面向旋翼飞机螺旋桨干扰的AM通信语音信号智能增强方法*
2022-07-30田斌鹏董文方周良辰
田斌鹏,董文方,张 昆,周良辰,文 飞
(1.航空工业一飞院,西安 710089;2.上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
旋翼飞机平台的语音通信过程中,飞机螺旋桨与机舱发动机等设备会对幅度调制(Amplitude Modulation,AM)语音信号产生复杂干扰。语音信号不仅会混杂着强烈的机舱噪声,并且信号传输也受到调制干扰,其语音整体感知质量和可懂度很低。语音增强利用音频信号处理相关技术,抑制音频信号中的噪声成分,提取纯净语音信号,以提高通信语音的整体感知质量和可懂度,达到改善语音通信的效果。因此,语音增强可作为语音通信系统的前端处理模块,用于提升系统的整体抗干扰能力,实现稳定鲁棒的语音通信。
语音与干扰噪声在信号特征方面有着明显差异,是实现语音增强的重要依据。语音信号一般为具有明显的多结构化特征的非平稳信号,而噪声根据具体情况可为平稳或非平稳信号,并不一定有特定的结构化特征。传统的语音增强主要采取无监督的数字信号分析方法,如谱减法、维纳滤波法等,一般都依赖于背景噪声的估计,噪声估计的精度直接影响语音增强效果[1]。常见的噪声估计算法,如最小值跟踪算法[2]和时间递归平均算法[3],可以有效估计具有平稳性的慢变噪声,但无法快速跟踪瞬变的非平稳噪声。然而,在真实的环境中噪声一般是非平稳的并且信噪比可能较低,传统算法增强后的语音质量甚至可能不如原始带噪语音,如噪声过估计引起的语音包络丢失,其实际应用效果不佳。
近年来,随着机器学习技术的发展,基于监督学习的语音增强算法不断被提出,各种机器学习模型[4-5]被用于挖掘带噪语音与纯净语音信号之间的关系,以达到抑制噪声、增强目标语音信号的目的。其中,基于深度学习的语音增强算法[6-8]受到了学者们的主要关注。相比于传统方法,深度学习具有优异的非线性建模能力,可更好地分析语音信号特征。基于深度学习的语音增强算法在降噪效果方面实现了极大的提升,同时具有更好的鲁棒性。在实际的非平稳噪声与低信噪比条件下,深度学习的语音增强仍可表现出较好的降噪效果。
针对旋翼飞机空地语音通信中复杂干扰与强噪声,本文采取基于深度学习的语音增强算法,充分利用深度神经网络挖掘语音信号特征,使用长短时记忆(Long Short-Term Memory,LSTM)网络联系语音序列的上下文信息,并通过大量带噪音频与纯净语音数据对,充分训练神经网络模型,最终实现高效鲁棒的语音增强。
1 旋翼飞机干扰与噪声分析
搭载于旋翼飞机的语音通信设备在通信过程中将受到复杂干扰。一方面,旋翼飞机机舱由于发动机、旋翼等存在强烈的噪声,其直接混杂在语音通信信号中;另一方面,飞机螺旋桨在转动过程中,会周期性地越过天线面,螺旋桨对语音通信的射频信号波束产生遮挡、反射效应,干扰语音通信,体现为在语音通信信号中产生一系列噪声分量。
以螺旋桨与发动机为主的机舱噪声以加性噪声的形式混合在通信语音信号中,可表示为
m(t)=x(t)+n(t) 。
(1)
式中:m(t)为调制信号,x(t)为通信语音信号,n(t)为机舱噪声信号。
幅度调制信号可表示为
s(t)=A[1+m(t)]cosωt。
(2)
式中:A为载波幅度,m(t)为调制信号,ω为载波角频率。螺旋桨对AM信号的影响,相当于引入了一个时变的幅度调制。受螺旋桨干扰后的AM信号可表示为
s′(t)=α(t)A[1+m(t)]cosωt。
(3)
式中:α(t)为螺旋桨引起的载波幅度调制系数,满足α(t)≥0且为周期信号。结合式(1),式(3)表示为
s′(t)=A[α(t)+α(t)x(t)+α(t)n(t)]cosωt。
(4)
螺旋桨引起的幅度调制α(t),其频率由螺旋桨转速和桨叶数决定,即
F=V×N。
(5)
式中:F为调制频率,V为螺旋桨转速,N为桨叶数。螺旋桨的周期性转动会引起辐射信号以角速率ω=2πF周期性变化。对应到频率,由于旋转桨叶的存在,辐射场产生了频谱扩展,在ω0±nω处产生了一系列噪声分量,这些噪声分量将选加在正常的通信信号上,可能会干扰正常通信。由于存在调制效应,当螺旋桨正常运转时产生的调制频率在有用载波频率周围产生一系列噪声分量。当通信信号解调之后,将在语音信号上叠加噪声分量。
2 深度学习语音增强
本文采取基于时频掩膜的深度学习语音增强算法,估计各个时频点的语音成分,并对噪声成分进行有效抑制,提高语音的整体感知质量或可懂度。典型的时频掩膜包括理想二值掩膜(Ideal Binary Mask,IBM)[9]、理想比值掩膜(Ideal Ratio Mask,IRM)[10]、谱幅度掩膜(Spectral Magnitude Mask,SMM)[11]等。本文测试了多种不同的时频掩膜,最终采用IRM作为目标掩膜。相比于IBM,IRM可更好地改善语音整体感知质量,并减少降噪带来的语音失真。相对比于SMM,IRM的掩膜值在0~1之间,更适合网络训练,加快模型收敛。另外,为了减小模型计算量,时频掩膜中不考虑相位信息[12],仅估计实数域的掩膜。
3 语音增强系统
3.1 模型描述
假定接收的带噪信号y具有T个采样点,即y∈RT,其可视为纯净语音信号x和噪声信号n混合而来,可表示为
y=x+n。
(6)
语音增强的目的在于从带噪信号y中提取语音信号x。由于时域信号特征难以直接利用,语音增强一般通过短时傅里叶变换(Short-time Fourier Transform,STFT)将时域观测信号变换到时频域,在时频域增强语音后通过逆短时傅里叶变换(Inverse-STFT,ISTFT)得到时域信号。
基于时频掩膜的深度学习语音增强可表示为
(7)

