多粒度编码器的每一层包含两个部分: 第1 部分是一个注意力层,使用多头注意力机制捕获句子与句子、以及句子与单词之间的语义关系,然后使用一个融合门融合不同粒度之间的语义交互信息; 第2 部分是一个全连接的前馈网络,完成多粒度语义信息的进一步转换.
如图2 所示,di,i=1,2,···,N表示第i个文档,sij表示文档di中的第j个句子,wijk表示文档di中第j个句子的第k个单词,si∗表示文档di中的各个句子,wij∗表示句sij中的各个单词,词wijk的初始向量记为eijk,为了表明输入单词的位置信息,我们使用与Transformer[18]中一致的特殊位置编码,如式(1)所示.

图2 多粒度编码器

其中,pos表示位置索引,t表示维度索引,d表示向量的维度. 在我们的多粒度编码器中,需要考虑3 个位置编码: 文档位置编码PEi、文档中句子位置编码PEj和句子中单词的位置编码PEk,最终的位置编码和输入层的词向量分别如式(2)、式(3)所示,将初始编码与位置编码相加作为单词级别编码器的输入.

输入层的句子表示h0sij和文档表示h0di均初始化为零,句向量通过对3 种粒度的语义交互信息融合进行更新: 首先是同一文档中句子之间通过多头自注意力机制捕获的上下文表示,如图2 中所示通过selfattention 模块获取di中各个句向量hsi∗之间的交互信息;然后是句子和句中单词之间通过多头交叉注意力机制cross-attention捕获的词粒度的语义信息最后是句子所在文档传递的文档粒度的语义信息,分别如下所示:


hl−1,l=1,2,···,L表示编码器第l层的输入,hsi∗表示文档di中各个句子对应的向量,hwij∗表示句sij中的各个单词对应的向量.MHAtt即为Vaswani 等人[18]提出的多头注意力机制,在式(4)中,文档di中某一句子的输入向量作为注意力中的query,各个句子的输入向量则作为keys和values,在式(5)中,同样作为注意力中的query,而此时keys和values为句中各个单词的输入向量.
我们使用两个融合门将多粒度语义信息融合,从而获取更新的句子表示,如式(7)所示,首先将句子与单词之间的交互和句子与文档之间的交互融合,然后再将其与句子之间的交互进行融合,Fusion即表示融合门,原理如式(8)和式(9)所示,其中参数W∈R2d×1,b∈R2d×1,σ为Sigmoid 激活函数.
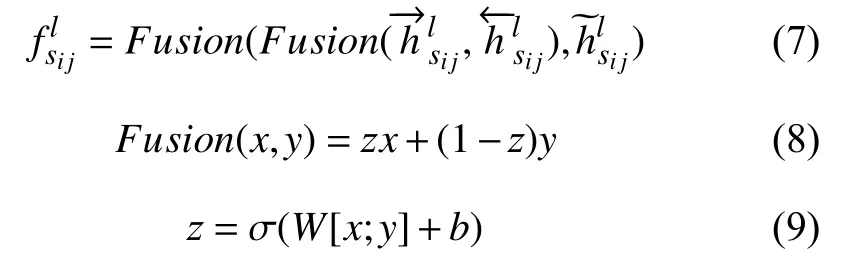
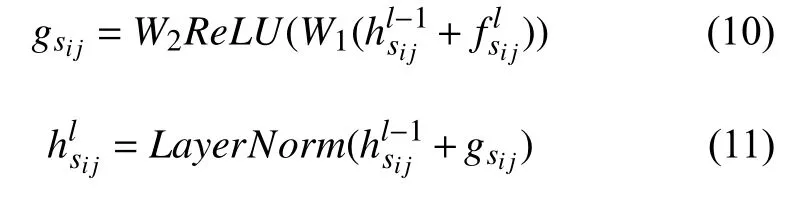
2.2 MMR 模块
MMR 算法最初用于文档检索,通过计算查询与待检索文档之间的相似度以及文档与文档之间的相似度对文档进行打分,然后对其排序. Carbonell 等人[19]首次提出将MMR 用于文本摘要中,基于与原文的相关度和冗余度为候选句打分,根据得分进行排序从而完成句子抽取,目标函数如式(12)所示,其中,R表示所有候选句子集,S表示已经选择了的句子,RS表示未被选择的句子,Q是查询,在实际摘要中,通常使用源文档或者输入文档对应的真实摘要作为这里的查询,每次选取MMR 得分最高的句子作为摘要句.
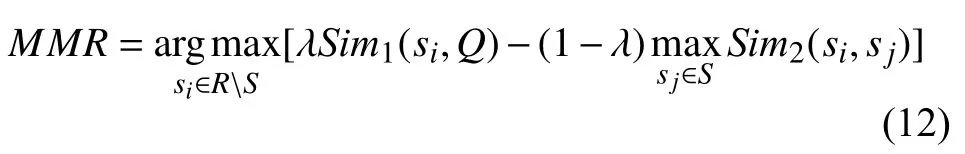
直观上来看,结合MMR 算法能帮助选择出与输入文档密切相关且彼此之间重复内容较少的句子,通过多粒度编码器,我们已经获取了输入多文档中各个句子的向量表示hLs(L表示最后一层输出),由于该向量已经包含了输入的多篇文档中不同粒度的关键信息,所以对于句子的重要程度,考虑使用基于句子本身的特征的方法代替计算句子与源文档之间的相似度,以避免相似度计算过程中丢失句子的相关重要信息,改进后的MMR得分计算公式如式(13)所示,式中的前半部分通过一个线性转换层的计算来表示句子本身的重要性,其中,Ws∈Rd×1,bs∈Rd×1,hLs表示输入文档中任意一个句子的向量; 后半部分计算句s与源文档中除该句以外的其他所有句子的相似度的最大值,这里使用余弦相似度函数,以保证最终抽取的句子包含尽可能少的重复信息,其中s′表示源文档中除s以外的其他所有句子.

