基于LSTM的边境频谱占用度预测
2022-08-03芦伟东罗士伟刘依卓
芦伟东,罗士伟,刘依卓
(国家无线电监测中心哈尔滨监测站,黑龙江 哈尔滨 150010)
0 引言
频谱占用度是用来描述无线电频谱资源利用率的重要指标,其也可以反映一个地区的频谱利用率变化趋势,边境地区的无线电监测的重要任务之一就是获取准确的频谱占用度,为上级无线电主管部门制定频率使用规划和国际台站申报计划提供重要依据。传统的分析方法不能通过频谱占用度的历史数据来预测频谱未来一段时间的频谱占用情况,难以满足无线电管理需求。本文提出一种边境频谱占用度预测方法,通过实验优化预测模型参数设置,使其能够达到预测未来一段时间内频谱占用度的目标。
1 时间序列
在不同时间对相同对象的持续观察而得到的序列称为时间序列[1]。通过对历史数据进行相关性分析,达到预测未来时间序列的目标。频谱占用度是通过不同时间段观测频谱占用情况而得到的数据,因此其自然构成了时间序列。频谱占用度时间序列的平稳性取决于具体数据的变化趋势。
2 长短期记忆神经网络模型
长短期记忆(Long Short Term Memory,LSTM)神经网络通过门限机制留下输入数据的有用信息[2],并控制其积累速度,相对于普通循环神经网络,LSTM神经网络的隐藏层中除状态h外,还引入了状态c用于非线性信息的传递(如图1所示),即

式中,U为网络参数;tanh(·)为激活函数。
随着时间t的增加,ct的累积量将会变得越来越大,如图2所示,这时LSTM的门限机制会主动遗忘部分累积信息,避免出现信息量过大的问题。

图2 增加新状态后的循环神经网络结构
在t时刻有三个输入量:xt,ct-1和ht-1,有两个输出量:ct和ht。LSMT的门限机制由输入门、遗忘门和输出门实现。
(1)输入门的主要目的是通过下式确定输入xt中部分信息留在ct中。

式中,i表示输入;为激活函数;U,V,W为网络权重参数;it为t时刻的输入数据,通过输入门,将输入中对应的保留下来,即对应向量中对应元素的乘积。
(2)遗忘门的目的是确定t时刻输入中的ct-1有多少成分保留在ct中,实现公式为

式中,f表示遗忘,此公式确定了遗忘门的门限,与输入门的门限一样,即通过遗忘门之后,将输入中的保留下来。
(3)输出门的目的是利用控制单元ct确定输出ot中有多少成分输出到隐含层ht中。

式(4)由两部分组成,一部分为输入门中存储的信息,另一部分为遗忘门中的存储的信息。下面给出留在ht中的信息实现公式:

式中,输出层状态ot经过输出门,留在隐藏层中的信息实现公式为

综上所述,随着时间的变化,整个网络的结构设计流图如图2所示,目前LSTM神经网络已被成功应用于数字识别、语音识别、图像识别等领域。
3 基于LSTM的频谱占用度预测模型
建立基于LSTM的频谱占用度预测模型主要有5个步骤(如图3所示):首先导入时序数据,通过设定隐藏层和输出层数量及激活函数来定义模型;然后编译模型,为了使用模型能够有效的进行数值计算,设定整个模型的损失函数和优化函数;最后对模型进行训练和评估预测效果。

图3 建立LSMT预测模型流程
4 实验仿真
模拟2010年1月至2021年12月期间某边境监测站某频段的频谱占用度数据,根据从实际边境频谱监测工作中获取的频谱占用度数据特征,随机生成144个月的频谱占用度数据样本,即生成时间序列数据。下面将根据建立LSMT预测模型流程进行实验仿真。
4.1 实验步骤
4.1.1 导入时序数据
导入时序数据集(如图4所示),可以看到频谱占用度逐年增高的趋势。对数据集进行预处理,将单列数据集转化为两列数据集,第一列包含当月(t)频谱占用度,第二列包含下个月(t+1)的频谱占用度。
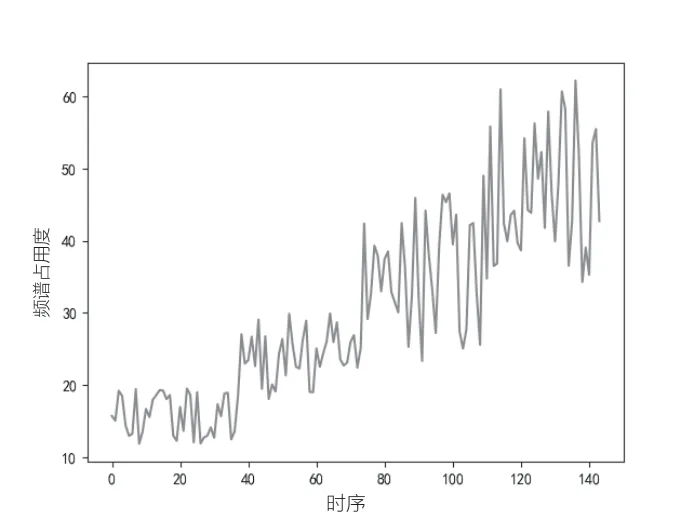
图4 原时序数据集
4.1.2 定义模型
首先对数据集进行归一化处理,设定存储单元和输出层数,选定sigmoid作为激活函数,选取训练数据集,设定训练次数。
4.1.3 编译模型
损失函数选取均方误差,优化函数选取自适应矩估计。
4.1.4 训练和评估模型
用训练数据集对LSMT模型进行训练,用均方根误差(Root Mean Squared Error,RMSE)作为模型预测准确度评价指标。