3.2 系统结构
基于时频掩膜的深度学习语音增强的系统结构如图1所示。带噪的语音信号在分帧与加窗后,通过STFT将时域信号变换到时频域。然后,将带噪语音的幅度谱将作为深度神经网络的输入,对各个时频点的语音掩膜值进行估计。网络输出的时频掩膜可理解为语音的存在概率或成分占比,其通过点乘原始带噪频谱,可获得增强后的幅度谱。由于语音相位信息对降噪效果影响较小,同时引入相位估计会极大增加计算量,本文直接采用原始带噪相位作为增强音频的相位,并结合增强的幅度谱,经过ISTFT得到增强后的时域语音信号。

图1 深度学习语音增强框架
上述过程中,语音增强的关键在于对时频掩膜估计,掩膜的性能直接影响到增强效果。深度学习语音增强通过深度神经网络优异的非线性建模能力,更加准确地估计时频掩膜,从而实现降噪性能明显优于传统算法。
3.3 网络结构
典型的深度神经网络结构主要包括共享层和特定任务层。共享层主要完成低层次数据特征的提取,特定任务层主要完成高层次的特定任务,如分类(classification)或回归(regression)。本文利用深度神经网络来训练带噪语音的时频掩膜,估计目标语音的理想比例值掩膜;使用语音掩膜增强原始带噪语音,增强后的信号频谱作为神经网络的预期输出。从语义的多层次结构角度看,共享网络层通过训练得到低层次的语义特征(如音节、音素等),而特定任务层通过训练得到高层次的语义特征(如字、词等)。
如图2所示,该深度神经网络采用多层感知器的结构:共享层由激活函数为ReLU的全连接层与LSTM层叠加而成,特定任务层由独立的激活函数为Sigmoid函数的全连接层构成。ReLU激活函数由于具有良好的稀疏性及梯度计算简单的优点,使得使用该激活函数的随机梯度下降算法收敛速度更快,从而成为隐藏层激活函数的首选。输出层的激活函数必须与训练目标匹配,掩膜的数值范围为0~1,因而选择Sigmoid函数。

