基于XLNet-BiGRU-Attention的行业分类方法
2022-08-02佘祥荣陈健鹏
陈 钢,佘祥荣,陈健鹏
(长三角信息智能创新研究院,安徽 芜湖 241000)
0 引 言
行业分类对于国民经济统计、市场监督管理等领域具有重要作用。企业所属行业通常从其经营范围描述来推断,但经营范围往往涉及到多个行业的描述,人工对行业分类存在效率低下、可靠性不高等问题。基于神经网络的方法通常使用卷积神经网络(CNN)[1]、循环神经网络(RNN)[2]、长短期记忆循环神经网络(LSTM)[3]自动完成经营范围文本特征提取和行业分类任务。相比行业门类,属于不同行业小类的企业在经营范围描述上存在很多相似性,利用神经网络方法很难发现这种微小的差异,较难做出正确的判断。
Word2vec、glove等经典词向量模型可以通过将自然语言中的词转换为稠密的词向量,从大量的未标记语料中学习文本的语义信息,但却无法处理自然语言文本当中一词多义的情况[4]。随着迁移学习的广泛应用,Bert[5]成功用于大规模未标记数据的语言表示学习领域。虽然Bert可以有效抓取文本的上下文语义信息,但它没有考虑到在训练过程中屏蔽的单词与未屏蔽的单词之间的关系。广义自回归语言模型XLNet[6]避免了BERT的缺点,它利用排列组合的原理实现了新的双向编码,具备强大的语义表征能力。双向门控循环单元(BiGRU)适合对文本建模、获取文本全局的结构信息。注意力机制(Attention)可以对经营范围中重要的词赋予更高的权重,可以更好地提取关键信息。
为克服基于机器学习和基于神经网络的行业分类方法的缺点,该文提出一种基于XLNet-BiGRU-Attention的行业分类方法。该方法通过XLNet网络从经营范围文本中获取具有上下文特征信息的语义表征向量,构建基于BiGRU和Attention的候选集生成网络来进一步提取上下文相关特征,通过构建键值对嵌入网络来进一步挖掘企业其他标签对于行业分类的提升效果,最后将融合后的特征向量输入到分类器完成企业行业分类。
1 相关工作
文本分类作为自然语言处理的经典任务,主要包括文本预处理、文本特征提取及分类器设计等过程,在情感分析[7]、垃圾邮件识别[8]、阅读理解[9]等多个领域均具有广泛应用。文献[10]提出了一种基于BiGRU和贝叶斯分类器的文本分类方法,利用BiGRU神经网络提取文本特征,通过TF-IDF算法权重赋值,采用贝叶斯分类器判别分类,缩短了模型训练时间,提高了文本分类效率。文献[11]利用TextRank算法对企业的经营范围进行了关键词提取,得到了企业的经营范围标签,先后尝试了多项朴素贝叶斯分类器、逻辑回归分类器、随机梯度下降这三个分类器对企业行业进行分类。
