融合多角度特征的文本匹配模型①
2022-08-04马中昊黄浩钰张远明
李 广,刘 新,马中昊,黄浩钰,张远明
(湘潭大学 计算机学院·网络空间安全学院,湘潭 411105)
在自然语言处理(NLP)中,文本匹配[1]是研究对给定的两个文本,采用匹配模型预测两个文本在某种意义上是否相似. 自动评分系统[2]、推荐系统[3]、问答系统[4]、信息检索[5]等都可以抽象成一个文本匹配问题. 在主观题评分过程中,系统可以判断用户的答案与标准答案相似性来进行评分,极大的减少了教师的工作量. 对于推荐系统,可以根据用户浏览的信息来推荐同领域或者同事件的相关信息. 问答系统中的答案匹配可以减少对人工客服的需求. 在信息检索中,查询文档匹配结果的准确性和相关性都很重要. 所以对文本相似度匹配任务的研究是必要且是具有重要意义的.
传统的文本匹配基于TF-IDF[6]、BM25[7]、VSM[8]等的算法,主要解决了词汇层面的匹配问题,但还是存在如“同义词”“一词多义”“双关”等的局限性. 虽然浅层语义分析LSA[9]、LDA[10]等技术可以弥补传统方法的不足,但是还是不能完全替代关键词匹配技术. 随着深度学习不断地发展,对深度文本匹配模型的研究也层出不穷. 大致可以分为两类: 表示型和交互型. 表示型模型注重对文本的唯一表示,经典的模型有DSSM[11]、CDSSM[12]、MV-LSTM[13]等,但是此类模型容易失去语义焦点,难以把握词的上下文的重要性. 交互型模型将词匹配信号作为后续的建模,经典的模型有ARCII[14]、Match-SRNN[15]、DRMM[16]等,但此类模型忽略了句型、句间关系等全局性信息.
针对以上问题,本文提出了一种融合多角度特征的文本匹配模型. 以孪生网络为基本架构,对输入文本使用BERT 模型进行词向量化表示,BERT 转化的词向量本身具有一定的语义信息,使用BERT 词向量计算出两个文本之间词向量的相似度再融合到两个文本中,加强输入文本的语义. 对文本进行词性的标注后,使用Bi-LSTM 对两个文本对应的词性序列进行编码,使用Transformer 编码器对两个文本信息和文本的词性进行特征提取,并使两个文本之间对应的信息进行多层次的信息交互. 对输出后的语义表示进行池化之后,将两个文本对应信息进行对齐拼接送入多层感知机(MLP)中进行两个文本之间的语义匹配. 在Quora部分数据集上的实验表明,本模型相比于经典深度匹配模型有更好的表现.
1 NLP 技术的主流框架
孪生网络[17]包含两个或者更多相同子网络的神经网络架构,子网络共享参数和权重,孪生网络在探索两个样本之间的关系任务中起到很大的作用,子网络结构的参数和权重共享,使训练的参数极大的减少,孪生网络结构可以提取文本整体的语义再送入匹配层进行匹配,利于更好的探索两个文本之间的相似性和联系.
双向长短期记忆模型(Bi-LSTM)[18]由长短期记忆神经网络(LSTM)发展而来,Bi-LSTM 是由前向的LSTM 和后向的LSTM 组成. 单向的LSTM 能捕捉较长距离的文本信息之间的依赖关系. 双向的LSTM 能捕捉双向的文本信息的依赖关系,从两个方向对输入序列进行特征提取.
Transformer 由Google 在2017 年发表的论文中提出[19],该模型在很多其他语言理解任务上都超越了以往的模型. 与循环神经网络类模型相比,Transformer 不需要循环的处理,结合位置信息可以并行地处理所有的单词和符号,同时利用自注意机制将上下文的信息结合起来并行处理,并且在处理过程中可以注意到文本中重要的信息,训练速度相比于循环神经网络有很大的提升,训练的效果也超越了以往的模型,逐渐替代了循环神经网络模型.
BERT[20]是一个预训练语言模型,以Transformer为主要框架,捕捉文本中的双向关系,通过mask language model (MLM)和next sentence prediction (NSP)两个任务来预训练模型,进一步增加了词向量模型的泛化能力,对字符级、词级、句子级甚至句间关系特征都可以充分描述,利用BERT 的特征表示代替Word2Vec[21]的特征表示作为任务的词嵌入特征,相较于词袋模型,BERT 的特征表示包含了更多的语义信息.
