基于改进FaceNet的飞行器结构裂纹识别方法
2022-08-01吕帅帅杨宇王彬文殷晨飞
吕帅帅,杨宇,王彬文,殷晨飞
中国飞机强度研究所,西安 710065
金属裂纹是航空结构的一种常见损伤形式。在航空结构疲劳试验中及时发现并跟踪损伤扩展过程,能够暴露航空结构设计的薄弱环节,支撑结构强度和完整性评估,同时也为航空结构维修大纲和维修手册编写提供必要的技术数据。目前发现裂纹主要依靠人工目视检查,以及定期的无损检测(如涡流、超声等)。但是飞机结构内部空间狭小、大量传感器线缆干扰,使得无损检测人工操作极为不方便。另外,裂纹通常只在结构加载至高载状态时才目视可见,而此时出于安全考虑,检测人员是无法抵近检查的。因此,传统的人工无损检测存在较大的损伤漏检可能性。
随着计算机视觉和机器人技术的发展和应用,机器视觉为飞机疲劳试验中的裂纹自动化检测提供了一条新的解决途径。通过工业摄像头和高精度运动系统(如机械臂、爬行机器人)定位检测位置并获取高清图像,再应用目标检测算法进行裂纹自动识别,可以大幅度降低人工在成本、实时性和危险性等方面的不利影响。
目前研究者主要采用单帧目标检测算法进行裂纹识别,即在单张图像内搜索裂纹。Ren等提出的Faster R-CNN算法和Redmon等提出的YOLO算法是典型的单帧目标识别架构,其差异体现在对检测准确率和计算速度的不同侧重。Deng、Du、Wang和杨晶晶等分别使用Faster R-CNN、YOLO等进行了混凝土结构和金属结构的裂纹检测,且获得较高的检测准确率。但是需要注意的是,被识别的裂纹主要是张开位移较大的混凝土裂纹和长度较长的金属裂纹。全尺寸疲劳试验中的裂纹长度、张开位移均较小,且金属结构表面的纹理、划痕、打磨痕迹等与这些微小裂纹的相似度极高,形成强烈的干扰。因此,单帧目标检测算法并不适合于飞机全尺寸疲劳试验中微小裂纹的识别。
另一种潜在的方法是采用基于两帧图像对比的相关性识别算法进行微小裂纹检测。该类算法是以两张图像间特征的相关性为依据,判别两者是否包含同一个检测目标,分为特征提取和相关性计算两个步骤。常用的特征提取方法包括多通道方向梯度直方图、颜色命名算法、多特征集成尺度自适应算法和深度学习算法等,相关性计算则以基于傅里叶变换和核函数的计算方法为主。该类方法目前通常应用于目标跟踪,即跟踪已知对象的运动轨迹。但是这类算法无法直接应用于飞机全尺寸疲劳试验,因为微小裂纹的尺寸相对于检测区域存在2个数量级的差别,很难对图像特征产生显著影响。此外,常用的特征提取方法对图像亮度、清晰度敏感,而全机疲劳试验由于结构的不规则振动,无法保证图像质量的一致性。
因此,本文提出了面向飞机全尺寸疲劳试验的微小裂纹识别方法,其创新点体现为:① 针对划痕、污损等广泛存在的干扰因素,采用特征对比策略识别裂纹;② 针对微小裂纹与被检测区域尺寸存在2个数量级差别这一矛盾,提出基于关键部位状态对比的识别方法,首先根据疲劳裂纹萌生机理,设定重点检测区域,然后将检测区域划分为4个部位,使得微小裂纹与检测部位的几何尺寸处于相同数量级;③ 为降低疲劳试验中结构振动导致的清晰度、亮度变化等问题对裂纹识别准确率的影响,选取人脸识别模型FaceNet作为基础架构,再根据裂纹数据集的结构特点,对FaceNet模型进行相应改进。
1 面向全尺寸疲劳试验的裂纹检测方法
1.1 检测策略
本文应用特征对比的方法进行目标检测。图像间的特征能够进行有效对比的前提是检测目标与被拍摄区域不能存在跨数量级的尺寸差别。而在全尺寸结构试验中,虽然飞机结构庞大,但是裂纹均是在结构细节处萌生,例如紧固件孔和非连续结构等应力集中区域。因此,本文采用基于关键部位状态对比的策略进行裂纹识别。
例如根据结构受力分析可知,图1中可能出现裂纹的关键部位为紧固件1~6的孔边。为提高微小裂纹的检出概率和裂纹在检测图像中的比例,本文将每个关键部位的周边区域分为4个部分,每一部分作为一个检测部位(如紧固件 1 所示)。通过对比每个检测部位的实时采集图像和无裂纹模板来发现裂纹。

