融合感受野模块的卷积神经网络视杯视盘联合分割
2022-08-03于舒扬郑秀娟
于舒扬 袁 鑫 郑秀娟
(四川大学电气工程学院自动化系,成都 610065)
引言
视神经是将视觉信息以电脉冲的形式传输到大脑视觉中心的通道,对视神经造成的任何损害或施加在其上的压力均会导致视力的损失。 青光眼是一种导致视神经进行性和特征性损伤的疾病,具有高患病率及高致盲率的特点,是我国乃至全球第一位的不可逆致盲性眼病[1]。 青光眼早期筛查诊断是预防视神经受损的关键。 由于青光眼使视网膜神经纤维层变厚,导致视杯(optic cup,OC)相对于视盘(optic disc,OD)的尺寸增大,因此,有经验的眼科医生在早期筛查和临床诊断阶段主要通过彩色眼底图像视杯与视盘的直径比,即杯盘比(cup to disk ratio,CDR)[2]等指标来进行评估。 一般而言,杯盘比与患青光眼的概率成正比。
在传统的青光眼筛查方法中,专家人工评估眼底图像并手动添加标签图像。 这种人为评判方法耗时费力,并且在很大程度上取决于专家的专业水平,而且从眼底图像中可人为提取的信息量有限。此外,人工评估的眼底图像由于各种人为因素(如医生的疲劳等)的影响,在判断上可能存在显著差异,而且人工分级的准确性也因观察者之间的不同而产生差异。 这些局限性意味着需要开发自动青光眼筛查和诊断方法,以便计算机辅助工具可以在协助临床医生诊断青光眼和其他眼病方面发挥重要作用[3]。
医学图像分割是计算机辅助诊断重要的应用方向[4],准确识别眼底图像中视杯与视盘是计算杯盘比的前提,因此准确分割视杯与视盘是青光眼辅助筛查和诊断的焦点。 视杯视盘分割方法主要分为传统方法和基于深度学习的方法。 传统方法主要基于视盘的颜色[5-6]、边界检测[7-9]、对比度阈值[10-11]和形态学[12-14]等。 但传统方法主要依赖人工提取图像特征,分割效果会受到图像拍摄质量、病变区域以及眼底其他结构等影响。 而且所提取的特征数量也较小,类型固定,影响了模型的泛化性能。
基于深度学习的分割模型克服了人工提取特征的局限性,可以自动学习数据的深层特征,对医学图像具有很强的分辨能力,成为计算机辅助诊断的重要研究方向。 针对医学图像分割任务,早期研究者采用滑动窗式卷积神经网络(convolutional neural network,CNN)进行眼底图像分割[15],用于从输入图像中提取强大的特征。 为了减少模型的训练和测试时间,采用了熵采样的方法来选择信息点。 该方法采用多层学习策略,将一层的结果反馈给下一层。 根据滤波结果训练分类器Softmax,实现视网膜图像的整体分割。 但CNN 主要利用滑动窗口的思想,使用图像块训练深度学习网络,极大增加了参数量和计算时间。 随后,全卷积神经网络[16](fully convolutional neural network,FCN)被提出,大幅提高了训练效率,并运用在眼底图像分割的研究中[17],实现了视杯视盘区域端到端的分割。 Qin等[18]在使用FCN 的基础上还引入了视盘定位和预处理算法,与原始FCN 相比,开发的模型获得了更好的效果,但FCN 没有考虑到全局上下文信息,忽略了像素之间的关系, 缺乏空间一致性。Ronnerberger 等[19]在全卷积神经网络基础之上提出了U-Net,因其结构简明,成为医学图像分割的重要网络框架。 Shuang 等[20]提出对标准U-Net 模型进行改进,采用预训练的标准ResNet34 模型进行编码和标准的U-Net 进行解码,避免了从头训练组合模型,以减少网络训练时间。 Baidaa 等[21]提出将密集连接引入U-Net,使特征得到充分复用,减少了网络参数。 Fu 等[22]提出了M-Net,该模型在U-Net 中加入多尺度输入层和侧输出层,多尺度输入层用于在多个层次上获取各种大小的图像,侧输出层的目的是将其用作产生局部预测的分类器。Badrinarayanan 等[23]所提出的SegNet,是一种基于编码器-解码器体系结构的分段模型。 在SegNet 架构中,编码器/解码器的输出被逐像素输入分类块。SegNet 模型已被研究人员进行改进,用于视网膜眼底图像的分割[24]。 Zhao 等[25]提出PSPnet,采用金字塔池化模块,整合了图像的上下文信息。 Chen等[26]提出Deeplabv3 模型加入空洞卷积池化金字塔,扩大了感受野。
目前基于深度学习的视杯视盘分割方法在效果上一定程度上优于传统方法,但是仍然存在一些问题,如编码器提取特征能力容易受其他病变区域或者照片的亮度等因素影响,导致无法提取出有效的特征; 用于训练神经网络的样本少则容易出现过拟合问题;大部分模型对视杯视盘利用各自的特征分别进行分割,先定位到视盘,把视盘分割出再分割视杯,造成了视盘分割信息的浪费。
针对现存模型的局限与视杯视盘分割的难点,本研究基于SegNet[23]框架引入感受野模块提出了Seg-RFNet 模型,实现端到端的视杯视盘联合分割。首先对眼底图像进行极坐标变换,有效平衡数据集,防止过拟合;采用特征提取能力很强的残差网络作为编码器,并将编码器做分支处理,进一步增强深层抽象语义信息的提取能力;同时在解码器结构中引入感受野模块,增大感受野,进一步增强网络的有效特征的响应。
1 材料与方法
基于SegNet[23]架构提出用于视盘视杯分割的网络框架Seg-RFNet 模型,先对编码器部分的进行深层特征分支,并在分割细节信息恢复前进行各层特征融合后使用大量感受野模块处理。 该体系架构如图1 所示,主要由残差编码层(ResNet layer),大量的感受野模块(receptive field block,RFB)和解码器层(decoder layer)组成。 采用ResNet50 编码器结构,提取有代表性的图像纹理及空间特征;对编码层进行分支处理,浅层网络保留更多图像细节位置信息,而深层网络具有较高水平的语义特征信息,编码器分支可以分化深层特征,在深度不变的情况拓宽获取特征的路径;在编码器和解码器之间增加多个感受野模块,通过多分支卷积层和空洞卷积层,在增大感受野的同时获取不同感受野下的全局信息;解码器根据特征层次的深浅所包含的信息量不同,仿照SegNet 模型的原生编码器,采用两种解码的方式分别针对深层和浅层特征,因为浅层特征更大程度保留图像原始的位置与结构信息,而深层特征则包含更多的抽象信息,两者进行融合可以使原图像得到更好地恢复。

