基于Python的电商网站服装数据的爬取与分析
2022-08-02陈广智刘伴晨曾天佑魏欣欣
陈广智,曾 霖,刘伴晨,曾天佑,魏欣欣
(1.郑州航空工业管理学院 智能工程学院,河南 郑州 450046; 2.贺州学院 人工智能学院,广西 贺州 542899)
0 引 言
随着电子商务的快速发展,电商网站迅速增加,随之而来网络购物成为趋势。网络购物带给商家和消费者的一个挑战是信息过载问题。面对电商网站上的大量数据,商家和消费者会迷茫,不能做出理性选择。为解决此问题,网络爬取(web crawling)[1-2],又称为数据自动采集,被提出来并得到迅速发展。因发布在电商网站上的数据被认为是公开的,所以对其上大量网页信息的爬取是允许的[3]。此外,中国的纺织服装产业消费市场非常大[4]。因此,该文主要聚集于电商网站上服装数据的爬取与分析。
服装,尤其女装,是一个巨大的产业。电商网站,比如京东、亚马逊等,其上的服装销售数据真实反映了服装消费趋势。对电商网站上的服装数据进行爬取和分析,对商家来说,有利于他们根据分析出的消费趋势更精准地投放产品;对消费者来说,有利于节省他们大量的网上商品浏览时间,快速地得到当前消费热点,其中的价格分析也有利于他们更理性地消费。
有的工作[5]提供了服装图片数据集,以便于对服装图片数据的分析研究[6]。但这些图片数据不具时效性。利用爬取技术能随时获取当前最新服装数据,便于及时发现和挖掘当前服装流行趋势和销售热点,具有较强的时效性。该文爬取的服装商品数据包括商品的描述、价格及图片等信息,与此相对应,对服装数据的分析包括描述的文本分析、价格分析及图片分析。
1 相关工作
该文不仅涉及到网络爬取,还涉及到数据的分析,因此,本节将介绍网络爬取、数据分析的背景信息。
1.1 网络爬取
网络爬取,也被称为网络采集(web harvesting)、网络数据抽取(web data extraction)或网络数据挖掘(web data mining),指的是对一个智能体(agent)的构造,该智能体能以自动化的方式从网络上下载、解析和组织数据[7]。网络爬取已广泛应用在多个领域,包括社会科学[8]、医疗健康[9-10]、电子商务[11]、农业市场[12]、司法[13]、教育[3,14]和公共交通[15]等。
万维网(WWW)提供了不同格式、不同来源的大量信息。在很多情况下,它往往是唯一的信息来源。然而,从网络上提取信息是非常困难的,其中一个主要难点是如何自动检测出感兴趣的对象,并将它们以统一的格式保存在数据库中[16]。该文对服装数据的爬取是采用人工方法确定待爬取的服装信息HTML标签(tag)定位,然后将这些定位信息(解析规则)写入爬取程序中,即采用的是手工开发爬取器的方法。
若一个网站提供了API(application programming interface),则可用其API直接获取数据。但该方法存在接口提供的数据不是所需、限时限量、收费等缺点。实际上大部分网站不提供API,仅提供公开访问的HTML页面。理论上,利用网站API获取数据的方法不属于网络爬取。可用多种不同的语言,例如,C/C++、PHP、Python、Node.js、R或Java,直接访问并获取网站的HTML代码。
1.2 t-SNE算法
t分布随机邻域嵌入算法(t-distributed stochastic neighbor embedding,t-SNE)[17]是Maaten等人于2008年根据SNE算法进行改进而提出的新算法。它将高维数据映射到二维或三维空间从而可视化高维数据,因此,可用于对数据降维和可视化[18]。
