采用循环神经网络的战场空中飞行目标型号辨识方法*
2022-08-01王明阳
王明阳
(中国西南电子技术研究所,成都 610036)
0 引 言
现代联合战场态势瞬息万变,辨识和掌握对手来袭目标的身份属性是有效打击对手、快速形成作战决策的重要关键环节[1]。随着军事技术的蓬勃发展,以高速战机、巡航导弹等为代表的典型战场空中飞行目标为了躲避和突破侦察预警网络,不断提升自我隐身能力,使得辨识其型号等身份属性变得愈加困难[2]。因此,如何及时辨明战场空中飞行目标的型号,一直是战场目标属性信息支持的难点问题。
对此,诸多学者提出了一系列解决方案。基于规则模式构建的经典目标识别方法[3-5]通过分析目标单源或多源数据特征,利用概率统计与推理机制,构建特征阈值规则,形成目标识别规则知识库,从而构筑目标数据到目标型号的规则判别路径与映射,最终实现目标型号的辨识。该类方法优点在于工程可快速部署,易于实现,识别速度快,人工规则设置修改便捷,因而很多目标属性甄别设备使用了该类方法。但该类方法也存在相对突出的缺陷和问题:由于战场环境的快速变化以及所探目标的属性特征纷繁复杂,空中飞行目标型号识别规则经常需要手动修改,而修改后的规则很可能因飞行目标特性的快速变化以及特征分析的不完备,导致识别性能急剧下降甚至失效[6]。
基于数据驱动的目标型号辨识方法[7-9]则利用了机器学习和深度学习技术,在模型训练阶段直接从数据中自动寻找便于目标型号辨识的可分特征,实现从目标数据到目标型号的“端到端”辨识,效果良好。然而在基于目标航迹态势数据的战场目标属性信息支持过程中,空中飞行目标型号需要每时每刻上报,即“边探边识”,不能容忍目标全部数据接收完毕后再进行型号辨识,即“先探后识”。因此,广泛用于计算机视觉的卷积神经网络(Convolutional Neural Network,CNN)方法不能适应实际作战需求[10];而基于梯度提升树的方法[11]因未能利用目标航迹数据间的运动状态转移时序性,使得目标型号辨识正确率还有进一步提升的空间。
为此,本文提出一种采用循环神经网络的空中飞行目标型号辨识方法,以飞行目标航迹态势数据为基础,通过分析数据不同特征特点,设计增加基于数据原有特征的人工统计特征族,增强目标特征可分性;构建并训练基于循环神经网络的场空中飞行目标型号分类器,利用目标航迹点间隐藏的运动状态转移信息形成序列化型号智能辨识模型,实现仅依赖于航迹的战场空中飞行目标型号时序化准确辨识,以满足实际目标型号时序化辨识的应用需求。
