基于特征融合和注意力机制的目标分割跟踪算法*
2022-08-01王诗言张青松雷国芳张江山
王诗言,张青松,雷国芳,张江山
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
视频中运动目标的跟踪问题是计算机视觉领域的基本问题之一,同时也是计算机视觉领域研究的热点和难点。目标跟踪的基本任务[1-4]是给定第一帧图像中的目标对象的初始状态(位置和尺度)来预测后续视频帧中目标的状态。如何在复杂场景中识别并跟踪不断变化的目标是一项具有挑战性的任务[5]。
近年来,得益于深度学习技术的快速发展,基于深度学习的目标跟踪算法不管是精度还是速度都有了较大的提升,但如何对跟踪的目标进行更为精确的状态估计仍然是一个复杂的任务。早期的目标跟踪算法依靠基于坐标轴对称的矩形框作为标记,但随着跟踪算法精度的不断提升,跟踪数据集的难度也在不断提升。现有算法在实现目标精确的状态估计这一方向上都取得了一定的成果,但它们未能有效利用目标间的长距离依赖关系和深度网络中各个特征层的不同特性(深层网络对大目标敏感,浅层网络对小目标敏感),同时对于分割任务不够精细,以至于无法达到更为精确的目标状态估计。
本文以D3S[5]为基础,针对这三个问题进行优化。首先,针对目标的多尺度的问题,在骨干特征提取网络后设计了一个自适应特征融合模块,可以通过对神经网络的训练来自动地对不同的特征层赋值不同的权重,用于更好地融合不同层级特征,使特征具有多尺度特性。其次,针对目标间的上下文关系的利用,选择在自适应特征融合模块后引入混合域自注意力模块,采用非局部均值(Non-local)的思想[6],分别在空间域和通道域对融合后得到特征层进行Non-local操作,然后进行堆叠。最后,针对分割任务不够精细的问题,在分割模块上面并行增加了一个目标轮廓分割模块,再与分割模块的输出进行相加,用于更精确地分割出目标几何状态。
1 基于特征融合和注意力机制的目标分割跟踪算法
整体框架如图1所示,主要由5个模块组成,分别是自适应特征融合模块(Adaptive Feature Fusion,AFF)、上下文信息聚合模块(Context Information Aggregation Module,CIAM)、定位模块(Location Module,LOC)、分割模块(Segmentation Module,SEG)和轮廓掩膜预测模块(Contour Segmentation Module,CSM)。在跟踪阶段,首先将视频帧序列送入到ResNet-50网络中提取特征,然后将提取后的特征送入到AFF模块中,经过AFF模块将ResNet-50提取出来的Layer 1-4层特征进行融合再与Layer 3特征进行相加输入到CIAM模块中进行上下文语义信息的聚合,使用自注意力机制的思想,在其通道域和空间域进行操作之后分成并行三路分别输入到定位模块、分割模块、轮廓掩膜预测模块,得到目标的位置信息、分割掩码和其轮廓信息,最后经过堆叠和上采样融合输入预测结果。其中定位模块和分割模块都是原本D3S的结构,本文在上面添加了AFF模块、CIAM模块、CSM模块,下面将详细介绍这三个模块。

