基于近似约简与最优采样的集成剪枝①
2022-08-04王安琪张友强杜军威
王安琪,江 峰,张友强,杜军威
(青岛科技大学 信息科学技术学院,青岛 266061)
集成学习近年来得到广泛研究[1–5]. 为了构建一个有效的集成分类器,研究者提出了不同的方法来训练一组好而不同的个体分类器. 现有的集成方法大致可分为两类,即基于单模态扰乱的方法和基于多模态扰乱的方法,其中,第1 类方法又包括基于重采样的方法(如Bagging、Boosting 等)[6,7]、基于特征子空间的方法[8–10]等. 与第1 类方法不同,基于多模态扰乱的方法[5,11,12]在训练个体分类器的过程中使用了多种扰乱技术,其动机是: 很多时候单一类型的扰乱可能不足以产生多样性大的个体分类器. 早期的集成方法通常对所有的个体分类器进行集成,然而,这种做法并不一定能够保证个体分类器之间的多样性. 对此,研究者们进一步提出了不同的集成剪枝方法[4,13,14]. 集成剪枝的主要目的是通过删除一些个体分类器来提升个体分类器之间的多样性(即只利用一部分多样性大的个体分类器来构建集成分类器). 研究表明,集成剪枝能够有效提升集成学习的性能.
为了增加个体分类器的多样性,多模态扰乱策略被广泛应用于集成学习,并形成了不同的基于多模态扰乱的集成方法. 例如,Lattine 等提出一种用于集成C4.5 决策树的多模态扰乱策略[15],该策略将Bagging和随机子空间(RSM)方法结合起来. 与基于单模态扰乱的方法相比,Lattine 等的方法具有更好的性能. Altinçay提出一种基于多模态扰乱的集成方法,该方法使用遗传算法(GA)来选择特征子集和最优重采样[16]. 实验结果表明: Altinçay 的方法要优于基于单模态扰乱的RSM方法. Zhou 等[11]提出一种集成KNN 分类器的多模态集成算法,该算法对训练数据、特征空间和学习参数同时进行扰乱. 与每一种基于单模态扰乱的方法相比,Zhou 等的方法都可以取得更好的性能.
本文从粗糙集[17]中的属性约简技术出发,提出了一种新的可同时扰乱属性空间和训练集的集成剪枝算法EPA_AO. EPA_AO 的主要思路如下: (1)假设T和V分别表示训练集和验证集,我们通过近似约简技术从T的属性集中产生M个近似约简AR1,…,ARM.(2)针对任意ARi(1≤i≤M),对T中的样本进行H次bootstrap 采样,获得H个采样集S1,…,SH并从中选择关于ARi的最优采样集Oi. 具体而言,对于任意采样集Sj,我们利用ARi来对Sj进行约简,再利用分类算法在Sj上训练个体分类器Cj(1≤j≤H). 然后,利用V来分别评价个体分类器C1,…,CH的性能,并将性能最好的个体分类器所对应的采样集作为ARi的最优采样集Oi. (3)利用ARi以及ARi所对应的最优采样集Oi来训练个体分类器ICi(1≤i≤M). (4)基于多数投票的策略,将个体分类器IC1,…,ICM集成在一起,从而得到集成分类器.
本文的工作主要包括3 个部分: 首先,在粗糙集中引入近似约简的概念,并提出一种计算近似约简的算法; 其次,设计出一种基于近似约简与最优采样的多模态扰乱策略: 通过近似约简来扰乱属性空间,并通过最优采样技术来扰乱训练集; 最后,基于上述多模态扰乱策略,提出一种集成剪枝算法. 该算法通过计算近似约简及其对应的最优采样集,可以在保证个体分类器性能的前提下,有效提升个体分类器的多样性. 证据KNN (K-近邻)分类算法[18]简单、有效,并且在许多领域都得到了广泛应用. 相对于传统的KNN 算法,证据KNN 算法通常具有更好的性能. 因此,在实验中我们使用证据KNN 算法来训练个体分类器. 我们利用多个UCI 数据集来比较EPA_AO 与现有的集成学习算法的性能. 实验结果表明,EPA_AO 具有更好的分类性能.