4.2 结果与分析
4.2.1 选取不同比例的训练数据
在144个数据样本中,分别选取30%、60%和90%比例的数据作为训练数据集。用激活函数对数据进行[0,1]区间的归一化处理,设定隐藏层有4个存储单元,训练次数为100,单个预测值输出层,对比预测结果的评价指标如表1所示。

表1 不同训练集比例的预测结果评价指标
可以看出,当选取训练数据集的比例由30%增加至60%,训练误差增大,预测误差减小;由60%增加至90%时,训练和预测误差都增大。这说明并非训练数据的比例越高越好,预测效果取决于样本特征数量与网络存储能力的匹配程度。
选取60%的总样本数据作为训练数据集,分别选取4,128,256个隐藏层存储单元,其他实验条件不变,对比预测结果的评价指标如表2所示。

表2 不同存储单元个数的预测结果评价指标
可以看出,在存储单元个数从4个增加到128个时,训练误差略有增加,预测误差降低,从128个增加到256个时,预测误差并没有随着存储单元个数的增加而明显降低,反而有所增加,这说明存储单元个数达到128以后,LSTM网络记忆了太多无效信息,因此无需再增加存储单元的个数。
4.2.2 选取不同的训练次数
选取60%的数据样本作为训练数据,128个隐藏层存储单元,分别采用50、100、300训练次数,其他实验条件不变,对比预测结果如表3所示。

表3 不同训练次数的预测结果评价指标
可以看出训练次数为100次时,可以得到较低的预测误差,说明网络已经比较稳定,训练效果较好。
4.2.3 选取不同的窗口大小
对于时序预测问题,可以使用多个最近的时间项来进行下一个时间项的预测,时间项的大小即为窗口大小。分别选取1个月和3个月的窗口大小对下一个月进行预测,以总样本60%的数据作为训练集,预测结果如表4所示。
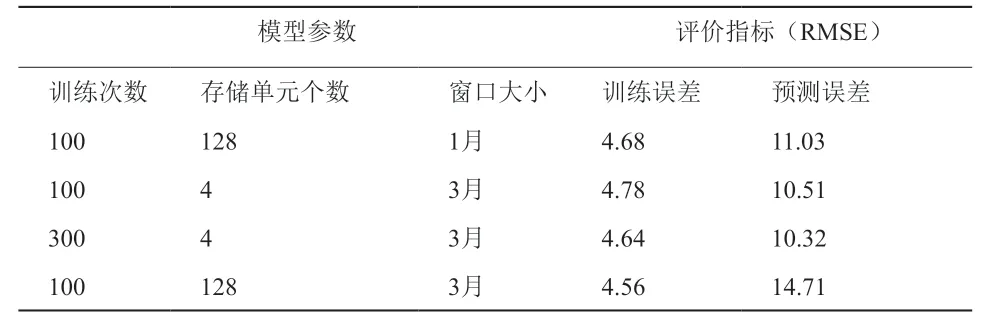
表4 不同训练次数的预测结果评价指标
可以看出,当窗口大小从1月增大为3月时,训练次数和存储单元的个数都会对预测误差产生影响,这说明窗口的大小需要针对不同的问题进行调整,不断进行调整参数的尝试,才能得到较好的预测效果,如图5所示。

图5 较好预测结果
4.2.4 分析
以上实验涵盖了影响边境频谱占用度预测准确度的主要因素,分别进行了对比实验,得到以下结论:对于此模拟边境频谱占用度数据集进行基于LSMT的频谱占用度预测,以总样本数据的60%作为训练数据集,选取4个隐藏层存储单元,网络进行300次训练,选取窗口大小为3个月,可以得到较为理想的预测结果。
5 结束语
对于边境频谱占用度的预测问题,本文提出了基于LSMT的边境频谱占用度预测方法,分析了影响预测误差的主要因素,并得出结论,此预测方法在满足一定的条件下,可以得到较为理想的频谱占用度预测结果,为提升我国边境地区频谱竞争力和上级主管部门频谱规划的前瞻性提供了一种解决方案。■