2 融合多角度特征的文本匹配模型IMAF
基于孪生网络结构的IMAF (text matching model incorporating multi-angle features)模型由输入层、交互层、表示层、预测层组成,在输入层利用BERT 模型训练出来的特征作为匹配任务的词嵌入特征,解决一词多义问题; 利用BERT 的词向量特征计算两个文本的词相似度,并将相似度结果融合到文本特征矩阵中,增强局部特征; 对输入文本进行词性标注后,利用Bi-LSTM 对文本的词性信息进行词性嵌入编码; 在表示层利用Transformer 编码器作为特征提取; 在交互层对两个文本融合词相似度信息和词性信息分别进行的注意力[22,23]交互,让模型对重点信息关注并充分学习; 在预测层,将交互后的结果进行池化之后送入多层感知器最终通过LogSoftmax 分类器得到两个文本的匹配结果. IMAF 结构如图1,N为Transformer 编码器数量.
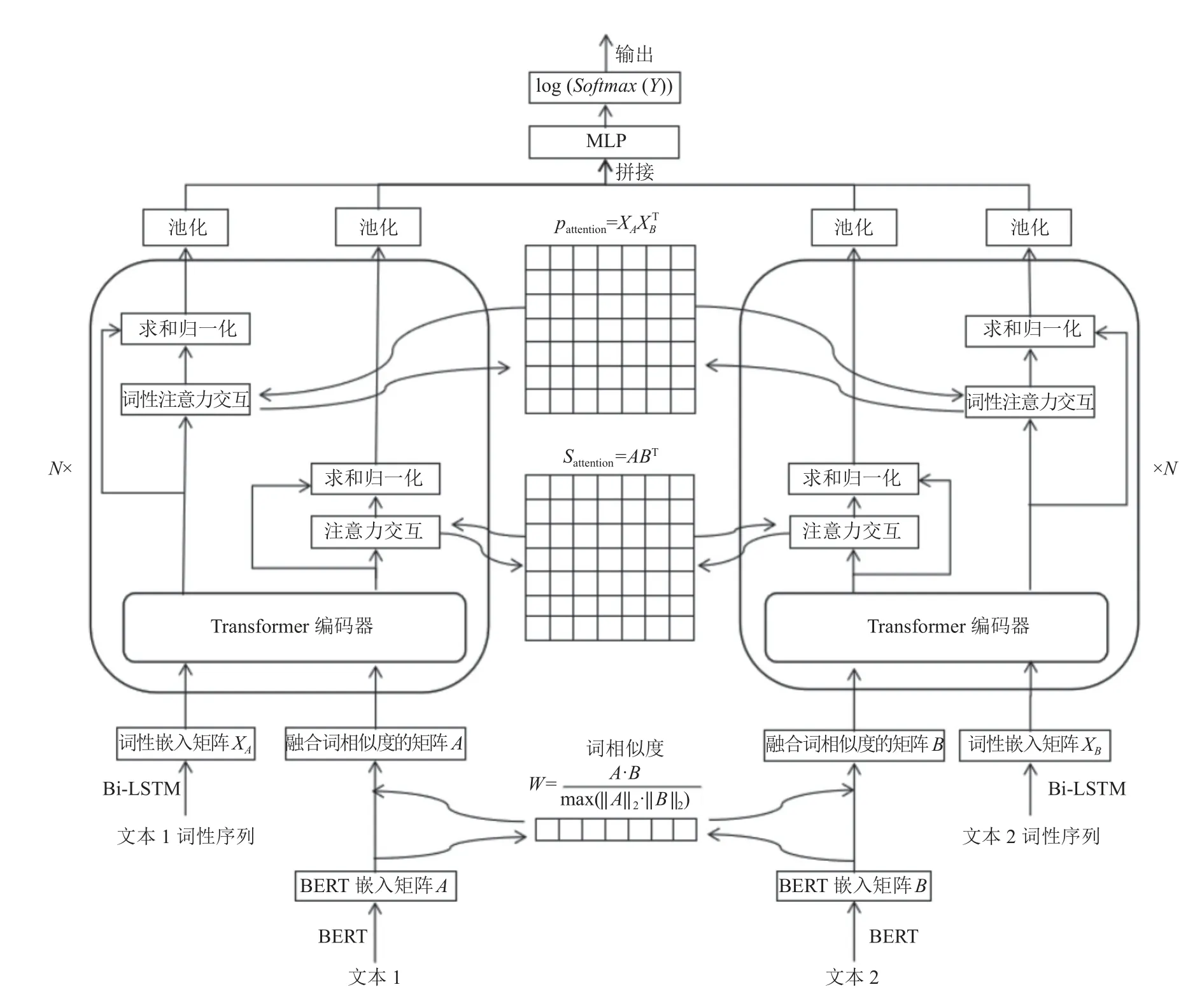
图1 IMAF 结构图
2.1 输入层
本文使用BERT 模型将文本转化为词级别嵌入矩阵. 相比于Word2Vec,BERT 生成的特征矩阵由单词周围的单词动态生成,包含了上下文信息,可以更好地解决一词多义的问题. 该模型拥有12 个Transformer 编码器,隐藏层维度为768 维,每个编码器拥有12 个注意力头.