图1 D3S-AM网络结构图
1.1 AFF模块
为了使网络充分利用到高层特征的语义信息和低层特征的细粒度特性,加强网络对不同尺度目标的跟踪效果,在特征提取网络ResNet-50后面添加一个自适应的特征融合模块,用以融合ResNet-50中的Layer1~Layer4特征,具体做法如图2所示。
如图2所示,图中描述了如何进行特征融合,其中x1→3、x2→3、x3、x4→3分别来自ResNet-50中的Layer1~Layer4的输出特征分别进行上/下采样成Layer3的尺寸,然后将这几个层的特征分别乘以它们的权重参数w1、w2、w3、w4并求和,就可以得到融合后的特征,用y表示。这个过程可以使用公式来表示:
y=w1·x1→3+w2·x2→3+w3·x3+w4·x4→3。
(1)
由于采用相加的运算,所以为了保证不同特征层的特征能够相加,要保证这些特征层输出的尺度和维度都相同,因此使用1×1的卷积分别将这些层的输出特征调整到统一的1 024通道,以便于计算。对于权重参数w1、w2、w3、w4是通过采样成统一尺寸后的Layer1~Layer4特征图经过1×1卷积后得到的,为了降低参数量统一调整到8通道,在输出的最后加了一个Softmax层,使得权重参数的值在[0,1]并且和为1。在网络进行训练的过程中,权重参数w1、w2、w3、w4会根据对应特征层的贡献大小来自动调节权重值,以达到自适应特征融合的需求。
1.2 CIAM模块
引入自注意力机制的思想[7]来构建此模块,分别从通道域和空间域来进行自注意力操作,使得特征通过空间注意力机制来捕获丰富的全局语义信息,同时通过通道注意力机制来选择性地增强相互依赖的通道特征。具体操作如图3所示。

图3 CIAM网络结构图
模块分别关注通道和空间位置两个方面。与预先定义目标分类的检测[8]和分割任务不同,视觉目标跟踪主要困难在于只有初始帧的信息可以利用,在后续跟踪中目标的类别并不固定,而在卷积神经网络中,每一个通道的响应通常反应了某种特定类别的响应,也就是说大部分通道的响应类别与跟踪目标不同,因此,同等地对待每一个通道的响应会限制网络特征的表达能力。另一方面,受感受野的限制,网络特征中的每一个空间位置都只能捕捉到附近的局部信息,因此,学习到全局上下文信息对于特征表达能力也非常重要。自注意力模块通过计算出通道的注意力特征图来自适应地对每一个通道的响应进行加权,将不相关通道的响应的影响降低;通过计算出空间位置的注意力特征图来捕捉空间每一个位置的信息,使得每一个位置的特征都能捕捉到图像全局的信息。接下来以空间自注意力模块为例,具体介绍其中的操作。
首先,将输入的特征图x∈C×H×W分别使用1×1的卷积核进行卷积。接着,对三个卷积结果分别使用三个变换函数f(x)、g(x)、h(x)进行转化。其中,变换函数分别为
f(x)=w1·x,