然后再添加一个Sigmoid 激活函数对MMR得分进行归一化处理,如式(14)所示,σ表示Sigmoid 激活函数.
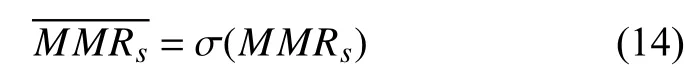
将使用多粒度编码器获取的句子特征向量输入到MMR 模块中,通过排序学习为每个句子打分,得到最终的排序列表,使用交叉熵作为损失函数,如式(15)所示,其中ys为句子的真实得分.

3 实验
实验中分别使用自动评估和人工评估的方法在公开的Multi-News 数据集上对提出的基于多粒度语义交互的抽取式多文档摘要模型进行评估,并与一些基准模型进行比较以验证本文的方法的有效性.
3.1 数据集
Multi-News 数据集是用于多文档摘要的第一个大规模数据集,其中的每个样本由一个人工摘要及其对应的多个源文档组成,其中,训练集包含44 972 个样本,验证集和测试集各包含5 622 个样本. 每个摘要平均有264 个单词,对应的同一主题的源文档平均有2 103 个单词,摘要对应源文档个数的信息如表1 所示.数据集中的摘要均为生成式摘要,为了满足本文抽取式模型的训练,我们使用Jin 等人[20]通过计算与人工摘要的Rouge-2 得分构建的标签序列.
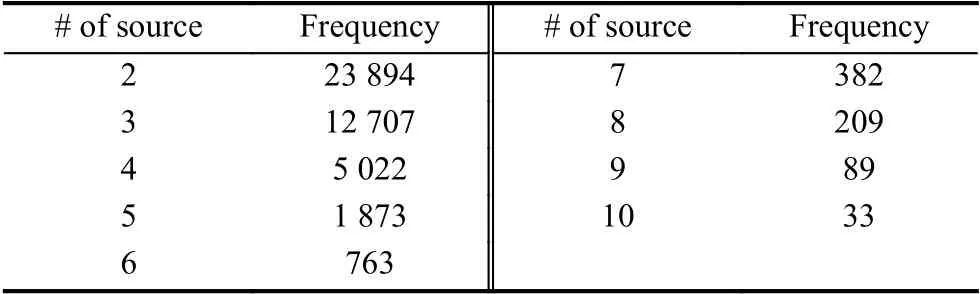
表1 源文档个数分布
3.2 基准模型
实验通过将本文提出的多粒度语义交互抽取式模型与一些经典的基准模型以及近几年中的一些强基准模型进行比较,来验证其对摘要质量改进的有效性,本节对这些基准模型分别作简要的介绍.
LexRank 是一种无监督的基于图的抽取式摘要方法,将文档中的句子作为图中节点,节点之间的连线表示句子间的相似度,通过对句子的相似性进行投票打分以确定句子的重要程度; TextRank 也是一种无监督的基于图的排序方法,句子的重要性得分通过加权图中特征向量的中心性进行计算; MMR 计算句子与原始文档的相关性以及与文档中其他句子之间的相似度,基于相关度和冗余度对候选句子打分,根据得分排名选择句子生成摘要; PGN[21]是一种基于循环神经网络的生成式摘要模型,该模型使用注意力机制,允许通过指针从源文档中复制单词,也允许根据固定词汇表生成单词,有效缓解了未登录词(out of vocabulary,OOV)的问题; CopyTransformer[22]对Transformer 进行扩展,使用一个内容选择器从源文档中筛选出应成为摘要中内容的短语,并将该选择器作为自底向上的注意力机制步骤来对模型进行约束; Hi-MAP 对指针生成网络进行扩展,将其扩展成层次网络,在摘要生成的过程中,结合MMR 模块对句子打分.
3.3 实验设置
通过初步实验对参数进行设置,将词汇量设为50 000,词向量维度和隐藏层单元数设为512,前馈层单元个数设为2 048,使用8 头注意力机制,输入时,在不同文档以及同一文档的不同句子之间分别引入特殊符号,以便于模型对不同粒度进行区分. 模型训练时,丢弃率[23]设为0.1,Adam 优化器的初始学习α=0.0001,动量β1=0.9 ,β2=0.999,权重衰减 ε=10−5,batch-size 设为10,超参数λ=0.5,在抽取句子生成摘要时,按照排序抽取Top-5 个句子作为最终的摘要句.
3.4 实验结果及分析
实验中首先使用ROUGE 得分[24]对本文的模型以及基准模型进行自动评估,基准模型中同时包含抽取式模型和生成式模型,通过对比以更好验证本文提出的方法的有效性. ROUGE 基于摘要中n元词的共现信息来评价摘要,参考Lebanoff 等人[25]的工作,实验中分别使用ROUGE-1、ROUGE-2 和ROUGE-SU4 得分作为多文档摘要自动评估的指标,ROUGE-N 主要统计N-gram 上的召回率,计算预测出的摘要与参考摘要中所共有的N-gram 个数占参考摘要中总N-gram 个数的比例; ROUGE-SU4 与ROUGE-N 不同的是它允许跳词,在对预测出的摘要与参考摘要进行匹配时,不要求gram 之间必须连续,可以跳过几个单词,考虑了所有按词序排列的词对,能更深入的反映句子级词序. 实验结果如表2 所示,其中MGSI 表示本文提出的基于多粒度语义交互的抽取式多文档摘要模型.

