基于场景动力学和强化学习的自动驾驶边缘测试场景生成方法*
2022-08-04李江坤邓伟文任秉韬王文奇
李江坤,邓伟文,任秉韬,王文奇,丁 娟
(1. 北京航空航天大学交通科学与工程学院,北京 100191;2. 浙江天行健智能科技有限公司,嘉兴 314000)
前言
汽车智能化是汽车行业未来发展的重要方向,因其在缓解交通拥堵、提升道路安全方面的巨大优势已引起政府、行业和科研机构的广泛关注。由于真实世界场景具有无限丰富、难以预测、强不确定性的特征,使基于人工智能的智能驾驶技术在实际场景应用中不断呈现脆弱性,导致Waymo、Tesla、Uber 和蔚来等智能驾驶汽车事故频发。因此如何解决小概率、高风险边缘测试场景的长尾问题成为自动驾驶测试验证的关键技术挑战。
智能驾驶系统由感知模块、决策规划模块和执行功能模块组成。任何功能模块失效都有可能导致车辆发生安全事故。道路测试是目前主要的测试手段。在安全员的监管下,智能驾驶系统在法律规定的开放道路上进行实车测试。真实的道路场景兼顾了以上方面,能够实现软硬件一体化测试,但是也面临着测试不充分的问题,主要体现在两个方面:(1)当车辆面临危险时,安全员会第一时间接管车辆来保证绝对安全,导致无法测试系统在极端工况下的性能表现;(2)小概率边缘场景的稀疏样本问题。
边缘场景是逻辑场景参数空间中介于碰撞危险和安全边界附近区域的场景集合,具有小概率、高风险的特点,能够加速测试自动驾驶系统的能力边界。以真实世界中频繁发生的典型切入场景为例,高危险、紧急突发的交通车切入干扰行为具有小概率发生特征,依托于现有示范区和开放道路的测试效率低。因此基于仿真的边缘场景自动生成技术成为了自动驾驶系统安全验证的关键。
数字孪生仿真测试技术是一种融合实际场地与虚拟场景的高效测试手段,它不仅能解决边缘场景测试不充分的问题,还能提升测试效率实现加速测试。数字孪生的仿真测试打破了时空约束,可在仿真平台中不受时间、场地的限制生成具有挑战性的边缘场景。建模过程中,首先连续场景被离散为有限个条件动作组合,然后基于“条件-动作”结构对场 景 建 模。例 如Zhao 等使 用TTC(time to collision)作为切入场景中前车切入动作的触发条件,当两车之间的TTC 满足阈值时前车按照固定的速度和换道路径开始换道。OpenScenario 标准中对场景的条件和动作设计给出了详细描述。该方法的优势在于将高度抽象的测试环境建模为能够用数学公式描述的参数化场景。其中边缘场景建模问题可转化为相应优化求解问题,通过优化搜索“条件-动作”参数空间来不断缩小测试过程中实际风险与预期风险之间的偏差。常用的优化方法有贝叶斯优化、模拟退火、粒子群优化算法和强化学习。然而,这类场景建模方法存在动态交互不足的问题,换道过程中交通车按照预定的速度行驶无法及时响应被测系统的速度变化,与真实世界的复杂的交互博弈差别较大。
考虑到真实场景中的各种外界输入直接或间接地影响内部状态随时间的变化规律,包括被测车状态、交通流中车辆间的相互作用等,文中从场景动力学角度研究场景中作用于参与物的力和参与物状态关系变化规律的映射关系,力求准确描述交通流中车辆的交互与动态博弈行为。因此,本研究采用动力学方程建立逻辑场景模型,并提出一种面向自动驾驶加速测试的边缘场景强化生成方法。场景动力学系统描述状态随时间的动态变化,能够及时响应被测系统的状态变化,减少无效场景的生成。并引入强化学习理论来解决边缘场景的优化生成问题。最后通过仿真验证所提出方法的有效性。该方法已应用于团队自研的商业仿真软件PanoSim,表明具有一定的工程应用价值。
1 生成方法框架
将场景动力学建模和强化学习方法相结合,提出一种基于场景动力学的边缘场景强化生成方法。如图1 所示,整个方法分为场景动力学建模和边缘场景控制器建模两大部分。

图1 基于场景动力学的边缘场景强化生成框架
场景动力学建模:随时间动态变化的场景被建模为由微分方程表达的场景动力学系统̇=(,,)。由于场景中的被测系统未知,无法基于形式化推导建立准确的场景数学表达模型,因此将场景动力学系统建模为一个黑箱函数。本研究仅关注场景输入对被测系统的影响,即与场景评价目标的差值。常见的场景评价指标有场景危险度、场景复杂度和场景无序度等。
最后基于强化学习算法构建边缘场景控制器,目标是找到一组能够刺激被测系统产生紧急制动行为的边缘场景。强化学习部分着重介绍基于DDPG算法设计边缘场景控制器的应用示例,主要包含DDPG算法、奖励函数设计和网络结构设计3个模块。
2 场景动力学建模
2.1 场景动力学系统描述
真实世界场景是一个随时间变化的复杂动态系统,具有不可预测、不可穷尽的特征。场景中的道路网络和交通规则是静态结构,不会随时间变化,可以通过组合的方式生成。相反,场景交通是一个随时间变化的动态系统,交通参与者的运动组合具有无穷多种,基于离散事件组合生成方法无法穷尽所有的参数组合,且伴随大量无效组合场景生成。因此,本研究受到微观交通流建模方法的启发,从微观建模的角度,在考虑场景静态结构的影响下,基于交通参与者个体的运动建模方法建立场景动力学模型。
场景的状态方程可描述为如下的时变非线性系统:

式中:(·)为系统微分函数,描述系统状态的动态行为变化规律,综合反映了静态场地、交通设施、天气条件和其他交通参与者对交通参与者个体行为变化的影响;为场景静态参数,包含道路结构、气象条件和交通设施等;为系统状态变量,是完整描述系统运动状态的数量最小的一组变量。状态变量可以是交通参与者的位置、速度和加速度等物理量。状态变量的选取较为自由,可以根据建模需求选定。例如,被测系统对交通车的扰动能够驱使系统状态发生转变,因此两车的相对运动状态(相对距离、相对速度)可以作为系统的状态量;为系统输入量,是驱动场景系统动态变化的主要驱动力,例如高速公路直道跟驰场景中,交通车的纵向驱动力是场景动态变化的主要驱动力;为系统输出量。场景评价量化信息是重要的系统输出量,用于指导场景的优化搜索方向。例如,场景复杂度、场景无序度、场景危险度等量化指标。TTC、THW(time headway)和紧急制动强度等是常用的场景危险度的量化指标。
2.2 场景动力学建模过程
图2 为典型的切入场景。场景可以分为3 个阶段“直行-换道-直行”。场景初始时刻交通车位于被测系统后方,首先交通车直行超越被测系统,然后当满足切入条件时执行换道切入动作,最后完成换道继续直行。交通车的换道切入动作侵占了被测系统的行驶空间,极易引发追尾碰撞事故,是典型的边缘场景。本文中以图2为例介绍场景动力学模型的建立过程。
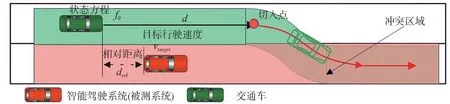
图2 基于固定切入点的场景参数化模型
场景静态参数描述了场景的空间结构、天气条件、交通规则,它不随时间变化,可以作为场景的初始预定义参数。如图2 所示,本文暂未考虑天气条件和交通设施的影响,假设车辆沿着固定路径行驶,因此场景静态参数被简化为一个固定的路径。
基于固定切入点的优势在于换道过程中的曲线轨迹固定不变,可以通过调节第一段直行路径的长度和两车的速度来模拟各种工况下的切入行为,从而将交通车的横纵向运动控制简化为简单的循迹运动控制。
状态变量主要从位置信息和速度信息两大类中选取。具体选取结果为