BERT 生成的嵌入矩阵含有丰富的语义信息,计算两个文本的词相似度作为匹配信号再分别融合到嵌入矩阵中,增强文本的语义表示. BERT 对文本1 的矩阵表示为A,BERT 对文本2 的矩阵表示为B,计算如下,其中,||A||2和||B||2代表矩阵A和B的二范数:
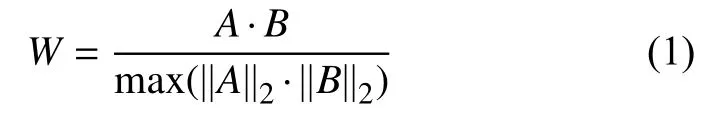
W包含了A与B的词相似度信息,再分别融入矩阵A和矩阵B中得到融合词相似度的矩阵,融合计算过程如下:

对于词性,将文本的词性序列进行向量表示,送入Bi-LSTM 模型学习文本语句结构的特征表示,例如,给定一个长度为n的文本序列[w1,w2,···,wn],将单词在文本中的词性标注映射到向量空间,对于单词wi的词性,都有一个唯一的索引表示,通过将词性向量序列pos[w1,w2,···,wn]输入到Bi-LSTM 从两个方向,即前向和后向,学习语句结构特征表示. 公式如下:
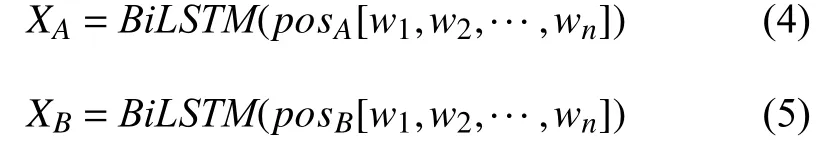
2.2 表示层
表示层通过Transformer 编码器对输入的信息进行特征提取,编码器由N个相同的layer 组成,每个layer分别由多头注意力机制(multi-head self-attention mechanism)和全连接层(fully connected feed-forward network)两个子层组成,每个子层都做了参差连接(residual connection)与归一化(normalisation)操作,Transformer 编码器的内部结构如图2 所示.
