面向电网PMU时序数据的云边协同技术①
2022-08-04郑晓露张珂珩王玉军
郑晓露,张珂珩,陈 鹏,王玉军
(国网电力科学研究院有限公司,南京 211106)
目前PMU/WAMS 系统已经在我国电力系统的实时监测、振荡告警、扰动和事故分析等方面发挥日益重要和显著的作用[1],通过对广域分布的电力系统的电气量,尤其是相量进行实时测量,为解决大型电力系统的安全分析和稳定控制等问题提供了重要支撑[2,3]. 目前典型的PMU 数据存储技术路线是采用时间序列数据库[4],通过统一支撑平台的集成,实现PMU 采集数据的存储入库以及WAMS 系统的应用[5].
目前电网调控数据由于数据源系统较多,各系统数据存在缺乏统一规范标准、数据分散、关联程度低等问题,系统间交互能力有限,数据共享困难[6]. 云计算技术由于在扩展性、可靠性方面的优势,成为电网调控数据共享的主要研究方向. 国家电网公司通过建设调控云,将云计算的特征和电网调度业务的实际需求相结合,运用虚拟化平台、多层次存储体系、智能化运维等技术,提供基础设施服务、运行环境支撑、模型数据服务等,提升了调控系统应用平台的支撑能力以及电网运行的智能化水平和全局监控能力[6,7],满足各级调控中心数据共享的需求. 南方电网公司也与阿里云签署合作备忘录,合作建设南网调度云平台,整合全网的运行基础数据,实现了各级调度资源和数据的共享. 为实现云端数据共享,文献[7]提出了主导节点、协同节点的概念,按照源端产生、全局共享方式进行数据流的规划. 对于全局统一的元数据、字典数据,全部由主导节点产生,各协同节点和业务系统只可以使用. 对于运行数据,全部由业务系统产生,汇集到协同节点和主导节点. 针对调控云端和调控系统的云边协同,文献[8]提出了一种基于边缘计算的云边协同控制方式,通过关联矩阵建立云边协同的电力物联网计算模型. 文献[9]从边缘计算的角度研究了适用于电力系统的应用范式和服务框架,并提出了边缘计算在广域发电控制、站域保护控制与符合建模评估三大场景的技术分析和应用方案. 文献[10]提出了层次化的云边协同模式,低层支持数据的临时存储,高层支持数据半永久存储. 由于PMU 数据采集密度高、数据量大[6],一直未有一套完整的云边协同方法,支撑PMU 数据的云端共享.
云边协同一般包括资源协同、应用协同、数据协同、智能协同等多种协同[11]. 本文阐述的PMU 数据云边协同方法,主要从数据协同角度介绍了从调控系统内部PMU 数据的采集存储,到云端PMU 数据的汇集和共享的整体技术路线. 针对PMU 数据采集密度高、数据量大的问题,采用了多通道收发、自动补录等方法,保证了云端PMU 数据的汇集的实时性和可靠性.针对PMU 数据的访问,提出了云端PMU 数据的关联存储模型和访问服务,便于上层应用获取PMU 数据.
1 数据协同模型
目前WAMS 系统一般通过部署在生产控制大区(Ⅰ区)调控系统支撑平台的消息总线接收前置发送的实时PMU 数据,存储在时序数据库中. 根据数据使用场景将PMU 数据分为3 类,实时数据、历史数据、案例数据. 实时数据表示PMU 当前时刻的最新数据,历史数据表示一段时间累计的数据,案例数据表示发生电网扰动等事件前后几分钟的数据. 根据调控云平台国(分)主导节点+省(地)协同节点的二级部署体系[12,13],基于某一个省(地)云环境下,整体数据协同模型如图1所示,主要包括数据跨区同步、数据汇集、数据存储和共享3 部分.
数据跨区同步是指将PMU 时序数据从调控系统Ⅰ区,同步到Ⅲ区,主要包括实时数据的同步、异常恢复数据补录、重要事件案例数据同步.
数据汇集是指多个调控系统将各自的PMU 时序数据按照云端的要求发送到云端,云端统一接收.
数据存储和共享是指云端进行PMU 时序数据统一存储,并提供基于模型的数据访问服务.
