基于改进VGG16网络模型的花卉分类①
2022-08-04侯向宁刘华春侯宛贞
侯向宁,刘华春,侯宛贞
1(成都理工大学工程技术学院,乐山 614000)
2(西华大学 计算机与软件工程学院,成都 610039)
步入全面小康社会,人们在享受物质生活的同时,也在不断追求高品质的精神生活,比如对美的欣赏及追求.花卉观赏可使人心情愉悦,给人恬美的视觉体验; 然而人们对花卉的分类却较为迷惑,究其原因主要有两点: 首先是花卉具有较高的类间相似性,即不同种类的花卉之间存在着难以分辨的相似的颜色及形状等; 其次是花卉具有较大的类内差异性,即同类花卉之间受气候和光照等因素的影响,存在着颜色、形状等方面的不同之处.
我国幅员辽阔,已知的花卉种类约3 万种. 在植物研究领域,基于人工提取特征的传统花卉分类方式分类准确率低且耗费人力; 而具有自动提取特征的基于深度学习的花卉分类方法逐渐受到人们的关注. 文献[1]设计了一个8 层的卷积神经网络,并在Oxford-102花卉数据集上进行了测试,由于模型的深度较浅,分类效果并不理想. 文献[2]通过迁移学习,对Inception-v3网络模型在花卉数据集上进行微调,对分类准确率有少量的提升. 文献[3]将AlexNet 和VGG16 模型的特征进行串联,利用mRMR 算法选择有效特征,最后采用SVM 分类器进行分类,该方法稍显繁琐且分类准确率不高. 文献[4]在VGG16 模型的基础上将多层深度卷积特征进行融合,并在 Oxford-102 花卉数据集进行了测试,但分类的准确率并不理想. 文献[5]对LeNet-5 模型进行了适当改造,取得了较好的分类效果,但其对花卉图像进行了灰度预处理,并未考虑到颜色对识别精度的影响. 文献[6]采用多层特征融合及提取兴趣区域的方法对花卉进行分类,模型较为复杂.
文献[7]将SE 视觉注意力模块引入VGG16 网络模型,用于对行人进行检测,取得了较好的检测效果.本文在VGG16-BN 模型的基础上,引入视觉注意力机制,将SE 视觉注意力模块嵌入VGG16-BN 网络模型,对花卉图片的显著性区域进行特征提取,充分利用VGG16-BN 模型的宽度和深度优势,以进一步提高花卉分类的准确率.
1 相关工作
1.1 SENet 网络
SENet 是最后一届ImageNet 分类任务的冠军.SENet[8]的本质是采用通道注意力机制,通过深度学习的方式自动获取图像各个特征通道的权重,以增强有用特征并抑制无用特征. SENet 的核心模块是squeezeand-excitation (SE),主要分3 个步骤对特征进行重标定,如图1 所示.
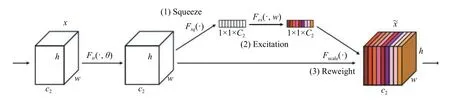
图1 SE 模块
在对特征进行重标定之前先进行一个标准的卷积操作Ftr,如式(1)所示:
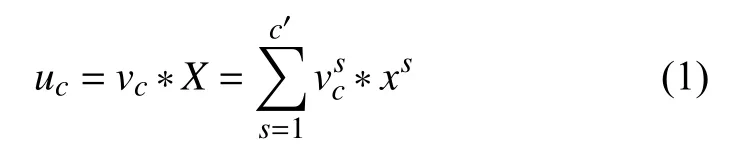
其中,输入特征X∈RH'×W'×C',输出特征U∈RH×W×C,卷积核V={v1,v2,…,vc},其中vc代表第c个卷积核. *代表卷积操作,vcs表示第s个通道的卷积核,xs表示第s个通道的输入特征,uc表示第c个卷积核所对应的输出特征.