图1 全尺寸疲劳试验中关键区域的检测图像示例Fig.1 Sample images of key areas in a full-scale fatigue test
1.2 基于改进FaceNet的裂纹检测模型
FaceNet是一种基于深度学习的人脸识别模型,本文选择FaceNet作为裂纹识别模型的基础架构,因为该模型的核心是三元组损失。三元组损失的优势在于细节识别,善于处理非同类、极相似样本的分类问题,可支撑深度学习网络提取仅对裂纹敏感的图像特征,降低图像质量变化对检测结果的影响。
1.2.1 FaceNet模型
FaceNet实现人脸识别的基本原理为:利用深度学习网络将输入的人脸图像映射至一个128维的欧氏特征空间,并计算不同图像在新空间内的特征距离,特征距离小于类别判定阈值的两张人脸图像可被判定为同一个人。
FaceNet的基本结构如图2所示,其中深度学习网络采用已有的成熟网络。该模型能够实现高准确率人脸识别的根本原因在于提出了三元组损失的概念,并应用三元组损失对深度学习网络进行训练。

图2 FaceNet模型的基本架构Fig.2 Basic architecture of FaceNet
人脸识别问题中的“三元组”指的是由模板-正例-反例三张图片组成的一个数据样本,其中模板和正例为同一个人在不同状态下(如正脸、侧脸)的两张图像、反例则为任意其他人的一张图像。在训练过程中,模型每次处理个样本(记为一个批处理数据),每个样本通过深度学习网络提取特征,得到3个128维的特征向量。然后网络根据特征向量计算批处理数据的三元组损失。三元组损失具体可表示为


(1)

由式(1)可知,三元组损失的本质是在新的特征空间内,尽量减小模板和正例图像间的特征距离,同时尽量增大模板和反例图像的特征距离,并要求前者的距离值至少比后者的距离值小。也就是说,FaceNet通过三元组损失使深度学习网络对比学习同一个人在不同状态下(如正脸、侧脸、不同表情)的共性特征和不同人间的差异特征,这使FaceNet提取的特征向量不易受人脸图像状态的影响,而对人脸的固有属性更加敏感。
1.2.2 裂纹识别与人脸识别的差异分析
在复杂的全尺寸疲劳试验环境中,针对同一检测部位在不同时刻拍摄的图像在亮度、清晰度和拍摄角度等方面均可能存在差异。深度学习模型必须能够准确区分裂纹的产生和图像质量的变化,即要求模型提取的特征不易受图像质量影响,而对裂纹十分敏感。这与FaceNet模型中三元组损失的设计目标是一致的。因此本文选择FaceNet作为裂纹识别的基础架构。但是,裂纹识别与人脸识别问题有两方面的差别:数据结构差异及由此引起的特征分布差异。
1) 数据结构的差异
在人脸识别问题中,若待识别数据包含个人,则每个人可看作一个类别,模型处理的是一个分类问题;而在裂纹识别问题中,无论训练数据来自于多少个检测部位,其均为一个二分类问题(有、无裂纹)。针对该问题,需对原FaceNet中的三元组样本生成规则进行改进。
原FaceNet模型的样本生成规则如图3所示:① 从待分类的个人中随机选择两个和,在的图像中随机抽取两张作为模板和正例,在的图像中随机抽取一张作为反例,构成一个三元组样本;② 重复步骤①至样本数量达到设定要求;③ 计算所有样本的正、反例距离差(见式(1)),并将大于0的所有样本作为最终样本。