2 技术原理
2.1 跨区数据同步
由于PMU 采集频率一般为25–100 fps,按照10000 个测点量计算,存储一个月的数据需要近4 TB的存储空间[6],所以时序数据库存储PMU 数据时采用循环删除的机制,一般只循环保存1–3 个月的历史数据. 针对PMU 数据采集频率高、数据循环删除的特性,跨区数据同步采用数据报文传输形式进行,需要实现以下3 个数据流.
(1)实时数据同步: 如图1 的②–⑤,从Ⅰ区消息总线接收PMU 消息报文,格式转化后发送到Ⅲ区. 实时数据同步通道于现有时序数据库写入通道独立,避免影响现有时序数据库的正常写入,且通过消息总线保证实时同步的数据和时序数据库中的数据一致性.
(2)历史数据补录: 如图1 的③–⑥、⑭–⑮,云端发送数据历史数据补录的协同命令,从Ⅰ区时序数据库获取历史数据,格式转化后发送到Ⅲ区. 历史数据补录主要应对的场景Ⅰ区和Ⅲ区之间的网络通道故障等异常导致数据不能实时同步,在故障恢复之后进行自动的历史数据补录.
(3)案例数据同步: 如图1 的④–⑦、⑭–⑮,云端发送数据案例数据同步的协同命令,从Ⅰ区时序数据库获取电网重要事件前后5 分钟的历史数据,格式转化后发送到Ⅲ区.
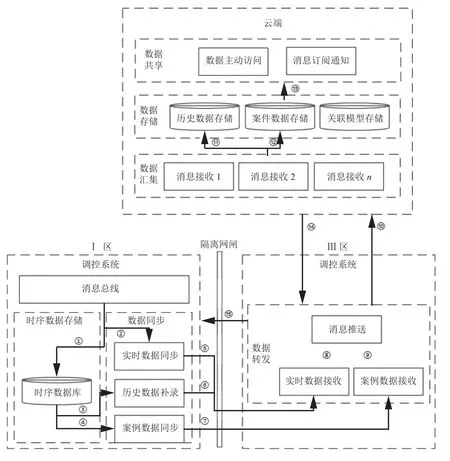
图1 PMU 数据协同模型
