基于深度学习表示的医学主题语义相似度计算研究*
2022-08-01黄承宁李双梅
黄承宁 李双梅 景 波
(1.南京工业大学浦江学院 南京 211222)(2.南京审计大学 南京 211812)
1 引言
当前搜索引擎已成获取信息之快捷工具,然即便是最受欢迎的搜索引擎返回的搜索结果也不令人满意。用户确实输入了正确的关键字,而搜索引擎却返回了涉及这些关键字的文本页面,大多数结果是不贴切的。搜索机制的性能好坏取决于解决两个重要问题:一是如何提取相关的文本的主题,二是给出了一组潜在相关的页面如何对它们根据相关性进行排名[1]。评估搜索机制在查找和查找中的有效性和排名结果,需要语义相似性的度量。在传统方法中,用户提供相关性或语义相似性的手动评估[2],而这非常耗费成本。词之间句之间的语义相似性研究[3],这是信息检索的重难点部分。语义相似性是一个概念,其中衡量语义单词之间的相似性是网络上各种任务中的重要组成部分提取[4]。在信息检索中,主要问题之一便是要检索一组文档数据集,计算给定的用户查询在语义上的相关度。高效估计之间的语义相似度单词对于诸如词意之类的各种自然语言处理任务至关重要。在基于字典的方法中,词之间的语义相似性是可查询的,但是当涉及到网络文本时,它已成为现今极具挑战性的任务。
基于深度神经概率语言模型的特征提取器可以提取与大量文本数据来计算任务相关的特征,这些方法亦被称为自然语言理解(NLU)模块。它们功能也可以用于计算文本样本之间的相似度,这对于基于实例的机器学习最近邻算法很有用。文本的相似度可以通过深度学习的神经网络模型将语言转化为对语义建模的向量空间,而通过测算语义向量空间中文本向量的相近度,可以更好比对文本的语义特征。为了说明这一点,本文将使用谷歌2019 年最新的基于神经网络的语言概率模型搜索算法(后文简称其首字母缩写BERT)[5],执行文本特征提取构建向量化语义数据,并为文本实现搜索的算法优化。
2 基于深度学习的搜索算法
基于神经网络的深度学习模型有利于统计文本数据中语言的出现概率,更好地对大体量地文本数据进行建模,下面将介绍神经网络地基本结构、基于深度神经概率语言模型以及基于语义相似度地向量空间模型。
2.1 神经网络基本结构
深度神经网络(DNN)是一种新型的基于数据概率的机器学习方法。DNN可以表示为函数F(X)=Y,其中X 表示输入空间,Y 表示输出空间。连接的层数和层之间的链接由一组权重矩阵加权[6~7]。训练阶段DNN 的作用是识别权重矩阵的数值。训练程序利用了已知的输入输出对,并定义了表示预测与真实标签之间的差异。训练阶段,则使用反向传播技术通过最小化损失函数来更新参数。
在如图1 的典型前向神经网络基本结构中,术语layer 特指一层人工神经元,术语input layer 特指创建出的接受输入的第一层神经元定义函数,输出张量进入第二层以及紧接着的hidden layer 函数群(图示含有三层),最后由output layer函数生成输出。
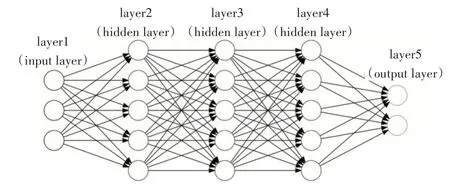
图1 典型前向神经网络基本结构
2.2 深度神经概率语言模型