后来母亲还告诉过,就是在翠姨还没有订婚之前,有过这样一件事情。我的族中有一个小叔叔,和哥哥一般大的年纪,说话口吃,没有风采,也是和哥哥在一个学校里读书。虽然他也到我们家里来过,但怕翠姨没有见过。那时外祖母就主张给翠姨提婚。那族中的祖母,一听就拒绝了,说是寡妇的孩子,命不好,也怕没有家教,何况父亲死了,母亲又出嫁了,好女不嫁二夫郎,这种人家的女儿,祖母不要。但是我母亲说,辈分合,他家还有钱,翠姨过门是一品当朝的日子,不会受气的。
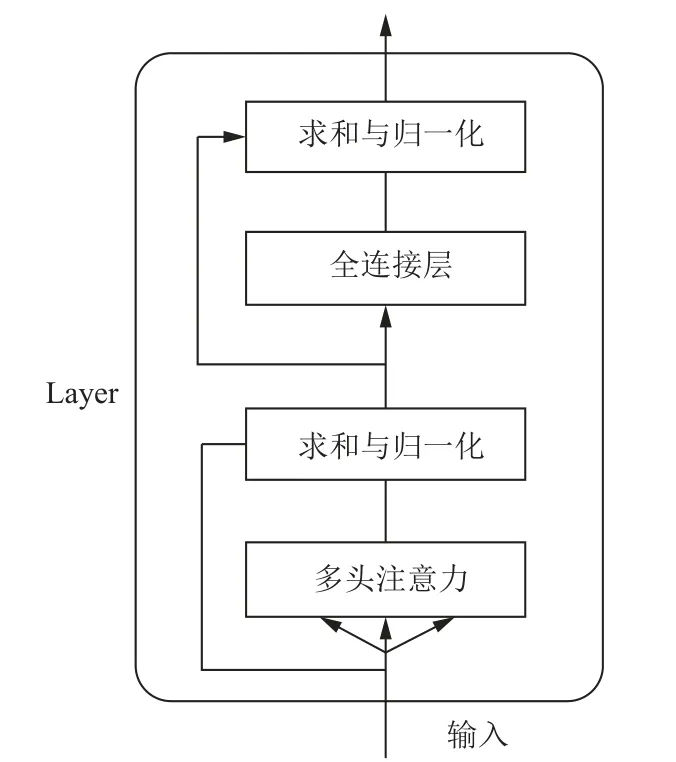
图2 Transformer 编码器
使用Transformer 进行特征提取,增强输入信息的矩阵表示,步骤如下:
(1)文本经过输入层的处理得到输入矩阵维度为S×E,其中,S为最大序列长度,E为嵌入维度. 本文中S为32,E为768. 假设一个文本经过输入层处理的输入矩阵为AS×E. 和对应的语句结构特征表示(XA)S×E. 以矩阵A做计算为例,对于另一文本的矩阵B和(XB)S×E做相同计算.
(2)通过注意力机制计算矩阵Q(query)、K(key)、V(value),其中,WQ、WK、WV为权重矩阵.
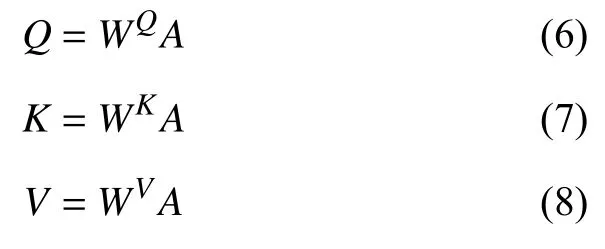
(3)得到矩阵Q、K、V之后进行self-attention 计算. 其中dk为K的维数.
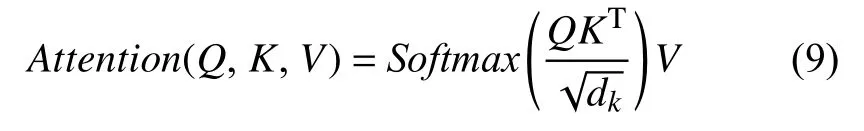
(4)通过多头注意力,即m个不同线性变换对Q、K、V进行投影,最后将所有的attention 结果拼接得到M,传入一个线性层得到的多头注意力的输出Mattention,其中m为注意力的头数.
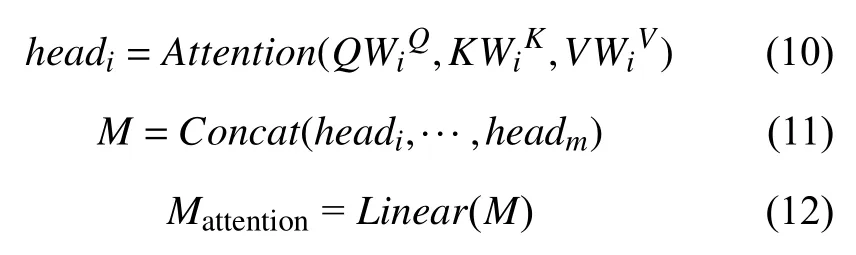
(5)再对得到的结果进行残差连接和归一化之后作为全连接层的输入.
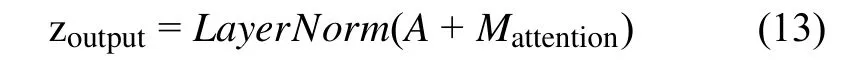
(6)最后送入全连接层之后再进行一次残差连接和层归一化,得到最终结果,输出矩阵的维度与A一致.