式中:为交通车到切入点的距离,m;为交通车的车头速度,m/s;为两车的纵向相对距离,交通车相对被测系统位置在前为负,在后为正,m;为被测系统的车头速度,m/s。因此是一个5 维的状态变量。
因为交通车沿固定路径行驶,因此系统的输入量是交通车的纵向驱动力,即

车辆行驶过程中,除道路结构和交通设施的影响,车辆的速度波动多来自于周围交通车的干扰。车辆制动加速度能客观反映场景的危险程度。场景越危险,系统反应时间越短,紧急制动加速度越大。因此本研究选取被测系统紧急制动加速度作为场景边缘属性量化指标,即系统的输出量为

式中为比例系数。
综上所述,典型切入场景的状态方程为
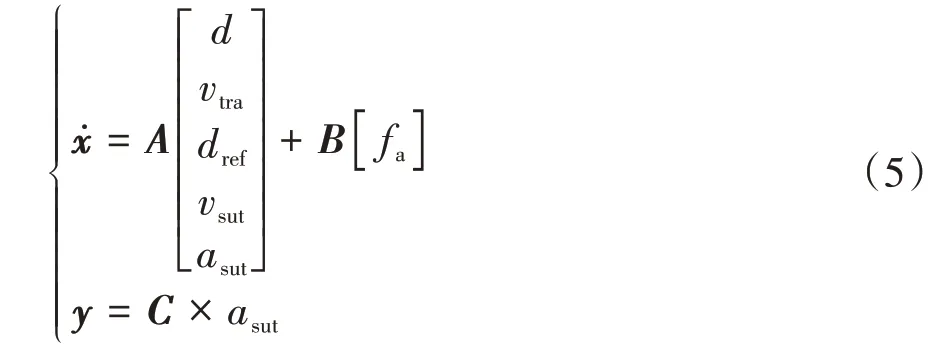
式中:为系统的状态矩阵,反映了系统内部各状态变量之间的耦合关系;为输入矩阵,反映输入量是如何影响各状态变量;为输出矩阵,表明状态变量到输出的转换关系。因被测系统的控制策略未知,是场景中的不可控元素,故难以给出明确的、矩阵。目前在场景生成过程中,研究人员多沿袭先进驾驶员辅助系统(ADAS)逻辑场景的构建方法,通过预定义主车的行为或轨迹来近似建模。然而高级别的智能驾驶系统行为变化复杂,难以建立明确的系统数学模型,且过度简化会丢失系统关键的动态特性,最后当被测主车与预期行为不一致时也会造成测试失效。
基于以上分析,本研究忽略场景元素之间复杂的耦合关系,仅关注场景输入和输出的映射关系,将场景动力学系统描述为一个黑盒函数,即

式中F为场景黑盒函数。
考虑到神经网络强大的黑盒建模能力,本研究基于强化学习方法构建边缘场景控制器,借助神经网络实现输入到输出的映射关系建模。生成的边缘场景模型结构为神经网络,整个训练过程中满足需求的网络权重会被保存到边缘场景库中。
表1 中详细地示出3 种典型工况场景的状态变量选取方法。其中,跟驰场景中状态变量的选取主要考虑两车的速度、相对距离和加速度信息;不规则切入场景中除要考虑速度和距离信息外,还须关注交通车到冲突点的距离和两车通过冲突点的时间差∆;在复杂的多车换道场景中,还须考虑主车的航向角和横向剩余换道距离。表1 中的3种场景简化了交通车运动仅考虑车辆的纵向运动,因此系统输入量为纵向驱动力,与车辆的加速度成正比。在多车换道场景中,两辆交通车协同运行,系统输入量是两车纵向驱动力的2维向量。
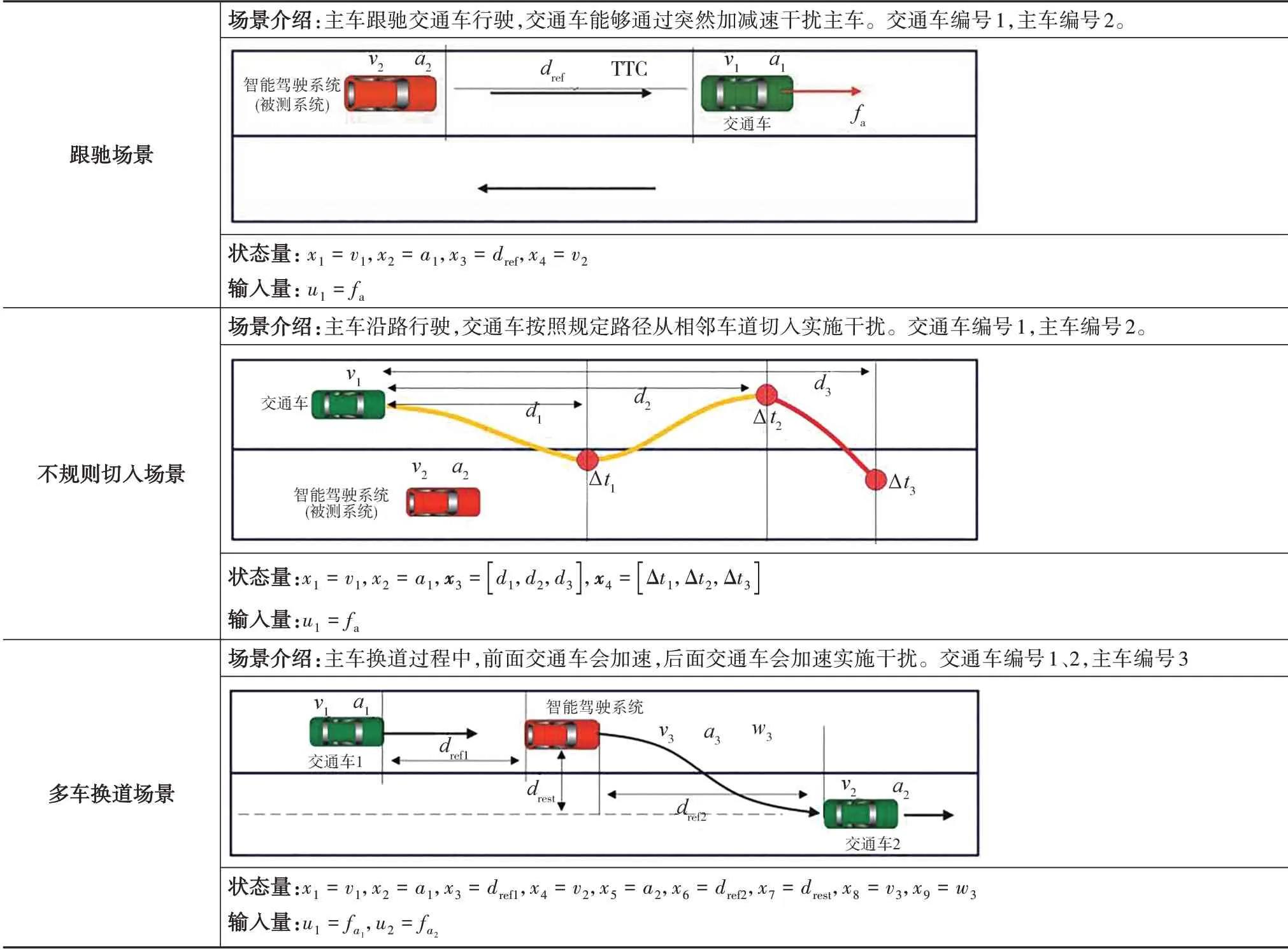
表1 典型工况场景变量选取过程
3 基于DDPG 算法的边缘场景控制器构建
3.1 基于马尔可夫决策过程的问题建立
真实测试场景中,车辆下一个状态决策不仅与当前状态有关,还和历史状态有关。为简化模型,本研究假设交通车与被测系统的动态交互过程满足马尔科夫属性,将边缘场景控制器建模问题构造为马尔可夫决策过程(Markov decision process,MDP),即下一个状态仅与当前的状态和动作有关,表示为