(1)Squeeze[9]即Fsq操作,该操作较为简单,主要是对特征图进行一个全局平均池化,从而获取各通道的全局特征,如式(2)所示:Fsq操作将H×W×C的输入转换成1×1×C的输出,也就是将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,它表征着在特征通道上响应的全局分布.
(2)Excitation[10]即Fex操作,通过两个全连接层先降维后升维对squeeze 操作的结果进行非线性变换,来为每个特征通道生成权值,该权值表示特征通道之间的相关性,如式(3)所示:
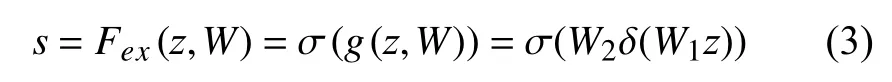
其中,W1z是第一个全连接层操作,W1的维度是C/r×C,z的维度是1×1×C,因此W1z的输出维度是1×1×C/r,即通过r(维度的缩放因子)进行了降维,然后采用ReLU 激活. 第2 个全连接层是将上个全连接层的输出乘以W2,其中W2的维度是C×C/r,因此最终输出的维度为1×1×C,即同squeeze 操作输出的维度相同,最后再经过Sigmoid 函数用于获取各通道归一化后的权重,得到维度为1×1×C的s,s用来表示通过之前两个全连接层的非线性变换学习到的第C个特征图的权值. Excitation 这种先降维后升维的操作一方面降低模型复杂度,使网络具有更好的非线性,另一方面更好的拟合通道间复杂的相关性,提升了模型泛化能力.
(3)Reweight[11]即Fscale操作,将上一步excitation 操作得到的权值s通过乘法逐通道加权到原始的特征上,完成在通道维度上的对原始特征的重标定,如式(4)所示:
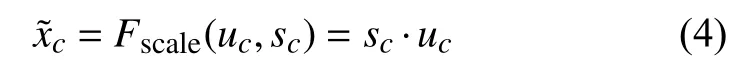
总之,SE 模块通过自动学习,以获取每个特征通道的重要程度,然后根据各个通道的重要程度,一方面去提升有用的特征,另一方面抑制对当前任务不相关或作用不大的特征.
1.2 VGG16 网络
VGGNet[12]荣膺2014 年ImageNet 图像分类第2名的好成绩,其中VGG16 是VGGNet 中分类性能最好的网络之一,其网络结构如图2 所示.
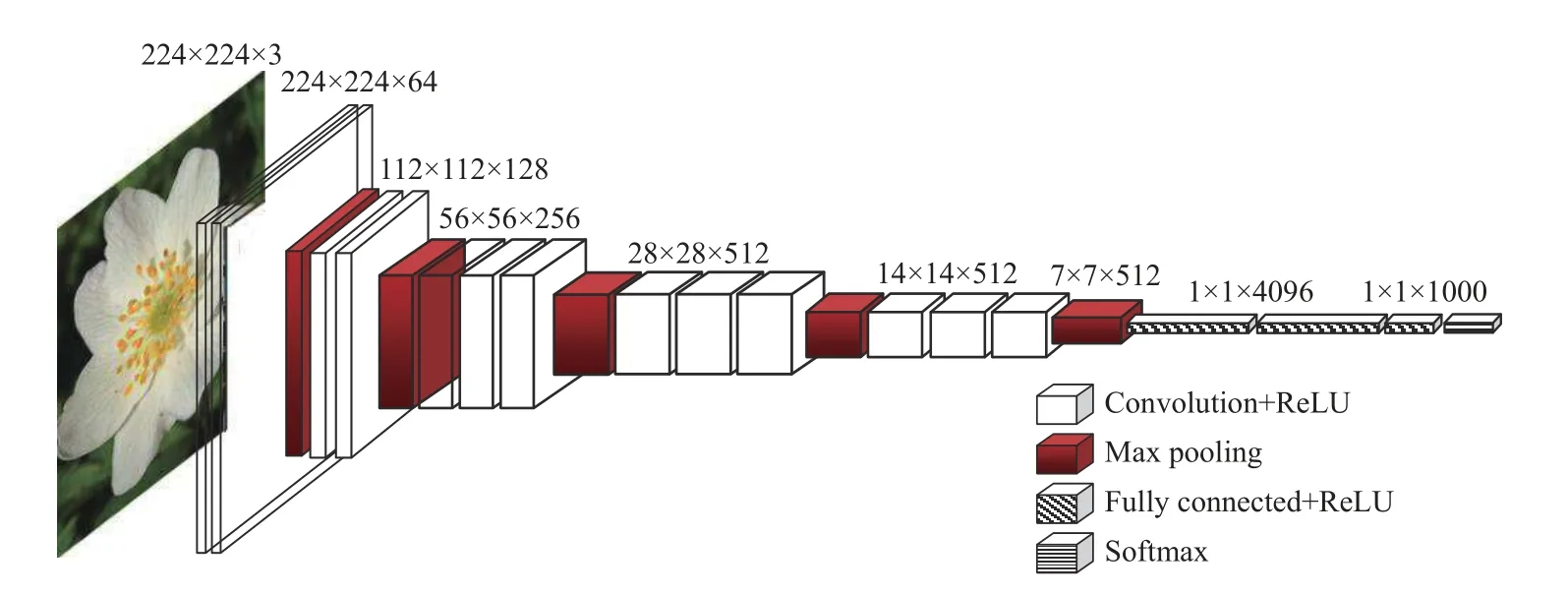
图2 VGG16 网络结构