图3 FaceNet的样本生成规则Fig.3 FaceNet sample generation rules
改进FaceNet裂纹样本的生成规则如图4所示:① 针对第一个检测部位,在所有无裂纹图像中随机抽取2张分别作为模板和正例,并在所有有裂纹图像中随机抽取一张作为反例,组成一个样本;② 重复步骤①,直至检测部位1的样本数量达到设定要求;③ 计算检测部位1中所有样本的正、反例距离差(见式(1)),并将大于0的所有样本作为位置1的最终样本;④ 针对其余位置,仿照第一个检测部位,重复以上操作,获取每个部位的最终样本;⑤ 所有部位的最终样本组成总样本,再分割成批处理数据进入深度学习模型参与训练。
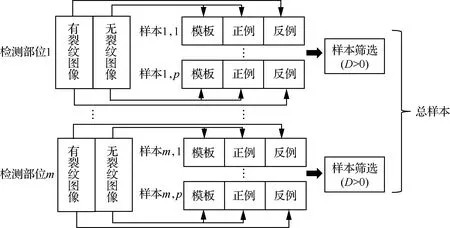
图4 改进FaceNet的样本生成规则Fig.4 Sample generation rules of improved FaceNet
2) 由数据结构差异引起的特征分布差异
对比两种样本生成规则可知:① 原FaceNet模型是对所有数据进行分类,改进后的模型是在每个检测部位内部进行分类;② 原FaceNet模型是对每个类别进行聚类,而改进后的模型只对每个检测部位的无裂纹图像进行聚类。样本生成规则的更改直接影响了模型提取特征的分布规律。图5为原FaceNet模型在人脸分类数据集上提取特征的分布示例,其中数字表示第个人的人脸图像,表示第个人图像的类内距离,,表示第、两个人的类间距离;图6所示为改进FaceNet在裂纹数据集上提取的数据特征的分布示例,其中-crack、-uncrack分别表示裂纹数据样本中第个部位的有、无裂纹图像,1表示第个部位有、无裂纹图像的类间距离,2表示第个部位无裂纹图像的类内距离。需要指出的是,图5和图6中显示的是原128维特征经过主成分分析降至2维后的分布状态,降维会导致部分数据特征的改变,只能定性表示原特征的分布规律。

图5 FaceNet提取特征的分布示例Fig.5 Distribution example of FaceNet extracted features
对比图5和图6可知,裂纹特征分布的规律性明显低于人脸特征。其中最明显的就是图5中的类内距离整体小于类间距离,例如、、小于、。基于这一规律,原FaceNet模型的类别判定阈值计算可以转化为一个简单的线性问题;而在图6中,数据特征的分布是高度非线性的,类别判定阈值的求取不再是一个线性问题,下面从两个层面对该问题进行分析。
首先,各检测部位有、无裂纹的判定阈值是不一致的,例如图6中检测部位1的判定阈值∈(,),部位3的判定阈值∈(,),而小于,也就是说无法通过线性计算的方法在各检测部位间确定一个统一的判定阈值;其次,即使在一个检测部位内部,判定阈值也无法直接求取。例如针对检测部位2,小于,也就是说在新的样本生成规则下,三元组损失只能保证每一张无裂纹图像到任意一张有裂纹图像的距离都大于该无裂纹图像到其他任意无裂纹图像的距离(例如>),却无法保证1大于2,这是裂纹特征与原FaceNet模型提取特征的最大区别,该区别增加了特征分类问题的非线性度。