式中:为强化学习模型的观测状态,场景动力学模型的观测量()和输入()都是强化学习模型的状态空间,=[(),()];为强化学习模型的动作空间,输出下一时刻交通车的动作;(,)为描述环境状态转换的概率模型,表示在状态下对智能体采取动作转到下一个状态的概率;(|)为个体策略,在状态时采取动作的概率,场景模型函数=(|);(,)为环境奖励,表示交通车从状态转换到状态后收到的即时奖励。
基于强化学习的策略=(|)求解原理如图3 所示。策略是具有可调参数的函数逼近器,例如深度神经网络。学习算法基于状态、动作和奖励不断更新策略参数。
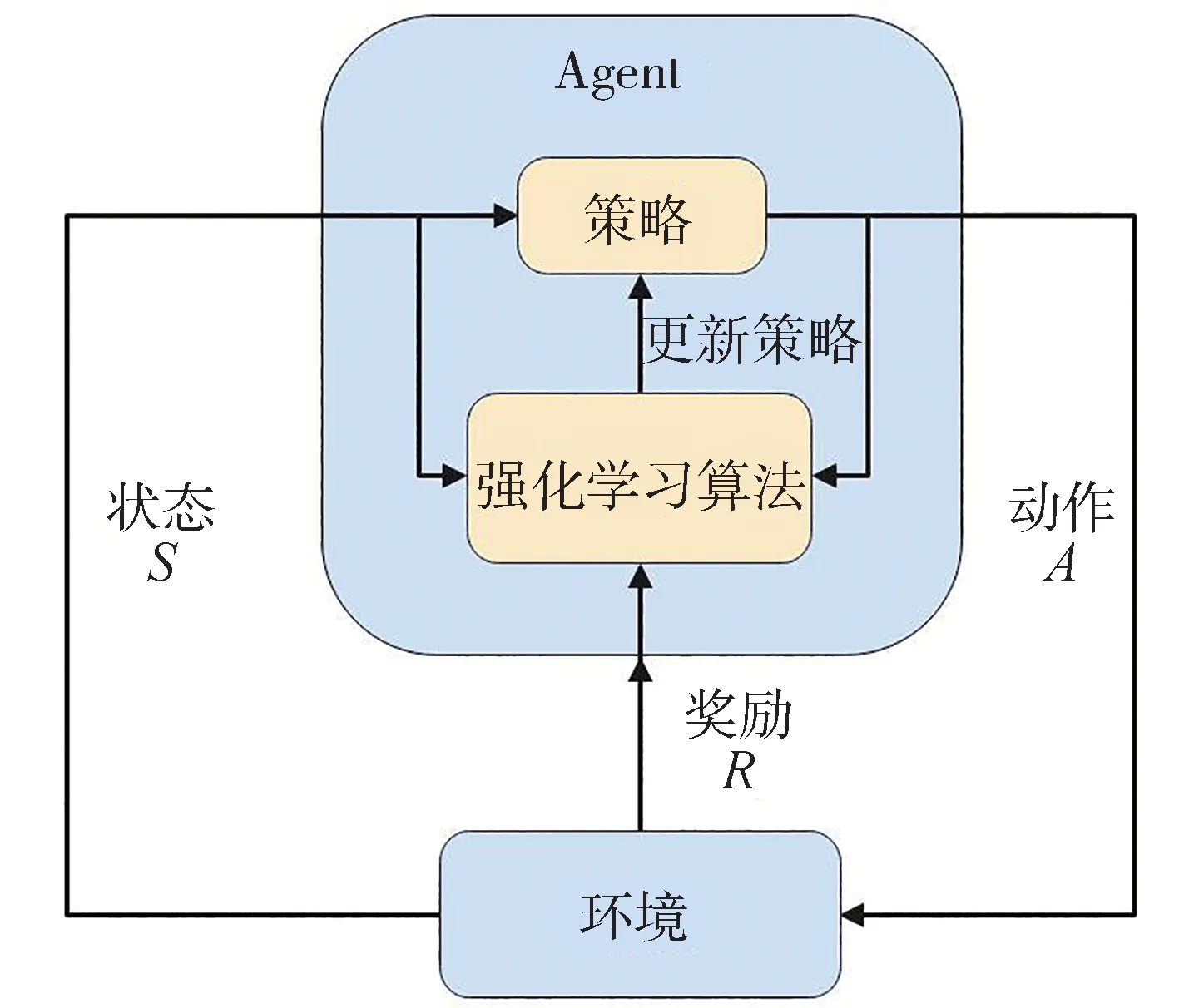
图3 强化学习方法原理
3.2 深度确定性策略梯度算法
本研究受到谷歌DeepMind 团队研究的启发,将深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法应用到交通车的连续动作控制中。DDPG 是一种基于Actor-Critic 网络框架的无模型、离线策略强化学习方法,能够很好处理连续动作空间的输出问题,在自动驾驶控制领域应用广泛。
DDPG 算法主要由基于策略的Actor 网络和基于价值Critic 网络两部分组成,Actor 网络根据环境状态观测信息产生连续动作,Critic 网络是对Actor网络输出动作的评价,主要根据环境状态信息、奖励等参数更新网络。为解决训练-样本强相关性的问题,Actor、Critic网络均采用off-policy方式训练,即有两个网络结构完全一致的在线网络和目标网络。
DDPG算法整体框架如图4所示,智能体从环境中获取当前的状态,然后由在线策略网络计算得到智能体对应动作,接着对环境实施动作得到奖励和新的状态′,并将上述要素组成新的四元组{,,,}存入经验回放池,并构建如式(8)所示的均方差损失函数,通过神经网络梯度反向传播更新在线网络的参数。