图1 Seg-RFNet 网络结构Fig.1 The architecture of Seg-RFNet
1.1 分支残差编码层
深度残差网络ResNet[27]通过引入残差单元,解决了网络深度增加所带来的梯度消失和性能退化的问题,大幅提升了网络性能。 如图2 所示为基本残差单元结构,F(x)表示残差路径,x表示恒等连接路径。 残差路径由2 个卷积层、批标准化(batch normalization, BN)和线性激活函数(rectified linear units, ReLU)构成,恒等连接路径没有导致额外的参数量和计算复杂度。 两条路径的结果相加即为输出。

图2 基本残差单元Fig.2 Residual block
ResNet50 即由一系列不同的残差单元串联而成,结构如表1 所示。 对于输入眼底原图I∈RW×H×3,其中W、H、3 这3 个参数分别代表图像的宽度、高度和通道数。 使用提取特征能力更强的Resnet50 作为编码器模块,替换原生SegNet 的编码器模块提取多层特征{Fk}k =1,将ResNet50 分为5个模块,用layer1 和layer2 表示浅层特征提取模块,layer3、layer4 和layer5 表示高层特征提取模块。 由于浅层网络里面保留的空间信息可以更好构建分割对象的边界,深层提取层可以保留特定对象的语义上下文信息[28]。 为分化深层特征,得到更多深层特征信息,在原编码层的基础上对第3 层进行分支处理。 在编码器所提取的特征分为浅层{F1,F2},深层{F3,F4,F5}。 再通过级联组合的方式进行特征融合以保留来自各层的丰富线索,组合可表达为

