基于预训练模型与无人机可见光影像的树种识别①
2022-08-04罗仙仙许松芽陈桂莲万晓会
罗仙仙,许松芽,陈桂莲,严 洪,万晓会
1(泉州师范学院 数学与计算机科学学院,泉州 362000)
2(福建省大数据管理新技术与知识工程重点实验室,泉州 362000)
3(泉州师范学院 教育科学学院,泉州 362000)
4(福建省林业调查规划院,福州 350003)
人工智能是未来的第一生产力,人工智能技术与方法在我国林业中的应用初见端倪. 遥感图像的树种识别始终是国际关注的学术前沿[1]. 无人机低空航拍受天气影响小,作业方式灵活,获取的影像比例尺大,精度高,为森林资源遥感调查研究提供了新的技术手段[2].然而,传统人工目视解译方法和遥感图像处理方法,并不能够对无人机遥感图像进行自动识别,而且精度难以保证.
深度学习是人工智能研究中重要方法,2006 年加拿大多伦多大学Hinton 等提出[3],能够模拟人的神经系统,可以从大量数据中自动提取特征. 深度学习方法用于无人机树种识别的研究刚刚起步. 由于深度学习方法依赖于大量的训练数据与测试数据,并且数据标注费时费力,一定程度限制深度学习在遥感图像树种识别研究,因此,少样本的迁移学习方法是当前研究热点. 目前,尚没有开放的无人机树种识别数据集[1],武红敢等人指出林业遥感专用数据库的必要性和紧迫性,并提出建设思路和原则[4].
迁移概念最早由心理学家提出,一般认为,迁移是指一种学习对于另一种学习的影响[5]. 在人工智能和机器学习领域,迁移学习是一种学习的思想和模式,可以利用数据、任务或模型之间的相似性,将在旧领域学习过的模型和知识应用于新的领域. 基于模型的迁移学习方法(预训练方法)是指从源域和目标域中找到它们之间共享的参数信息,以实现迁移方法[6]. 预训练模型在大数据集(如ImageNet[7])上训练得到一个具有强泛化能力的模型,作为后续任务的基准模型,通过少量有标注的数据微调训练可以取得较好识别效果.
近两年,林业遥感领域的研究学者把迁移学习应用于无人机影像的树种识别. 王莉影等[8]较早应用迁移学习思想,基于Inception-v3 模型在ImageNet 数据集上进行预训练,然后利用有限样本重新训练一个全连接层,对东北林业大学实验林场只进行针叶林、阔叶林分类研究,总体分类精度为98.4%,Kappa 系数为0.987. 滕文秀等[9]基于迁移学习思想,对4 种常规的卷积神经网络方法在ImageNet 数据集上进行预训练后,增加全局平均池化层、1 个全连接层和1 个Softmax层,对4 个树种进行分类,研究表明VGG16 作为树种分类模型的预训练模型是好的. Natesan 等 [10] 基于ResNet50 模型在ImageNet 数据集上进行预训练后,增加最大池化层和4 个全连接层,基于Keras 框架进行3 类树种分类,总体精度达80%. 总之,现有研究没有对数据集制作详细介绍,数据集尚未共享一定程度影响此领域迅速发展.
论文利用TensorFlow 框架,基于VGG16 在Image-Net 数据集上预训练模型,进行无人机可见光影像树种识别研究. 利用大疆精灵4RTK 无人机,搭载FC6310R相机,采集南平市和三明市的杉木和马尾松人工纯林彩色图像. 通过图像预处理、标注、裁剪和增强等环节构建两个数据集UAVTree2k 和UAVTree20k. 基于UAVTree2k 数据集和VGG16 模型在ImageNet 数据集的预训练模型,重新定义3 个全连接层,输出层设置成2,进行小样本的杉木和马尾松二分类研究; 验证小样本的预训练模型的有效性,以期为复杂林分环境下的树种分类与制图提供参考.