图2 语音增强网络框架
共享网络层包含LSTM网络层,可以更有效地利用语音信号时间轴上的上下文信息。另外,选择使用时间轴上相邻c帧组成超级帧向量,每个超级帧中总共有(2c+1)帧(左边c帧,当前帧,右边c帧)。每个时刻的网络输入层的特征维度总共为
D=F×(2c+1) 。
(8)
式中:D代表网络输入,F是输入特征的频点个数,c是相邻帧数。由此可见,该深度神经网络输入特征的构造过程中,融合了音频信号在时间、频率两个维度上的信息,使得该DNN具备时频二维特征学习能力。
具体网络结构与参数如图3所示,输入层的特征维度为257×5,其中输入特征的频点个数为257,相邻帧数为2;而后连接两层LSTM,其输出维度均为200;并连接一层全连接层与ReLU层,其输出维度为300;最后连接输出层与Sigmoid层,输出维度与输入维度保持一致。

图3 语音增强网络结构与参数
3.4 网络训练
深度神经网络的模型训练与损失函数设计对性能有着重要影响。本文的语音增强网络训练结构如图4所示。

图4 语音增强网络训练
结合网络估计的语音掩膜与带噪幅度谱,获取增强后的语音幅度谱,通过将其与干净幅度谱对比,计算对应的均方误差(Mean Square Error,MSE),将其作为网络的损失函数用于训练。该损失函数具体可表示为
(9)

由于网络训练过程中需要使用对应的干净语音频谱与带噪语音频谱,而真实场景下采集的音频一般为带噪音频,且无法提取对应的干净语音,因而网络训练集采用了仿真数据,利用已有的干净语音与纯噪声,通过混合生成带噪音频。
另外,为了保证训练得到的模型具有更好的鲁棒性与泛化性,训练数据的带噪音频采取了多种噪声与多种说话人进行混合,使得训练数据的多样性大大增加,增强了模型对实际未知噪声与说话人语音的鲁棒性。
4 实验结果
4.1 仿真实验
本文设计了语音增强仿真实验来初步证实神经网络模型的降噪性能。利用大量纯净语音与纯噪声的人工混合,获取带噪语音信号。通过语音增强网络处理人工混合的带噪语音信号,并将增强后的语音信号与对应的纯净信号进行比较,分析和评估语音增强网络的降噪性能。本文从语音质量的感知评估(Perceptual Evaluation of Speech Quality,PESQ)和短时客观可懂度(Short-time Objective Intelligibility,STOI)两个指标来验证该模型的性能。
PESQ可对客观语音质量评估提供一个主观MOS的预测值,并可映射到MOS刻度范围,但其计算过程较为复杂,且同时需要带噪语音信号和纯净参考信号。PESQ的得分范围在-0.5~4.5,其分数越高表示音频质量越好。STOI作为另外一种语音客观评价方法,可用于衡量语音可懂度,其得分范围在0~1,分数越高表示可懂度越高,但其计算同样较为复杂,且需要带噪语音和纯净语音。
人工混合的带噪语音、增强语音以及纯净语音的幅度谱如图5所示。原始带噪语音中存在强烈的噪声干扰,噪声布满整个频谱,尤其在低频部分噪声更加恶劣,如图5(a)所示。通过本文提出的语音增强系统处理原始带噪信号,可得到明显增强的语音信号,其中噪声成分已经得到明显抑制,如图5(b)所示。尽管相比于纯净语音,增强语音还存在部分残留噪声,但其整体的语音质量已得到明显改善。本文为了更好地验证模型的降噪效果与鲁棒性,针对四种不同场景(公交车站、咖啡厅、步行街、街道)下的噪声,分别与语音信号混合,并进行了语音增强仿真实验,通过主流的语音评价指标PESQ和STOI来验证语音增强的效果。

(a)仿真带噪语音
另外,为对比不同深度神经网络的语音增强效果,本文分别以全连接网络(Fully Connected Network,FCN)与卷积神经网络(Convolutional Neural Network,CNN)为主构造了不同的网络模型,进一步验证了本文方法的优越性。不同场景和增强网络下带噪语音增强后的PESQ和STOI得分如表1和表2所示,其中第一行表示原始音频以及不同神经网络增强后的音频,第一列表示用于混合的不同场景噪声,即BUS表示公共交通噪声,CAF表示咖啡馆噪声,PED表示步行街噪声,STR表示街道口噪声。