表1 ResNet50 骨干网络结构Tab.1 The backbone structure of ResNet50

式中,Cat 表示特征图的拼接,UP 表示上采样操作。再使用感受野模块放大特征感受野区域。
1.2 融合感受野的解码层
和原生的SegNet[23]解码层所不一样的是,进行解码的特征信息是经过感受野模块处理之后的特征。 在卷积神经网络中, Inception[29]和Deeplabv3[26]是两个经典的模型。 Inception 在同一层中采用不同大小的卷积核进行分支处理,再将经过各分支的特征拼接,意味着不同尺度特征的融合拓宽了网络宽度。 而Deeplabv3 模型的关键结构是空洞卷积(dilated convolution),可以在不改变特征图大小的同时控制感受野,有利于提取多尺度信息。 本研究提出的感受野模块受到了上述两种模型的启发。 感受野模块具有两个特点:一是采用不同尺寸卷积核的卷积层构成的多分支结构;二是引入了空洞卷积层。 如图3 所示为感受野模块的结构,包含5 个分支{bk,k =1,2,…,5} ,在每一个分支中,先使用基础卷积层,即(Conv(1 × 1) +BN +ReLU) 。 然后对k≤4 的分支使用尺寸为(2k-1)×(2k-1)的卷积层和一个空洞卷积层,膨胀因子为dilation =2k-1,然后将4 条分支的结果进行1×1 卷积操作, 增加更多的非线性特性,然后对它们进行拼接操作以获取多尺度特征信息。 最后与第5 条分支残差进行融合,提升语义表达能力的同时能加速梯度反向传播。 另外,在多尺度卷积中,当k较大时,直接实现(2k-1)×(2k-1)尺寸的卷积核会极大增加计算量,因此使用(2k-1)×1 与1×(2k-1)卷积层级联代替,在减少参数的同时还可以增加一层非线性扩展模型的表达能力[30]。 最后对5 个分支的特征进行相加并使用ReLU 函数激活得到处理后的特征。

图3 感受野模块结构Fig.3 The structure of receptive field block
感受野模块的详细结构如图4 所示,用3 种不同大小和颜色的输出叠加来展示。 用不同大小的圆形表示不同尺寸卷积核的卷积层,并结合不同扩张因子的空洞卷积层,最后将不同尺寸和扩张因子的卷积层输出进行特征拼接。 从特征拼接图可以看出,引入多分支多尺寸卷积核,可以捕捉不同感受野的信息,人类视野的特点就是距视野中心距离不同感受野不同,所以使用多分支结构,每个分支捕捉一种感受野,最后通过特征拼接来融合感受野信息,可以达到模拟人类视觉的效果[31]。 引入空洞卷积层,可以在不增加参数量的前提下,增大感受野。

图4 感受野模块详解Fig.4 Detailed illustration of receptive field block
根据得到的感受野模块处理后的特征,使用解码器进行解码。 此时由编码器前两层处理后得到的是浅层特征,其余是深层特征。 仿照SegNet[23]的原生解码器,针对不同层次的特征,设计两种解码方式,其结构如图5 所示,可以看出两种解码方式的不同在于浅层特征没有特征融合部分,意义在于保留之前的图像空间细节信息。

