面向社会评价的人才培养质量评估
——基于社交文本数据
2022-08-01黄振宇字汝倩林嘉鸿邹苇婷
■黄振宇,陈 哲,字汝倩,林嘉鸿,邹苇婷
(湛江科技学院,广东 湛江 524000)
一、前言
随着我国国际化进程逐渐加快,各行业人才市场需求不断加大。各大高校为了提高办学效率和教学质量,都在开展教育改革,从而为人才培养提供有效保障,因此,开展高等教育人才培养质量的评估成为了教学质量管理工作的关键环节[1]。“互联网+”教育以及教育大数据分析可以为教学工作提供决策支持[2]。本研究以广东省高校人才培养质量社交文本数据为基础,利用情感词典和卷积神经网络算法展开分析,从而获取社交网络平台对于广东省高教人才培养质量的态度和建议。
当前我国关于高校人才培养质量的研究,大多集中在学校专业建设、教师团队建设以及学生培养方式等高校人才培养环节上[3],研究手段主要是采用理论分析[4]、国内外经验借鉴,在此基础上进行人才培养质量评估体系的优化[5],少有依据培养质量效果的反馈对人才培养方案做持续改进;研究中所选用的数据来源基本上是通过问卷调查[6]、专家访谈等渠道,而这些数据带有较大的主观误差,难以为研究提供精准的实证支撑。所以,当前采用独立客观数据精准分析的以高校人才培养质量效果为导向评估方式的研究成果较为匮乏。本研究通过对网络资讯、网络社交数据的无差异采集分析,进行海量大数据文本统计分析,引入基于双向循环注意力神经网络模型解决文本中的高频词和情感关键词之间的关联问题,并融合注意力模型分配给领域关键词更高的权重,最终进一步完善对高校人才培养质量评估系统的改进。
本研究获得的数据均是来自网络上社会对广东省省属高校的客观意见,但是在研究方法和手段上是国内首次将大数据文本挖掘和神经网络算法分析运用在高等教育领域的研究中。
二、研究方法与设计
文章运用网络文本内容分析法与对比研究法。内容分析法是对文献内容进行高效率、去主观化、量化分析的一种研究方法[7]。这种方法的优势是去中心、去系统的文本,将离散的互动交流式的信息转化为系统、量化的数据[8]。本研究使用python爬虫程序获得社交文本数据,利用情感词典和神经网络算法(通过github获取的开源代码)对文本施行分词分句后进行情感判断,得出文本计量,最后建立人才培养质量评估体系对数据进行分析评价。
本研究整体上分为四个步骤:第一阶段是对研究的学术环境进行分析,对高校人才培养质量评估的创新需求进行整理,对文本分析关键技术运用评估;第二阶段是分别进行实验设计、数据集获取、文本的预处理;第三阶段是对文本进行挖掘工作,关键点在于使用情感词典+卷积神经网络算法对文本的情感进行分析,使用stata分析数据的相关性;第四阶段是将分析的结果进行讨论和思考。实验设计思路如图1所示。

图1 实验计划思路
本研究的数据来源主要两处:一处是社交文本数据,来自中国较大的社交平台:百度贴吧;另一处是广东省教育厅在“创新强校”项目中对广东省48所省属本科高校的人才培养质量评估的数据。
本研究计划通过该实验回答以下几个问题:
通过社交媒体获取的文本,是否能较为全面地展示高等教育的人才培养质量?
使用社交媒体的文本对高校人才培养质量进行评估的结果和主管部门提供的评估结果有什么不同?