1 数据集构造与特征增强
1.1 目标航迹数据集构造
本文数据集采用文献[11]中所述数据集。该数据集源于脱密处理后的某战场空中飞行目标航迹数据集,其结构如图1所示,总计含有空中飞行目标型号14类,以英文字母A~N进行分别标识,每类又含有数量不等的目标个体航迹数据,每条航迹含有以下特征字段:
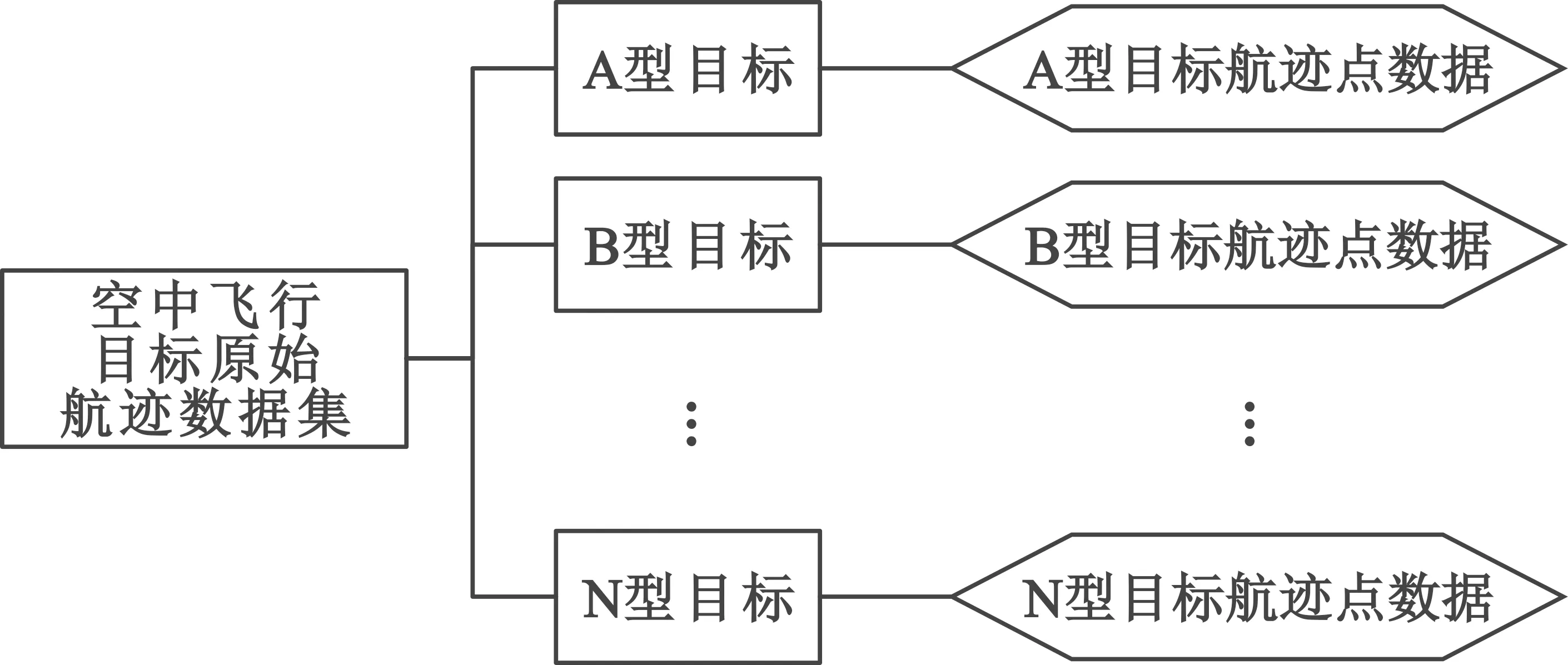
图1 数据集结构示意图
(1)航迹点编号(PID),形如1,2,…;
(2)目标编号(TID),形如A000001;
(3)目标经度(LAT),形如123.45,单位为(°);
(4)目标维度(LON),形如67.89,单位为(°);
(5)目标高度(ALT),形如10000,单位为m;
(6)目标速度(V),形如500,单位为m/s;
(7)目标航向(AZ),形如60.0,单位为(°);
(8)航迹点时间(T),形如1643472000,单位为s。
由于数据以航迹点出现的时间顺序进行排列的,且未对重复上报航迹点数据以及上报异常数据进行处理,因此在构造空中飞行目标航迹数据集时首先进行数据整理及清洗,具体算法伪代码如下:
for type=A,B,…,N do
for PID=1,2,…,Pdo
end
end

第三,针对每一个个体目标,具体按以下步骤进行数据预处理:
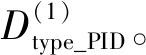
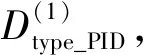
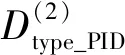
箱线图[12]是观察数据特征值是否异常的直观展示形式,如图2所示,其使用了最小值(vmin)、第1四分位点(Q1)、中位数(Q2)、第3四分位点(Q3)以及最大值(vmax)5个数据统计特征。根据这5个统计数值便可给出数值异常的定义,即若特征数值v

图2 箱线图示意
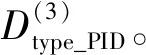



表1 预处理后的目标航迹数据集概况
1.2 特征增强