1 数据集的构建
1.1 无人机外业数据采集
杉木与马尾松数据采集,均采用无人机大疆精灵4RTK,搭载机型为FC6310R,相机像素为2000 万(5472×3648). 杉木拍摄时间为2020 年11 月19 日,图像采集天气状况好. 拍摄地点位于南平市邵武市下沙镇,地理位置位于117.60°E、27.33°N,森林覆盖率约73%,拍摄范围地势较为平坦,相对高差约100 m,拍摄高度约为150 m,拍摄对象为杉木人工纯林,拍摄方式为垂直俯视,经过图像预处理、拼接后图像(.tif 格式)如图1 所示. 马尾松拍摄时间为2020 年12 月29 日至30 日,天气状况良好. 拍摄地点位于三明市清流县温郊乡温家山村,拍摄高度约为180 m,拍摄对象为马尾松人工纯林,拍摄方式为垂直俯视,经过图像预处理、拼接后图像如图2 所示.
1.2 数据标注
采用图像标注工具LabelImg (https://github.com/tzutalin/labelImg),分别从图1 和图2 中,找出单一杉木或马尾松区域,采用矩形拉框,长宽大小不一,大约为224×224,坐标为(xmin,ymin,xmax,ymax),杉木标签设为0,马尾松标签设为1,共标注了1 058 张杉木、1 278 张马尾松图像,数据标注完成后生成.xml 文件,该文件只存储矩形拉框的坐标信息,无法直接导出已标注好的图像.

图1 杉木人工纯林

图2 马尾松人工纯林
1.3 数据裁剪
采用Python 编程实现批量数据的裁剪. 编写readXML()函数,读取xml 文件坐标,并转化为pillow模块的图像坐标格式(left,upper,right,lower); 编写save_tif()函数,从原始的.tif 图像中一次性裁剪出1058张杉木、1 278 张马尾松图片.
1.4 数据增强
数据增强是一种能够有效扩充数据集的数据处理手段. 采用10 种方式对原始数据进行增强: (1)对原始图像进行垂直翻转和水平翻转; (2)对原始图像进行逆时针90°、270°旋转处理; (3)对原始图像进行灰度化处理; (4)对原始图像进行2 种亮化处理(亮化系数分别为1.2 和1.4); (5)对原始图像进行2 种饱和度处理(饱和度系数为2 和4); (6)对原始图像进行随机裁剪,裁剪后图像大小调整为原始图像大小. 单张马尾松图片数据增强如图3 所示.

图3 单张马尾松的数据增强
1.5 数据集构建
从数据裁剪后的1 058 张杉木、1 278 张马尾松图片中,选取杉木、张马尾松各1 000 张图片构建数据集,取名为UAVTree2k,其中2 表示2 个树种,2k 表示训练集与测试集的总数为2 000 张,其中,杉木和马尾松图片各1000 张. 定义数据读取函数read_image_filenames(),读取指定目录下的图片信息,返回文件名列表和标签列表; 定义解码图片和调整图片大小函数decode_image_and_resize(),读取图片并解码,重新调整图片大小并进行归一化处理; 通过TensorFlow 框架下的tf.data.Dataset 的from_tensor_slices()方法生成小样本数据对(图片,标签). 通过数据增强,将数据裁剪后图像,扩大为10 580 张杉木图像和12 780 张马尾松图像,从中选取各10 000 张的图像作为数据集,取名为UAVTree20k,20k 表示训练集与测试集的总数为20 000 张.
2 研究方法
2.1 VGG16 模型
VGG-Net 是牛津大学计算机视觉组(visual geometry group)和Google DeepMind 公司的研究员一起研发的深度卷积神经网络[11],VGG-Net 在2014 年大规模视觉识别挑战赛(ILSVRC)中,夺得图像分类第2 的成绩. VGG-Net 的网络层数从11 层到19 层不等. 常用的VGG16 模型由13 个卷积层和3 个全连接层堆叠而成,总共包含约1.38 亿个参数. 所有卷积层使用3×3 的卷积核和ReLU 激活函数,以加强特征学习的能力.VGG16 模型整体上分为8 段,前5 段为卷积层,后3 段为全连接层. 卷积层重叠2 或3 次后形成一个卷积段,同一段内的卷积层具有相同的卷积核数,每个卷积段后有一个2×2 的最大池化层,池化层将图片大小缩小一半. 每增加一个卷积段,卷积核数增加一倍. VGG16具体结构见图4.