图6 原FaceNet模型提取的裂纹特征的分布规律示意图Fig.6 Schematic diagram of distribution of crack characteristics extracted from original FaceNet model
1.2.3 对现有FaceNet模型的改进
通过以上分析可知,更改样本生成规则后,原FaceNet模型的架构和三元组损失已无法满足裂纹识别任务的要求。因此,本文在原FaceNet模型后增加一个全连接层(2个神经元)直接进行样本分类,同时在原损失函数中加入分类层的交叉熵损失,以在参数优化过程中统筹考虑特征分布和分类准确率。改进后的模型架构如图7所示,原FaceNet模型输出的3个128维特征向量先通过特征拼接形成两个256维的拼接向量,再输入全连接层进行分类。特征拼接的具体方法如图8所示。
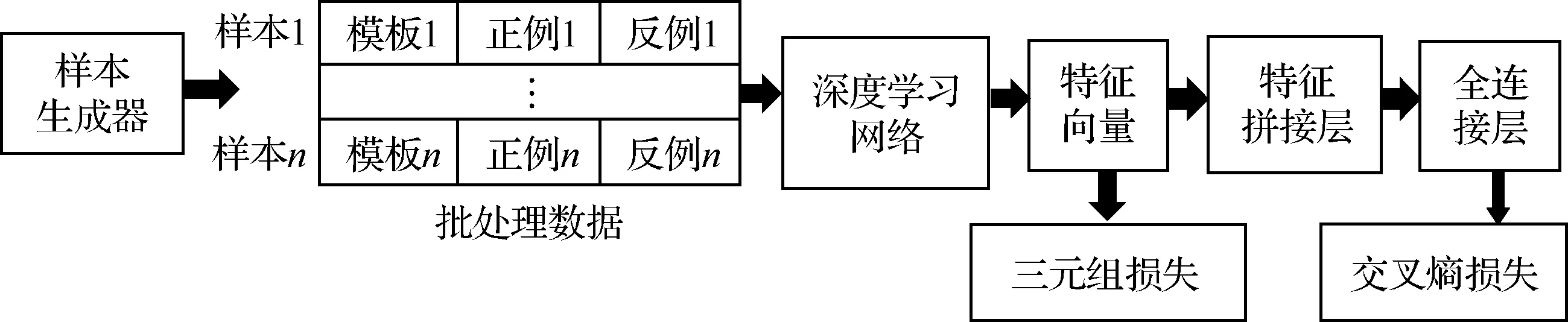
图7 基于改进FaceNet的裂纹识别模型架构Fig.7 Framework of crack identification model based on improved FaceNet
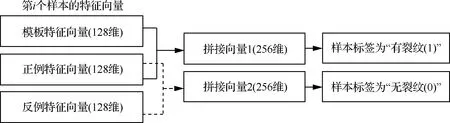
图8 改进FaceNet中的特征拼接方法Fig.8 Feature mosaic method in improved FaceNet
改进FaceNet模型的损失函数具体可表示为
Loss=triplet_loss+cross_entropy_loss=
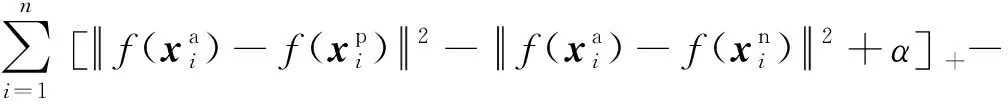

(2)
式中:cross_entropy_loss为交叉熵损失;为批处理数据中的分类样本个数,=2;表示第个样本标签的真值;1{=}表示样本标签真值为时,系数为1,其他情况系数为0;为分类层第个神经元的输出值。
2 试验设计与结果分析
2.1 试验设计
为丰富样本类型,本文使用的数据集由两类构成,第1类是全尺寸疲劳试验的实时检测图像(如图9(a)所示),这类数据的图像像素为2 000万,视场为200 mm×300 mm,物方分辨率为0.055 mm。裂纹为通过图像处理手段制造的模拟裂纹。该类图像共包括200个检测部位,每个部位有24张图像,所有图像均由机械臂采集系统在舱内巡检时自动拍摄,拍摄间隔时间为1 d,因此该类图像代表了全尺寸疲劳试验中待检测图像的质量水平。针对每个检测位置,从24张图像中随机选择10张添加模拟裂纹。
第2类样本是金属元件疲劳试验中的裂纹图像(如图9(b)所示), 这类数据的图像像素为200万, 视场为33 mm×50 mm,物方分辨率为0.026 mm, 与全尺寸疲劳试验图像为同一量级。