数据同步的数据报文格式如图2 所示: 主要包括设备ID、量测类型、数据类型、数据时间、值、质量码6 部分. 设备ID 和量测类型用于唯一确定一个PMU 设备的特定监测指标,数据类型用于表示是实时数据、历史数据还是案例数据. 因PMU 采集的数据是等周期的,所以使用一个秒级时间精确指示该报文中的数据采集时间,值和质量码分别通过连续的50/100个数表示该秒采集的50/100 帧数据值和质量码.
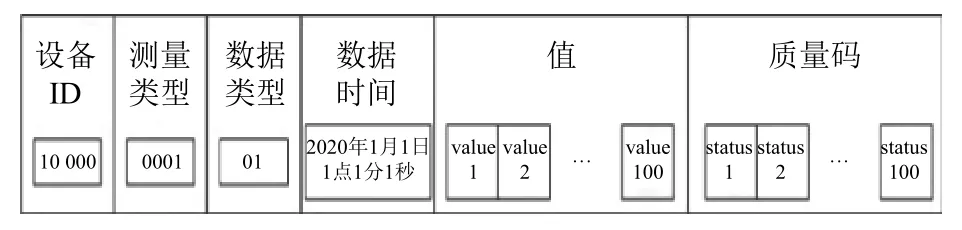
图2 同步数据格式设计
2.2 数据汇集
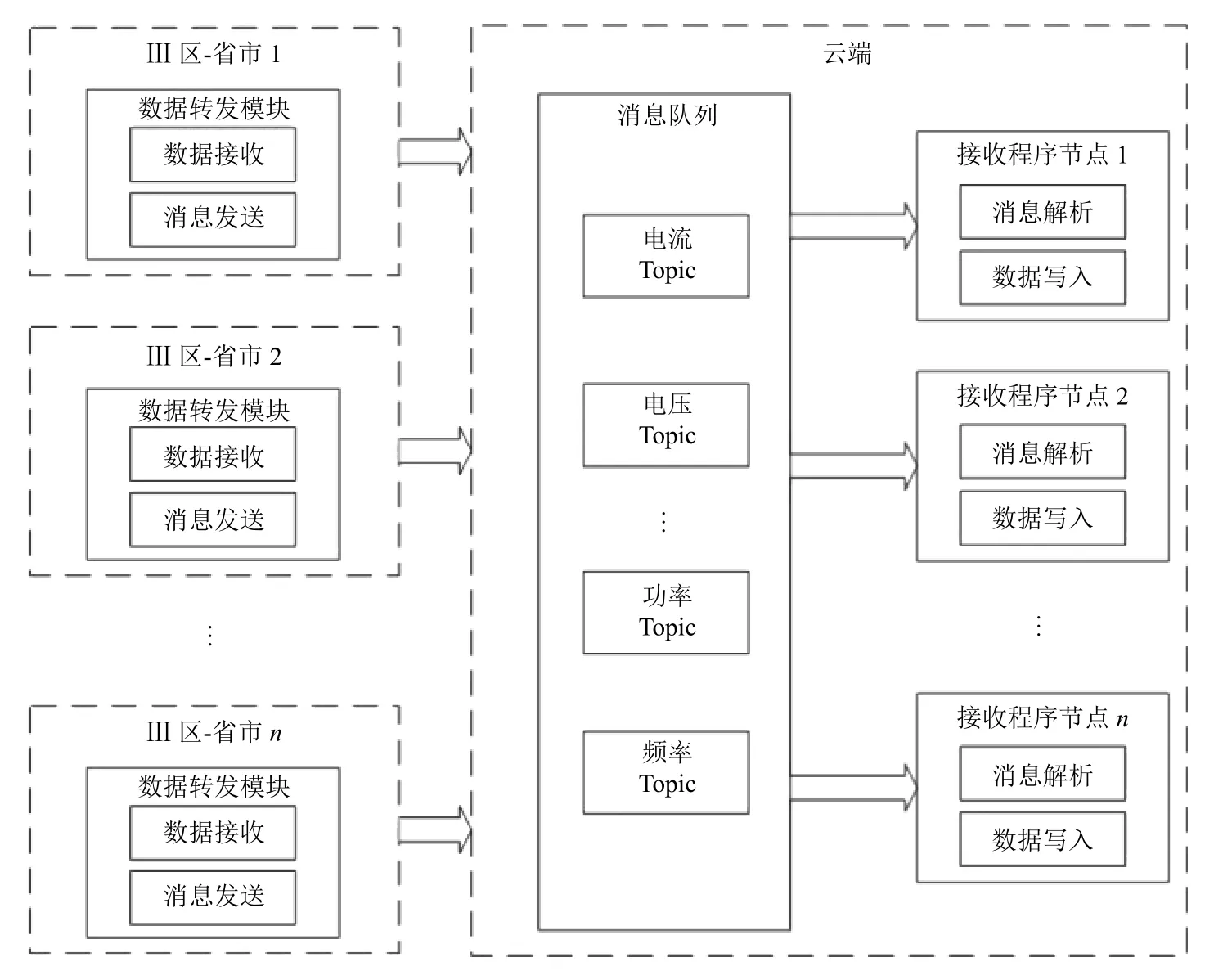
Ⅰ区数据同步模块通过隔离网闸将PMU 数据发往Ⅲ区之后,由Ⅲ区数据转发模块转发至云端. 目前主要的数据转发手段有: 基于E 文件和ftp 传输[14]、基于数据同步组件[15]、基于消息组件[16]等. 基于E 文件和ftp 传输适合非数据库之间直接的转发,基于同步工具的转发适合关系型数据库之间的数据同步复制,基于消息组件的转发适合对数据实时性要求比较高的场景.PMU 数据协同采用消息队列进行数据汇集,并在数据压缩和并行汇集方面进行优化提升.
2.2.1 面向PMU 时序数据的拟合压缩技术
通过将PMU 时序数据压缩,可有效减少网络传输的数据量,提升数据汇集的效率. 常用的压缩方式有无损压缩和有损压缩,文献[17]提出的混合熵编码并行压缩算法和文献[18]提出的有损压缩比的动态控制方法,分别在无损压缩和有损压缩进行了优化研究. 本文针对PMU 数据量大、汇集实时性要求高,且注重数据趋势的特性,拟采用一种分段拟合方式的进行有损压缩,既有较高的压缩率,也便于实时数据同步发送.