图4 VGG16 的结构
2.2 基于VGG16 的预训练—微调模型
基于VGG16 的预训练—微调模型如图5 所示,分为共享层和迁移层[6]. 共享层为VGG16 中前13 个卷积层,主要提取图像的低级特征. 因为这些特征是通用特征,所以共享层采用VGG16 模型在ImageNet 上训练好的模型,并冻结其权重与参数. 迁移层提取图像的高级特征,是整体模型的核心层. 重新训练3 个全连接层,其中包括输出层FC2,该层采用Sigmoid 激活函数.考虑训练样本较少,全连接层分别采用128 和32 个神经元,在FC128 和FC32 后分别加了Dropout 方法,其系数均设置为0.3,随机删除全连接层的部分神经元,防止过拟合,提高模型泛化能力.

图5 基于VGG16 的预训练—微调模型
3 实验与结果分析
3.1 云环境及其搭建
本机为Windows 10 的64 位操作系统,采用阿里云服务器2 核4G 的共享型实例,在云端搭建Tensor-Flow 2.3.0、Anacona 3.0、Python 3.7 等环境. 采用基于VGG16 的预训练-微调模型进行无人机可见光影像的树种识别,数据集采用UAVTree2k. 基于数据集UAVTree2k,进行VGG16 模型重新训练与测试. 探讨迭代次数、批次大小、数据集划分比例对训练精度与测试精度影响. 所有实验参数更新采用Adam 优化器,学习率采用0.001.
3.2 实验结果与分析
3.2.1 迭代次数对精度影响
为探讨迭代次数对精度的影响,固定训练集1200张,测试集800 张; 批次大小为16. 迭代次数依次从{10,20,30,40,50,60}中取值,得到训练集的精度分别为0.9087,0.9319,0.9800,0.9800,0.9856,0.9925,测试集的精度分别为0.9425,0.9525,0.9675,0.98,0.9675,0.9775. 精度与迭代次数关系如图6 所示. 从图6 可看出,训练精度均在90%以上,随着迭代次数的增加,训练精度整体呈上升趋势; 训练精度均在94%以上,测试精度整体上随迭代次数的增加而增加. 究其原因,随迭代次数增加,模型权重、参数不断更新,学习到的特征越多,测度精度也就越好. 当迭代次数为40 时,测试集精度下降,而后上升,其原因尚不明确. 综合训练精度、测试精度,以及训练时间,后续实验的迭代次数取40.
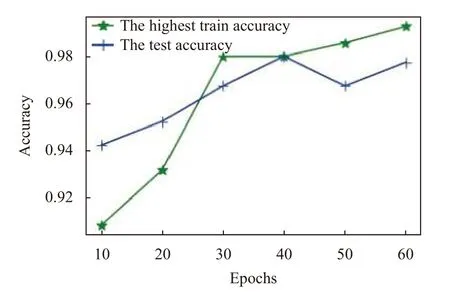
图6 精度与迭代次数关系图
3.2.2 批次大小对精度影响
为探讨批次大小对精度的影响,固定训练集1200张,测试集800 张; 迭代次数为40,批次大小依次从{10,12,14,16}中取值. 精度与迭代次数关系如图7 所示. 从图7 可看出,训练精度均在98%以上,随着批次增加,训练精度有些波动. 批次大小12 时突然下降,批次大小为14 时降到最低,此后继续增加; 测试精度随机批次大小增加而增加,在训练精度下降时,测试精度增速变缓,可能因为批次偏小,训练时反向传播的损失值不稳定导致训练精度的波动,也导致测试精度增速变缓. 综合训练精度、测试精度,最优批次大小取16.
