融合自注意力的卷积门控循环网络语音增强*
2022-07-30胡少东袁文浩时云龙
胡少东,袁文浩,时云龙
(山东理工大学 计算机科学与技术学院,山东 淄博 255000)
0 引 言
传统语音增强方法多基于统计学原理或噪声平稳的假设,在低信噪比(Signal-to-Noise Ratio,SNR)和复杂噪声环境下表现不佳。基于深度学习的时频域语音增强方法,其泛化能力和降噪能力相比传统语音增强方法有着显著提升[1]。由多层全连接层(Fully Connection Layers,FC)组成的前馈型深度神经网络(Deep Neural Network,DNN)最先被应用于时频域语音增强任务。文献[1]以对数功率谱(Logarithm Power Spectrum,LPS)作为DNN的训练目标,将含噪语音时频谱通过DNN映射到纯净语音的LPS,形成了从含噪语音到纯净语音的时频谱映射关系,提高了语音增强性能。但DNN忽略了语音时频谱中存在的时间依赖性和空间相关性,因此文献[2]提出了在时间维度对语音增强任务进行建模的循环神经网络(Recurrent Neural Network,RNN)。为提高RNN的长时序列建模能力,改进型RNN被提出,如长短时记忆(Long Short-Term Memory,LSTM)网络、门控循环单元(Gated Recurrent Unit,GRU)网络。文献[3]提出了一种基于LSTM的时频域语音增强模型,通过利用长时依赖关系进一步提高了语音增强性能。语音时频谱除时间维度中相邻帧之间具有时间依赖性外,在频率维度中频带之间还具有强烈的局部和全局的空间相关性。卷积神经网络(Convolutional Neural Network,CNN)具有提取输入特征局部空间相关性的能力[4]。文献[5]提出了用于语音增强的编码器-解码器结构的全卷积神经网络(Fully Convolutional Neural Network,FCN),以多帧时频谱特征作为网络输入。而文献[6]提出了一种包含CNN、池化层、FC的语音增强模型,提高了语音增强模型的泛化能力。受限于卷积核大小,基于CNN的增强网络只关注了较小范围的时频谱局部相关性,文献[7]通过空洞卷积提高了卷积关注时频谱局部相关性的范围,但仍无法关注全局相关性。文献[8]提出了串联RNN和CNN的编码器-解码器网络结构,网络使用CNN提取时频谱特征的局部相关性,使用LSTM提取相邻帧的时间依赖关系。但串联RNN和CNN的方法不能同时提取时间依赖性和局部相关性,且依然忽略了含噪语音时频谱中的全局相关性。
针对上述问题,本文首先借鉴GRU对时间序列的建模能力,以CNN代替GRU中的FC,构成卷积门控循环网络(Convolutional Gated Recurrent Network,CGRN),CGRN在对时间维度建模的同时可以提取频率维度中的局部相关性。但CGRN无法关注帧内的全局相关性,因此本文在CGRN中进一步引入借鉴人类注意力机制提出的自注意力(Self-attention,SA)[9],构成自注意-卷积门控循环网络(Self-attention-Convolutional Gated Recurrent Network,SA-CGRN),其中SA通过自注意力计算,能有效地关注输入信息的全局相关性。实验证明,SA-CGRN通过同时关注时间依赖性、局部相关性和全局相关性,显著提高了语音增强性能。
1 基于深度学习的时频域语音增强
基于深度学习的时频域语音增强是回归任务,其主要包含数据预处理阶段、训练阶段以及增强阶段。
1.1 数据预处理阶段
第一阶段是数据预处理。训练集的纯净语音和含噪语音经短时傅里叶变换(Short-time Fourier Transform,STFT)得到对应的频率谱,一帧频率谱Fl如下:
(1)
式中:Fl为第l时间帧的频率谱,Sl,k表示Fl中第l时间帧中第k个频带的特征值。由Fl可知,连续时域语音信号经STFT后在时频域内帧间具有时间依赖性,帧内k个频带之间具有空间相关性。
1.2 训练阶段
在训练阶段,本文时频域语音增强网络的输入x是含噪语音LPS特征,目标y对应含噪语音和纯净语音的幅度谱掩蔽特征,x、y计算如下:
x=ln(|Fnoisy|2),
(2)
(3)

(4)
以平均绝对值误差(Mean Absolute Error,MAE)作为网络训练的代价函数,通过梯度下降最小化如下代价函数:
(5)
式中:n为输入网络样本的Mini-Batch大小。
1.3 增强阶段