(1)VGG16 网络可分为6 段,即5 段卷积加1 段全连接,其中5 段卷积包含13 个卷积层,1 段全连接指网络最后的3 个全连接层,因此VGG16 网络总共有13+3=16 层.
(2)5 段卷积用以提取低、中、高各层的图像特征,每一段有2 或3 个卷积层. 为了增加网络的非线性、防止梯度消失、减少过拟合以及提高网络训练的速度,各卷积层后均采用ReLU 激活函数. 为利于捕捉细节变化,获得更好的非线性效果并减少参数数量,每个卷积层均采用3×3 的卷积核,使得网络结构更加简洁,在必要时3×3 卷积核的堆叠还可以替代5×5、7×7 等较大的卷积核.
(3)5 段卷积的尾部均接有一个最大池化层,该池化层采用2×2 的池化核,能够减小卷积层参数误差造成估计值均值的偏移,更容易捕捉图像和梯度的变化,有利于保留纹理等细节信息.
(4)VGG16 网络的最后一段是3 个全连接层,全连接层中的每一个节点都与上一层每个节点连接,把前一层的输出特征综合起来,起到分类器的作用.
总之,VGG16 网络的深度为16 层,这种较深的网络通过逐层的抽象,能够不断学习由低到高各层的特征,具有更强的非线性表达能力,能表达更为丰富的特征,拟合更为复杂的输入特征. 另外,VGG16 网络最开始采用64 个3×3 卷积核,随着网络的加深,卷积核数量逐渐从64,增加到128、256、512,因此使其具有较大的网络宽度,宽度的增加能使网络各层学习到更为丰富的颜色、纹理等特征.
2 改进后的VGG16 网络
2.1 SE-VGGConv 模块
SE 模块的最大特点在于其内部采用常见的池化及全连接层,因此具有很强的通用性,可以方便的嵌入到其他常见的网络模型中. 在VGG 网络模型的卷积层之后加入SE 视觉注意力单元,如图3 所示.

图3 SE-VGGConv 模块
如前所述,在VGG 网络的卷积层后,首先经过一个GAP 全局平均池化层,即图1 中的squeeze 操作,用于获取通道级的全局特征. 然后进入第一个FC 层进行降维操作,用ReLU 函数激活后进入第2 个FC 层进行升维操作,Sigmoid 函数用于获取各通道归一化后的权重. Scale[8,13](即reweight 操作)将归一化后的权重加权到每个原始通道的特征之上,实现了在通道维度上的对原始特征的重标定.