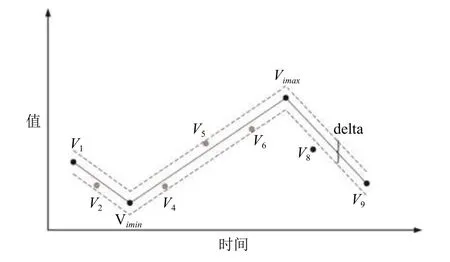
分段拟合算法的关键思路是: (1)每秒内的最大和最小值预先保留,确保数据曲线的波峰和波谷不丢失,减少压缩对数据趋势的影响; (2)通过拟合算法,将符合拟合标准的数据去除,只保留超过拟合偏差的数据,减少需要存储的数据量,达到压缩的目的.
设置当前已有N个测点Tall秒的数据,分段的时间跨度为S秒,将原历史数据按时间跨度拆分成M段,M=Tall/S,各时间段组成集合T={T1,T2,…,TM}; 设置拟合压缩的误差为delta. 算法针对N个测点的M个时间段分别进行压缩处理,然后进行结果合并. 每个时间段的处理流程如下.
(1)针对每个Ti∈T,获取Ti时间段内的所有数据V={V1,V2,…,Vcount},计算这段时间的最大和最小值Vimax和Vimin;
(2)设置压缩的中间节点为node1 和node2,将集合V拆成3 段,[V1,Vnode1),[Vnode1,Vnode2),[Vnode2,Vcount];
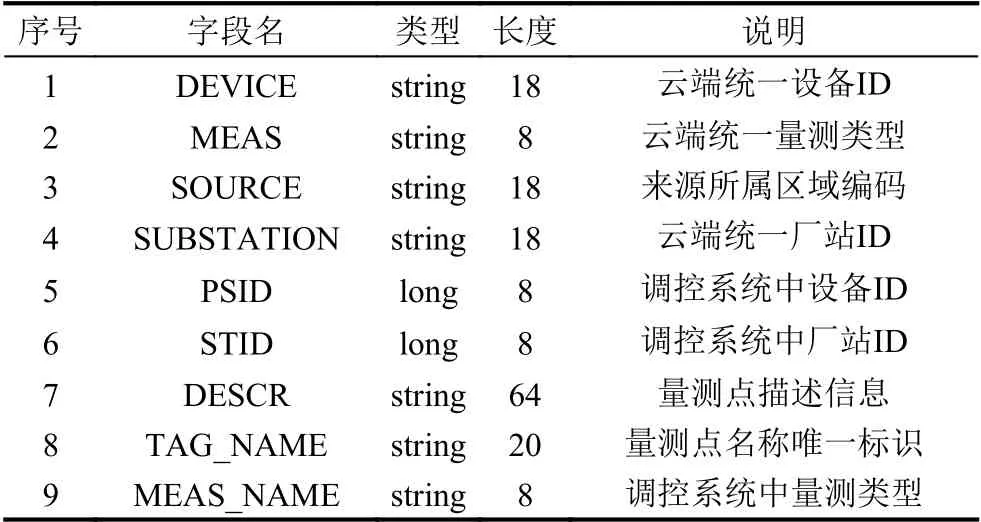
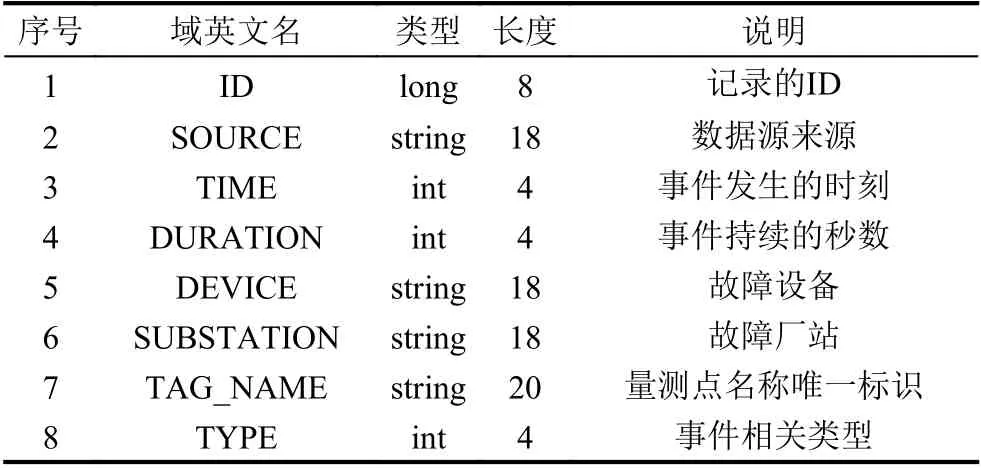
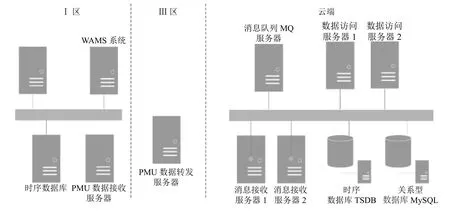
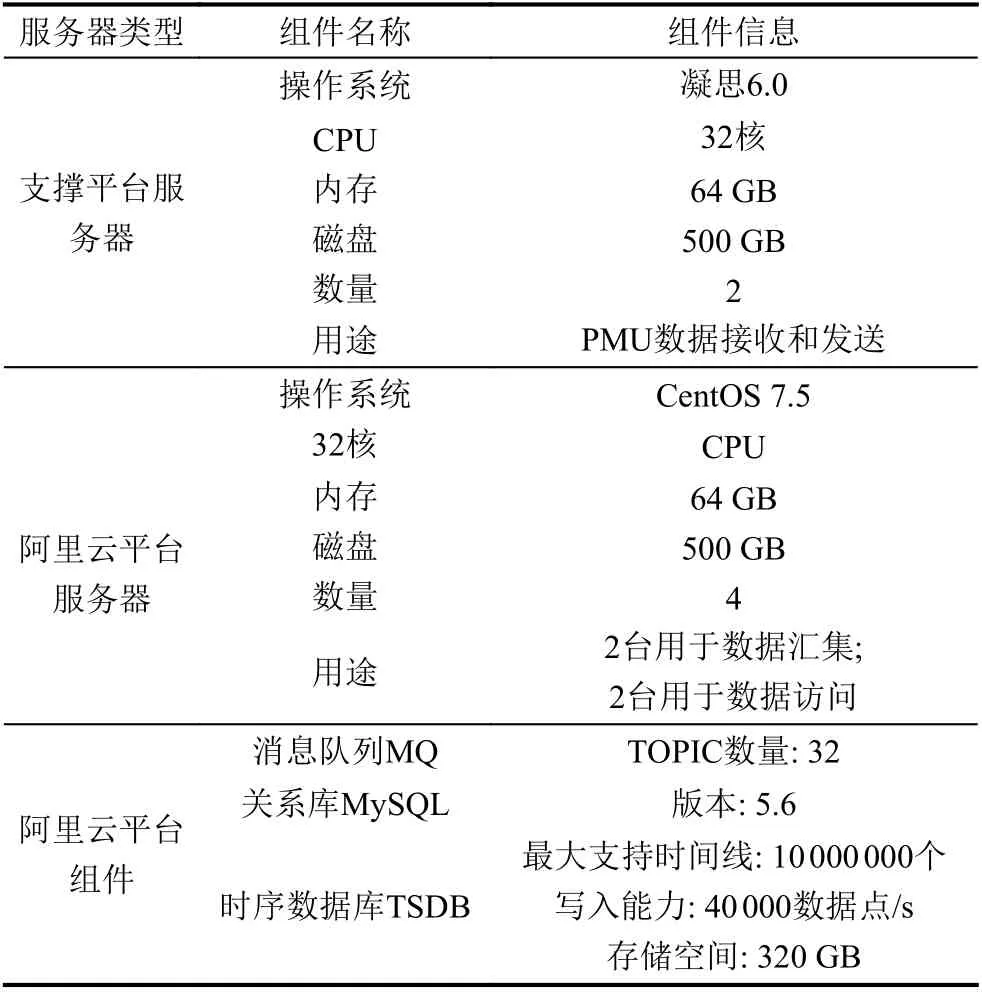
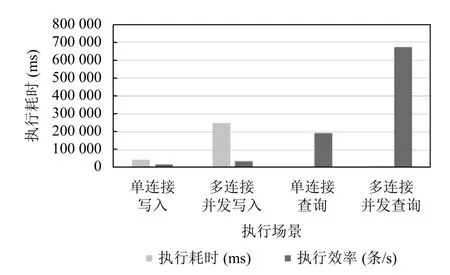
(3)比较Vimax和Vimin的时间Timax和Timin,如果Timax (4)进行[V1,Vnode1)段的拟合压缩,设置起始Vstart=V1,结束Vend=Vnode1; (5)计算从start 至end 的每个值的拟合偏差Di: (6)比较Di和delta 大小,如果Di (7)重复执行步骤(3)–步骤(4),从start 执行到end,保留的数据集合为Vresult; (8)进行[Vnode1,Vnode2)段的拟合压缩,设置起始Vstart=Vnode1,结束Vend=Vnode2,执行步骤(5)–步骤(7); (9)进行[Vnode2,Vcount]段的拟合压缩,设置起始Vstart=Vnode2,结束Vend=Vcount,执行步骤(5)–步骤(7); (10)合并步骤(4)、步骤(8)和步骤(9)3 个步骤的结果数据集合Vresult,Vresult即为最终压缩后的结果. 