以深度学习为代表的数据驱动学习方法模型之所以能够对数据样本进行分类辨识,是因为目标特征数据在抽象的特征空间中具有显著的可分性,从而可以通过构建分类辨识模型得到这个可分的超平面,将不同类型的数据分隔开来[13]。因而要想得到性能优良的可分分割超平面,分类辨识模型就必须具备良好的特征映射能力,将原先不可分的、不连续的数据映射到可分的、连续的高维特征空间中。
为了达到这样的可分连续目的,需要对原始特征数据进行一系列的变换,以便增强后续目标型号辨识模型的识别性能。因此,为了方便后续识别性能的比较,本文基于预处理后的目标航迹数据集,选取了与文献[11]中设计相同的3类派生特征,即正余弦航向特征、地理行距特征以及相对时间特征,从而能够在时序维度上反映出航迹数据的显性状态转移特性。
2 基于长短时记忆网络的型号辨识模型
2.1 长短时记忆网络
长短时记忆网络[14](Long Short-Term Memory,LSTM)是一种具备输入和处理序列数据能力的循环神经网络(Recurrent Neural Network,RNN),因其具备动态记忆较为久远的目标状态信息能力以及兼具神经网络深层次非线性特征映射等优点,因此非常适合用于基于航迹数据的战场空中飞行目标型号辨识任务。
一个典型LSTM单元如图4所示。通过引入常量误差轮转(Constant Error Carousel,CEC)结构以及门控机制,使得LSTM单元一方面可以加大缓解延时间方向的梯度消失问题,而且另一方面可以较好地控制历史信息与当前信息对识别性能的贡献程度,较好地利用了时序数据中隐含的状态转移信息。
LSTM的工作原理可形式化表示为以下过程[15]:
(1)
(2)
(3)
(4)
(5)
(6)
2.2 目标型号辨识分类器
本文采用LSTM模型对战场空中目标型号进行辨识,所提模型如图5所示。
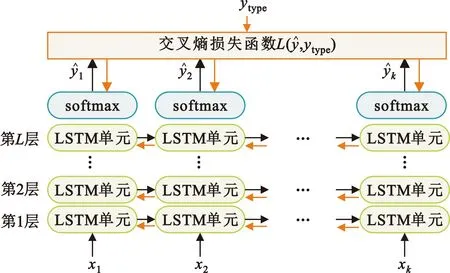
图5 基于LSTM的目标型号辨识分类器
首先,通过设置每个LSTM单元内部的权值维度,堆叠LSTM单元,最终形成L层LSTM深度神经网络。
其次,将战场空中飞行目标航迹数据(如图5中的X={x1,x2,…,xK},其中K为航迹长度)按序列顺序依次输入网络,计算生成目标型号概率值。
最后,通过交叉熵损失函数的损失计算,利用延时间梯度反传(Back Propagation Through Time,BPTT)方法优化调整各LSTM单元中的权重直至收敛,最终形成战场空中飞行目标型号分类器。