图4 深度确定性策略梯度算法框架
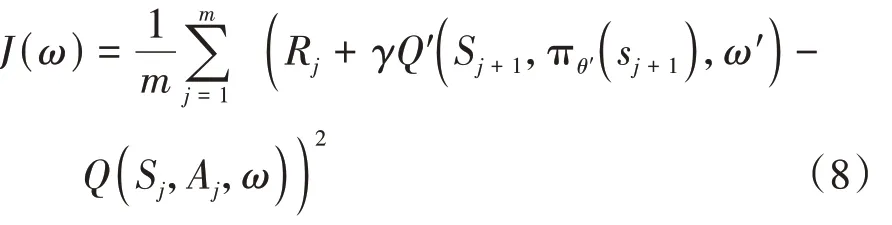
在线网络用于更新在线策略网络参数,其梯度表达式为
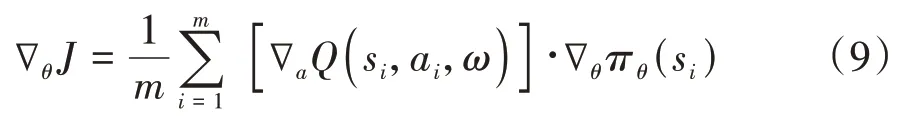
DDPG 目标网络的参数更新采用一种软更新的方法,即每次参数值更新较小幅度,即
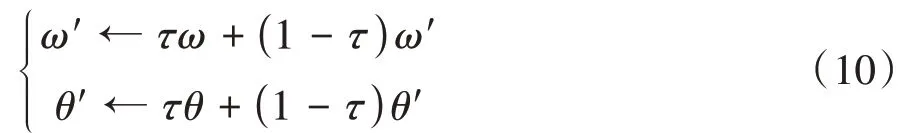
式中为更新系数,取值一般较小,如0.1或0.01。
3.3 网络结构设计
考虑到环境状态的输入变量空间规模较小,研究中首先选用简单、高效的4 层全连接网络,从状态中充分挖掘场景信息背后隐藏的运动规律,在满足任务需求的前提下还能提高训练速度,Actor 网络结构如图5 所示。为提高模型的收敛速度,在全连接层之间采用ReLU 激活函数,最后通过缩放层对输出进行线性缩放和偏置,此处采用tanh 激活函数为加速度提供有界输出。
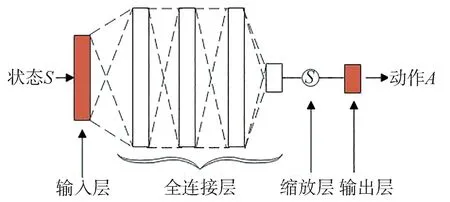
图5 Actor网络结构
Critic 网络结构如图6 所示。环境状态通过2层的全连接层处理后与经过1 层全连接层处理的动作取和,然后在经过2 层的全连接层处理得到值。全连接层之间都采用ReLU激活函数。
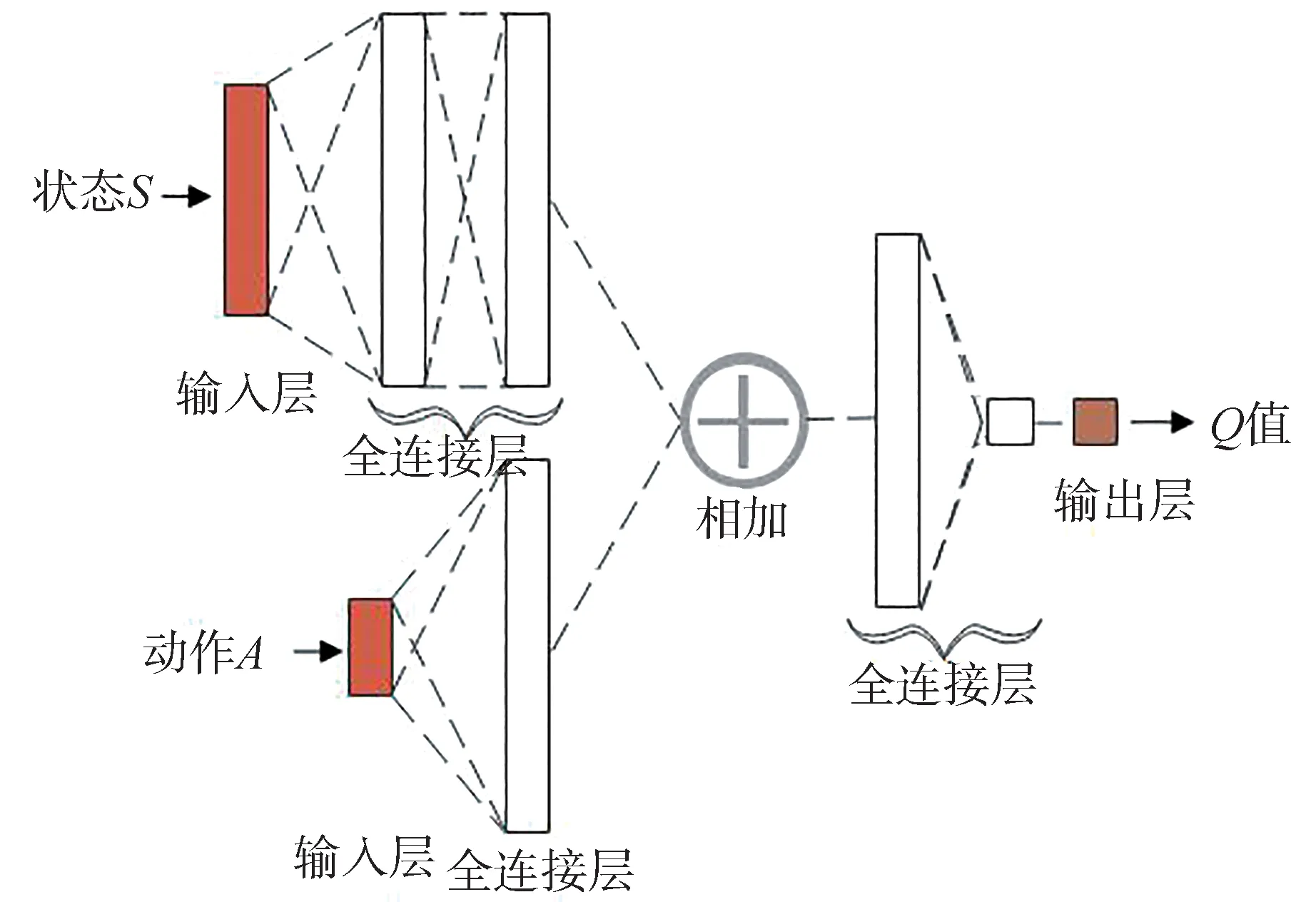
图6 Critic网络结构
3.4 奖励函数设计
奖励函数是强化学习的重要组成元素,其设计直接影响智能体学习、进化的方向,是强化学习算法训练成功的关键。为使生成的边缘场景兼顾危险性和合理性,本文中从对抗奖励和不合理碰撞奖励两方面来设计奖励函数。对抗性奖励是为提高交通车对边缘场景的探索能力,不合理碰撞奖励是为约束交通车动作的合规性,提高生成场景的合理性。
除因道路结构限制导致的车辆减速行为外,智能驾驶系统行驶过程中的大幅制动多源于其他交通参与者的影响。例如行驶过程中前车紧急制动,或邻车近距离切入都会导致车辆采取紧急制动避障行为。制动强度越大说明交通车的影响越大,场景越具有挑战性。因此被测系统紧急制动过程中的制动加速度可以量化智能体的对抗性奖励。对抗性奖励可表示为