双向编码器语言模型的注意力机制表示法(后文称Transformer)[8]是由谷歌人工智能团队最新开发的语言表示模型于2018 年对深度双向表示进行预训练,通过共同限制左右文本环境所有层。神经网络语言模型允许深层双向表示屏蔽某些百分比的输入数值的方法然后仅随机预测那些被屏蔽的数值。这个应用在预测许多重要的下游任务,诸如机器阅读和自然语言问答推论基于对在两个文字句子之间关系的理解。
2.3 预训练语言模型
2018 年,学术界引入并发布了基于神经网络的自然语言处理(NLP)预训练技术,该技术被称为Transformer 的双向编码器表示模型[9~10],是组成BERT模型的基本单元。这项突破是谷歌研究的结果:该模型可处理与句子中所有其他单词相关的单词,而不是一个接一个地处理单词。BERT的突破,在于其基于查询中的段落及句子集来训练语言模型,而不是以往的有序序列训练方法。BERT 允许语言模型基于周围的单词学习单词上下文,而不只是限于其后接着的语句。
2.4 与传统查询方法的比较
区别于传统方法RankBrain[11~12],新的方法可以立足于上下文语境构建更复杂的共现统计。关于RankBrain,其实是搜索排名算法并行运行,用于对检索结果进行调整。RankBrain通过上一步查询从而查找接近的已有查询来优化结果。
传统算法虽然查到页面上的内容,以了解其相关性。但是,传统文字检索算法一般只关注词之前或之后的内容以获取其全文语境,以更好地计算该关键词的语义。BERT[13]的双向组成部分使其与众不同,它在查看关键词所在全文的内容以了解词的含义和相关性,是自然语言处理中的一次巨大突破。
3 算法实现与开发
该项目采用Python 3 编程语言开发,使用TensorFlow 框架以及相关内置API 和相关调用库。为了更快速地加载大量文本数据,使用其NLTK[14]调用库,该库可以把大规模文本数据集作为二进制字节流保存在硬盘中[15~17],存储大小不超100M,且可以使用代码快速重复调用,更有利于深度模型将其数据作为向量化输入。
3.1 加载预训练语言模型优化计算图
实验将从加载预先训练的BERT 保存节点开始。 出于方便实验目的,将使用Google 开源预先训练的无固定大小写英语模型。为了配置和优化推理图,将调用bert-as-a-service 存储库。在实验部分中,将重点放在创建本地过程中的特征提取器。
从表1、表2可见,语言概率模型的大小若果存储在本地磁盘会造成一定计算负担,为了保障模型的稳定性及整体搜索的迅速性,要修改模型图,借助bert-as-a-service,使用CLI 命令行界面配置信息,并对张量处理器(TPU)和图形处理器(GPU)训练实施计算优化。
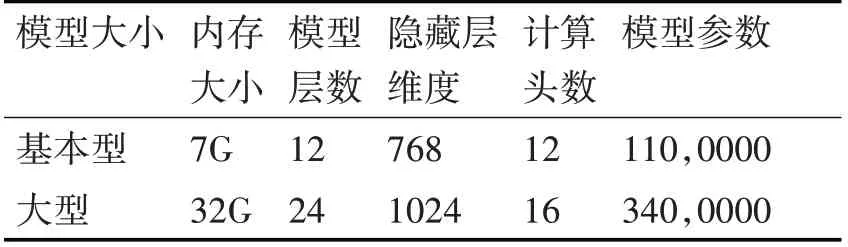
表1 模型大小对比各项特征数值表
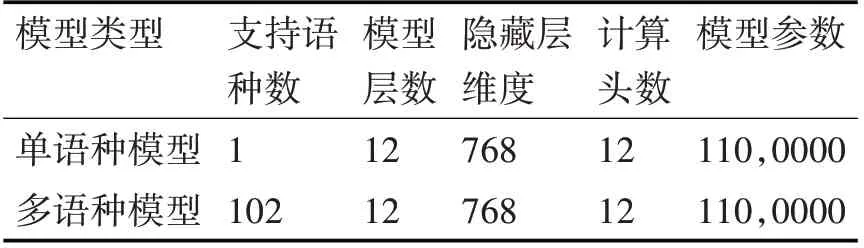
表2 基本型模型不同类型对比表
3.2 初始化特征提取器
将通过序列化图使用tf.Estimator API 构建特征提取器。将需要定义组件:input_fn 和model_fn。组件input_fn负责把数据传入模型。过程显示如图2所示。