2.3 分类器的训练
为了与文献[11]所提梯度提升树模型进行性能比较,本文采用与文献[11]相同的识别模型训练流程,即针对战场空中飞行目标型号分类器模型,其训练流程如图6所示。

图6 分类器设计流程
首先,将预处理后的空中飞行目标航迹数据集划分为训练集与测试集,具体步骤如下:
Step1 以航迹为细粒度,对各目标型号航迹数据进行乱序洗牌。
Step2 针对每型目标,将洗牌后的航迹数据依据各型目标航迹总数以8∶2的比例无放回式抽取形成各型目标对应的训练数据子集以及测试数据子集。
Step3 合并所有训练数据子集,再次经过乱序洗牌后,形成最终训练集。同理,合并所有测试数据子集,再次经过乱序洗牌后,形成最终测试集。
其次,设置LSTM分类网络模型参数。本文使用pytorch架构,利用python语言,通过调用LSTM高速运算模块,并运用pack_padded_sequence、pad_packed_sequence以及dataloader模块,实现不等长航迹数据的并行化训练输入。在训练过程中,损失函数采用交叉熵损失函数,优化算法使用Adadelta算法[16]。对于LSTM网络来说,其参数设置如表2所示。

表2 LSTM网络模型参数设置表
然后,开始模型训练过程。本文采用5折交叉验证方式。其评估准则使用精确率、召回率以及F1分数。
最后,选择F1分数最高的模型为最终战场空中飞行目标型号辨识模型。
3 实验与分析
3.1 型号识别模型的辨识效果
本文所提型号识别模型的训练和测试过程均在GPU环境下进行,操作系统为Windows10 64位,运算平台为HP Z8工作站,CPU为Intel Xeon Silver 4216,内存256 GB,GPU为Nvidia RTX6000,python IDE环境为pycharm 2020.2,anaconda版本为2020.2,cuda版本为10.2。
经过训练后,最优模型文件占用约12 MB的硬盘存储空间。经测试集验证,所训目标型号辨识模型的最终分类性能如图7和表3所示。其中,测试集支撑数是指测试集中对应空中飞行目标型号的航迹样本的航迹点总个数。由表3可计算出准确率为96.73%,F1分数加权平均为0.968 3。
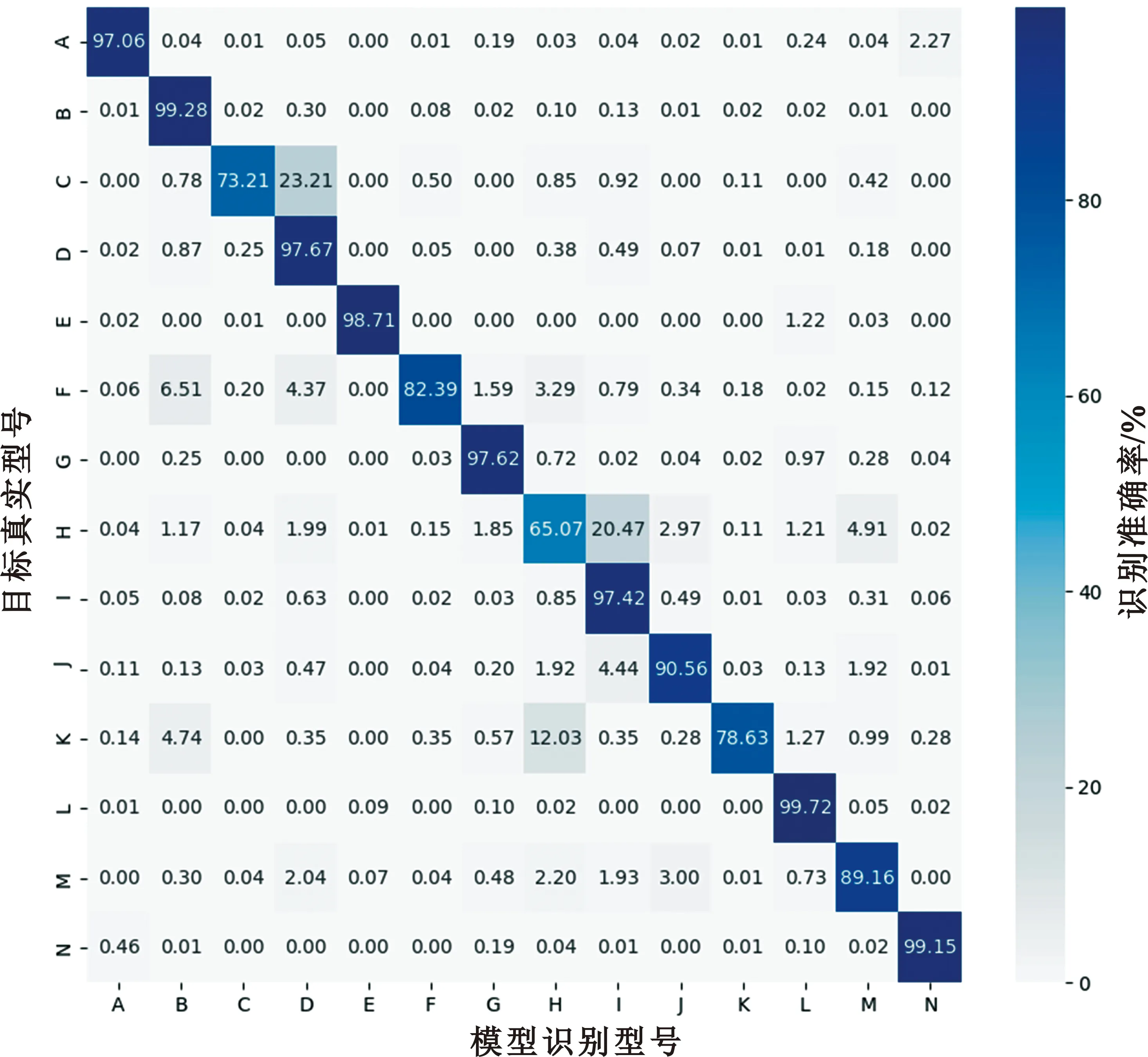