1 预备知识
在粗糙集理论中,信息系统是一个四元组IS= (U,A,V,f),其中,U是一个非空、有限的对象集;A是一个非空、有限的属性集;V=∪a∈AVa是所有属性论域的并集(Va表示属性a的值域);f:U×A→V是一个信息函数,使得对任意a∈A,u∈U,f(u,a)∈Va[17,19]. 如果进一步把属性集A划分为条件属性集C和决策属性集D,则这种特殊的信息系统被称为决策表DT= (U,C,D,V,f).
定义1. 不可分辨关系. 给定决策表DT= (U,C,D,V,f),对任意B⊆C∪D,我们将由B所确定的不可分辨关系IND(B)定义为[17,19]:
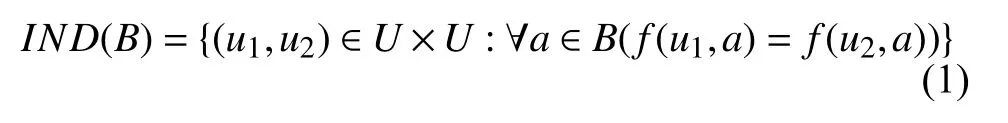
不可分辨关系IND(B)实际上是U上的一个等价关系,它将U划分为多个不相交的等价类. 令U/IND(B)表示IND(B)所对应的所有等价类的簇,我们称U/IND(B)为由IND(B)所确定的论域U的划分. 对任意u∈U,令[u]B表示U/IND(B)中包含对象u的等价类[17,19].
定义2. 正区域. 给定决策表DT= (U,C,D,V,f),对任意B⊆C,我们将D的B-正区域POSB(D)定义为[17,19]:

定义3. 核属性. 给定决策表DT= (U,C,D,V,f),对任意b∈C,如果POSC−{b}(D)≠POSC(D),则我们称b是C中相对于D的一个核属性[17,19].
给定决策表DT= (U,C,D,V,f),C中所有核属性的集合被称为C相对于D的核.
定义4. 约简. 给出决策表DT= (U,C,D,V,f),对任意B⊆C,如果POSB(D)=POSC(D)并且对任意b∈B,POSB−{b}(D)≠POSB(D),则我们称B为C相对于D的一个约简[17,19].
接下来,我们分析证据KNN 的原理. 证据KNN是由Denoeux 所提出的一种分类算法[18],它将训练样本在输入空间不同部分的分布信息融入到传统的KNN中,其主要思想是: 从所有训练样本中计算出测试样本t的k个最近邻,将每个最近邻都作为支持t所属类的证据,然后结合所有最近邻的基本概率赋值来得到t的类别[18].
令L ={l1,…,lh}表示由h个类标签所组成的标签集,T= {(u1,C(u1)),…,(ug,C(ug))}表示由g个样本所组成的训练样本集,T中每个样本都用一个二元组(uj,C(uj))来表示,其中,uj表示第j个样本,C(uj)∈L表示uj所属的类别标签,1≤j ≤ g.令Nw= {(v1,C(v1)),…,(vk,C(vk))}⊂T表示T中距离当前的测试样本tw最近的k个训练样本(即tw的k-最近邻),Nw中每个元素也用一个二元组(vj,C(vj))来表示,其中,vj表示tw的第j个最近邻,C(vj)∈L表示vj所属的类别标签,1≤j ≤k.对于tw的任意一个最近邻vj(1≤j ≤ k),如果C(vj)=lp∈L,则我们将 (vj,lp)看作是支持tw被分类为lp的一个独立证据.
每一个独立证据 (vj,lp)的可信任度都由一个基本概率赋值函数来度量,即该基本概率赋值函数的值越大,则证据 (vj,lp)的可信任度越高. 具体而言,(vj,lp)中所包含的分布信息将采用以下的基本概率赋值函数来刻画:Ew,j({lp})=β,Ew,j(L)= 1−β.在上述基本概率赋值函数中,β∈[0,1],β的具体取值由vj与tw的距离d(vj,tw)所决定(通常情况下,距离越大,则β越小). 很多学者通过定义相似函数来描述β与距离d(vj,tw)的关系,例如Denoeux 将相似函数定义成[18]: β=β0×e−γs×d(v j,tw)2.在上面的相似函数中,0 <β0<1 是一个预先指定的参数,而γs> 0 则是另一个预先指定的参数. 对任意vi,vj∈Nw,如果i≠j,则Ew,i与Ew,j是相互独立的,这是因为这两个基本概率赋值函数是由不同的训练样本所生成的. 利用证据理论的组合规则,将Ew,1,…,Ew,k都组合起来,从而获得Ew=⊕vi∈NwEw,i.在获得Ew之后,就可以利用其来计算tw相对于各个类标签的置信度 函数,从而实现对测试样本tw的分类.