表1 测试音频PESQ
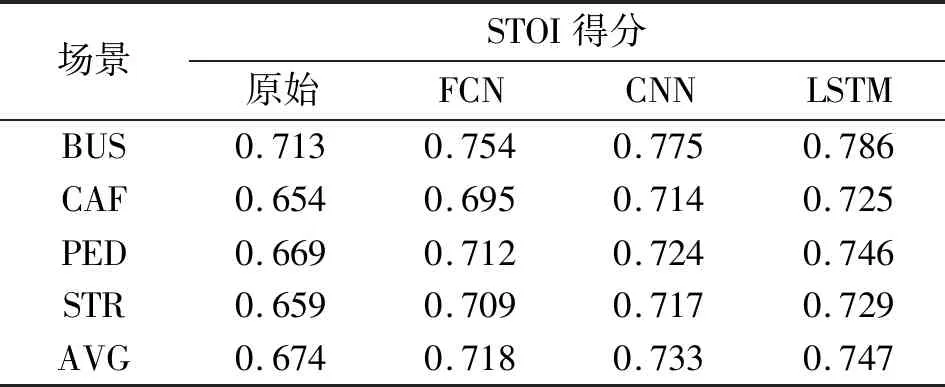
表2 测试音频STOI
从表1和表2的结果可看出,增强后音频的PESQ和STOI得分均有明显上升,表明经过语音增强后语音整体感知质量和可懂度得到明显改善,而本文采取的基于LSTM的语音增强网络取得了最大的提升。相比于基于FCN的增强网络,LSTM可以更好地挖掘音频上下文信息,获取更准确的掩膜估计,从而实现更优的降噪效果。相比于基于CNN的增强网络,由于CNN同样可以建模音频上下文信息,LSTM带来的提升不大,但CNN需要同时输入整段音频,难以实现实时语音增强,而LSTM可以通过调整未来帧数目逐帧输入音频,实现实时的语音增强。
本文语音增强系统时延主要由输入时延与运算时延两部分组成,输入时延为语音产生到输入网络的时间,运算时延为网络处理与输出增强语音的时间,其中输入时延占主要部分。相比于其他因素,系统中STFT与ISTFT造成的时延微乎其微,可不作考虑。因此,输入时延主要由输入帧的时长决定,在不使用未来帧的情况下其时延为单帧时长,但在使用未来帧的情况下其时延将对应增加。本系统的帧长为32 ms,帧移为16 ms,不使用未来帧情况下时延即为32 ms,但实际使用了两个未来帧,因而输入时延为64 ms。运算时延主要由网络参数大小以及设备状况决定,本系统的参数大致为2×106,在主流GPU机器上时延不超过20 ms。因此,本系统的语音增强系统时延在84 ms以内,可满足实时语音增强要求。
4.2 实测数据验证
前文通过仿真实验初步验证了本文实现的语音增强系统的有效性,为了更好地测试系统对实际旋翼干扰的降噪性能,本文使用某型旋翼飞机采集的真实带干扰和带噪语音信号,进一步测试系统对复杂噪声干扰的抑制效果。
真实采集的通信语音信号中存在多种干扰与噪声。在低频部分,如300 Hz以下,频谱显示存在强烈而稳定的干扰信号;在高频部分,一些结构性干扰会随机分布。除此之外,类白噪声干扰存在于整个频带,如图6(a)所示。综合来看,通信语音信号干扰复杂,对语音增强带来巨大挑战。图6(b)展示了增强后的语音幅度谱。通过提出的通信语音智能增强系统处理后,增强后的语音幅度谱结果表明噪声明显减少,多种干扰噪声均得到有效抑制,而语音信号得到了有效保留,其语音质量得到了极大改善。

图6 某型旋翼飞机AM语音信号增强测试结果
5 结 论
针对旋翼飞机螺旋桨对空地语音通信造成的复杂多频干扰以及恶劣机舱噪声,本文提出了一种通信语音智能增强方法,利用LSTM的网络结构挖掘语音上下文信息,采用深度神经网络估计语音的理想比值掩膜,并将掩膜信息用于增强语音信号。仿真实验与某型旋翼飞机实测数据测试处理验证了本文语音增强系统,能够有效抑制旋翼飞机的复杂干扰与噪声,改善语音通信质量。
