地震诱发滑坡空间分布概率近实时预测研究
——以2022年6月1日四川芦山地震为例*
2022-08-02范宣梅方成勇戴岚欣罗永红王运生
范宣梅 方成勇 戴岚欣 王 欣 罗永红 魏 涛 王运生
(地质灾害防治与地质环境保护国家重点实验室(成都理工大学), 成都 610059, 中国)
0 引 言
2022年6月1日17时00分,四川省雅安市芦山县(30.37°N, 102.94°E)发生6.1级地震,震源深度17km,发震断层为龙门山中央断裂带的小关子断裂,震源机制为逆冲型(中国地震台网)。此次地震与2013年4月20日芦山地震(MS7.0)相距9km。据报道,截止2022年6月3日5时,地震已造成4人死亡(均在宝兴县)、42人受伤(宝兴县31人,芦山县11人), 14427人受灾(宝兴县7505人、芦山县5470人、雨城区83人、荥经县40人、天全县214人、名山区1115人)。

震后快速准确获取地震诱发滑坡的分布范围和评估可能的灾害损失对地震灾害应急救援和安置规划至关重要(黄润秋等, 2009)。通过基于遥感影像的目标识别和地表覆盖变化分析是大范围滑坡分布获取最有效方法(Guzzetti et al.,2012; Amatya et al.,2021; Wang et al.,2022)。然而,这种方法非常依赖影像获取的天气条件。目前距此次芦山地震发生已有一周时间,但由于震后的阴雨天气至今仍难以获取清晰的卫星遥感影像。震后72h为救援的黄金期,在无法获取震后遥感影像的空窗期,就需要利用地震诱发滑坡空间分布预测模型,进行同震滑坡的快速预测,从而为应急救援提供支撑。目前,国内外已有部分学者开展了同震滑坡易发性评价模型方面的研究,这些模型大多以历史滑坡数据为训练样本,采用空间统计方法如信息量法、逻辑回归等进行建模,然而简单的空间统计模型难以快速有效地处理大量滑坡样本数据集(Nowicki Jessee et al.,2018; Lombardo et al.,2020; 许冲, 2020),因此深度学习算法越来越受到地球科学界的关注。
1 研究区概况

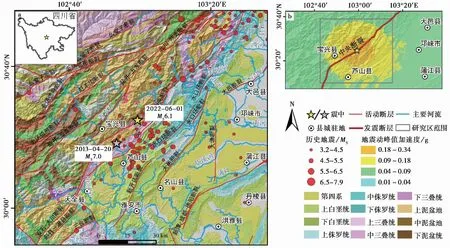