图5 解码层结构。 (a) 深层特征解码层;(b)浅层特征解码层Fig.5 The structure of decoding layer.(a)Deep feature decoding layer; ( b) Shallow feature decoding layer
1.3 数据集
选用REFUGE 数据集[32]进行方法验证。REFUGE 数据集同时包括诊断、图像分割及定位信息,其中分割定位标签由7 位专家的手动标记结果融合,是目前青光眼眼底图像数据库中标注信息最全面的数据库。 REFUGE 数据集分为训练组、验证组和测试组,共有1 200 视网膜眼底图像。 训练、验证、测试数据集的比例为1 ∶1 ∶1,由于其中400 张训练数据和400 张验证数据包含眼底图像和其对应的标签,剩下的400 张测试数据只含有眼底图像,所以采用训练组和验证组共计800 张眼底图像进行试验。 训练组的400 张眼底图像是由型号为Zeiss Visucam 500 眼底相机拍摄的,图像大小为2 142 像素×2 056 像素。 验证组400 张眼底图像由型号为Canon CR-2 眼底相机拍摄,图像大小为1 634 像素×1 634 像素。 两组数据采用不同相机,具体如图6所示。

图6 不同眼底照相机拍摄的眼底图像。 (a) Zeiss Visucam 500 拍摄;(b) Canon CR-2 拍摄Fig.6 Fundus images taken by different fundus cameras.(a) Taken by Zeiss Visucam 50; (b)Taken by Canon CR-2
1.4 图像预处理
1.4.1 极坐标变换
由于REFUGE 数据集提供的是整幅眼底图像,因此视杯视盘区域占了相当小的一部分,为防止血管、黄斑等无关区域对视盘分割结果的影响,首先采用现有的视盘自动检测提取方法确定初始视盘中心[33],然后以其为中心从整图中裁剪出大小为480 像素× 480 像素的感兴趣区域。 然后,将得到的感兴趣区域以初始视盘中心为原点进行如式(2)所示的像素级极坐标变换,有

式中,u,v表示某个像素在笛卡尔坐标系下的横纵坐标;θ,r表示某个像素在极坐标下的方向角和半径。 极坐标变换效果如图7 所示。

图7 眼底图像和标注的预处理流程。 (a)原始眼底图像;(b)感兴趣区域图像;(c)极坐标变换后图像;(d) 原始标注;(e) 感兴趣区域标注;(f) 极坐标变换后的标注Fig.7 Preprocessing of fundus image and label.(a)Original fundus image; (b)Region of interest image;(c) Image of polar coordinate transition; ( d)Original label; (e) Region of interest label; (f)Label of polar coordinate transition
预处理引入极坐标变换,不仅可以平衡视杯视盘面积占比,而且可以使用层状结构表达视杯、视盘和背景的空间约束关系[20]。 通过极坐标变换后使眼底图像具有旋转和尺度不变性,可以简化视盘视杯分割问题,从而有效地提取特征,有利于分割模型的训练,实现更好的视盘视杯分割性能。
1.4.2 数据增强
由于数据集样本数量较少,在裁剪得到感兴趣区域并进行极坐标变换处理后,再对数据集进行数据增强。 采用离线随机数据增强的方法,对样本加入随机噪声扰动、随机旋转和翻转,以及进行亮度和对比度的随机调节。 数据增强的作用是增加训练样本的数量以及多样性,提升模型鲁棒性。 随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
1.5 实验
1.5.1 实验设备
实验使用的深度学习框架是PyTorch1.2.0,计算机操作系统为Windows 10,采用Python 语言实现编程。 硬件部分,采用显存为8 GB、型号为Nvidia GeForce GTX 2080 SUPER GPU 和主频3.60 GHz 的型号为Inter(R)i9-9900 k CPU。 采用Adam 优化器对深度模型进行优化,因为其计算高效,对内存需求少,可以在训练时自行更新学习率。
1.5.2 实验细节
首先对图像进行预处理,随后使用网络训练来学习优化参数,并在每个训练迭代周期结束后保存最佳网络模型,最后测试最佳网络模型并预测结果。 初始学习率设为0.000 3。 Batch size 设置为2,训练迭代次数为50。 本实验以有监督训练的方式进行,其中75%即600 张眼底图像用于训练,12.5%即100 张图像用于验证,12.5%即100 张图像用于测试。 训练集每迭代一次,对验证集进行一次整体评测,实验测试结果与专家人工标注结果作对比,得到测试图片的最好分割结果作评价指标的分析。实验评价指标所得到的评价指标均使用K=5 的K折交叉验证所得到的平均分评分,不同方法的对比所采用的数据集切分方案一致。
1.5.3 评价指标
为评估Seg-RFNet 模型的性能,采用Jaccard 相似度(Jaccard similarity,JS)和F 分数(FS)两个评价指标,JS 和FS 计算分别表示为