t-SNE算法是用高斯核函数计算高维联合概率,得到高维相似度距离,通过t-分布核函数定义低维空间内嵌入样本的相似度,并用梯度下降法进行KL散度(Kullback-Leibler divergence)的寻优计算,从而找到原高维空间和嵌入低维空间内尽可能相近的联合概率分布[19]。
该文采用t-SNE算法对爬取的服装图片数据进行聚类并可视化。
2 服装数据的爬取
2.1 爬取方法设计
利用网页浏览器对一些电商网站上的服装数据进行人工分析,可知:要得到服装数据,需在搜索文本框中输入搜索关键词;返回的页面结果通常是分页显示的服装商品列表。例如,在京东网站上的搜索文本框中输入关键词“连衣裙女装新品”,则返回的页面如图1所示。

图1 京东网站搜索案例
为此,设计了针对电商网站服装数据爬取的算法fashionDataScrape(fkw,n),如算法1所示。该算法的输入为搜索关键词fkw及要爬取的页面数量n,其中fkw被限制为服装类的词,如“连衣裙女装新品”、“礼服”、“旗袍”等。有的电商网站,如京东网站,对返回的页面数有限制,其为100;而有的,如淘宝,没在返回页面显式给出页数,但可通过修改URL(uniform resource locator)中的查询字符串(query string)中的查询参数pnum的值,试探出返回的页面数。为统一处理上述情况,将爬取的页面数n作为算法的输入,由用户爬取数据时提供。由图1可知,搜索返回页面中,每个服装商品包含图片、价格、描述、评价、所属商店、是否折扣等信息。为简化分析和讨论,该算法仅抓取服装商品的图片、描述、价格等信息。因此,算法的输出中,列表resList元素中含商品描述(desc)、价格(price)、图片网址(url)和id(用图片名称代替),图片集合images包含所有对应于resList中url的图片。该算法是基于关键词的爬取算法,是聚焦爬取方法(focused crawler)[20]的一种。
算法1:服装数据爬取算法fashionDataScrape(fkw,n)
输入:服装关键词fkw;爬取的页面数量n
输出:列表resList,其中元素为(id, desc, price, url);与resList中url对应的服装图片数据集合images
1 fori←1 tondo
2 访问与fkw对应的第i个页面page(fkw,i);
3 解析page(fkw,i),找出其含的服装商品数量m;
4 forj←1 tomdo
5 抓取页面page(fkw,i) 中第j个商品信息(idj, descj, pricej, urlj) ;
6 将(idj, descj, pricej, urlj)添加到列表resList中;
7 end
8 end
9 for (idj, descj, pricej, urlj) ∈resList do
10 下载与urlj对应的服装图片imagej;
11 将图片imagej添加到集合images中
12 end
13 return reslist,images
算法中,page(fkw,i)指的是查询关键词fkw返回的第i个HTML页面。该算法分为2部分,第1部分对应算法1-8行,依次访问每个页面page(fkw,i)(i≤n),提取出其中的所有服装商品信息并将它们加入到列表resList中;第2部分对应算法9-12行,从列表resList中逐个读出每个服装商品的图片URL,然后下载该图片,并将其添加到图片集合images中。
为以模块化的方式实现该算法,设计了一个详细类图,如图2所示。

图2 算法fashionDataScrape(fkw,n)的详细设计类图