图1 a. 2022年6月1日芦山地震影响区域地质构造图; b. 地震动峰值加速度图Fig. 1 a. Geological structure map of the area affected by the June 1st, 2022 Lushan Earthquake; b. Peak acceleration of ground motion
据中国地震台网中心数据显示,距离震中200km范围内历史地震活动强烈, 1900年以来内共发生6级以上地震21次,震级最大的为2008年5月12日四川汶川8.0级地震(距离本次地震震中约83km),空间距离最近的为2013年4月20日四川芦山7.0级地震(距离本次地震震中约9km)。地震主要影响区域平均海拔2000m以上,最高海拔4115m,最低557m。
2 数据与方法
2.1 数 据
地震诱发滑坡(同震滑坡)数据是建立地震诱发滑坡空间分布概率预测模型(易发性模型)的基础。笔者团队建立了全球42次地震诱发滑坡事件数据库,共包括近30万处全球地震滑坡数据,并对其进行标准化处理。其中:近年来有5次地震发生在青藏高原及周缘,包括2008年汶川地震、2013年芦山地震、2014年鲁甸地震、2017年九寨沟地震以及2017年米林地震,如图2所示。这5次地震所在的区域地质环境条件与本次芦山地震较为接近,且地震信息丰富,呈现不同的震源机制: 2008年汶川地震和2013年芦山地震的发震断层为逆冲断层, 2017年九寨沟地震的发震断层为走滑断层。因此,模型将这5次地震事件作为训练样本,以建立适用于青藏高原及周缘区域的同震滑坡预测模型。模型主要采用地形、地质环境和地震(刘艳辉等, 2021; 张卫杰等, 2022)3类控制地震诱发滑坡灾害的关键因素,具体体现为10种特征因子(表1)。

图2 中国境内5次同震滑坡事件空间分布图Fig. 2 Spatial distribution of five coseismic events in China
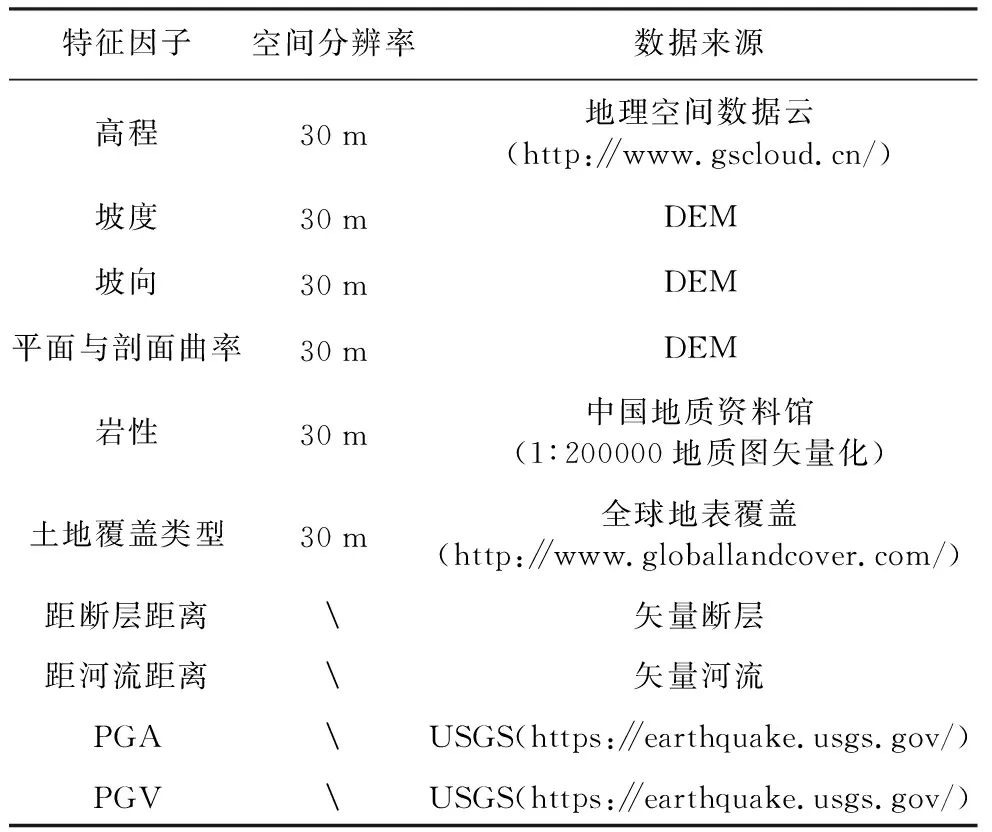
表1 同震滑坡特征因子及数据来源Table 1 Coseismic landslide characteristic factors and data sources