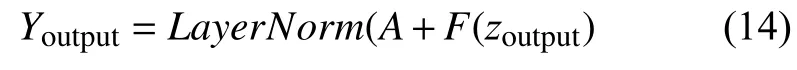
2.3 交互层
经过Transformer 特征提取后的文本1 的矩阵表示为AS×E、对应的词性嵌入矩阵为 (XA)S×E,文本2 的矩阵表示为BS×E,对应的词性嵌入矩为(XB)S×E.
计算两个文本信息的交互注意力矩阵(Sattention)S×S:

对(Sattention)S×S的每一行进行最大池化操作,再融合到A得到交互后的A,此时A包含了B对A中所有的词注意力权重信息,计算如下:

对(Sattention)S×S的每一列进行最大池化操作,再融合到B得到交互后的B,此时B包含了A对B中所有的词注意力权重信息,计算如下:

计算两个文本对应的词性嵌入矩阵交互注意力矩阵(Pattention)S×S:
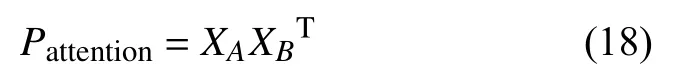
对(Pattention)S×S的每一行进行最大池化操作,再融合到XA得到交互后的XA,此时XA包含了XB对XA中所有的词性注意力权重信息,计算如下:

对(Pattention)S×S的每一行进行最大池化操作,再融合到XB得到交互后的XB,此时XB包含了XA对XB中所有的词性注意力权重信息,计算如下:
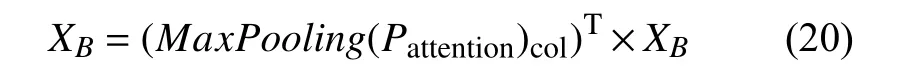
再将结果进行求和与归一化,经过N次的交互后,使得到的结果包含更多的交互信息和上下文信息,其中N为Transformer 编码器的数量.
2.4 预测层
假设经过交互后的两个文本矩阵表示为A32×768和B32×768,预测方法来自文献[24,25],分别经过最大池化后得到对应向量为a和b; 对应的交互后的词性矩阵表示为(XA)32×768和(XB)32×768,分别经过最大池化后得到对应向量为x1和x2; 进行向量拼接后送入多层感知机,得到匹配结果,计算如下:

其中,a×b表示向量a与向量b按位相乘,注重两个文本相同的地方; |a–b|代表向量a与向量b按位相减后的绝对值,注重两个文本相异的地方,H为多层的前馈神经网络,将6 个向量拼接后送入多层的前馈神经网络经过LogSoftmax 分类器得到最终的预测结果,计算如下:
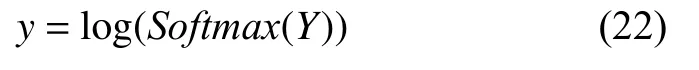
3 实验及分析
3.1 数据集
Quora Question Pair 是美国知识问答网站Quora发布的数据集,包含了40 万对的问句对,旨在判断两句话是否同义. 为了验证模型在少数据量和短文本上情况下的有效性,从中抽取了2 万对短文本句子,相同含义的句子标记为1,不同为0,并将其切分为训练集(15 996 对)、验证集(2 002 对)和测试集(2 002 对).
3.2 评估准则
实验采用的评估准则是F1 值和准确率Acc,F1 值由精确度和召回率得到,TP(true positive)为真正例,FP(false positive)为假正例,FN(false negative)为假负例,TN(true negative)为真负例,计算如下:

3.3 模型参数设置
模型的复杂程度通常与Transformer 编码器的层数设置有着莫大的关系,往往层数越多,训练时间越长.因此找到一个层数少,训练速度快且准确率高的模型是迫切的. 本文将Transformer 编码器层数分别设置为1、2、3、4、5、6.F1 值与Transformer 编码器层数的实验结果如图3 所示,Acc值与Transformer 编码器层数的实验结果如图4 所示,最终将编码器层数设置为3.