2 近似约简与EPA_AO 算法
在粗糙集中,给定决策表DT= (U,C,D,V,f),一个约简R是条件属性集C的最小子集,它能充分识别具有不同类别的对象. 理论上已经证明,基于约简R所训练的分类器与基于C所训练的分类器具有相等的分类能力[20]. 一些学者提出在C的每一个约简上训练一个个体分类器,并利用这些个体分类器来构建集成分类器. 由于C的约简与C具有相同的区分能力,因此,基于这些约简所构建的个体分类器不仅可以保证个体分类器的分类能力,还可以保证每个个体分类器之间具有较好的差异性,降低个体分类器训练的复杂度,从而高效率地训练出性能优异的分类器. 也就是说,我们可以利用粗糙集的属性约简技术来扰乱属性空间. 然而,利用属性约简技术对属性空间进行扰乱时将面临以下问题: 约简个数过少. 很多时候,在决策表DT中,只存在少量的C的约简. 如果没有足够多的约简,那么我们就不能训练出足够多的个体分类器. 特别是,如果只存在一个约简,那么我们就只能获得一个个体分类器. 为解决上述问题,本文提出近似约简的概念,通过放宽对约简的严格要求(即C的约简必须与C具有完全相同的区分能力),可以获得足够多的C的近似约简.下面,我们首先在粗糙集中引入近似约简的概念,利用近似约简我们可以构建足够多的个体分类器; 其次,我们将近似约简与最优采样技术相结合,从而设计出一种新的多模态扰乱策略; 最后,基于上述多模态扰乱策略提出集成剪枝算法EPA_AO.
2.1 近似约简
近似约简是对粗糙集中经典的约简概念的推广.前面提到给定决策表DT= (U,C,D,V,f),如果R是C的约简,则R与C必须具有完全相同的区分能力,即|POSR(D)| = |POSC(D)|. 根据上述严格的要求,我们可以得到关于C的约简,但是往往约简的数量不够多. 对此,有必要对上述要求进行适当地放宽,即要求R的区分能力不需要完全等于C,而是在一定程度上近似等于C. 基于上述考虑,我们可以提出近似约简的概念.与约简不同,近似约简的区分能力可以小于C.
定义5. 近似约简. 给定决策表DT= (U,C,D,V,f),对任意AR⊆C,如果|POSC(D)| ≥ |POSAR(D)| ≥δ×|POSC(D)|,则AR被称为C相对于D的δ-近似约简,其中,δ∈(0,1]是一个给定的阈值.
由上述定义可以看出,近似约简AR的区分能力不需要完全等于C(即|POSC(D)| ≥ |POSAR(D)|),而是近似等于C(即 |POSAR(D)| ≥δ×|POSC(D)|),且近似的程度由阈值δ来控制.δ的值越大,则AR的区分能力越接近于C,特别是当δ=1 时,近似约简AR就变成经典的约简. 接下来,我们给出算法1,用于计算C中所有的近似约简.

算法1. 近似约简的计算输入: 决策表DT= (U,C,D,V,f),其中,U={u1,…,ug},C={a1,…,an}; 参数S 与MI,其中,S 是预先给定的近似约简的数量,MI 是最大迭代次数.输出: 近似约简集SAR.初始化: Core ← Ø,SAR ← Ø,其中,Core 表示所有核属性的集合.1)采用计数排序的方法来计算D 的C-正区域POSC (D)[19].2)对任意 1≤ j ≤ n,循环执行下列语句:3)采用计数排序的方法来计算POSC-aj;4)如果POSC-aj(D)≠ POSC (D),则Core ← Core∪{aj}.5)Remain ← C – Core.6)如果Remain=Ø,则SAR ← SAR∪C,并跳转到步骤17).7)如果Remain≠Ø,则对任意 1≤ i ≤ MI,循环执行下列语句:8)Temp ← Core;9)从Remain 中随机选择一个属性a;10)Temp←Temp∪{a},Remain ← Remain – {a};11)对任意属性b∈Remain,计算b 相对于Temp 和D 的重要性Sig (b,Temp,D),其中,Sig (b,Temp,D)= (|POSTemp∪{b}(D)|–|POSTemp(D)|)/ |U|;12)选择Remain 中重要性最大的属性bmax;13)Temp ← Temp∪{bmax},Remain ← Remain – {bmax};14)重复执行步骤11)–13),直到满足近似约简的条件,即|POSTemp(D)≥ δ×|POSC (D)|;∉15)如果Temp SAR,则SAR ← SAR∪{Temp};16)如果 |SAR| = S,则结束当前循环.17)输出SAR.