2.2 SE-VGG16-BN 网络模型
VGG16 因其具有较好的深度及宽度,在图像分类的应用具有一定的优势,但对具有类间相似性高,类内差异性大以及存在复杂背景干扰的花卉分类,其准确率还有待提高. 因此,在VGG16 的基础上引入BN 层及SE 视觉注意力单元,可以充分提取花卉分类任务中类间相似性高、类内差异较大的敏感特征,从而提高花卉分类的准确率.
在VGG16 加入BN 层及SE 视觉注意力单元后的网络结构如图4 所示.
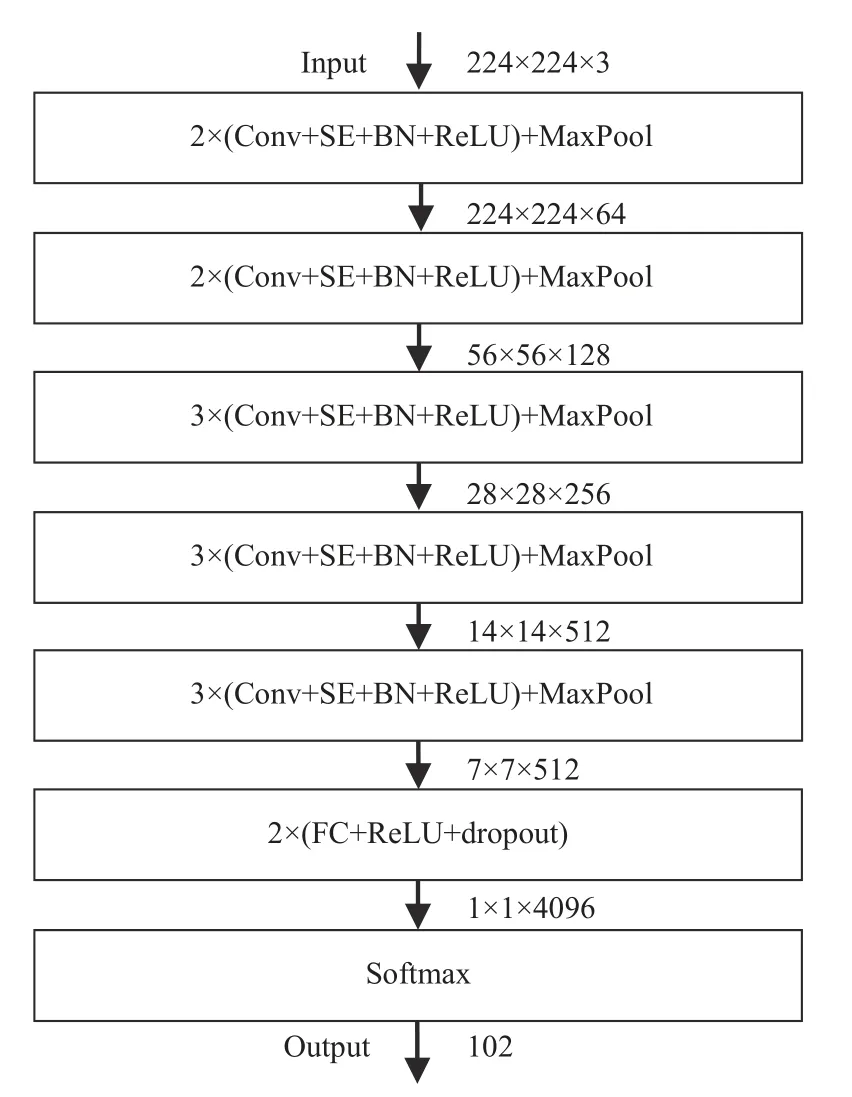
图4 SE-VGG16-BN 网络结构
2.3 多损失函数融合
为扩大花卉的类间距离,减少类内距离,以进一步提高花卉分类的准确率,采用多损失函数融合的方式,具体如下:
交叉熵损失函数(cross-entropy cost function)经常用于分类任务中,起着控制模型的总体走势的作用,交叉熵损失函数的定义如下:
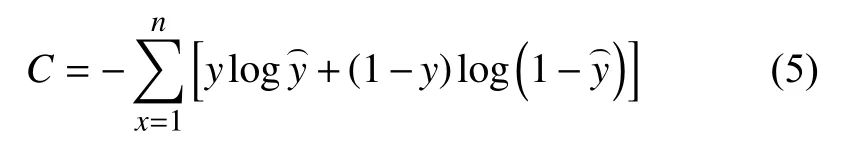
其中,n是批处理样本数,x为输入,y为标签值,ŷ表示实际输出.