文献[12]利用Jieba工具对企业经营范围内容进行分词,再采用简单的贝叶斯文本分类模型,以Chi作为特征选择的基础,对经营范围的多维特征进行选择和重新加权,再利用余弦相似度进行计算后完成行业分类。文献[13]提出了一种基于互联网简历大数据的行业分类方法,通过使用从专业社交网络收集的在线简历大数据构建劳动力流动网络,通过分层可扩展的社区检测算法在劳动力流动网络上实现了企业群体的发现。文献[14]提出了一种基于文本挖掘的行业分类方法,结合机器学习技术从财务报告中的业务描述中提取不同特征,该方法在对相似企业进行行业分类时可以有效减少词向量的维数。
文献[15]在微软语料库MPRC上从影响计算特性的各因素出发比较了Bert和XLNet的性能,研究表明这两种模型除了对目标位置的感知表示和XLNet在相对位置具有特性编码之外,其他计算特性非常相似,但XLNet能够获得更好的性能。文献[16]通过分析物联网实体的语义特征及需求,构建了基于XLNet+Bi-LSTM+Attention+CRF的命名实体识别模型,并与其他语言模型作对比分析。文献[17]利用显性知识从知识图谱中匹配知识事实,在不改变Transformer结构的前提下直接添加知识命令层,提升了预训练语言模型的性能。文献[18]在XLNet基础上增加LSTM网络层和Attention机制,提出了XLNet-LSTM-Att情感分析优化模型。采用XLNet预训练模型学习到的词向量比以往模型获得更多的上下文语义信息,将XLNet预训练模型的潜力充分挖掘成为研究人员目前的新工作[19]。
2 模型结构
XLNet在语言表义方面具有较好的优势,可以更好地实现中文词的语义嵌入,BiGRU可以有效获取上下文依赖关系和文本特征,而Attention机制可以凸显特征对最终分类任务的重要程度,从而提高模型的准确率和效率。基于此,该文提出的行业分类模型主要由XLNet网络、候选集生成网络和键值对嵌入网络构成,如图1所示。
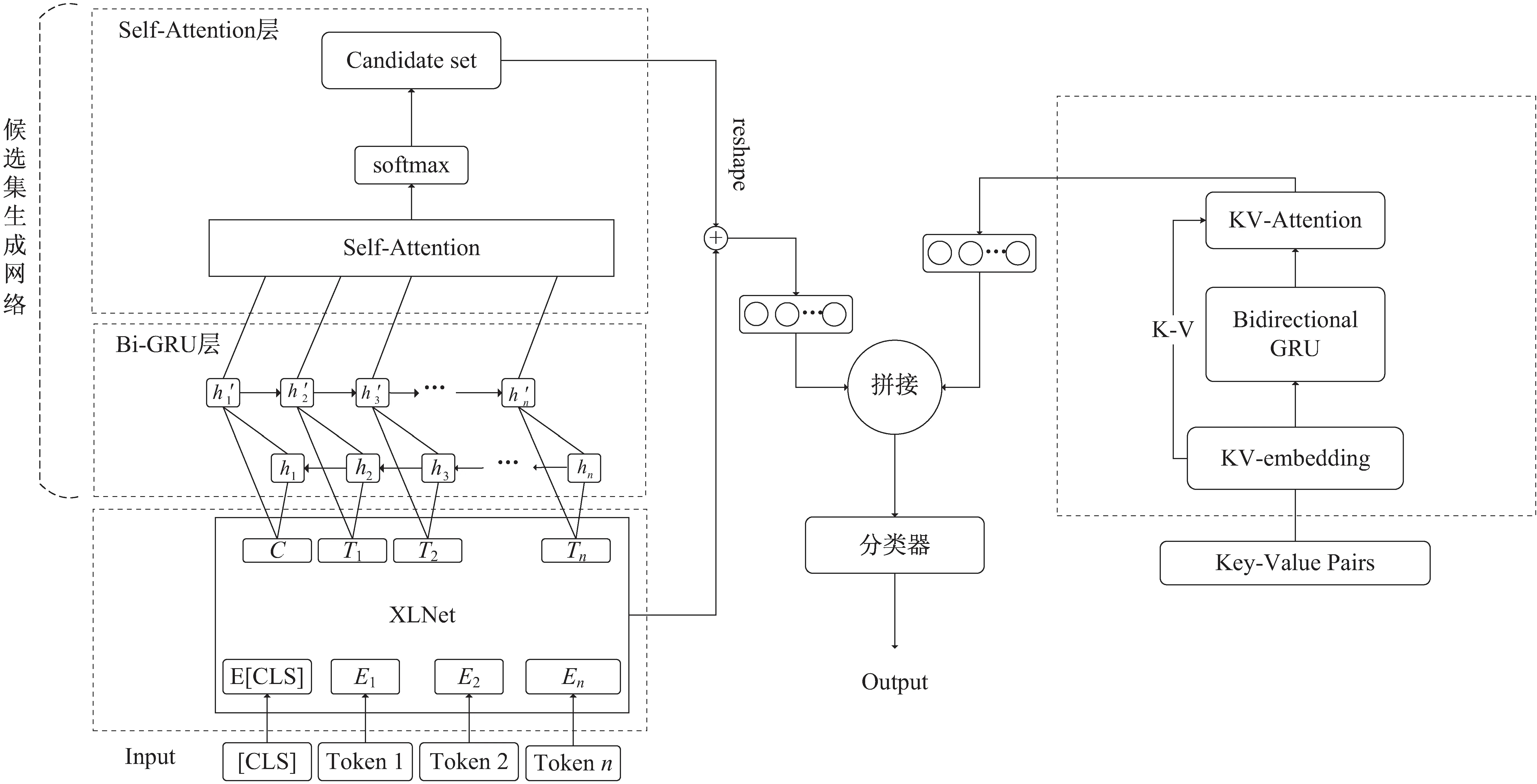
图1 XLNet-BiGRU-Attention模型结构
XLNet网络对输入的企业经营范围文本进行语义信息提取,获得具有上下文特征信息的语义表征向量。候选集生成网络中的BiGRU层对语义表征向量进行进一步筛选,补充遗忘信息并生成隐藏状态提供给Self-Attention层。候选集生成网络中的Self-Attention层对BiGRU层输出的隐藏状态进行处理,凸显重要性高的语义特征,并结合softmax函数生成行业分类候选集。键值对嵌入网络对企业信息进行处理,使模型更关注对行业分类贡献度高的特征,以提高最终行业分类的准确率。
2.1 XLNet网络
XLNet的核心思想是在Transformer中通过Attention Mask矩阵对输入序列重排列,通过学习不同排序的序列特征信息实现其双向预测的目标,同时不会改变原始词顺序,有效优化了Bert中Mask机制下的信息缺失问题。