2.2 爬取实现分析
本节将分析如何用Python语言[1]实现上述算法,并给出关键代码。由于不同的电商网站所用关于服装信息的HTML代码可能不同,所以该算法实现仅以京东网站为例,具体基础网址为https://search.jd.com/Search。选择京东网站的原因是,其具备一定的反恶意爬取措施,且每次搜索能保证返回6 000个服装商品信息,而淘宝则不能做到这一点。对于国外的服装类电商网站,比如Zalando,同理。
2.2.1 实现所用的Python库(Library)
实现该算法时需用一些Python第三方库,其中主要的库如下:
●Requests库。用于向网站发送HTTP请求,以获取网页HTML代码。获取的原始HTML代码可用于进一步解析。该库还便于伪装浏览器、设置请求参数等,是一个简洁、易用、非常人性化的库。该文所用版本为2.24.0。
●Beautiful Soup库。用于从HTML或XML代码中抽取有用的信息。它提供了易用的接口用于查找、定位HTML元素。在命令行中可用“pip install beautifulsoup4”安装该库。该文所用版本为4.9.1。
实现代码中还用到了urllib.parse、random、time、xlwt及pandas等库,在此不再介绍。此外,该文采用lxml作为HTML解析器。
2.2.2 关键代码介绍
类FashionSpider负责某个页面page(fkw,i)的服装信息爬取。因京东网站采用判别浏览器头的反爬取技术,需设置requests的“User-Agent”以进行浏览器伪装。同时,还需设定URL中查询字符串中的参数,以方便传入用户的服装搜索关键词。这些参数名称可通过观察京东网站查询网址的变动规律得到。该类的构造函数代码如下:
class FashionSpider:
def __init__(self, searchStr, n=0):
self.url = 'https://search.jd.com/Search'
self.myParams = {"keyword":searchStr,
"qrst":"1",
"zx":"1",
"page":str(n),
"click":"0"}
self.myHeaders = {
"Host":"search.jd.com",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/84.0.4147.135 Safari/537.36"}
self.result = [] # 用于保存本页面的爬取结果
其中,函数参数searchStr为查询关键词,n代表第n个页面。函数体内self.myParams是一些页面查询参数设置,相关值根据京东网站查询网址的变动规律而得。
抓取某个服装商品的ID(用图片名称代替)、价格、描述和图片网址,需手工确定这些信息的HTML元素定位,以便于用Beautiful Soup书写解析代码。确定HTML元素定位的一个简便方法是利用Chrome浏览器的开发者工具,在页面某个服装商品上右击,然后在出现的快捷菜单上单击“检查”,即可调出HTML元素定位。由此,类FashionSpider中负责对某个服装商品信息解析抓取的方法fetchImgInfo的代码为:
def fetchImgInfo(self, liText):
divImag = liText.find("div",class_="p-img").find("a").find("img")
imgSrc = divImag["data-lazy-img"]