式中,TP 是真正例,即网络输出为正,实际上也为正;TN 是真负例,即网络输出为负,实际上也为负;FP 是假正例,即网络输出正,但实际上为负;FN 是假负例,即网络输出正,但实际上为负。P表示精确率,R表示召回率。 可以看出,JS 指的是交集与并集的比值可以用于比较分割结果与专家分割结果之间的相似性与差异性,即视盘重合率;FS 是精确率和召回率二者算数平均值与几何平均值的商,可以综合反映两指标的特性。 JS 与FS 介于0 与1 之间,越接近于1,代表结果越好。
通过对眼底图像进行感兴趣区域获取、极坐标变换预处理,得到了更加聚焦于视盘的区域,随后采用多种数据增强的方法,得到最终用于模型训练和验证的数据。 首先,为了验证模型自身构造的合理性,设置两组对比实验,第1 组为编码器结构对比实验,计算3 种不同编码器结构的分割效果;第2 组对比实验为感受野模块数量对比实验,分析感受野数量与分割效果之间的关系,验证该模块的有效性。 为了更加客观地评价Seg-RFNet 的性能,引入5种现有的主流分割模型进行对比。 其次还探究了不同的损失函数对分割效果的影响。 以上实验均采用JS 和FS 作为评价指标。 最后,从参数量和计算量这两个角度评价本文提出的模型与其余5 种主流分割模型的效率。
2 结果
在其他条件不变的情况下选取3 种编码器结构VGG16、ResNet50、ResNet101 做对比实验,结果如表2 所示,实验结果表明,使用3 种编码器在JS 和FS两项指标的差别不大,不会对解码器部分产生关键的影响。

表2 不同的编码器结构对分割效果的影响Tab.2 Influence of different encoder structures on the segmentation effect
为了验证Seg-RFNet 在视杯视盘分割任务上的有效性,使用REFUGE 数据集和相同的实验环境与5 种基准模型进行对比实验,其定量结果见表3。 结果表明所提出的Seg-RFNet 整体性能要优于其他5 种模型,表征视杯、视盘分割性能的JS 和FS 分别为0.951 5、0.872 0 和0.974 9、0.930 1,相较于原生的SegNet 框架,分别提高了2.8%~14.5%,1.5%~8.5%。
表4 表明了感受野模块数量对分割性能的影响,可以看出感受野数量与JS 和FS 两项指标的值呈现明显正相关趋势,说明了感受野模块的有效性。 在Seg-RFNet 结构中部署感受野模块数量小于等于6 的时候深层分支数量无需增加,而当感受野模块数量达到6 以上时需通过增多深层分支(layer4,layer5)数量,从而导致网络复杂度更大,总体的参数量和浮点运算量也会增加。
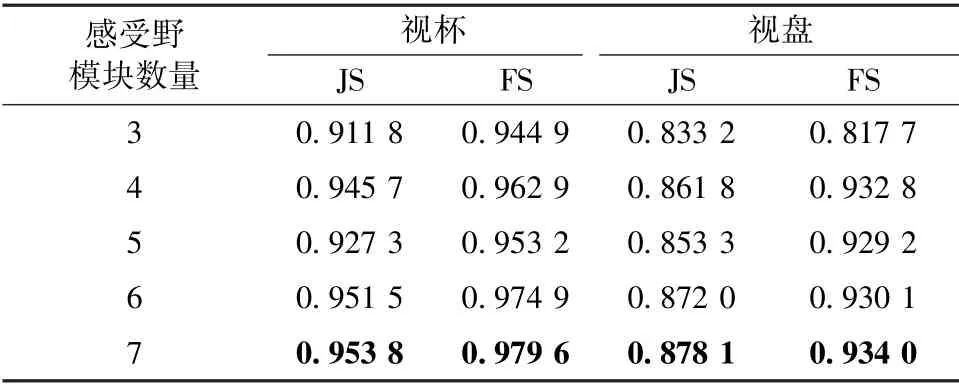
表4 感受野模块数量对分割性能的影响Tab.4 The influence of the number of receptive field Blocks on segmentation performance
通过表5 可知,使用Dice 损失函数的结果要略优于传统的交叉熵损失函数。