2.2 候选集生成网络
2.2.1 BiGRU层
GRU是一种特殊的循环神经网络模型,该网络模型类似于LSTM模型,可以解决梯度消失和梯度爆炸的问题。GRU由重置门和更新门两个门结构构成,如图2所示。

图2 GRU单元结构
各个门控单元计算公式如下:
(1)重置门rj控制过去状态信息对候选状态的贡献度:
(1)
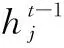
(2)更新门zj控制保留多少过去的信息和添加多少新信息:
(2)
(3)
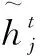
(4)
当重置门rj趋于0时,隐藏状态会强行忽略前一步隐藏状态,仅使用当前的输入进行重置。这有效地实现了隐藏状态丢弃任何将来不相关的信息。更新门控制有多少信息将从以前的隐藏状态转移到当前的隐藏状态。
在单向的GRU网络结构中,状态是从前往后输出的,仅能获取文本前文信息,难以获取整个文本的上下文信息。然而在文本分类中,当前时刻的输出可能与前一时刻的状态和后一时刻的状态都存在相关性。双向门控循环单元可以有效获取文本的上下文信息,为此使用BiGRU网络作为信息提取网络,为输出层提供输入序列中每一个点的完整上下文信息。BiGRU结构如图3所示。
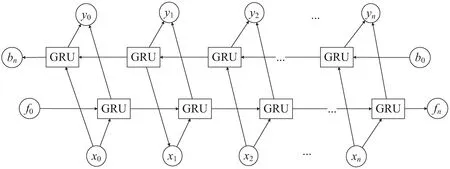
图3 BiGRU结构