图7 空中飞行目标型号辨识模型识别混淆矩阵
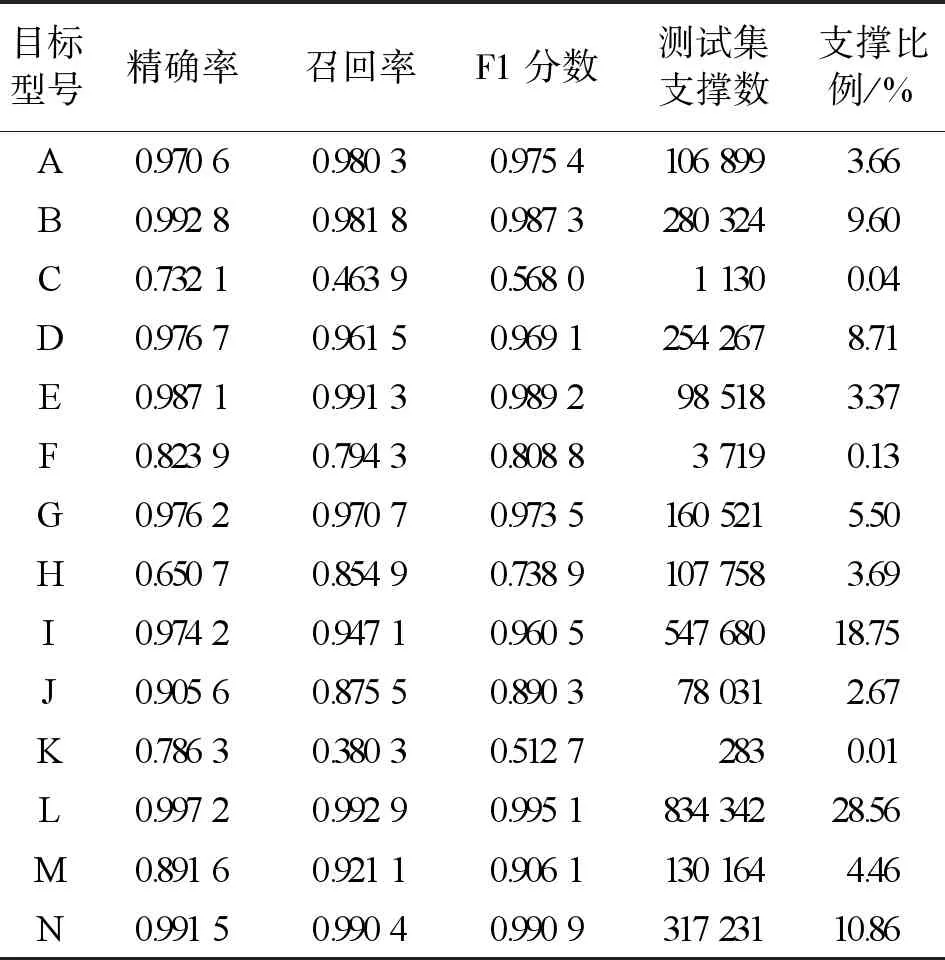
表3 模型测试集辨识性能结果
由图7和表3可知,型号C被误识别为型号D的概率以及型号H被识别为型号I的概率都较大,型号F有一定概率被识别成型号B和型号D,型号K有12.03%的概率被识别为型号H。结合所用目标航迹数据集,可初步分析出所训模型误识别的主要原因在于,这些已被误识别的型号航迹样本数目太少,航迹过短,导致LSTM模型难以从少量的样本信息中学习到目标航迹与目标型号间的映射关系。此外,由于所用样本数据类别不平衡问题较为突出,使得模型学习存在偏差,识别性能更加偏向于样本数目较多的目标型号类别。
3.2 Light GBM模型识别效果
为了证明所提方法的性能优势,与文献[11]中的轻量梯度提升树模型(Light Gradient Boosting Model,Light GBM)方法进行了比较,具体流程如图8所示。其中,两个模型除输入层参数与相应输入特征维度对应之外,其余参数均与文献[11]中的Light GBM模型参数一致。

图8 基于Light GBM的比对模型训练测试流程
首先,以相同的训练集和测试集作为模型训练和测试的数据源,并且以相同的方式和比例划分和生成训练集和测试集。
然后,按照文献[11]中描述的训练方法构建并训练Light GBM模型。为了验证本文所提LSTM模型的识别性能,在此步骤中,采用两种方式进行比较:一种方式是完全采用文献[11]中设计的全体目标识别特征进行训练,得到Light GBM-1模型;另一种方式则是仅采用本文1.2节使用的三种目标航迹特征进行训练,得到Light GBM-2模型。
最后,使用相同的测试集对已训Light GBM-1和Light GBM-2模型进行辨识性能测试。
经过训练与测试后,可得基于Light GBM-1比对模型的空中飞行目标型号平均识别正确率为95.71%,F1分数加权平均值为0.955 1,与文献[11]中的测试结果基本吻合;而基于Light GBM-2比对模型的型号平均识别正确率为95.15%,F1分数加权平均值仅为0.950 2。具体模型识别性能比较如表4所示,可以看出,本文所提LSTM方法与Light GBM-1模型相比识别正确率提高了1.02%,F1分数提高了0.013 2;与Light GBM-2模型相比,识别正确率提高了1.58%,F1分数提高了0.018 1。