图2 加载过程
3.3 使用Projector组件搜索向量空间
使用矢量化器,将为Reuters-21578 基准语料库的文章生成嵌入。为了探索3D中的嵌入矢量空间,将使用一种称为T-SNE 的降维技术,在其子类EmbeddingProjector上可以获得生成的嵌入向量。
设p和q分别代表输入文本向量和存储数据集中各文本向量,则计算各文本间相似度可用欧几里得距离来衡量,如式(1)所示。

在图3 不加算法的文本空间中可以看到,不同颜色的文本混乱地粘合在一起,难以区分不同的主题。使用基于神经网络的概率语言模型将文本型量化后,在向量空间中不同语义的文本距离更大了而语义相近的文本距离变小了。

图3 搜索算法分类文本空间可视化
3.4 创建搜索引擎
实验中将要解决的搜索问题定义如下:给定向量空间M 中的一组点S 和一个查询点Q∈M,在S 中找到最接近S 的点。有多种方法可以定义向量空间中的“最近数据点”,将使用欧几里得距离。
因此,要构建文本搜索引擎,将按照以下流程操作:向量化知识库中的所有样本,从而得到S;向量化查询-给出Q;计算Q 和S 之间的欧式距离D;按升序对D 排序-提供最相似样本的索引;从知识库中检索所述样品的标签。
3.5 实验数据及结果分析
实验中,使用《中国癌症杂志》、《中国癌症杂志》等医学期刊作为样本数据来源数据集。使用Retriever 模块,将建立一个信息推荐器,为具有相似主题数据特征的文本提供建议。
实验过程中,使用三组关键字进行搜索测试,分别为“乳腺癌”、“宫颈癌”、“肺炎”主题文本返回了语义相关医学文档的标题,显示出有效的语义相似度搜索能力;第三组的肺炎标签,显示所搜不存在,也从侧面显示语义相似度的有效性。
根据实验测试数据,通过计算新模型的精确率、召回率和F1 数值,衡量本文方法和目前已有方法的表现。
从表3 可见,采用预训练模型的搜索算法精度可达80%以上,对照组的基准线精度如表4所示。
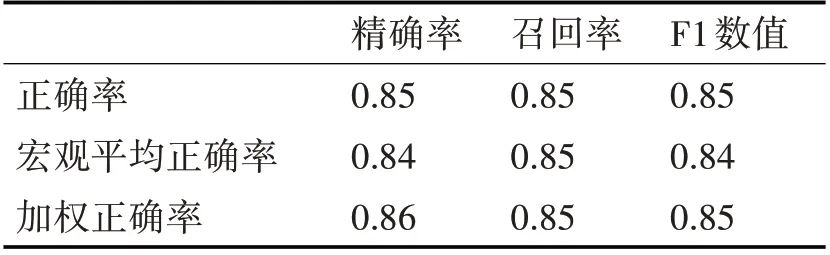
表3 新方法表现

表4 对照组基准线方法表现
从表4 可见,不采用预训练模型的搜索算法精度可达60%以上。由此可得,计算搜索算法的提高效率如表5所示。
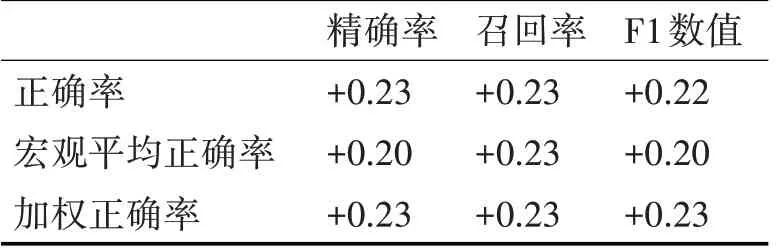
表5 两项对比数值提高情况
从表3、表4、表5可知,新算法的准确性平均可达80%以上,对比原有方法存在20%的提高。这是因为预训练语言模型,可以通过对词语及关键语句的上下文或邻接语段进行遮盖编码输入深度模型,更精确地计算文本语义相似度。
4 结语
寻找两个句子的语义相似性总是自然语言处理与信息摘取领域的一个大挑战。在本实验中,构建了基于预训练语言模型特征提取器,并使用BERT 构建文本检索功能,在分类和检索任务上充分发挥作用,充分证明了预训练语言模型在基于语义相似度的搜索算法优化中有显著的提升作用。通过对预训练神经网络进行微调,语义搜索方法可以进一步提高其性能。实验中显示使用更大长度的查询结果比短的查询具有更高的精确度和召回率。