表5 不同损失函数对性能影响Tab.5 Impact of different loss functions on performance
6 种神经网络模型的参数量和计算量对比结果如表6 所示。 参数量和计算量都是衡量深度学习算法的重要指标,参数量对应模型的空间复杂度,计算量对应的是模型的计算复杂度,对应硬件层面,参数数量对应的是计算机内存资源的消耗,计算量对应的是计算时间。 实验结果表明,Seg-RFNet 的参数量和浮点运算量(floating point operations,FLOPs) 分别为25.743 M 和5.209 G。 Seg-RFNet在性能提升的同时,参数量没有明显增加,而计算量大幅降低。
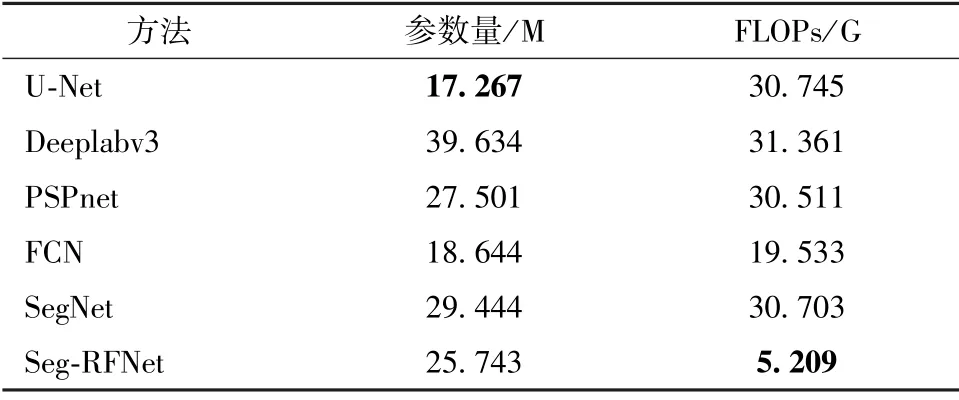
表6 不同方法的参数量和计算量对比结果Tab.6 Comparison of different methods in terms of parameters and FLOPs
此外,将视杯视盘分割结果可视化,可以更直观的比较Seg-RFNet 与其他深度学习模型的分割结果。 从REFUGE 数据集中选取11 张图像,分割结果如图8 所示。 可以看出其他5 种模型的分割结果不如Seg-RFNet 网络,与表3 中的定量结果相吻合。

图8 11 幅不同图像(从上至下)采用不同模型的视杯视盘分割效果对比,其中白色区域为得到的视杯区域,灰色部分为视盘区域。 (a)原图;(b)标注图像;(c)FCN;(d)U-Net;(e)Deeplabv3;(f)SegNet;(g)PSPnet;(h)Seg-RFNetFig.8 Comparison of different models for optic cup and disc segmentation with 11 different pictures (From the top to the bottom).The white areas are optic cups, the gray areas are optic discs.(a) Original pictures; (b)Annotated pictures; (c) FCN; (d) U-Net; (e) Deeplabv3; (f) SegNet; (g) PSPnet; (h) Seg-RFNet