2.2 同震滑坡空间分布概率预测模型

图3 同震滑坡模型构建流程图Fig. 3 Flow chart of coseismic landslide model construction
为了客观评价模型的性能,本文构建了一套综合多种指标的评价体系,除了常用的精度系数(ACC)和曲线下面积(AUC)指标外,还额外选择了Kappa系数(Kappa)、F1系数(F1_score)、平均交互比(MIOU)来评价模型表现,几种函数的表达式如下:

(1)
(2)
(3)
式中:pii是第i类像素被成功预测的概率;pij是第j类像素被识别为i类像素的概率;pji是第i类像素被识别为j类像素的概率;pjj是第j类像素被成功预测的概率;pi是i类像素的总和;pj是j类像素的总和。
留一法是统计学习中常用的一种交叉验证方法(Wong, 2015),即在构建模型的过程中,每次保留一个相对的独立的测试数据集用于检验模型性能,剩下的全部作为训练集,通过这种方法得出结果的泛化能力与整个数据集期望值最为接近。本文所选取的5次国内地震事件留一法测试结果如表2所示。
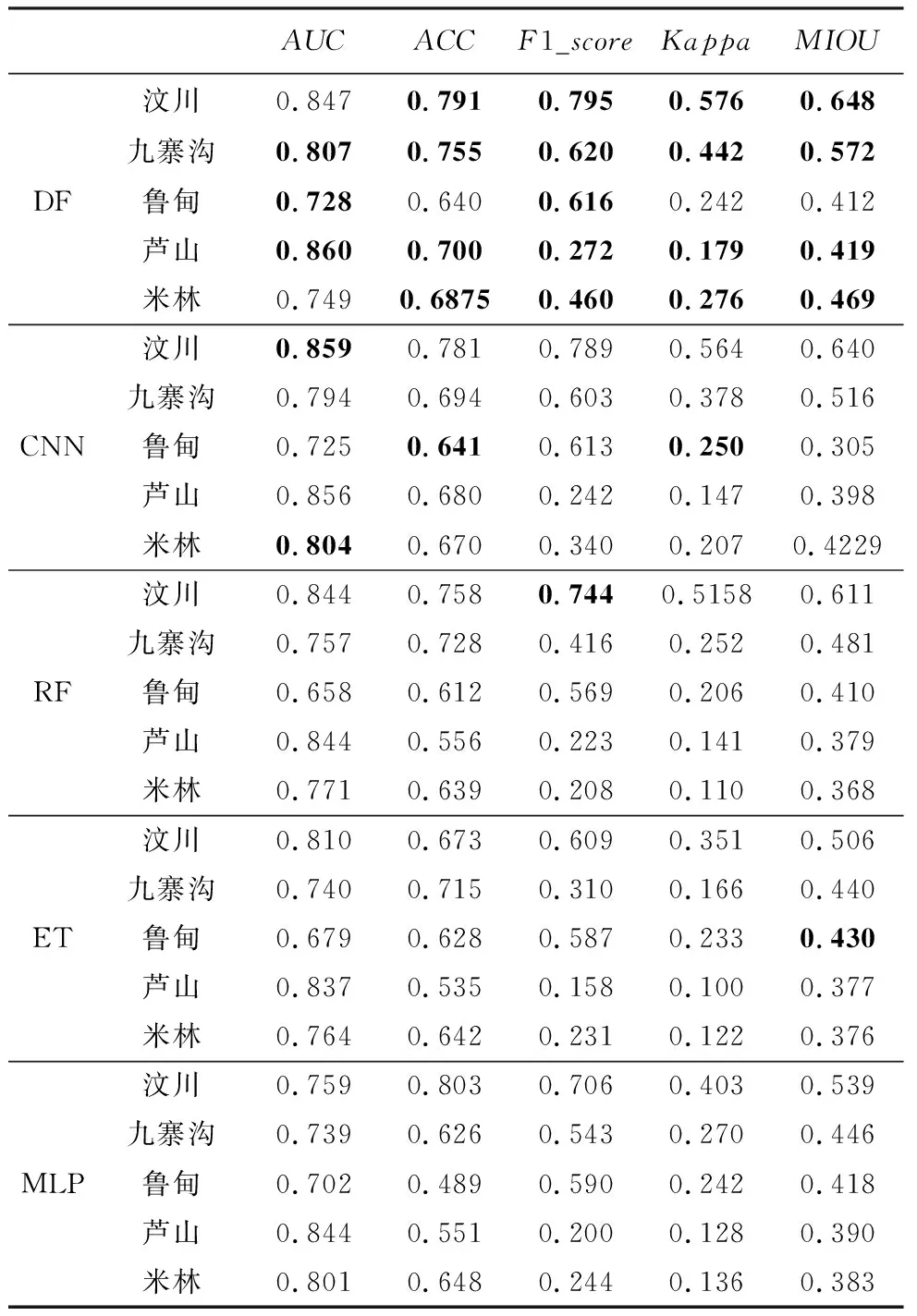
表2 5次地震事件交叉验证的最佳结果Table 2 Best results of cross validation of five seismic events
由表2 可见,5种模型的交叉验证结果显示,深度学习算法的整体精度指标显著高于传统算法。进一步对比CNN与DF算法,发现DF算法拥有更好的泛化性能。此外。结果还表明汶川和九寨沟两次地震事件的交叉验证结果最好。从这5次地震事件的实际结果来看,由于汶川和九寨沟两次事件拥有相似的地貌环境条件,因此模型在这两次事件中展示出了较强的泛化能力。
采用留一法进行交叉验证的目的是为最终同震滑坡模型构建挑选最优算法和参数。虽然米林、芦山和鲁甸的精度指标反映出模型的泛化能力相对较弱,但这并不妨碍我们将这些事件纳入滑坡样本数据库中进行模型训练。图4和图5显示了同震滑坡空间分布概率预测模型的精度。

图4 同震滑坡空间分布概率预测模型ROC曲线及AUC值Fig. 4 ROC curve and AUC value of coseismic landslide spatial distribution probability prediction model