对任意B⊆C,计算D的B正区域POSB(D)的时间复杂度通常为O(|U|2). 在算法1 中,我们通过计数排序的方法[21]来计算POSB(D),时间复杂度仅为O(|B|×|U|).在最坏的情况下,算法1 的时间复杂度为O(MI×|C|3×|U|),空间复杂度为O(|U|+|C|).
2.2 算法EPA_AO
由于只采用近似约简来扰乱属性空间可能还不足以保证个体分类器的多样性,因此,本文将近似约简与最优采样技术结合在一起来实现一种多模态的扰乱,即不仅对属性空间进行扰乱,而且还利用最优采样技术来扰乱训练集. 在上述多模态扰乱策略的基础上,我们提出了集成剪枝算法EPA_AO. 在EPA_AO 中,对于每个近似约简ARi(1≤i≤M),我们首先对训练集进行多次bootstrap 采样,然后选择关于ARi的最优采样集Oi. 与其他采样集相比,在Oi上训练的个体分类器具有最高的分类性能. 我们最终利用近似约简ARi以及ARi所对应的最优采样集Oi来训练个体分类器ICi(1≤i≤M),并对IC1,…,ICM进行集成.

算法2. EPA_AO 算法输入: 训练集TS = (U1,C1,D1,V1,f1); 验证集VS = (U2,C2,D2,V2,f2);参数H,其中,H 表示为选择最优采样集而提前生成的bootstrap 采样集的个数.输出: 集成分类器EC.1)利用算法1 计算出TS 中的所有近似约简(令AR1,…,ARM 分别表示这些近似约简).2)对任意 1≤ i ≤ M,循环执行下列语句:3)利用ARi 对TS 进行约简,并且令TSreduced = (U1*,ARi,D1,V1*,f1*)为约简后的训练集.4)利用ARi 对VS 进行约简,并且令VSreduced = (U2*,ARi,D2,V2*,f2*)为约简后的验证集.5)对任意 1≤ j ≤ H,循环执行下列语句:6)对TSreduced 中的U1*进行bootstrap 采样,生成采样集Sj;7)利用给定的分类算法在采样集Sj 上训练一个个体分类器Cj;8)利用VSreduced 来评价个体分类器Cj 的性能.9)从C1,…,CH 中选取分类性能最好的个体分类器Cmax 以及Cmax 所对应的采样集Smax,并且令Oi = Smax 表示关于近似约简ARi的最优采样集,其中,1≤ Cmax ≤ H.10)将Cmax 作为最终由近似约简ARi 以及最优采样集Oi 所训练的个体分类器ICi.11)基于多数投票的策略,将个体分类器IC1,…,ICM 集成在一起,从而得到集成分类器EC.
3 实验结果及分析
为了评价EPA_AO 的有效性,我们开展了相关实验. 实验采用9 个来自于UCI 机器学习库的数据集,并使用证据KNN 算法来生成个体分类器. 关于这9 个数据集的具体信息见表1.