(2)
g(x)=w2·x,
(3)
h(x)=w3·x。
(4)
式中:w1、w2、w3分别表示f(x)、g(x)、h(x)三个函数的权重。将函数f(x)输出的结果进行转置后与g(x)输出的结果进行相乘运算,得到的结果使用Softmax函数运算可以得到空间注意力权重图。空间注意力权重计算公式为
(5)
式中:b、a表示特征图上的位置。再将得到的空间注意力权重图与函数h(x)做乘法,得到的结果与输入的特征图x进行相加运算,就得到了经过空间注意力模块调整后的特征图。最终的输出结果计算公式为
(6)
式中:ys为空间注意力模块的输出;xb为输入的特征;β表示权重参数,初始化为1,随着网络训练自适应动态变化。对于通道注意力的操作,可以使用类似的方式计算。最终将得到的空间注意力特征和通道注意力特征进行堆叠之后通过1×1的卷积进行特征融合就完成了这个模块的计算。空间注意力也是同样计算。
1.3 CSM模块
为了更好地捕获目标的几何状态,选择引入预测目标的轮廓掩膜信息,去和D3S原有的分割信息作为互补以提升跟踪的准确度。对于这个模块,受到了可变性卷积[9]的启发,普通的卷积对大型或未知形状变换的建模存在固有的缺陷,这种缺陷来源于普通卷积模块固有的几何结构——卷积单元对输入特征图的固定位置进行采样。在同一层卷积中,所有的激活单元的感受野是一样的[9],但由于不同位置可能对应着不同尺度或形状的物体,因此对尺度或者感受野大小进行自适应是进行精确定位所需要的。而可变形卷积可以用来提高网络对形变的建模能力。这个模块是基于一个平行网络学习偏移,使得卷积核在输入特征的采样点发生偏移,集中于网络感兴趣的区域或者目标。标准卷积中的规则格点采样是导致网络难以适应几何形变的原因,为了削弱这个限制,在轮廓预测模块中使用可变形卷积对卷积核中每个采样点的位置都增加了一个偏移变量,可以实现在当前位置附近随意采样而不局限于之前的规则格点。本模块结构如图4所示。

图4 CSM网络结构图
使用两个可变形卷积级联的方式组成此模块,借助于可变性卷积获取对目标外观模型的更强有力的表示,输出的特征经过上采样融合模块后与目标的真实轮廓标签进行交叉熵函数损失的计算[10]。
2 实验与分析
2.1 网络训练细节
使用ResNet-50在ImageNet[11]中的预训练模型作为骨干特征提取网络,使用YouTube-VOS数据集中的3 471个分割视频帧对整个网络进行训练,通过对所有帧序列在80帧的范围内进行均匀采样构造出训练样本。为了提高网络对跟踪目标定位的鲁棒性,通过对真实标签的位置进行扰动来增强算法鲁棒性。设置BatchSize为64,训练40个epoch,采用Adam优化器并且使用学习率调整策略,每15个epoch进行一次学习率衰减。损失函数采用预测结果和真实标签的交叉熵损失,使用GTX1080GPU进行训练,初始学习率设置为10-3。使用pytoch来对算法进行实现,在单块GTX1080上面需要30 h的训练。使用GOT10K、VOT2016和VOT2018对所提出的方法进行评估,在输入跟踪器前,视频图像的大小会被调整到384 pixel×384 pixel。