中心损失函数(center loss)优势是可以学习类内距离更小的特征,从而减小类内的差异,并能在一定程度上增大类间差异性,从而提高分类的准确率,中心损失函数的定义如下:

其中,n是批处理样本数,xi表示yi类别的第i个特征,Cyi表示i类特征的中心值.

将交叉熵损失函数和中心损失函数进行融合,并将其推广至多层神经网络,假设输出神经元的期望值是y={y1,y2,y3,…},,则融合后的计算公式如下:其中,融合系数λ的取值范围是0–1,通过多损失函数的融合,放大了花卉的类间距离,缩小了类内距离,加快了网络的收敛速度,进一步提高了分类的效率和准确率.
“一日之计在于晨”,早晨是人们精力最充沛的时刻,此时读书,利于记忆,吟咏背诵,往往事半功倍。学校安排学生晨读,从时间分配与人体生理方面而言,是合理的,就晨读内容而言,据本人了解,各校有各校的安排、部署,而我院,则以传统文化为主要朗读、背诵的对象。
3 实验结果与分析
本实验的软硬件环境如下: 操作系统为Ubuntu 16.04.1 LTS,显卡为NVIDIA GeForce GTX 1080Ti,CPU是Intel Core i7-9700K,32 GB 内存. 采用PyTorch 1.6.0深度学习框架,Python 3.6 编程环境以及Pycharm 开发工具.
3.1 数据集
选用牛津大学公开的Oxford-102 花卉数据集,该数据集包括102 类花卉,每类由40–258 张图片组成,共计8189 张花卉图片. 由于Oxford-102 花卉数据集的数据量较小,为了防止过拟合,提高网络模型的性能,对该数据集进行了随机旋转、翻转、平移、裁剪、放缩等操作,通过数据增强,将Oxford-102 数据集扩充至8189+8189×5=49134 张.
3.2 模型训练及参数设置
(1)为提高训练的效果,加快网络模型的收敛,对两个数据集的花卉图片按照保持长宽比的方式归一化,归一化后的尺寸为224×224×3.
(2)将数据增强后的每类花卉图片数的70%划分为训练集,剩余30%作为测试集.
(3)训练时保留VGG16 经ImageNet 预训练产生的用于特征提取的参数,SE 单元模块中用于放缩参数r设置为文献[8]的作者所推荐的16,其余参数均使用正态分布随机值进行初始化.
(4)采用随机梯度下降法来优化模型,batchsize 设置为32,epoch 设为3000,学习率设为0.001,动量因子设为0.9,权重衰减设为0.0005.
(5)为了防止过拟合,SE-VGG16 网络模型第6 段的两个全连接层的dropout 设置为0.5.
(6)多损失函数融合公式中λ参数的值设置为0.5.
3.3 实验对比与分析
(1)数据可视化
VGG16 网络卷积层前36 个通道特征图可视化如图5 所示.

图5 原图及特征图
图5 中网络底层conv1_2 主要提取的是花卉的颜色及边缘特征,网络中间层conv3_3 主要提取的是花卉的简单纹理特征,网络高层conv5_3 主要提取的是花瓣、花蕊等细微的抽象特征.
本文与其他网络的可视化类激活图的效果对比如图6 所示.
从图6 中可以看出,与其他模型相比,本文模型的可视化类激活图所覆盖的范围较大,温度也较高,表明加入SE 视觉注意力单元后,网络能够有效提取花卉的花蕊、花瓣等显著性区域.