三、数据采集与数据处理
(一)社交网络文本的获取
在文本分析任务中,往往需要使用大量的文本数据集来完成算法的训练,从而提高算法性能。百度贴吧是百度旗下独立品牌、全球领先的中文社区,该社区有效地使用特定的关键词将感兴趣的网络用户聚集在一起,这为捕捉广东省不同高校学生的社交文本提供了极大便利。在数据爬取过程中,利用chromedriver软件来模拟用户登录,采集贴吧文本数据。百度贴吧采集数据的流程如图2所示。
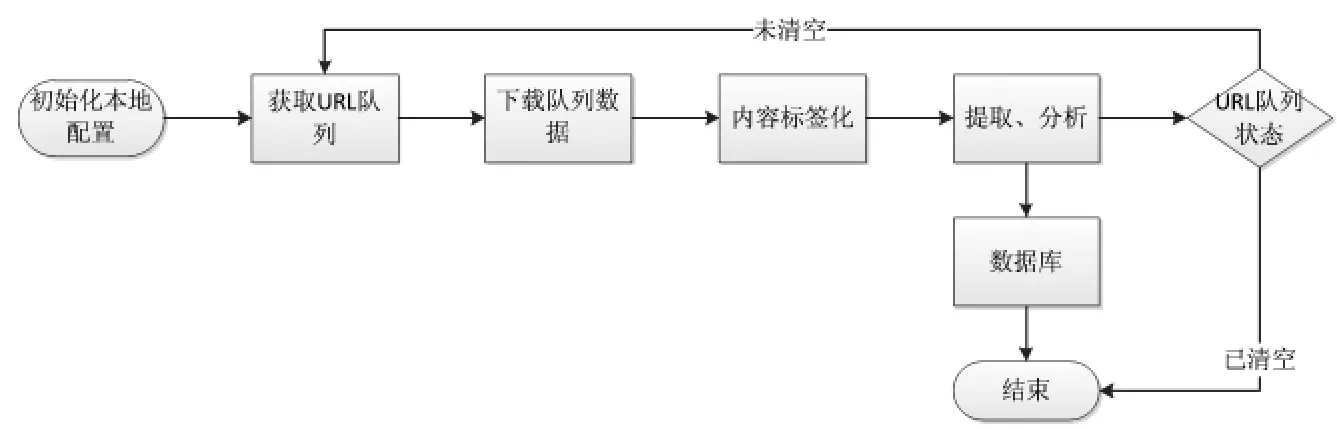
图2 百度贴吧文本抓取流程图
在获得数据后,我们对数据进行初步处理:爬虫所获取的文本就算通过解析之后,可能仍然包含许多网页格式自带的标签,这些无用的标签不仅对于文本内容分析不起作用,还会干扰正常文本分析工作,去除程度越高,越有利于文本分析工作的进行。常见方法是匹配正则表达式,筛选网页数据中的网页标签。此外,也可使用字符串匹配的方式去除相对应的网页标签字符,或者使用Word中通配符文本替换的方法进行标签去除。
通过对48所学校(原本是49所学校,但某学校因为政治敏感原因不开放贴吧)社交平台进行抓取,笔者获得了百万级的文本数据(平均每个学校的文本字符数约70 000,总文本字符数约等于3360 000),使用神经网络算法的并行运算,实现了对贴吧每一个文本句子的内容进行情感分析,笔者按照每年广东省教育厅所进行的“创新强校工程”专家考核评审中详细指标拟定了关键词,筛选出对应的文本句子,在使用人工的方法对贴子所标志的情感状态进行收集整理和展示。
(二)高校人才培养质量社会评价指标词典构建
广东省教育厅的高校评价指标体系涵盖了专业和课程建设、教师教学能力、实践教学、人才培养模式改革与成效、质量保障体系建设及成效、学位授予质量六个一级指标,一级指标下面分多个二级指标,如专业和课程建设一级指标下面就有专业及课程建设规划、优质专业和课程建设、校企共建专业多个二级指标。确保立体全面涵盖了高等院校人才培养质量的方方面面,具有科学性和权威性[9]。
本研究通过以下的操作验证问题:笔者在借鉴广东省教育厅的高校评价指标体系(把握控制变量,用于验证问题),进一步构建每类指标的相关指标词典;确保每个指标指向的关键词具有能够代表这一类别指标的特点,同时采用抽样验证的方法,确保关键词能获取到实验中所需的文本内容,若出现文本量不足或者文本情感差异过大的情况,笔者将对关键词进行审核或者替换尝试,各类指标词典如表1所示。

表1 社会评价指标词典(部分)
(三)高校人才培养质量评估数值的相关分析
在构建高教人才培养质量社 会评价指标词典基础上,利用其中的关键词对卡面获取到的300多万文本进行文本内容提取,例如在一级指标“专业和课程建设”中“专业及课程建设规划”下的关键词“课程”,通过其检索出来的文本句子或者句子群(以单个帖子或者回答作为区分标准),进行计算机神经网络算法的打分来实现情感判断。