双向GRU由两个方向的多个GRU单元组成,分为前向GRU和反向GRU。前向GRU能依据文本的上文信息来预测下文的输出,而反向GRU则可以依据文本的下文信息来预测上文的输出,从而实现文本上下文信息提取。
2.2.2 Self-Attention层
注意力机制通过将关注点聚集在焦点区域,从而获得输入文本的关键信息。自注意力机制是注意力机制的一种变体,利用注意力机制计算输入特征中不同位置之间的权重,降低了对外部信息的依赖。同时,借由注意力机制对关键信息的跳跃捕捉,提高关键信息的传递效率,使得自注意力机制更擅长捕捉数据或特征的内部相关性。在企业经营范围描述信息中,对于企业行业分类任务价值较高信息往往集中于部分关键词上,因此引入自注意力机制对企业经营范围信息中的关键内容进行提取。
在计算Self-Attention的过程中,对输入的每一个部分进行编码后形成语义编码Iembedding,通过建立参数矩阵WQ、WK和WV,将语义编码线性映射到特征空间中,形成Q、K、V三个向量:
Q=WQ*Iembedding
(5)
K=WK*Iembedding
(6)
V=WV*Iembedding
(7)
之后针对Query和Key进行相似度计算,得到计算注意力权重,并对得到的权值进行归一化操作,最后将权重与Value进行加权求和得到最终的注意力得分Vout,整体机制实现如图4所示。
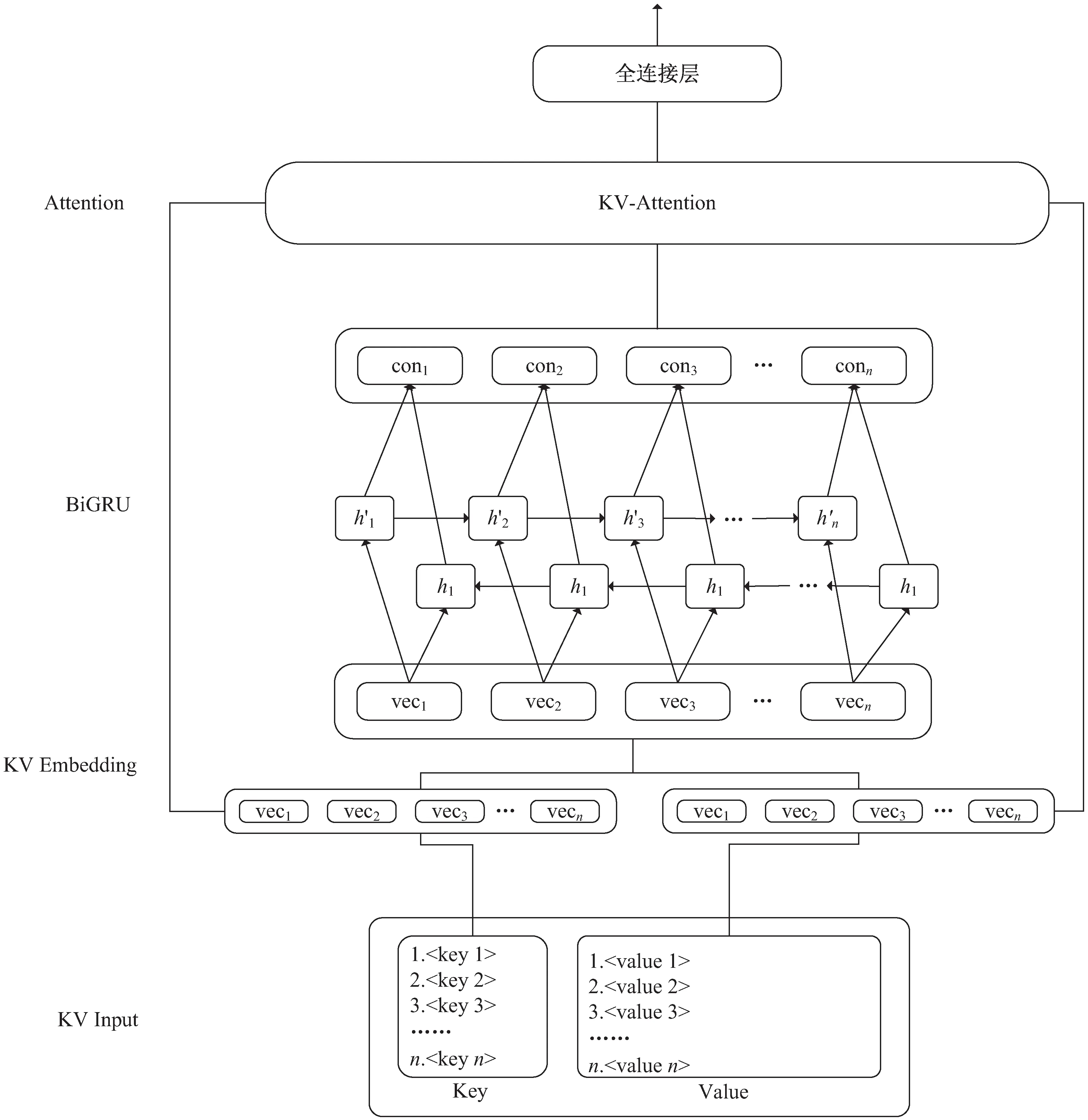
图4 键值对嵌入网络