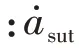
当智能体在一个周期内未触发被测系统紧急制动行为时被认为探索失败,须返回一个负奖励。探索失败奖励的表达见式(12):

式中为常数,通过仿真调参选取具体值。
虽然本文鼓励碰撞事故发生,但是更关心被测系统导致的碰撞事故,因此要减小由交通车不合理行为导致的碰撞事故。例如交通车切入过程中的追尾事故、被测系统正常行驶过程中被追尾或交通车近距离切入导致智能驾驶系统来不及反应去规避碰撞事故。这些都是不合理碰撞场景,应该通过奖励函数引导智能体的探索方向,减少此类场景的产生。不合理碰撞奖励的表示见式(13):

式中为常数,通过仿真调参选取具体值。
最终奖励函数为

式中、、为各项奖励的权重系数,通过仿真调参获取最终值。
4 验证与分析
本研究设计了两个典型场景示例,以验证所提出的方法。
4.1 智能驾驶策略(被测系统)
被测系统基于智能驾驶员模型实现沿路行驶。当相邻交通车的车身在地面上的投影落入自车前面车道便被视为前车。智能驾驶员模型(intelligent driving model,IDM)是典型的跟驰模型。该模型描述了在驾驶员追求期望车速的心理作用下车辆的速度和加速度变化规律,同时前车对车辆的运动变化构成障碍。智能驾驶模型公式为
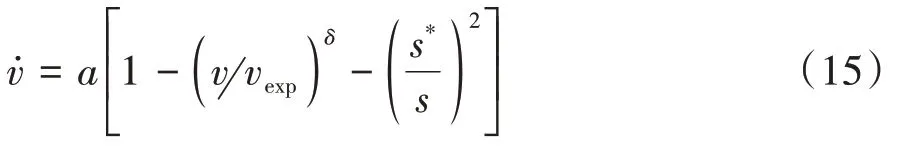

4.2 DDPG模型基本参数设定
DDPG 的网络结构和训练参数如表2 和表3 所示。训练过程中每次训练的周期为30 s,采样步长为0.1 s,最大训练次数为5 000 次。对于每一次训练,当车辆发生碰撞,或训练时间超过30 s,或最大行驶距离超过80 m 时,结束此次训练,并开始新一次的训练。
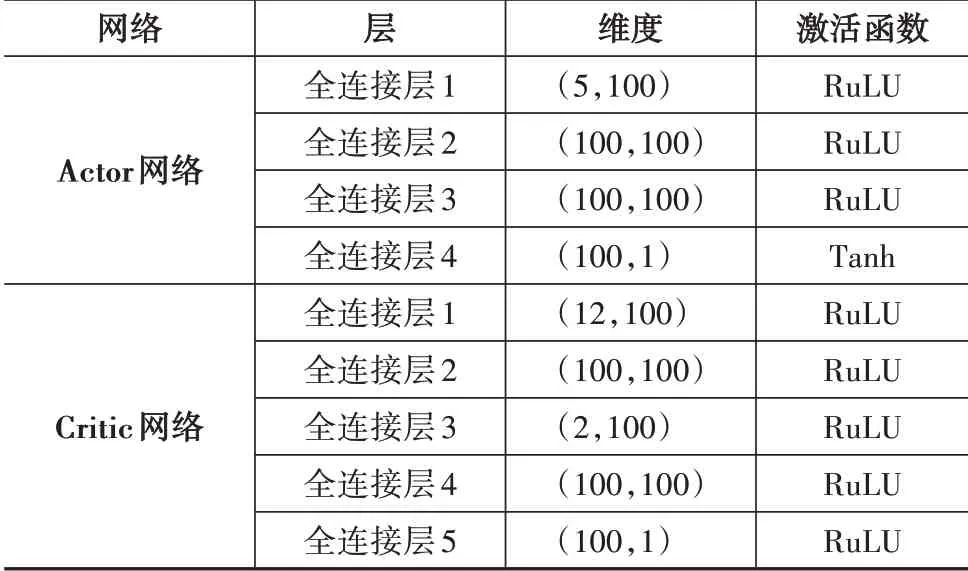
表2 DDPG网络结构
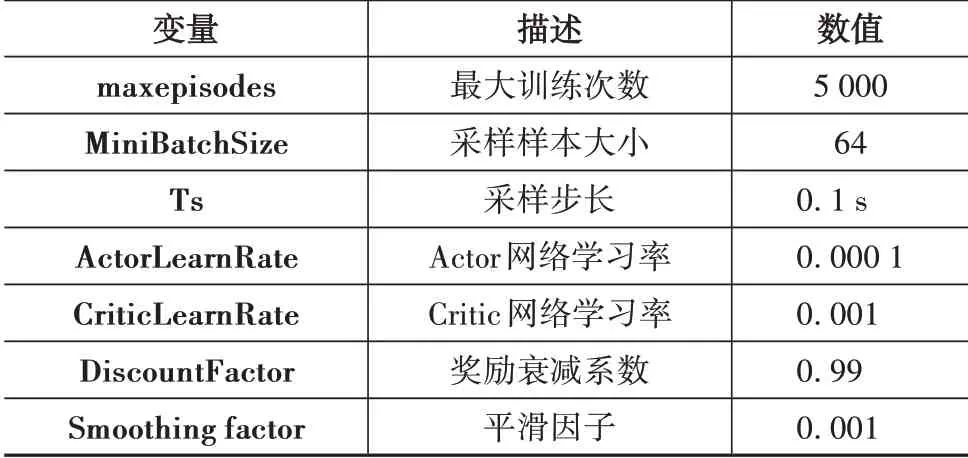
表3 DDPG网络训练参数
强化学习模型的状态空间和动作空间须分别根据场景动力学模型的状态变量和输入变量具体设计。
4.3 典型切入场景示例
4.3.1 实验参数
状态空间=[,,,,],动作空间=,奖励函数式(12)~式(14)中的参数取值为= 1,= 1,= 10,= 20,= 20。
4.3.2 分析与讨论
针对离散奖励,奖励平滑处理以后(平均窗口长度为300),整个训练过程的奖励变化曲线如图7 所示。经过1 500次的训练奖励值逐渐稳定,说明强化学习模型收敛。