以下操作主要是为了验证问题:笔者将数值分为三组,第一组是广东省教育厅“创新强校”工作中选取的“人才培养”专项的分值,第二组数据是来自于神经网络算法训练前的情感判断打分(取样10%进行人工训练),第三组数据是来自于神经网络算法训练后的情感判断打分。广东高校社交文本情感分析得分见表2。

表2 广东高校社交文本情感分析得分(部分)
结果显示神经网络算法训练前的结果与广东省教育厅“创新强校”工作中选取的“人才培养”专项分值毫不相关,P值(0.17)大于 0.1。这说明从GitHub上面获得的开源代码和情感词典进行情感判断的误差非常大,如果进行大数据文本分析工作,必须要进行事前的人工训练,实现算法系统的调教。
经过实验人员提交人工判断方法进行训练的神经网络情感算法的打分分值,与广东省教育厅“创新强校”工作中选取的“人才培养”专项分值的回归P值(0.048)低于0.05,说明相关性显著,存在负相关,但不是非常明显。断点回归图如图3所示。
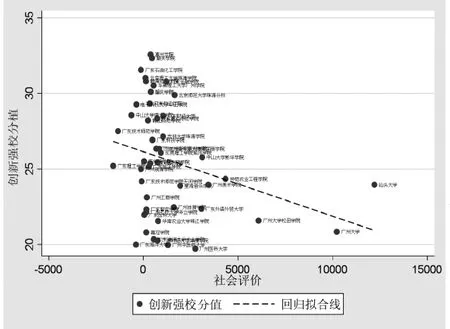
图3 断点回归图
四、结果展示与讨论
通过借鉴和对照广东省教育厅对省属本科高校的评估指标,笔者建立了社会评价指标词典。最后结果显示问题的结论是肯定的;笔者将省教育主管部门的评估分数和社交网络文本的情感分析方法获得的人才培养质量评估分值相对比,显示存在显著负相关,对于这个结果的理解分为两面:一个原因是高校行政主管部门和高校学生自己的观察角度不同,所获得的信息存在较大的误差;另一个原因是高校在按照上级主管部门执行人才培养方案的时候忽略了学生的需求,导致学生产生不满情绪——这个笔者认为是对问题的解答。鉴于此,笔者建议广东省教育厅在高校人才培养质量评估标准的优化过程中,可以对指标作进一步细化,尤其是顾及到高校学生对本校方案实施的满意程度和情感诉求。
五、研究不足与展望
第一,数据获取来源渠道不足,目前按照计划从多个平台上获取文本信息进行分析,但是受限于数据量的要求和文本的质量,绝大多数用于分析的文本来自于百度贴吧,这导致了文本的情感的主体是在校大学生,存在一定偏差,不足以代表社会群体的整体意见。后续的工作是编写更多的社交平台文本抓取程序,增加文本获取的时长,以获得更多的文本数据来进行多维度校正。
第二,文本数据清洗的质量不高,导致了有大量的广告参杂其中,其主要原因是本调研的时间不足,人手有限。后续工作将会开发新的广告清洗算法,使用软件来解决。
第三,关键词设置不合理,本研究使用的关键词是为了能筛选出与评价指标相关的文本信息,但是因为互联网平台上的管理规则,某些主题的贴子将会被管理员删除,所以导致本次设置的一些关键词对应的内容不能被开始的爬虫程序所抓取。未来需要开辟新的思路,寻找社交平台管理更为宽松的平台,以获得更加真实的学生意思表示文本,提高研究质量。