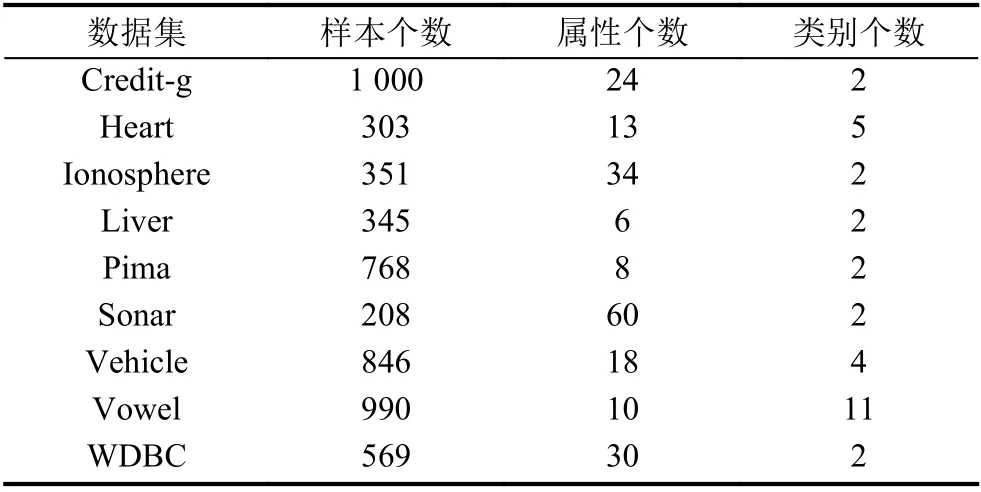
表1 实验数据集
我们基于Java 实现了EPA_AO. 在实验中,对于表1 中的任意数据集T,我们首先使用等宽度算法对T中每一个连续型属性进行离散化处理,其中,bins=5;其次,我们将T随机划分成一个训练集Train (占样本总数的50%)和一个测试集Test (剩下50%的样本);然后,由于我们要为EPA_AO 提供一个单独的验证集VS来获得当前近似约简AR的最优采样集,因此我们从Train 中随机选择50%的样本来生成VS.
在运行证据KNN 算法之前,我们要对β0与γs这两个参数的取值进行设置. 在我们的实验中,β0被设置为 0.95,而γs则被设置为相应类别训练样本的平均距离的倒数[12],在经过多次取值实验后,发现β0为0.95时证据KNN 算法训练出的个体分类器精度最好. 对于EPA_AO,我们需要对S和MI 这两个参数以及阈值δ的取值进行设置. 在我们的实验中,S和MI分别被设置为10 和25,而δ则被设置为 0.9 (实验发现,S设为10 时既能避免约简个数太少而影响集成分类器的分类性能,也不会因约简太多而影响训练的效率;MI设为25 时实验效果最佳;δ设为0.9 时能够保证约简
后的个体分类器的分类能力与约简前比较接近,不会因为分类能力下降太多而影响集成分类器的整体性能).
下面,我们首先比较EPA_AO 与文献[12]中所采用的RSM 方法的性能. 在文献[12]中,RSM 也通过证据KNN 算法来生成个体分类器. 证据KNN 的性能依赖于k的值,因此,对于每个数据集,我们为k赋予不同的取值(即k= 3、k= 5 和k= 7),从而得到不同k值下的实验结果.
表2 给出了EPA_AO 和RSM 这两个算法在不同k值下的分类性能(为了避免偶然性,我们将全部实验都重复执行10 遍,表2 中所列出的实验结果都是这10 次实验的平均值).

表2 EPA_AO 和RSM 算法在不同k 值下的准确率
根据表2,我们可以得出这样的结论: EPA_AO 的分类准确率在大部分数据集上都比RSM 更高. 具体而言,如果将k设置为7,则EPA_AO 的准确率在所有数据集上均要优于RSM; 如果将k设置为 5,则EPA_AO的准确率在除了Vowel 之外的其余8 个数据集上均要优于RSM; 如果将k设置为 3,则EPA_AO 的准确率在其中5 个数据集上要优于RSM,而在另外4 个数据集上 (即Ionosphere、Sonar、Vowel 和WDBC)要低于RSM. 特别是,如果我们统计多个k值下的平均准确率,则可以发现EPA_AO 的性能在总共7 个数据集上(除了Vowel 和WDBC)均要优于GAv1 与GAv2. 由上述实验结果可知,本文提出的EPA_AO 算法其分类性能明显优于现有的集成学习算法.
接下来,我们将比较EPA_AO 与两种基于GA (遗传算法)的集成剪枝算法的性能. 这两种基于GA 的集成剪枝算法是由Altinçay 所提出[12],分别称为: GAv1(GA version 1)和GAv2 (GA version 2). 与本文所提出的EPA_AO 类似,GAv1 和GAv2 也采用多模态扰乱策略来训练个体分类器.