算法示意图如图3 所示,图中V2、V4、V5、V6符合拟合压缩条件,被压缩,V8不满足拟合压缩条件,被保留. 图3 拟合压缩算法示意图 2.2.2 面向量测类型的消息并行处理技术 PMU 接入的数据类型主要有相量(电压、电流、内电势相量、内电势功角、母线电压相量等)、模拟量(励磁电压、励磁电流、频率偏移量、频率变化率、机组转速量、机组AGC 模拟量、机组AGC 升脉冲增量、机组ACGC 降脉冲增量等)、开关量(机组开关、机组AGC 投入等)3 种[19]. 为提升消息转发的并行性和效率,通过数据类型将消息队列的消息设置成不同的消息主题. 如图4 所示,云端部署消息队列组件和多个接收程序,Ⅲ区的数据转发模块将PMU 数据按照电流、电压、频率等分为不同的主题发到消息队列中,不同的接收程序解析不同主题的消息后,写入云端时序数据库. 图4 数据汇集方法 数据转发模块,采用定时任务触发方式. 使用算法1所示算法,通过时间轮算法将任务平均分配到多个时间点,并通过一致性Hash 算法将任务发布到指定的节点上执行. 该算法能够避免所有任务同时触发造成消息拥塞,也能保证任务的可靠执行. 主要算法如图5所示. 图5 数据汇集任务调度算法 算法1. 基于时间轮和一致性Hash 的任务发布算法/* 初始化每个任务的位置,和触发时间 *//* VT 为所有任务的集合,每个周期的任务链为chain */for each tast∈VT do cacluate task.position = e.Time % 12 cacluate task.round = e.Time / 12 set chain[posion] = chain[posion] + task end/* 任务触发和发布执行 */while(true)do get current position pos for each task tast∈chain[pos] do if task.round = 0 then cacluate task.hash and IP position IPN.hash < task.hash < IPN+1.hash dispath tast to node on IPN+1 end end end if pos = 12 then for each tast