表4 模型型号辨识性能的对比
从上述实验结果可以得出以下结论:
(1)当采用相同的目标特征时,由于所提LSTM模型正是利用了航迹点间的运动状态时序转移关系信息,使得识别性能较未使用该信息的Light GBM-2模型的识别性能更优;
(2)当采用同一模型时,由于Light GBM-1模型使用了更多的特征,使得模型可分性更加显著,因此Light GBM-1模型识别性能比Light GBM-2模型识别性能好;
(3)当利用航迹数据时序信息且采用深度特征提取方式来替代人工设计特征时,由于深度时序状态转移特征比人工设计的5点统计特征在特征表征能力上更加有效,因此所提LSTM模型比Light GBM-1模型的识别性能更优。
综上,在空中飞行目标型号辨识性能方面,本文所提方法与文献[11]所提的Light GBM模型相比,在识别正确率和F1分数方面均有提高,证明了所提方法在型号辨识上的有效性。
4 结束语
本文针对战场空中飞行目标型号辨识不清的问题,提出了一种采用LSTM循环神经网络的战场空中飞行目标型号辨识方法,旨在利用航迹点间的目标运动状态转移信息来提升模型的辨识性能。具体地,以飞行目标航迹态势数据为数据源,通过分析数据不同特征特点,设计增加基于数据原有特征的3个派生特征,构建并训练基于LSTM循环神经网络的目标型号分类器,形成目标型号序列化智能辨识模型,实现仅依赖于航迹的战场空中飞行目标型号时序化准确辨识。在性能比较方面,本文通过控制输入特征,以文献[11]所提的Light GBM模型为基准,生成Light GBM-1模型和Light GBM-2模型,并使用实测数据对目标型号的识别准确率和F1分数进行了比较。经实测数据验证,本文所提方法识别准确率达到96.73%,F1分数达到0.968 3,较Light GBM-1模型分别提升了1.02%和0.013 2,较Light GBM-2模型分别提升了1.58%和0.018 1,证明了所提方法的有效性。
下一步将基于文献[10]所提的CNN模型、文献[11]所提的Light GBM模型以及本文所提的LSTM模型,在相同的数据样本集条件下对样本不平衡及小样本识别的问题开展研究工作,从而进一步提升辨识性能。