表3 给出了EPA_AO、GAv1 与GAv2 这3 个算法的分类准确率(因为GAv1 与GAv2 能够自动选取最优的k值以得到最高的准确率[12],所以这里我们只给出了EPA_AO 的最优结果,即k= 7 时的准确率. 此外,我们还统计了EPA_AO 在不同k值下的平均准确率).
根据表3,我们可以得出这样的结论: EPA_AO 的分类准确率在大部分数据集上都比GAv1 与GAv2 这两个算法更高. 具体而言,如果将k设置为 7,则EPA_AO 的准确率在总共8 个数据集上均要优于GAv1 与GAv2,只是在Vowel 上表现差一些. 尤其是在以下4 个数据集上: Credit-g、Liver、Pima 与Vehicle,EPA_AO 的分类准确率相对于GAv1 与GAv2 这两个算法有明显的提升(提升了10%以上). 此外,如果我们统计EPA_AO 在多个k值下的平均准确率,则可以发现EPA_AO 的性能在总共 7 个数据集上(除了Vowel 和WDBC)均要优于GAv1 与GAv2. 由上述实验结果可知,本文提出的EPA_AO 算法其分类性能明显优于现有的集成学习算法.
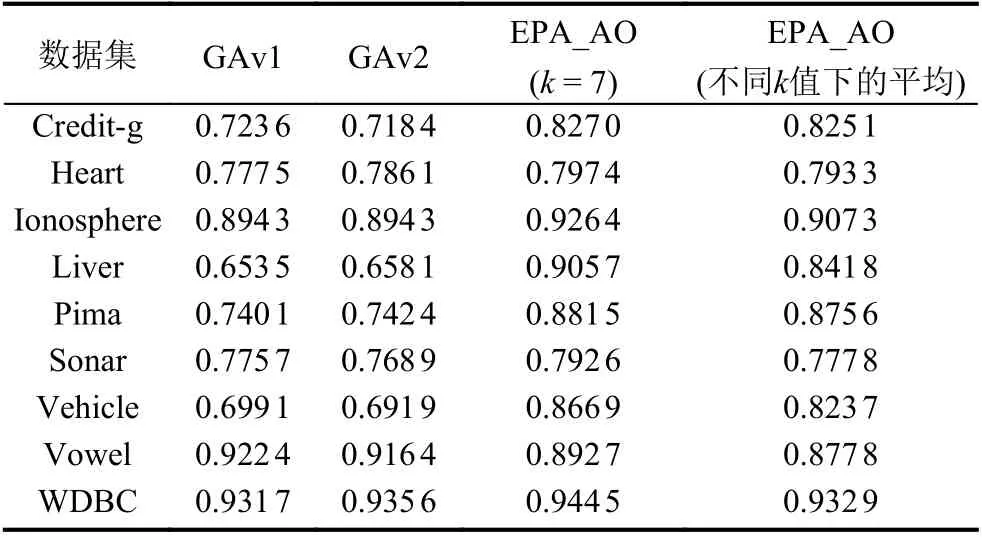
表3 EPA_AO、GAv1 与GAv2 的准确率
4 总结
为了增加集成学习中个体分类器的多样性,本文提出了近似约简的概念,并由此设计出一种新的多模态扰乱策略. 该策略通过近似约简来扰乱属性空间,并通过最优采样技术来扰乱训练集. 近似约简是对粗糙集中经典的约简概念的扩展,它能够解决给定决策表中约简数量可能不足的问题. 在上述多模态扰乱策略的基础上,本文提出了集成剪枝算法EPA_AO. 实验结果表明,EPA_AO 算法的性能要优于现有的集成算法.
由于本文在Pawlak 的经典粗糙集模型[17]基础上提出了近似约简的概念,而经典粗糙集模型更适合于处理离散型属性,所以,EPA_AO 需要通过某种离散化技术将所有的连续型属性转换为离散型属性. 然而,属性离散化可能会导致信息的丢失问题. 因此,在下一步工作中,我们计划将EPA_AO 扩展到邻域粗糙集[22]或者模糊粗糙集[23]等扩展的粗糙集模型中,从而可以不经过离散化过程而直接处理连续型属性.