tast∈VT do set task.round = task.round–1 end end end 电力调度通用数据对象结构化设计规范[20]中对电网运行数据的存储结构定义中,量测类数据主要存储的信息有时间、对象ID、量测类型、数据源标识等.PMU 数据在云端的存储参考该规范定义,结合PMU数据量大、无事务要求的特性,采用具备高可扩展能力和良好的容错能力[21]的Key-Value 型数据库进行存储. 根据汇集上云的数据类型,设计将数据分别保存到历史数据存储实例或案例数据存储实例,分别用于周期保存一定时间的历史数据以及永久保存案例数据.历史数据存储实例或案例数据存储实例存储结构一致,如表1 所示. 表1 Key-Value 数据库存储结构示意图 Key 值为数据源标识、量测类型、设备ID、时间的顺序组合,Value 存储Key 值对应的PMU 监测指标在该秒的所有帧的值和质量码,通过“#”分割成一串字符串存储. 设计该存储结构的优点如下. (1)Key 值的高位为数据源标识和量测类型,对于云端汇集的各地PMU 数据可以充分利用Key-Value数据库分布式存储的特性,将数据分布到各数据库节点,写入和查询并行度高,且数据分布范围大,不容易产生写入热点问题. (2)通过将一个PMU 监测指标1 秒钟所有帧的数据和质量码合并成一个字符串,作为一条Value 存储,减少了数据库读写的次数,提升了数据写入和查询的效率. 为提升数据存储的效率以及可靠性,采用多个存储执行器并行处理的架构,并采用算法2 所示负载均衡算法,根据活跃执行器的个数进行动态的负载均衡. 算法2. 多节点任务负载均衡算法/* VE 为所有执行器executor 的集合,所有写入的key 的总数为N */begin set alive_executor_count = 0 set executor _seqence = 0 for each e∈VE do if e is alive then set alive_executor_count + 1 set e.seqence = executor _seqence + 1 else VE = VE–e end calculate avg_key = N/executor _seqence for each e∈VE do if e is last Executor then set