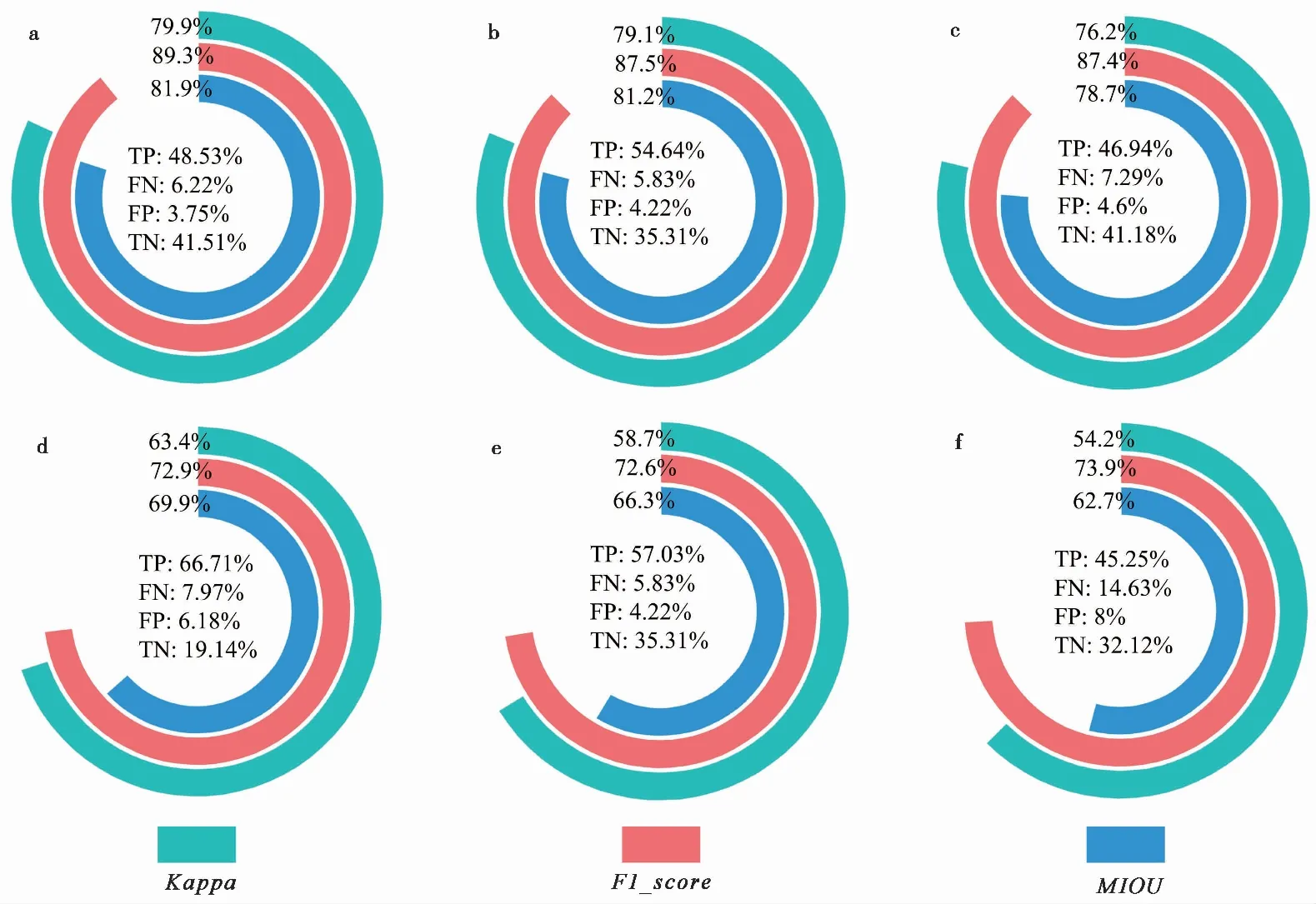
图5 训练数据集和5次地震事件的测试数据集在模型中的精度评价结果Fig. 5 The accuracy assessment results of the training data set and test data set of five seismic events in the modela. 训练数据集; b. 米林事件; c. 汶川事件; d. 九寨沟事件; e. 芦山事件; f. 鲁甸事件
由于同震滑坡数据库在标记过程中的误差和30m地貌数据自身客观存在的数据噪声,训练数据集的拟合精度大约为90%。从5次地震事件的测试数据精度来看,它们的Kappa系数大于0.55,F1系数大于0.7,MIOU系数大于0.6,表明该模型在不同的地震事件中都具有良好的预测能力,可以用于青藏高原东缘地震诱发滑坡空间分布概率快速预测。
3 芦山地震诱发滑坡空间分布概率预测

图6 a. 2022年6月1日芦山地震诱发滑坡空间分布概率图; b. 宝兴东河流域位置图Fig. 6 a. Spatial distribution probability of earthquake-induced landslides in Lushan on June 1st, 2022; b. Location of Baoxing Donghe Basin
从整个研究区的预测结果来看,同震滑坡高易发区主要分布于距震中和发震断层15km的空间范围内,该区域地形高差显著,属高山峡谷地貌,平均海拔在2500m以上,平均坡度大于35°。此外,同震滑坡空间分布规律上,还呈现出明显的上下盘效应,与前期研究发现的大多数逆冲断层的上下盘效应一致(Huang et al., 2013; Fan et al.,2019)。
4 宝兴东河流域地震诱发滑坡灾害特征与预测模型复核
4.1 宝兴东河流域地质灾害特征