表3 不同方法在REFUGE 数据集上的对比结果Tab.3 Comparison results of different methods on REFUGE dataset
3 讨论
本研究提出了融合感受野模块的卷积神经网络Seg-RFNet,对眼底图像中的视杯视盘进行联合分割。 利用ResNet50 强大的网络性能,并将其深层网络分支,充分提高了高维特征的利用率;同时将各层特征都经过感受野模块的处理,更加扩宽了网络的宽度,丰富了特征的语义信息,得到了比现有的方法更高的精确度。 针对本研究中涉及到的一些问题进行讨论。
首先,网络的编码器部分使用了ResNet50 网络,因为其在计算速度和硬件资源消耗方面更有优越性,虽然ResNet101 性能指标最好,但其结构复杂,运行较为耗时。 而VGG-16 网络的特点是卷积核更小,网络结构更浅,使其在提取图像浅层特征如形状、纹理、轮廓的时候也获得了大量的冗余特征和噪声信息,从而影响分割网络整体的性能,因此ResNet50 作为采用的折中方案,兼顾运行速度和质量。
Seg-RFNet 的分割性能优越性可以通过实验体现在定性和定量两方面,JS 和FS 均超过其他5 种方法,原因在于编码器采用ResNet50 残差模块可以使网络的梯度消失问题得到有效抑制,而内部的跳跃连接可以保留浅层网络的表面特征,实现了不同层次的特征融合。 解码器采用感受野模块可以模拟人类视觉的特点使模型获得更强的特征感知能力。 而从具体的分割效果图来看,可以看出U-Net与SegNet 分割效果较差,受到了血管等其他结构的影响。 图8 中第1 行、第4 行和第8 行对比尤其明显,甚至出现了视杯在视盘外部的分割样例;从第6行、第8 行和第11 行来进行对比分析,可以看出FCN 与PSPnet 的分割轮廓精度比较粗糙,边界不够规则,出现了锯齿现象。 而Seg-RFNet 网络输出的分割结果更接近于专家标注的金标准,而且Seg-RFNet 网络输出的分割结果更加平滑,出现的不规则边缘更少,其原因是解码层采用残差网络,并进行深层网络分支,以及融合了感受野模块,使得Seg-RFNet 网络获得了更多样的语义信息。 这与表2 中的定量结果相吻合。 因此可以说明Seg-RFNet 对视杯、视盘的分割效果更精确,能够为计算杯盘比提供更加精确的依据,从而减少误诊率,这对青光眼早期辅助筛查与诊断是有益的。
另一个值得探讨的问题是Seg-RFNet 在性能提升的情况下,参数量没有过多增加,而且计算量大幅降低。 主要在于编码器的残差连接在缓解梯度消失问题的同时,也大大降低了网络模型的计算量;其次,Seg-RFNet 无需如同U-Net 模型在编码器和解码器之间大量使用特征拼接,也大幅减少了模型的计算复杂度。
本研究也有局限之处,数据集的预处理与分割被分离成两个独立的阶段,如何将这两个过程合并,从而提高眼底图像的分割效率,是以后需要研究的重要内容。 同时,在预处理过程中采用的感兴趣区域裁剪方法有进一步优化的空间,可以引入目标检测的方法提升定位视盘中心的精度,从而影响后续分割的准确度。 另外,也存在反极坐标变换结果后,边界不够平滑的情况。
4 结论
本研究在对眼底图像进行极坐标变换的基础上,提出一种融合感受野模块的视杯视盘分割网络Seg-RFNet。 该模型采用ResNet50 作为编码层,并且通过将编码层分支,增强了提取图像深层抽象语义特征的能力;在编码层与解码层之间了感受野模块,增大了感受野,增强了有用特征的响应能力。通过REFUGE 数据集与其他5 种分割模型进行对比实验,表明Seg-RFNet 具有较好的视杯视盘分割性能,得到了更为精确的分割结果,为计算杯盘比获得了更可靠的依据。 未来工作还需进行跨数据集验证Seg-RFNet 模型的泛化性和鲁棒性。