imgSrc = imgSrc.strip()
imgUrl = "https:" + imgSrc
imgID = urlparse(imgUrl).path.split('/')[-1]
imgID = imgID[:-4]
price = liText.find("div", class_="p-price").find("i").string
priceStr = str(price)
desc = liText.find("div", class_="p-name").a.get_text()
desc = desc.strip()
return (imgID, desc, priceStr, imgUrl)
其中,函数参数liText为某个服装商品的HTML代码。
类FashionSpider还需一个函数,用于抓取该页面所有服装商品的信息,它需调用函数fetchImgInfo。其代码如下:
def fetchImgsInfo(self, bs):
divGoodList = bs.find('div',id="J_goodsList")
ul = divGoodList.find("ul")
lis = ul.find_all('li',recursive=False)
for i, li in enumerate(lis):
res =self.fetchImgInfo(li)
self.result.append(res)
其中,函数参数bs为Beautiful Soup对象。
类FashionCrawler负责对多个页面服装商品信息的抓取,其用到了类FashionSpider,代码如下:
class FashionCrawler:
def __init__(self, searchStr, n=3):
self.fSpiders = []
for i in range(1, n+1):
self.fSpiders.append(FashionSpider(searchStr, i))
self.result = [] # 用于存放所有页面的爬取结果
def startCrawling(self):
for i, fs in enumerate(self.fSpiders):
print(' Crawl Page: ' + str(i))
time.sleep(random.randint(15,25)) #不要抓那么快
fs.scrapeImgPage()
self.result.extend(fs.result)
print("page:" + str(i) + " Finish")
其中,__init__函数参数searchStr为查询关键词,n为页面总数。
2.3 爬取结果
为验证爬取算法fashionDataScrape的有效性,利用上述实现算法的程序,以“连衣裙女装新品”为搜索关键词,同时设置n=50(由于每个页面30条商品数据,故爬取了1 500条商品数据),爬取到的服装商品信息如表1所示。由于爬取到的服装商品信息较多,为节省空间,表1仅给出了2条服装商品的信息。其中,id、desc、price和url的含义请参见前述列表resList元素的讲解。
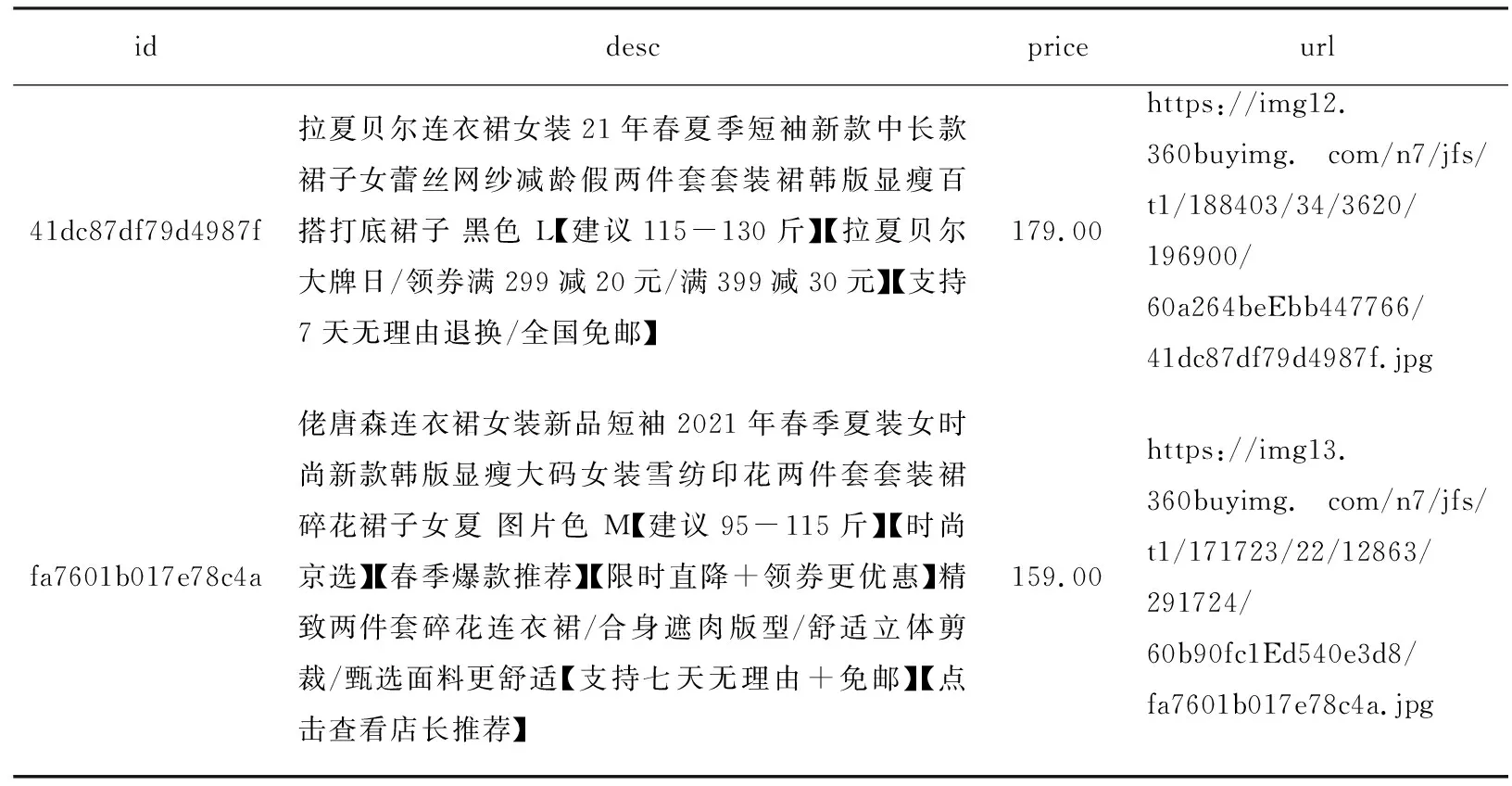
表1 以“连衣裙女装新品”为关键词爬取到的服装信息(部分)
与上述爬取到的服装商品信息相对应的爬取到的服装图片信息如图3所示。根据这些爬取结果,结合手工对相关页面验证,可知,提出的爬取算法fashionDataScrape是可行的和有效的。