图9 疲劳试验中的数据获取方法Fig.9 Data acquisition method in fatigue test
通过15个试验件的疲劳试验共获取80个检测部位,每个检测部位包含25张无裂纹图像和12张真实裂纹图像,每张图像的拍摄间隔时间为2 s。由于元件疲劳试验中的试验件始终处于振动状态,所以各图像间会存在一定的光线和清晰度差异。
在280个检测位置中随机选择210个作为训练集、70个作为测试集。使用本文提出的改进FaceNet模型进行训练,深度学习网络的基础模型选择Inception V3,边界距离设置为0.05,优化器为Adam,设置一个批处理数据包含40个三元组样本,每200个批次为一个循环。经过2 100个循环后模型收敛,第2 100个循环的平均三元组损失为0,平均交叉熵损失为0.005。
图10所示为改进FaceNet模型在部分训练集上提取的128维特征的分布状态(通过主成分分析法降维至2维)。对比图6可知,图10中每个检测位置的类间距离(有裂纹图像到无裂纹图像的最小距离)均大于类内距离(无裂纹图像间的最大距离),特征分布的规律性明显增强。

图10 改进FaceNet提取裂纹特征的分布规律示意图Fig.10 Schematic diagram of distribution law of crack feature extracted by improved FaceNet
2.2 结果分析
针对测试集中的每个检测部位,随机抽取5个无裂纹待检测样本和5个有裂纹待检测样本,其中无裂纹样本由两张无裂纹图像组成,有裂纹样本由一张无裂纹、一张有裂纹图像组成,70个检测位置共获得700个检测样本。样本中待检测裂纹的长度从0.2~8 mm不等。使用训练好的改进FaceNet模型对700个待检测样本进行测试,测试结果中350个无裂纹样本均判定正确,350个有裂纹样本中有13个被判定为无裂纹,测试样本的整体检测准确率为98.1%,有裂纹样本的误判率为3.7%。对误判样本进行分析发现,13个样本来自4个检测部位,裂纹长度均小于0.6 mm 且处于裂尖(如图11所示)。该现象说明大尺寸裂纹更容易被检出,而小尺寸裂纹由于宽度小,检出难度较大,这与人工目视检查的经验相同。要提高小尺寸裂纹的检出概率,可结合试验场景,通过减小视场、增大物方分辨率等手段来实现。

图11 误判样本示例Fig.11 Example of misjudged samples
需要指出的是,在无裂纹样本的部分图像中,划痕的形态与裂纹相似度较高,当使用FasterR-CNN对这些图像进行检测时,划痕会被误判为裂纹。但使用本文模型进行检测时,即使待检测图像与模板的清晰度和亮度分布存在一定差异,也均能判断正确,其对比如图12所示。说明针对疲劳试验中的裂纹识别问题,相较于单帧目标检测算法,该模型优势明显。

图12 Faster R-CNN和改进FaceNet检测结果对比Fig.12 Comparison of Fasters R-CNN and improved FaceNet detection results
此外,本文使用相同的数据集对原FaceNet模型进行了训练,并分别使用线性计算阈值和单独训练一个两层分类神经网络的方法完成对训练集的分类,最后使用以上两个完整的模型对700个测试样本进行检测,其与改进FaceNet模型的性能对比如表1所示。
由表1可知,改进FaceNet模型的检测准确率明显高于原有模型的79.8%和91.7%,但由于进行了向量拼接,模型的复杂度提升,其在测试状态下的浮点运算数(FLOPs)明显增大,造成每秒可检测图片数量减少,该问题可通过提高硬件水平得到改善。

表1 改进FaceNet模型与原FaceNet模型的 检测结果对比Table 1 Comparison of detection results between proposed model and FaceNet
3 结 论
1) 本文提出了基于关键部位状态对比的裂纹识别策略,设计了基于改进FaceNet的裂纹检测模型,从而形成了一种基于机器视觉的面向飞机全尺寸疲劳试验的裂纹识别方法。
2) 本文提出的方法解决了由全尺寸结构与微小裂纹跨数量级的尺寸差异导致的裂纹难以被检测的问题,能够有效排除被检测结构表面广泛存在的划痕、污损等因素的干扰,实现了高准确率的裂纹识别。
3) 本方法裂纹识别准确率高的原因为:特征对比机制可有效避免划痕等干扰因素的影响;三元组损失支撑模型对比学习裂纹特征和图像质量差异;面向实际问题的模型架构和损失函数改进。
4) 本文提出的方法需结合工程经验才能缩小裂纹检测范围,为实现紧固件孔、非连续结构等应力集中区域的自动检测和定位,进一步的改进方向是进行单帧目标检测算法和特征对比算法的融合模型设计。