表2 Multi-News 数据集测试评估(%)
对于抽取式基准模型,三者在Multi-News 数据集上的表现相差很小,其中MMR 的ROUGE-1 得分比LexRank 和TextRank 分别高0.5 个百分点和0.33 个百分点,而ROUGE-2 和ROUGE-SU4 得分则均低于LexRank 和TextRank. 生成式基准模型普遍比抽取式基准模型表现好,我们认为这可能是因为Multi-News数据集中的参考摘要更倾向于使用新的单词和短语来对源文档进行总结. 在几个生成式基准模型中,Copy-Transformer 比PGN 在ROUGE-1、ROUGE-2 和ROUGE-SU4 三个指标上分别提升了近4%、9% 和6%,表明Transformer 框架在文本摘要任务中优于指针网络; Hi-MAP 则比PGN 在3 个指标上分别提升了近4%、15% 和6%,表明在指针网络的基础上添加MMR 模块能有效提高文本摘要的质量.
我们的基于多粒度语义交互的抽取式模型在ROUGE 三个指标上的得分分别是43.85、15.98 和19.62,优于所有的基准模型. 与MMR 相比,在ROUGE-1 上提升了13.1%,在ROUGE-2 上提升了33.4%,在ROUGESU4 上提升了52.0%,这说明将多粒度语义交互网络与改进的MMR 相结合抽取的摘要相对于仅用MMR模型抽取的摘要有很大的改进,我们将其归结为多粒度交互网络的有效性,使用该网络能够捕获到包含不同粒度关键信息的句子表示,从而提高文本摘要的质量; 从表中实验结果还可以看出,即使与一些生成式的强基准模型相比,我们的抽取式多文档摘要模型表现也不差,比CopyTransformer 在3 个指标上分别提升了0.6%、13.9%和13%,比Hi-MAP 分别提升了0.9%、7.3%和12.7%,表明不同粒度之间的语义交互能帮助充分利用全局信息,例如跨文档、跨句子之间的语义交互,从而使得更新后的句向量包含不同的关键信息,即在多文档摘要任务中使用层次编码框架能够有效提升摘要的质量.
为了对摘要的质量做进一步评估,我们还进行了人工测评. 人工测评要求关注3 个指标: 相关性、非冗余性和语法性. 其中相关性用来度量摘要是否覆盖源文档中的全部关键信息; 非冗余性用来度量摘要是否包含重复信息; 语法性用来度量摘要的语法是否通顺.我们从Multi-News 数据集的测试集中随机选择20 个样本,邀请3 名软件工程专业的研究生对每一个样本对应的摘要依照Likert scale 就3 个评估指标分别打分,使用五级量表,分值为1–5,1 表示最差,5 表示最好,每个指标取所有样本得分的平均值作为最终结果.我们从基准模型中分别选择一个表现较好的抽取式模型和一个生成式模型作为代表,来与本文提出的MGSI模型进行比较.