(8)
(9)
2.3 键值对嵌入网络
除了经营范围描述外,企业还包含大量其他相关性的标签,单纯利用某一类标签,可能存在难以理解某些模糊描述的情况,理解层次偏低。因此在完成候选集生成后,该文通过BiGRU网络结合KV-Attention层构建了一个基于企业其他标签(企业名称、行政许可、知识产权、招聘信息、招投标信息等)的键值对嵌入网络来提高分类模型的理解层次。企业其他标签处理成如下键值对(key-value)列表形式:
L=[(s1,v1),(s2,v2),…,(sn,vn)]
其中,si表示企业标签名称(例如企业名称),vi表示对应企业标签的具体内容(例如安徽XXX公司)。键值对嵌入网络结构如图4所示。
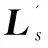
(10)

(11)

(12)
(13)
2.4 行业类别预测
(14)
p=softmax(WVconcat+b)
(15)
其中,W、b是可学习参数,p是各类别的分类预测概率。
使用正确类别的负对数似然作为训练损失函数:
(16)
其中,j是企业E的分类类别。
3 实验结果与分析
3.1 实验环境与参数设置
该文使用基于CUDA 9.0的深度学习框架PyTorch 1.1.0搭建网络模型,操作系统为Ubuntu 18.04,硬盘为1 TB,内存为32 GB,CPU为Intel(R)Core(TM)i7-7700CPU@3.60 GHz,GPU为GeForce GTX 1080 Ti。
在超参数的设置上,XLNet语言模型的嵌入维度为768维,多头注意力机制的设置为12个注意力头,隐藏层维度同样设置为768维,隐藏层层数设置为12,GRU的隐藏层维度设置为128。在训练设置上,批处理大小设置为16,批处理以token为单位,每个输入文本的token个数设置为200。同时,模型使用学习率为1e-5的Adam优化器。训练轮数设置为10轮(epoch=10)。
3.2 数据集
根据2017版《国民经济行业分类》标准规定,国民经济行业分类共有20个门类和1 380个小类。为了评估该行业分类方法的有效性,构建了两个由企业数据组成的数据集。数据集1包含60 000条数据(10个门类,100个小类,训练集50 000条,验证集5 000条、测试集5 000条),数据集2包含80 000条数据(20个门类,200个小类,训练集64 000条,验证集8 000条、测试集8 000条)。每条数据包括企业名称、注册资本、成立时间、经营范围、行业类别、行政许可、产品信息、专利信息、软件著作权信息、招聘信息等维度。
3.3 基线方法对比
该文采用微平均F1值和宏平均F1值作为行业分类性能评价指标。为了验证文中分类方法的性能,与多种基线方法进行了对比。在基线方法中,文献[11]、文献[12]和文献[14]使用textRank、TF-IDF等作为文本特征提取方法,并使用多项朴素贝叶斯、支持向量机等传统机器学习方法作为分类器对行业进行分类。文献[1]、文献[2]和文献[20]使用神经网络方法对文本进行分类。文献[1]使用卷积核窗口大小分别为2、3、4的3个卷积层和相应的池化层提取特征并进行拼接,以此来获得更丰富、不同粒度的特征信息。文献[2]使用经过词嵌入之后的词向量作为输入并经过RNN网络和池化层完成文本分类。文献[20]使用基于单词层面注意力机制的BiGRU模型和基于句子层面注意力机制的BiGRU模型提取文本多层面的特征进行文本分类。实验对比结果如图5和图6所示。

图5 数据集1上基线方法分类对比结果

图6 数据集2上基线方法分类对比结果
可见,文中的行业分类方法在两个数据集上均取得了比其他基线方法更好的分类效果。基于神经网络的方法在分类效果上明显优于传统机器学习的方法,因为机器学习方法仅简单的对文本中的词向量进行加权平均,没有使用文本更深层次的语义信息,而CNN和RNN可以获取更深层次的语义信息从而得到更好的分类效果。然而,CNN无法获取文本的上下文信息,RNN不能很好提取句子的局部特征,XLNet能有效提取文本的语义信息和上下文信息,因此其分类效果高于CNN和RNN方法。可以看出,文中行业分类方法在XLNet的基础上增加了候选集生成网络和键值对嵌入网络,有效提升了行业分类的性能。
3.4 消融实验
3.4.1 候选集生成网络有效性
为说明候选集生成网络的有效性,定量比较了是否使用候选集生成网络的实验结果(将未使用候选集生成网络的模型命名为XLNetwithoutCGN),对比结果如表1所示。可见,XLNet-BiGRU-Attention在两个数据集上的行业分类效果都优于XLNetwithoutCGN。

表1 候选集生成网络消融实验结果 %
3.4.2 键值对嵌入网络有效性
为说明键值对嵌入网络的有效性,定量比较了是否使用键值对嵌入网络的实验结果(将未使用键值对嵌入网络的模型命名为XLNetwithoutKVE),对比结果如表2所示。可见,XLNet-BiGRU-Attention在两个数据集上的行业分类效果都优于XLNetwithoutKVE。

表2 键值对嵌入网络消融实验结果 %
3.5 分类准确率比较
从图7可以看出,提出的行业分类方法的分类准确率优于其他分类方法。

图7 不同方法在部分类别上的分类准确性比较
4 结束语
提出了一种基于XLNet-BiGRU-Attention企业行业分类方法。该方法将企业经营范围文本信息输入到XLnet网络生成语义表征向量,通过基于BiGRU和Attention的候选集生成网络来有效获取上下文依赖关系和文本特征,并构建基于企业其他标签的键值对嵌入网络来进一步提升行业分类的效果,将键值对向量和语义表征向量进行拼接得到融合的特征向量输入到分类器,最终完成企业行业预测。实验结果表明该方法相较于其他几种基线方法都取得了更好的行业分类效果,消融实验说明了该方法所构建的候选集生成网络和键值对嵌入网络的有效性。