图7 每个Episode平均累积奖励变化曲线
训练过程中紧急制动次数的变化如图8 所示,训练次数按照500 间隔被分为10 组。可以看出,当训练在1 500次附近后,智能驾驶系统的紧急制动次数稳定在400左右,即测试成功率为400/500 = 80%,这与基于平均累计奖励变化曲线的分析结论一致。
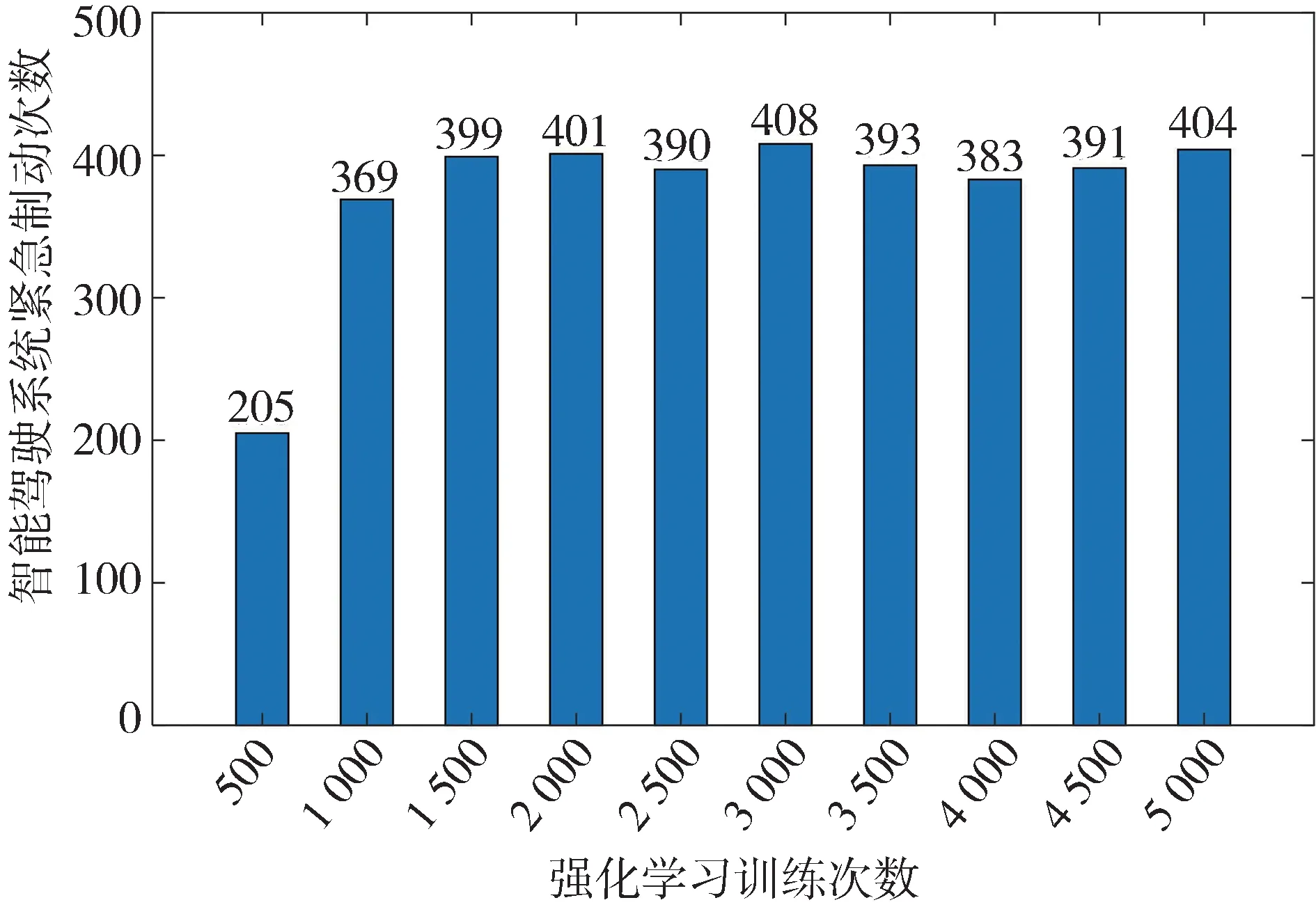
图8 系统紧急制动次数变化
与强化学习在优化求解领域的应用不同,本研究的目标不是找到一个最危险的边缘场景,而是希望找到尽可能多的边缘场景。由强化学习最优求解的特性可知,继续训练得到的都是同质化的场景,无法提升场景的多样性。因此,当强化学习训练收敛时,可以通过增加模型探索能力,来提高生成场景的多样性。未来研究中,将考虑引入动态探索系数来提高场景多样性。
通过一个具体的测试场景来说明该方法在动态交互博弈方面的优势。训练过程中,两车的速度-相对位置变化如图9 所示。首先基于两车的相对距离可将两车的位置关系分为交通车相对位置在后和相对位置在前两种。
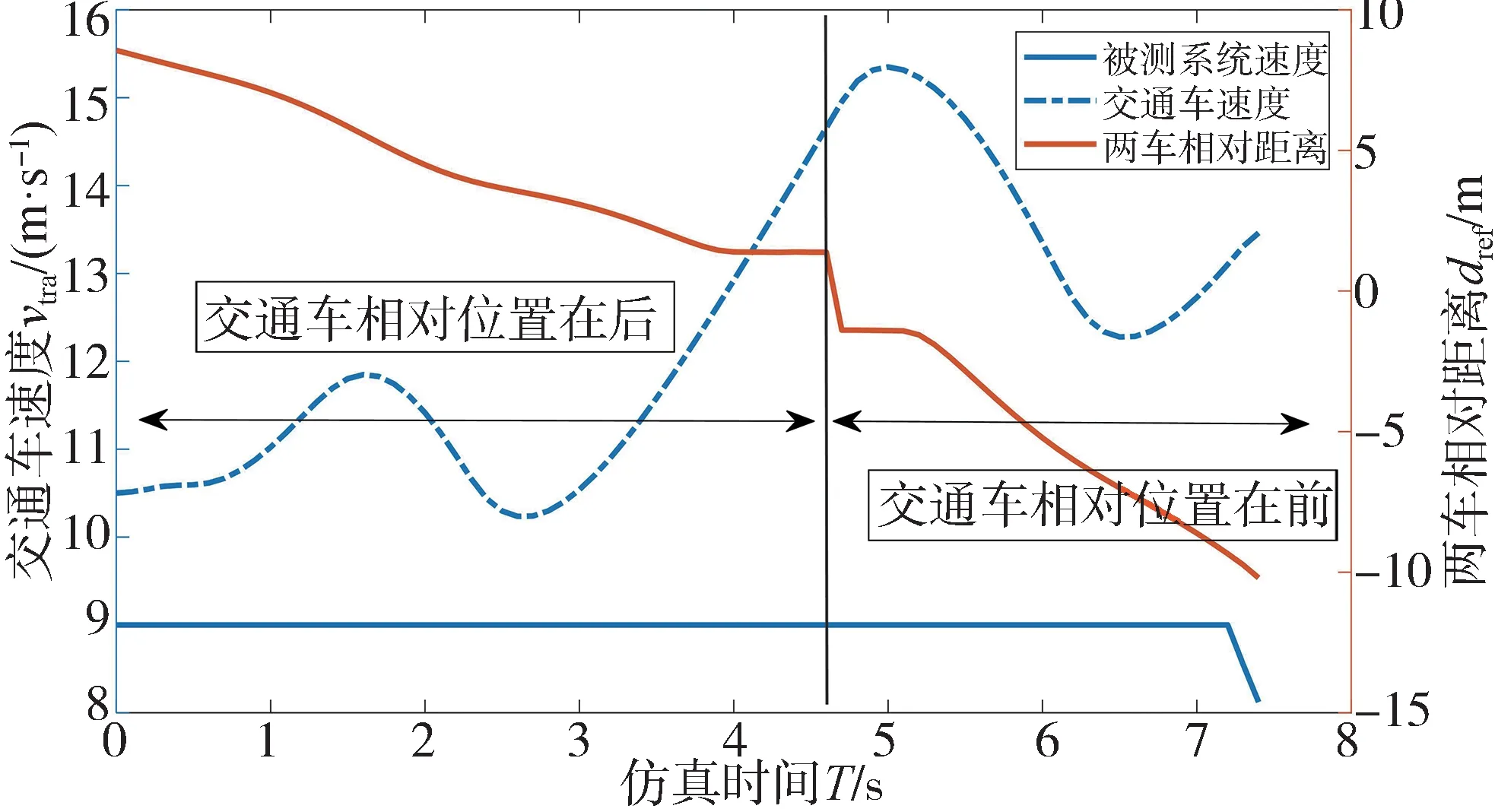
图9 速度-相对距离变化曲线
交通车相对位置在后时,速度呈现出一种波动增加的趋势,这增加了智能驾驶系统对周围交通车速度、未来运动趋势预测的难度。交通车相对位置在前时,交通车运动状态是先减速直行后加速切入,交通车先减速缩小两车的相对距离,然后在加速切入缩短主车车道的时间,从而提高被测系统的紧急制动可能性。由此表明强化生成的交通车能够通过对抗性博弈训练更高效地找到被测系统决策规划的安全漏洞。
经过仿真统计,测试过程中智能驾驶系统的制动加速度分布区间为[ - 5.5,- 3.5]m s,然后按照0.25 m/s的间隔得到8 组加速度,加速度出现频次占比分布如图10所示。由图可见,加速度的分布较均匀,最大占比和最小占比的极差为5.941 个百分点,这说明本文提出的方法能够有效覆盖各种测试工况。
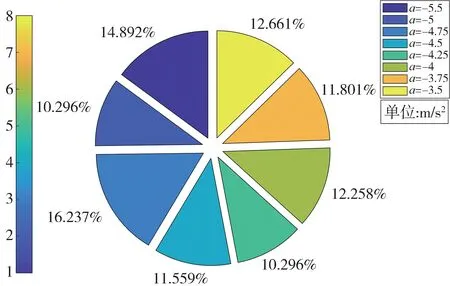
图10 智能驾驶系统紧急制动加速度分布图
4.4 不规则切入场景示例
4.4.1 场景描述
场景中交通车的运动轨迹由多段曲线组合而成,为更加贴近真实驾驶场景,本研究将交通车的切入干扰运动过程抽象为试探切入-安全驶离-最终切入3 个阶段,如图11 所示。相邻车辆换道切入时会存在试探行为,在试探切入过程中交通车如发现存在安全风险,会终止试探行为,并安全驶离目标车道,然后等待合适的时机再继续最终切入。
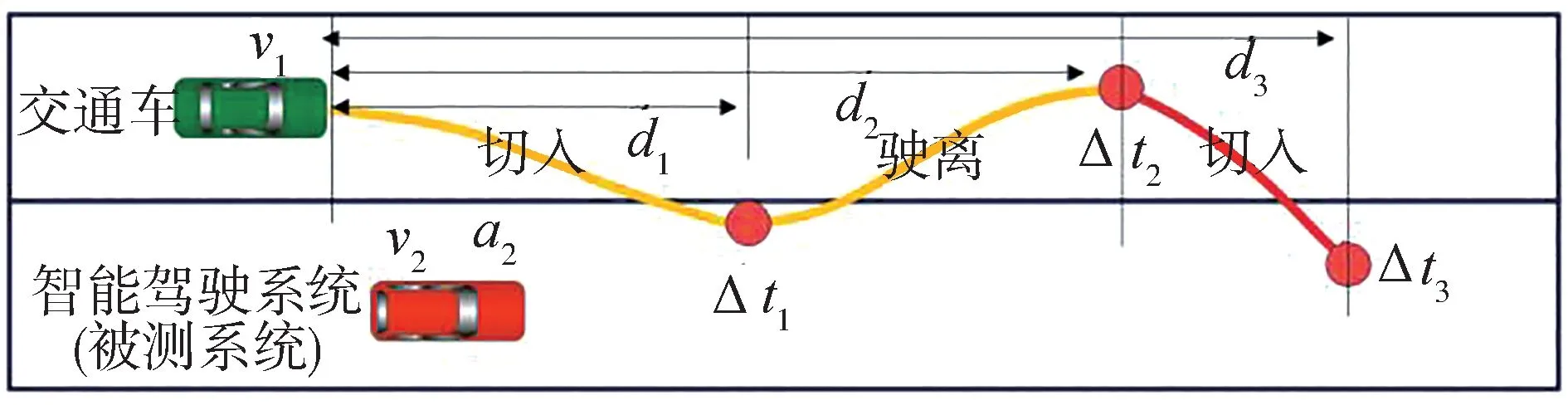
图11 不规则切入场景
4.4.2 实验参数
表1 示出场景的状态变量和输入变量选取方法 。因此强化学习状态空间=[,,[,,],[Δ,Δ,Δ]],动作空间=。奖励函数式(12)~式(14)中的参数取值为= 1,=1,= 10,= 20,= 20。
4.4.3 分析与讨论
交通车与主车的博弈对抗过程如图12 所示。图中蓝色曲线为交通车的运动路径,两车的速度、相对距离、主车的加速度信息以散点的形式呈现。
由图12(a)可见,主车整个运动经历了加速-减速-加速-减速4 个过程。首次切入过程中,由图12(d)可见:两车的相对距离小于5 m,主车减速避让;交通车驶离阶段主车又加速行驶;在主车加速过程中,交通车的切入导致主车产生了紧急制动行为。图12(b)也全面展示了主车的加速度变化。