评估结果如图3 所示,本文的MGSI 模型比其他两种基准模型在3 种指标上表现都好,在相关性上,达到了3.50 的最高分,表明多粒度语义交互网络确实能够挖掘句子的深层语义,从而在计算句子重要性时能考虑到各个方面的关键信息; 在非冗余度方面,MGSI比LexRank 和Hi-MAP 分别高出了0.91 分和0.69 分,表明结合改进的MMR 算法能够有效减少摘要中的重复信息,降低其冗余度; 在语法上,Hi-MAP 模型的得分最低,这可能是因为生成式的方法需要生成新的词和句子,往往会造成语法错误,而抽取式的方法由于直接从原文中抽取句子,在很大程度上保留了原意,从评估结果可以看出,MGSI 模型的语法性得分虽然比基准模型略有提高,但是相对于其他两个指标来说比较低,这可能是因为我们对抽取的句子直接按照其在原文中出现的位置进行排序,没有进一步考虑句子之间的逻辑关系,导致生成的摘要整体上语义连贯性较差,可读性不高,这也是后续研究中需要改进的问题.
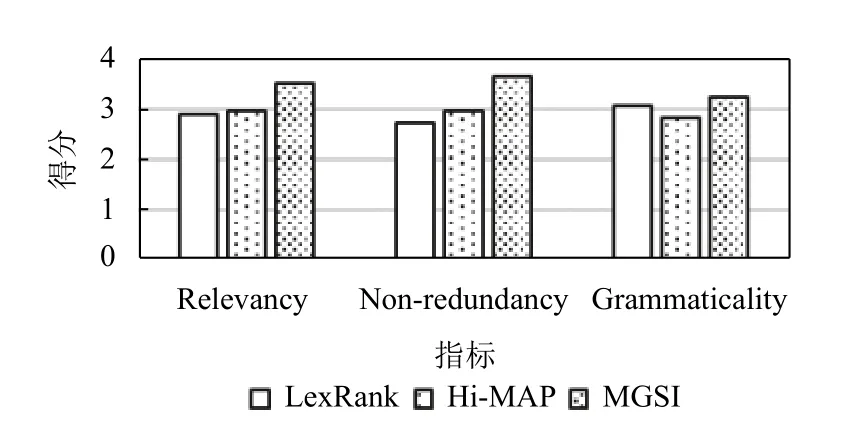
图3 人工评估
3.5 实例分析
表3 中展示了本文的MGSI 模型抽取摘要的一个实例,从抽取出的摘要本身来看,句子之间的重复内容较少,具有较低的冗余度,此外,与人工摘要进行对比发现,二者在内容上有较高的重叠,表中划线部分即为本文的模型抽取的摘要与人工摘要中完全重合的部分.这进一步说明我们提出的基于多粒度语义交互的抽取式模型能针对多文档生成一个信息较全面且重复内容少的摘要.

表3 抽取式摘要示例
4 结论与展望
本文提出了一种基于多粒度语义交互的抽取式多文档摘要模型,将单词、句子和文档3 种粒度的语义关系图与MMR 模块结合,以解决多文档摘要中存在的信息主题覆盖度低、冗余度高的问题. 通过多粒度编码器获取同一主题下多个文档中全部句子的向量表示,然后使用改进的MMR 算法通过排序学习为这些句子打分,从而完成摘要句的抽取. 在Multi-News 数据集上的实验结果表明,我们的模型优于LexRank、TextRank 等基准模型.
在当前的工作中,对于抽取出的句子,我们按照其在文档中出现的先后顺序对其进行排列,但由于抽取的句子来自于不同文档,往往会导致生成摘要的语义连贯性较差,未来我们将考虑通过学习句子的前后逻辑概率对抽取出的句子进行进一步的排序,而不是简单按照其在源文档中出现的顺序进行排列,以保证最终生成的摘要的语义连贯性,增加其可读性.