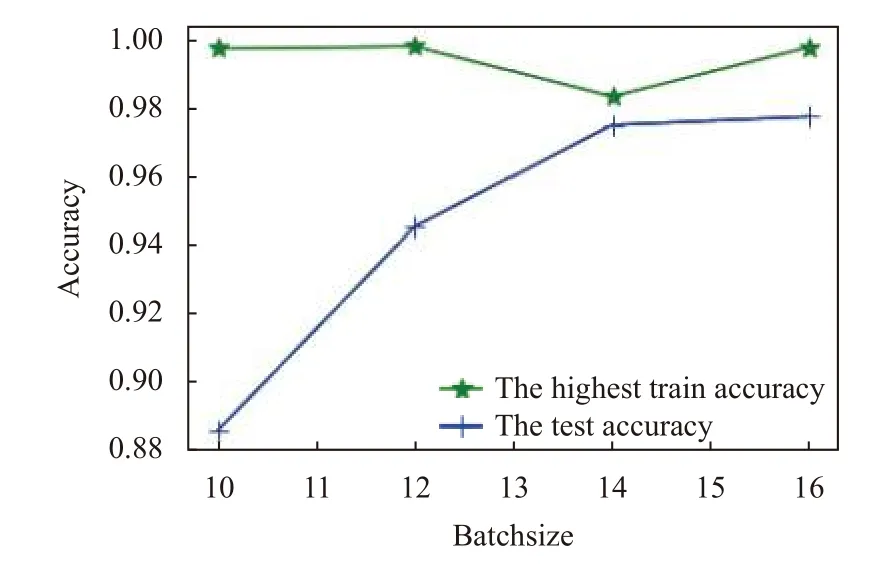
图7 精度与批次大小的关系图
3.2.3 不同数据集划分比例对精度影响
为了探讨不同数据集划分比例对精度的影响,验证预训练-微调模型在小样本下的识别效果. 训练集与测试集按8:2、7:3、6:4 和5:5 四种比例划分. 这4 种比例的测试精度分别为98%、98%、98.63%、98.20%.4 种比例划分训练集的占比依次减少,但实验结果表明准确率有上升趋势,其中6:4 的测试精度最高,达到98.63%. 原因可能是VGG16 模型是在ImageNet 上训练过的,共享层的权重和参数进行了冻结,可以较好提取物体识别的通用特征,同时,进一步验证,预训练-微调模型在小样本下,可以取得较好的分类效果. 体现了迁移学习具有良好的特征学习能力.
4 结论与展望
4.1 结论
(1)论文利用预训练-微调模型,进行无人机可见光影响的树种识别,通过实验研究,在小样本下,模型可以取得较好的分类效果. 体现了迁移学习具有良好的特征学习能力.
(2)模型超参数直接影响模型识别效果,当迭代次数为40,批次大小为16,训练数据与测试数据划分比例为6:4,模型识别效果最好,测试精度达到98.63%.
(3)利用大疆精灵4RTK 无人机,搭载FC6310R 相机,采集南平市和三明市的杉木和马尾松人工纯林彩色图像. 通过图像预处理、标注、裁剪和增强等环节自主构建两个数据集UAVTree2k 和UAVTree20k,分别可用于预训练模型和其他卷积神经网络模型的实验研究.
4.2 研究不足与展望
(1)由于标注工作量大,自主构建的数据集只有2 个树种,可进一步采集南方主要树种,把数据集扩充到10 树种,每个树种有10000 条数据集,最终形成无人机可见光影像的数据集UAVTree,并开放共享,供不同模型与不同算法比较.
(2)预训练模型是基于ImageNet 数据集,是普通图像识别的数据库. 而遥感图像的树种识别或无人机影像的树种识别,目标是空对地的识别,因此,预训练模型可采用中国科学院遥感与数字地球研究所建立的全国地表类型遥感影像样本数据集[12],可提高源域和目标域间数据的相似度,通过预训练,把参数调整到合适的范围,从而提高识别效果或至少减少训练模型时间.
(3)论文基于VGG16 预训练-微调模型,只针对数据集进行实验研究,在完成数据集UAVTree 时,可对复杂林分下的树种进行分类与制图. 同时,非常迫切建立不同传感器的无人机树种数据集,生成超大规模预训练树种识别模型.
(4)论文基于云服务器开展实验处理,下一步可进行多GPU 资源分布式训练方法,如数据并行、模型并行、流水并行等. 如何从框架层次自动解决并行策略选择问题是最近的研究热点.