2.2 GOT10k实验结果
GOT-10k[8]是一个大型多场景的跟踪数据集,由10 000个视频帧序列组成,其中真实目标用轴对齐的矩形框进行标注。作为测试集,所测试的跟踪器需要在有84个不同对象类别和32个运动场景下的180个测试视频序列上进行评估,其余的帧序列形成一个训练集。设定跟踪器在第一帧上使用真实标注进行初始化然后一直持续跟踪到视频序列的末尾,数据集选择根据真实标注的边界框和预测出来的目标边界框的平均重叠率对跟踪器进行评价,分别在两个重叠阈值0.5和0.75处报告跟踪成功率,以便进行详细分析跟踪器的效果。
表1给出了GOT-10k的结果。D3S-AM在所有性能指标上都远远超过了性能最好的跟踪器,与D3S基准相比,D3S-AM的平均重叠提升了大约3.3%。如图5所示,它在平均重叠方面也比最新的ATOM和SiamMask跟踪器分别高出7.4%和11.6%以上。这证明了所提出的跟踪算法在不同的目标类型集合上有相当大的泛化能力。
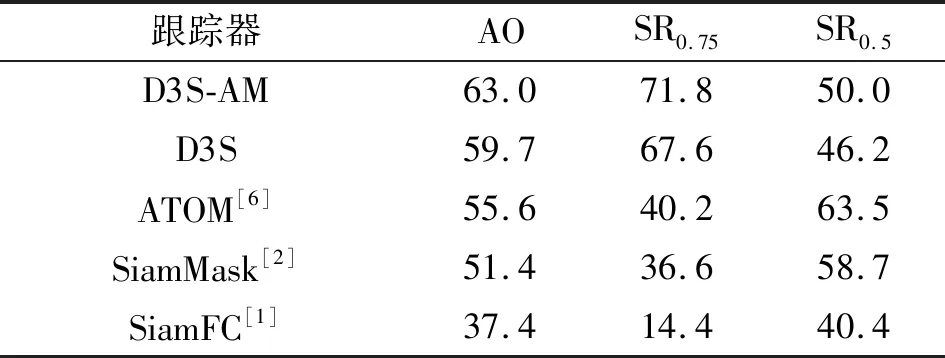
表1 GOT-10数据集结果分析

图5 GOT-10k跟踪结果对比图
2.3 VOT2016和VOT2018实验结果
VOT数据集[9]为世界视觉跟踪挑战赛使用的基准数据集,包含60个视频序列。它通过旋转矩形框对目标进行标注,可以全面地评估短时跟踪器的性能。其评判指标包括准确率(Accuracy)、鲁棒性(Robustness)和期望平均覆盖度(Expected Average Overlap,EAO)。在目标跟踪测试时EAO的值越高,跟踪算法性能越好。
选用在VOT数据集的性能极好的的几个跟踪器(SiamMask、ATOM、SiamRPN)以及基准算法D3S作为对比,结果如表2所示,同样的本文提出的D3S-AM性能遥遥领先。
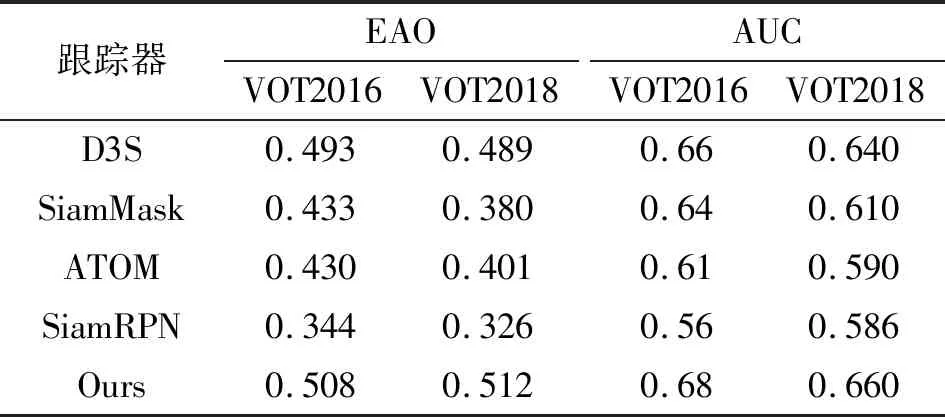
表2 VOT2016&VOT2018数据集结果分析
2.4 消融性试验分析
对提出的三个模块在GOT-10k上进行了消融实验,如表3所示,AFF、MDA和CSM模块起着积极的作用。 使用D3S作为基准,设置相同的超参数并分别比较每个模块,结果如图6所示,可见所提的D3S-AM具有最佳性能。
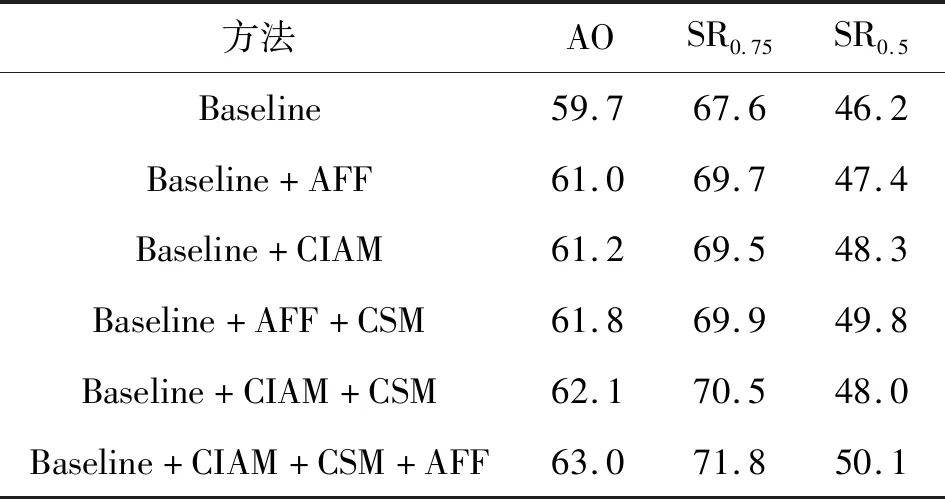
表3 消融性试验结果

图6 D3S-AM跟踪效果图
3 结 论
本文提出了一个目标跟踪网络的新的跟踪器——D3S-AM。针对D3S的不足提出了三点改进,分别实现成为了AFF、CIAM和CSM三个模块,其中AFF模块明显提高了网络的多尺度跟踪能力,CIAM模块增强了网络对目标的识别能力即鲁棒性,CSM模块增加了网络的准确度。将这三个模块应用到D3S网络中,在当前所有主流的数据集上都取得了优异的成绩。