e.start = avg_key * e. seqence set e.end = N else set e.start = avg_key * e. seqence set e.end = avg_key * (e. seqence + 1)end end 为提升数据共享的易用性,云端提供两种数据共享模式: 主动数据访问模式和消息订阅模式,同时通过使用关系型数据库存储电网模型,提供基于模型的数据访问服务,如图6 所示. 图6 云端数据共享方法 存储层通过Key-Value 型数据库存储PMU 的历史数据和案例数据,同时利用关系型数据库存储3 类关系表: 电网模型表、量测信息表、案例信息表. 电网模型表和量测信息表用于提供基于电网模型的数据共享. 电网模型表主要包括厂站表、发电机表、变压器绕组表等表示电网设备的表,量测信息表主要结构如表2 所示,存储时序库中存储的测点与所属厂站、设备的关联关系,以及和和云端汇集后统一设备ID[20]之间的映射关系. 案例信息表主要表结构如表3 所示,保存WAMS 系统中事件发生的时间以及相关的设备信息. 表2 量测信息表结构 表3 案例信息表结构 访问层以服务化方式将云端设备ID、厂站ID 等设备统一编码转换为时序库数据存储ID,进行时序数据库中PMU 数据定位与查询. 数据访问方式如下. (1)提供数据访问接口,支持基于接口的数据访问,供高级应用调用. (2)通过“区域-厂站-设备-量测”树状结构的展示界面,显示PMU 数据. (3)通过云端内部消息队列,将应用订阅的PMU数据推送至应用. 通过本地服务器和阿里云环境,搭建测试环境进行PMU 数据云边协同可行性验证,模拟PMU 测点1 万个,采集频率为50 fps. 物理环境如图7 所示. 图7 验证环境物理部署图 所需使用资源具体如表4 所示. 表4 验证环境部署配置 验证环境部署步骤如下. (1)在PMU 数据接收服务器上部署PMU 系统数据发送程序,从平台的消息总线中实时接收PMU 数据,并发往Ⅲ区. (2)Ⅲ区PMU 转发服务器上部署转发上云模块,调用消息队列MQ 的接口通过消息方式推送数据. (3)在云平台中消息接收服务器1 和2 上部署接入程序,将消息中的设备ID、量测类型、数据时标等转为TDSB 数据库的Key 值,并写入PMU 数据. (4)在云平台MySQL 数据库中建立设备表、厂站表、量测信息表、案例信息表,录入WAMS 系统对应的设备ID 及相关信息,以及TSDB 对应的Key 值信息. (5)在云平台服务器上部署查询服务和订阅通知服务,查询服务将输入的云端统一设备ID 等查询条件,通过查询MySQL 的映射表转化为TSDB 对应的Key 值,调用TSDB 查询接口查询数据. 