图7 宝兴东河流域芦山地震诱发滑坡空间分布概率预测与现场滑坡调查结果比对分析Fig. 7 Comparison between the prediction of spatial distribution probability and on-site landslide investigation of “6.1” Lushan Earthquake-induced landslides in Baoxing Donghe Basin

图8 宝兴东河流域诱发滑坡野外照片Fig. 8 Field photos of landslide induced in Baoxing Donghe Basina. 东河流域沟口东河村附近浅表层滑坡群, b. 水塘上华能宝兴电站运营中心附近岩质滑坡, c. 光明村附近浅表层崩塌-碎屑流, d. 新华村岩质崩塌, e. 华能宝兴水电站附近土质滑动, f. 华能宝兴水电站库区新华村壅塞体; 蓝色箭头指明河道流向
4.2 同震滑坡空间分布概率预测模型复核
通过东河流域地质灾害应急调查,确定了124处灾害位置,其中78.23%的灾害点位于滑坡预测结果的中到高易发区,仅有18处小型滑坡和9处崩塌灾害点位于低易发区,初步说明地震诱发滑坡空间分布概率模型预测结果与实际的滑坡分布较为吻合。特别值得指出的是,所有的相对较大规模的滑坡,均发生在预测的高易发区内。例如,新华村滑坡-堰塞湖(图8f,长约510m,宽约270m)和华能宝兴水电站附近的土质滑坡(图8e,长约460m,宽约170m)均位于预测的高易发区。可见,模型对大规模滑坡的预测能力优于小规模滑塌,而规模较大的滑坡往往对震区人民的生命财产安全和重大基础设施造成更为严重的危害。因此,预测大规模滑坡的空间分布对地震地质灾害风险防控具有更为重要的意义。
受天气影响,震区目前尚无清晰的卫星遥感影像,后续获取到高质量遥感数据后,可建立整个震区的完整数据库,对模型结果进行进一步复核与优化。此外,本次地震的经验还表明,地震诱发滑坡空间分布概率近实时预测模型,可以较好地填补遥感数据缺失的空窗期,为震后应急救援和抢险工作提供信息支撑与决策依据。
5 讨 论