图12 交通车-主车博弈对抗过程
在交通车驶离时,主车激进加速能保证行驶效率但会带来安全隐患,主车过于保守能确保安全,但行驶效率低。该场景很好地考验了主车的综合决策能力,为效率最优和安全最优之间的权衡决策提供了有效测试手段。不规则切入场景相比于固有匀速切入场景,能增强对车辆间交互能力的测试,贴合实际测试要求,其中交通车的速度过快或过慢都无法保证3 个阶段在整体测试过程起作用。这表明本研究设计的基于DDPG 构建的边缘场景控制器为解决生成效率低和交互测试困难提供了一种有效途径。
4.5 基于PanoSim仿真平台的测试应用
本研究提出的方法已在国产商业仿真软件PanoSim 进行验证。PanoSim 是由作者团队自主开发的一款面向汽车自动驾驶技术与产品研发的一体化仿真与测试平台,它集成了高精度车辆动力学模型、高逼真汽车行驶环境与交通模型、车载环境传感器模型和丰富的测试场景。作为国内自主仿真平台在第四届世界智能驾驶挑战赛(WIDC)中得到应用。
本文中选取PanoSim 软件内置的智能驾驶员模型作为测试对象,将生成的边缘场景模型导入PanoSim软件中驱动交通车运动,仿真结果显示它能有效触发被测对象的紧急避撞策略,实现危险工况的自动化生成和测试。图13 展示了一个完整的测试过程,仿真初始时刻主车(灰色的SUV)和交通车(白色的轿车)分别位于两条车道上,交通车在主车的后方,然后交通车加速超过主车,在超过主车一定距离后实施换道切入动作,从而触发主车的紧急制动策略,完成测试。