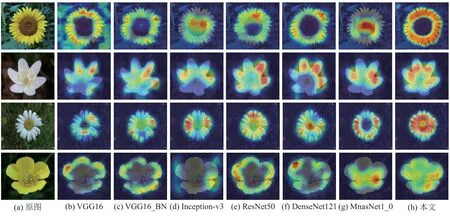
图6 可视化类激活图
(2)分类准确率对比
本文与常见网络模型及引用文献中的网络模型,在Oxford-102 花卉数据集上做了比较,准确率对比结果如表1 所示.

表1 Oxford-102 上不同网络模型分类准确率对比(%)
本文的模型比所引文献中在Oxford-102 花卉数据集上平均高出近6.2 个百分点,本文的模型比未添加SE 视觉注意力单元的VGG16 高出近15.85 个百分点.这一方面缘于本文对数据进行了增强,提高了模型的泛化能力和鲁棒性,另一方面本文模型中嵌入了SE 视觉注意力单元,能够有效学习花瓣、花蕊等部分的细节的信息,从而提高了模型分类的准确率.
(3)损失函数效果对比
多损失函数融合在Oxford-102 花卉数据集上,与常用的交叉熵及中心损失函数对分类准确率影响的对比,实验的结果如表2 所示.

表2 Oxford-102 上各损失函数分类准确率的对比(%)
对比的结果显示,采用多损失函数融合的方法比单独使用交叉熵及中心损失函数在Oxford-102 花卉数据集上的分类准确率分别高出0.85 及1.11 个百分点.结果表明通过多损失函数的融合,放大了花卉的类间距离,缩小了类内距离,进一步提高了分类的准确率.
(4)融合系数效果对比
多损失函数融合公式中融合系数λ取值对花卉分类准确率影响的对比,实验的结果如表3 所示.

表3 Oxford-102 上融合系数λ 对分类准确率的影响
实验结果显示随着融合系数λ的增长,在Oxford-102花卉数据集上,分类的准确率逐渐提高,当λ=0.5 时,准确率达到最高,之后又逐渐下降. 实验表明交叉熵损失函数在总体上控制着模型的走势,中心损失函数能够捕捉并学习类内距离更小的特征,两者的适度融合,可以有效提高花卉分类的准确率.
(5)BN 层效果对比
当λ=0.5 时,未加入BN 层及加入BN 层后的分类准确率效果对比分别如图7、图8 所示.
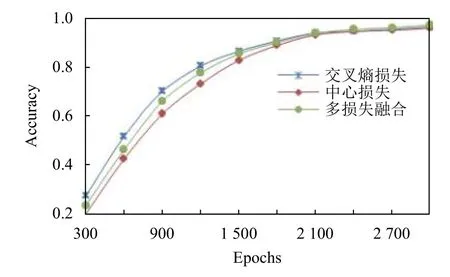
图7 未加入BN 层的分类准确率效果

图8 加入BN 层后的分类准确率效果
实验结果显示,未加入BN 层的曲线收敛较慢,在2400 个epoch 时才逐渐趋于稳定,而加入BN 层的模型曲线收敛的较快,在1200 个epoch 时已经基本趋于稳定. 实验表明,在模型中加入BN 层后,能够利用小批量上的均值和标准差,使网络中间层参数服从于相同的分布,加快了网络的训练和收敛的速度,防止梯度爆炸及梯度消失,使模型变得更加稳定.
4 结论与展望
本文在VGG16 网络模型的基础上,引入视觉注意力机制. 通过将SE 视觉注意力模块嵌入到VGG16 网络模型的各卷积层之后,以提取花卉显著性区域的图像特征; 各卷积层之后分别加入BN 层,有效防止了梯度爆炸及梯度消失,加快了网络的训练和收敛的速度;采用多损失函数融合的方式对新模型进行训练,放大了花卉的类间距离,缩小了类内距离,进一步提高了花卉分类的准确率. 实验结果表明,新模型在Oxford 102数据集上的准确率比未引入注意力前有较大的提升.