图3 以“连衣裙女装新品”为关键词爬取到的服装商品图片信息(部分)
3 服装数据的分析
本节将分析抓取到的服装数据,所分析的数据为:以“连衣裙女装新品”、“女装t恤”和“旗袍年轻版”为关键词分别抓取到的1 500条服装商品数据,抓取时间2021年6月14日。
3.1 描述数据分析
以关键词“连衣裙女装新品”的1 500条服装商品数据为例,对这些商品的描述信息词云进行分析。首先需对这些描述文本进行预处理,包括:去除重复描述;去除折扣、优惠信息;去除退换、免邮信息等,仅保留品牌描述相关信息。然后,利用Python的jieba库对描述文本分词。分词时,去除了一些停用词,这些词对商品的品牌分析关系不大,例如,“的”、“下单”和“请”等。分词时发现,jieba库不能对服装专业品牌词进行很好地分词。因此,自定义了一个服装品牌词典,并将其导入到jieba库中。该词典共包含101个词,其中绝大部分为服装品牌专有词,例如,“拉夏贝尔”、“莱倪晟纳”等。最后,得到的这1 500条服装商品描述的词云如图4所示。从图中可看出女装连衣裙的一些流行趋势:中长款、短袖、韩版的居多,M、L号的比较多,品牌以“拉夏贝尔”、“莱倪晟纳”的居多等。

图4 以“连衣裙女装新品”为关键词爬取到的1 500条服装商品描述信息词云
对于以“女装t恤”、“旗袍年轻版”为关键词抓取的各自1 500条服装商品描述信息,可采用上述类似方法进行词云分析。
3.2 价格数据分析
对以“连衣裙女装新品”、“女装t恤”和“旗袍年轻版”为关键词抓取的各自1 500条服装商品价格信息,绘制了它们的箱线图(Boxplot),如图5所示,以对比分析这三类商品的价格趋势。从图中可看出,大部分“女装t恤”(75%)的价格低于“连衣裙女装新品”,而“连衣裙女装新品”又低于“旗袍年轻版”;“旗袍年轻版”高端价位(异常值)的商品数量最多,“连衣裙女装新品”次之,而“女装t恤”的则最少;但是,三者最低价位中,“连衣裙女装新品”为最高。

图5 以三种不同关键词爬取得到的各自1 500条商品价格的趋势对比
3.3 图片可视化分析
为展示t-SNE算法对爬取到的服装图片数据的聚类、可视化效果,从上述爬取到的三类关键词服装图片中分别随机选取250张,得到含有“连衣裙”、“女装t恤”和“旗袍”的共750张图片,对这750张混杂类别的图片进行t-SNE聚类、可视化分析,结果如图6所示。

图6 对含有“连衣裙”、“女装t恤”和“旗袍”的750张图片的t-SNE可视化结果
图中每个图片的坐标对应各自的t-SNE位置。从图6可看出,t-SNE算法依据色彩的饱和度、强度聚类,并将服装图片放置于图6中的相应坐标位置;但是,它没有按服装款式聚类。上述t-SNE聚类为根据服装色彩对顾客进行服装商品推荐奠定了基础。
4 结束语
为及时准确地获取当前服装产品的流行趋势、消费热点,提出了针对电商网站服装数据爬取的算法fashionDataScrape。为提高爬取的灵活性,该算法首先爬取服装商品的描述、价格及图片网址等文字信息;然后,再利用前述图片网址爬取相应的服装图片信息,做到了文字信息和图片信息爬取的相分离。为验证算法的可行性和有效性,用Python语言实现了该算法,其中主要用到的库为Requests和Beautiful Soup。利用该算法实现,以“连衣裙女装新品”、“女装t恤”和“旗袍年轻版”为关键词,共爬取了京东网站上4 500条服装商品信息,包括图片信息。针对这些爬取结果,分别对它们进行了商品描述分析、价格分析和图片的t-SNE聚类可视化分析。从对服装数据的分析结果来看,进一步验证了电商网站服装数据爬取的意义。