地震诱发滑坡预测是国际地球科学领域的前沿热点问题。为此,美国地质调查局USGS也研发了近实时地震诱发滑坡预测模型,并进行了一段时间的线上试运行(https:∥www.usgs.gov/programs/earthquake-hazards/science/earthquake-hazards-101-basics),其主要采用传统的统计模型(逻辑回归模型),地质环境因子则采用全球数据(Allstadt et al.,2016,2018)。然而,模型在试运行期间的几次地震预测结果与实际偏差较大,因此目前USGS已经停止了地震诱发滑坡预测结果的实时发布。对比美国地质调查局模型,本文模型采用了最新人工智能算法,其准确率较逻辑回归模型有了大幅度提升。另外,模型考虑了不同的震源机制与区域地质环境条件,使模型能够在区域尺度具有更强的适应性。
本文所研发的模型虽然较现有模型在计算精度和计算效率上有了大幅提升,但仍存在一些误差,误差产生的原因主要包括以下几个方面:
(1)地震参数的不确定性:目前模型采用的地震参数,除了发震断层、震源机制等因素外,主要为可以快速获取的地面峰值加速度PGA参数,而其目前尚不能充分考虑地形、地质条件等放大效应影响。另外,地震诱发滑坡,特别是逆冲断层,还具有显著的上下盘效应,需在未来模型改进中给予更充分的考虑。
(2)局地地质和地形条件的不确定性:坡体结构是决定局部滑坡发生的重要因素,然而其具有明显的局地特征,很难获取大范围实际测量数据,并概化为模型输入参数。现有所有区域尺度的易发性评价模型,均采用岩性表征地质条件,而无法考虑岩体结构与坡体结构的不利组合,因此会产生一定误差。此外,地形数据精度也在一定程度上影响模型预测结果。大范围高精度的地形数据一方面难获取,另一方面会影响计算效率。因此本模型兼顾这两个因素,采用全球可获取的免费30m精度的DEM数据,提取相关地形因子。
(3)历史地震影响及地震诱发滑坡数据不完整性:针对同一区域的高频率地震,例如龙门山断裂带在过去十余年经历了多次中强地震,其对坡体可能产生的累积损伤、震裂山体及恢复机制,仍需要进一步研究,以更好地预测下一次强震诱发滑坡的可能分布范围。此外,随着全球地震诱发滑坡灾害数据库的不断完善,本文模型具有自主学习能力,将随着数据更新,不断提升预测精度。值得指出的是,通过本次芦山地震对比,证明了基于多次地震事件建立的预测模型准确率高于仅基于2013年芦山地震滑坡数据建立的模型。
6 结 论