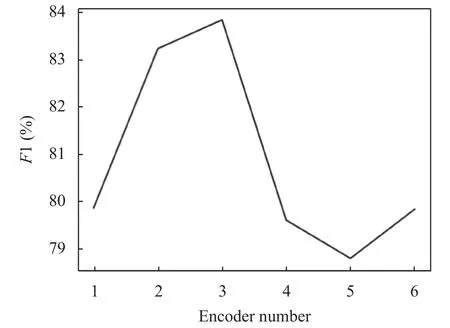
图3 F1 值随编码器层数变化图
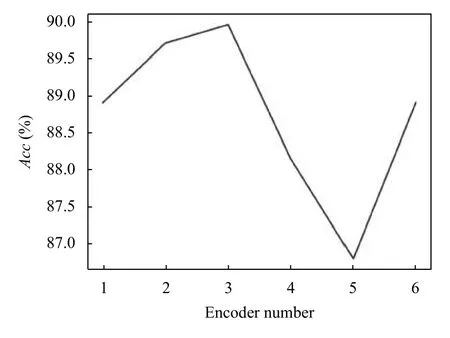
图4 Acc 值随编码器层数变化图
表示层的性能与注意力头数有关. 但数量过多可能导致模型过拟合. 本文将注意力头的个数设置为4、6、8、12.F1 值与编码器注意力头数的实验结果如图5所示,Acc值与编码器注意力头数的实验结果如图6 所示,最终将编码器注意力头数设置为8.
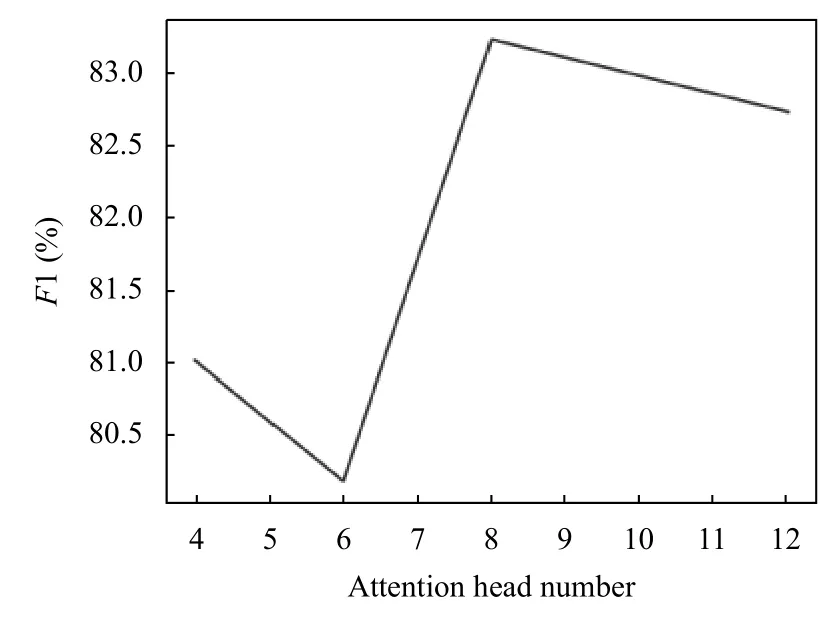
图5 F1 值随注意力头数变化图
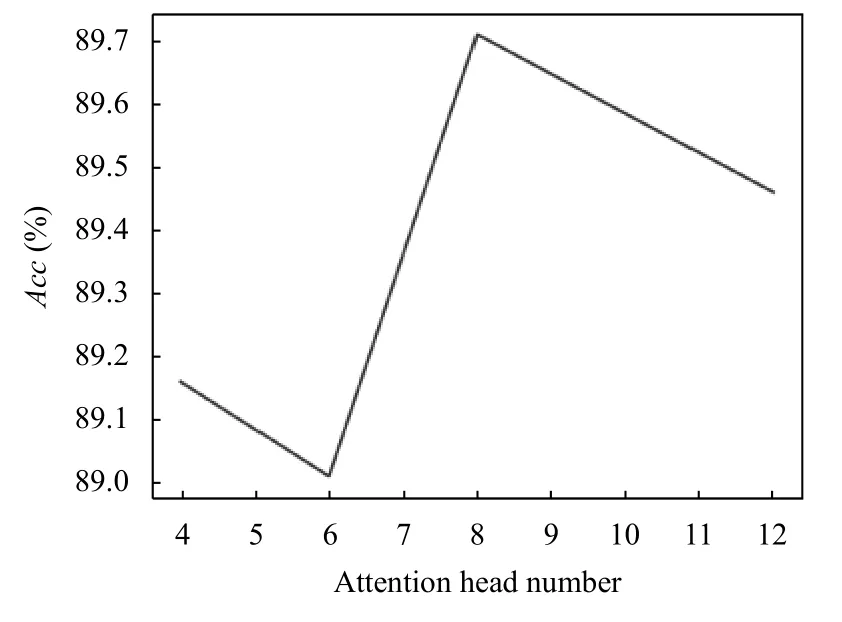
图6 Acc 值随注意力头数变化图
训练模型时需要关注模型的收敛情况,如果模型收敛了就应当停止训练,否则模型将会过拟合,达不到期望的效果. IMAF 模型收敛情况如图7 所示. 训练次数在20 左右模型就已经开始收敛,因此将训练次数设置为25.