图13 基于PanoSim的仿真测试过程
测试过程中,主车的加速度变化曲线如图14所示。在第15 s时,主车开始紧急制动,最大制动减速度达到8.29 m/s,说明该方法能有效生成极具挑战性的边缘场景,有助于发现系统的安全漏洞,提高测试效率。
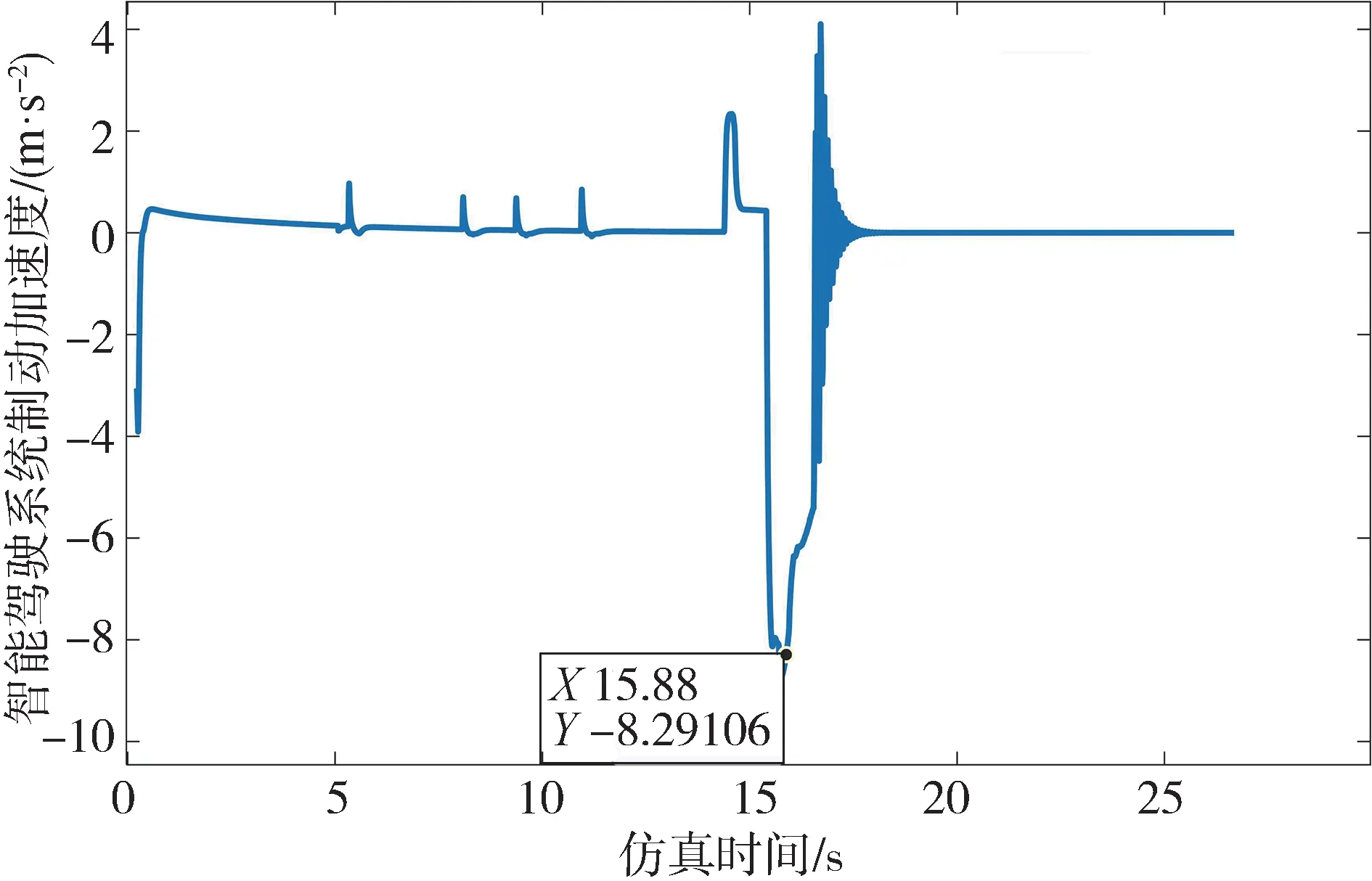
图14 被测系统加速度变化
仿真场景生成方法具有可重复性的优势。训练过程中所有紧急制动场景对应的网络权重都被保存到边缘场景库中。测试阶段仅须调用对应的网络权重即可复现测试场景。例如,当智能系统算法工程师对算法进行迭代升级后,通过调用边缘场景库中的网络权重即可实现测试场景复现,且场景中的交通车具备动态交互能力,通过测试能发现新升级的算法是否具备应对该边缘场景的能力,从而提高测试效率。此外,强化学习只有在训练过程中需要大量计算资源,当训练生成了目标网络策略后,调用训练好的神经网络无需耗费大量的计算资源,能满足车辆极限工况测试的实时性要求。
5 结论与展望
为解决自动驾驶仿真测试中边缘场景小概率、高风险的长尾问题,本文中提出一种基于场景动力学的边缘场景强化生成方法,提升快速测试能力。该方法首先为场景建立了由微分方程表达的动力学系统模型,描述测试环境系统的状态变化;然后将神经网络作为通用函数逼近器,基于强化学习构造边缘场景黑盒控制器。仿真测试结果表明,该方法能有效地提升边缘场景的动态博弈行为模拟、场景覆盖率和可重复测试能力。当前研究还存在边缘特征提取不全、场景建模考虑因素不全面的问题,未来将深入研究复杂场景的动力学建模和属性量化问题。