同时,针对云边协同中数据汇集、存储等关键场景,进行效率和参数的测试验证,主要验证以下场景. (1)跨区数据同步效率测试 测试不同大小的文件跨区同步的效率,测试参数和测试结果分别如表5 和图8 所示. 图8 跨区同步测试结果 表5 跨区同步测试参数 通过对比发现,大文件跨区传输效率远高于小文件的传输效率. 大文件传输效率约为10 MB/s,满足1 万个PMU 测点每秒50 帧的数据跨区同步. (2)拟合参数对比测试 测试设置不同的拟合参数,对压缩率和拟合结果的影响. 测试参数和测试结果分别如表6 和图9 所示. 图9 拟合参数测试结果 表6 拟合参数设置 对比实验结果发现,拟合误差较少时,能够较好地拟合原有曲线,压缩掉的点也少; 压缩单元跨度不宜设置过大,否则可能将曲线的波峰和波谷压缩掉. (3)时序数据库写入和查询能力测试 测试不同并发场景下时序数据库的写入和查询能力. 测试参数和测试结果分别如表7 和图10 所示. 图10 时序库写入和查询测试结果 表7 时序库读写测试参数设置 数据写入效率: 单连接和多连接分别为20315 和39760 条/秒; 数据查询效率: 单连接和多连接分别为193498 和675858 条/秒. 满足1 万个PMU 测点的数据存储和查询需求. 本文针对PMU 时序数据的共享需求,提出一种PMU 时序数据的云边协同方法,介绍了该方法的数据协同模型、数据汇集架构与拟合算法、数据访问服务等关键技术,并通过阿里云的实际环境验证测试该方法的可行性. 目前该方法还有两处待改进: (1)数据在云端汇集后,对于缺失或者需要重传的数据,需要在云端提供历史数据补招功能; (2)云端PMU 数据汇集后,针对电网事件对PMU 案例数据分析时,缺乏事件发生时刻对应的模型. 针对这两个问题,本文下阶段的目标是研究历史补招命令的下发执行,以及历史模型动态匹配方法.


2.3 云端数据存储


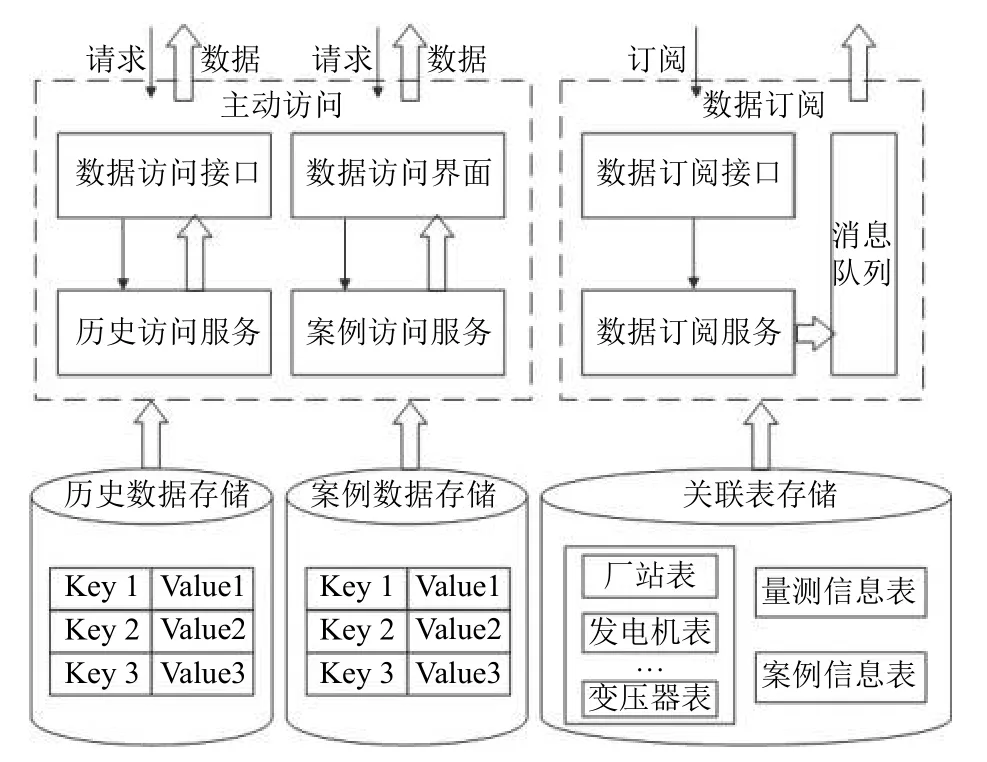
2.4 云端数据共享
3 测试验证





4 总结与展望