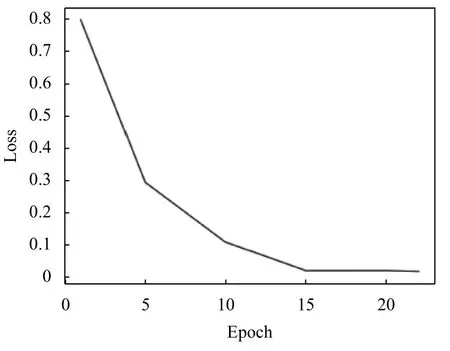
图7 IMAF 模型收敛情况
3.4 实验对比
IMAF 模型实验部分主要参数如表1 所示.

表1 模型参数设置表
为了验证IMAF 模型的效果,本文选取多个经典的文本匹配模型进行对比实验.
针对DSSM 和CDSSM 无法捕捉较远距离的上下文距离的缺点,文献[26]提出了LSTM-DSSM 来解决该问题.
针对现有模型计算能力弱和特征提取能力弱的缺点,文献[27]提出了Transformer-DSSM 模型.
实验引入仅使用词相似度IMAFword-similary模型,以及利用LSTM 的变种代替DSSM 的深度神经网络BiLSTM-DSSM、BiGRU-DSSM 和GRU-DSSM 做对比实验. 模型对比实验表如表2 所示.
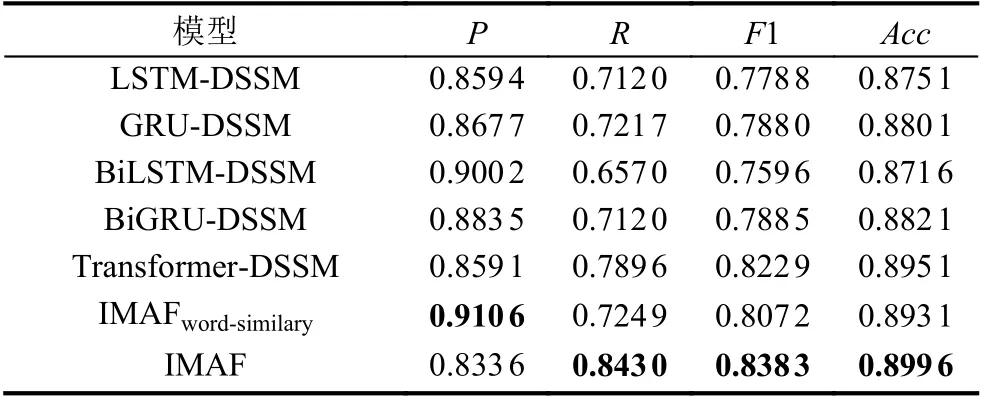
表2 模型对比实验结果表
从实验结果可以看出,本文提出的IMAF 模型的F1 值达到了83.83%,准确率和召回率都有着不俗的表现,从前5 组实验验证了Transfomer 编码器提取特征的能力,由第5、6 组实验验证了引入词相似度的有效性; 由第6、7 组实验可知,IMAF 模型的文本句型结构信息的引入确实提升了文本匹配的效果,由第1、5、7 组实验可知,IMAF 模型在文本匹配方面有着不错的效果,主要体现在召回率、F1、准确率的提升. 其原因在于: 利用词相似度融合加强文本信息,使之后的操作能更好的衡量词上下文重要性,利用Transformer 编码器作为优秀的特征提取器,利用文本信息和句型结构信息的多次交互学习到更丰富的特征表现形式,对文本匹配的效果有着不错的表现.
4 结束语
针对现有文本匹配模型存在一些的问题,提出了一种融合多角度特征的文本匹配模型IMAF,该模型以孪生网络为基础架构,融合了词相似度,对文本的信息和句型结构信息进行多层的交互,使模型学习到更加丰富的特征表示,从对比实验结果来看,本文提出的IMAF 模型在文本匹配上有着不错的效果.