2 GRU
RNN与DNN这类独立处理每个样本的前馈型网络不同,其将输入样本视为一个时间序列,在样本可扩展的时间维度建模。由于传统的RNN在长时序列建模时容易发生梯度消失和梯度爆炸,LSTM和GRU通过引入门控机制来避免这一问题。GRU相比LSTM少一个门控结构,同一场景下GRU参数量更少易于训练和收敛。
一层GRU网络有序列时间长度个单元,第t单元在时序建模时,t时刻的输入特征xt和t-1时刻的单元态特征ht-1通过门控结构更新本单元的状态特征ht,因此GRU通过迭代可以捕获时间序列的长时依赖。图1(a)为GRU单元的结构图,图1(b)为GRU单元中FC的计算方式,可见GRU单元中门控计算和单元状态更新均经FC计算,在FC中每一个结点与其他结点进行全连接,参数量较大。

图1 GRU单元结构图
GRU单元中重置门rt和更新门zt的计算过程为
rt=σ(Wr[ht-1,xt]+br),
(6)
zt=σ(Wz[ht-1,xt]+bz)。
(7)
式中:“σ”是激活函数Sigmoid,“[]”为张量拼接,W#和b#分别为FC的权重张量和偏置。在本文的时频域语音增强任务中,xt是输入网络的LPS序列特征的第t帧。FC的权重张量W#与xt和ht-1的特征拼接张量做矩阵乘法加上对应偏置项b#,经Sigmoid激活后,便得到了rt和zt。
利用rt和zt,同时结合xt和ht-1来更新本单元状态。单元状态更新过程为
(8)
(9)
3 CGRN
由于GRU的门控计算和单元状态更新均经FC计算,无法提取帧内空间相关性,因此利用CNN提取局部特征相关性的能力改进GRU结构,同时CNN权值共享和局部连接特性相较于FC大大减少了参数量。本文利用CNN代替GRU中的FC构成CGRN,CGRN单元结构如图2(a)所示,CGRN单元中CNN的计算方式如图2(b)所示,可见进入CGRN单元的Xt和Ht-1经过填充后进行特征维度不变的卷积,区别于FC中的全连接方式,CNN的局部连接降低了网络参数量并可以捕获特征的局部相关性。因此,CGRN在捕获含噪语音时频特征长时依赖的前提下可以提取输入特征的局部空间相关性。融合CNN之后的CGRN的门控计算过程为

图2 CGRN单元结构图
Zt=σ(WZ*[Ht-1,Xt]+bZ),
(10)
Rt=σ(WR*[Ht-1,Xt]+bR)。
(11)
式中:“*”为卷积运算;b#为对应的偏置项,但与GRU中FC的权重不同,CGRN中W#为CNN的多通道卷积核,门控输入经卷积运算得到Rt和Zt。
为加速网络的收敛速度,将GRU中更新单元状态的激活函数tanh改为指数线性单元(Exponential Linear Unit,ELU)。CGRN的单元状态更新为
(12)
(13)
4 SA-CGRN
通过融入CNN,CGRN在时序建模的同时可以捕获输入特征的局部相关性,但受限于CNN卷积核的大小,CGRN仍无法捕获输入特征的全局相关性。人类注意力机制在全局复杂噪声信息中可以关注感兴趣声音,通过在CGRN中引入借鉴人类注意力机制提出的SA,关注输入特征的全局相关性,最终提出了SA-CGRN。SA通过计算查询(Query,Q)、键(Key,K)、值(Value,V)之间的映射关系关注全局相关性,其中Q、K、V为同一输入。计算SA时,将输入特征张量和其自身转置通过点击进行相似度计算得到注意力权重,为防止权重发散通常除以特征张量的维度。特征张量与经Softmax()函数归一化的权重值相乘,便得到了含有注意力信息的特征张量,从而关注输入特征中重要的全局相关性。
如图3(a)所示,在SA-CGRN单元中,需对Xt和Ht-1施加SA,SA-CGRN单元中的其他结构与CGRN保持一致。其中,对Xt进行SA计算的计算过程如图3(b)所示,将Xt通过多通道CNN映射到高维度特征空间得到XQ、XK、XV,其过程为
XQ=WQ*Xt+bQ,
(14)
XK=WK*Xt+bK,
(15)
XV=WV*Xt+bV。
(16)
然后,经自注意力层得到包含注意力信息的特征SAattention(Xt):
(17)
式中:T为矩阵转置;XQXKT为自注意力得分,为梯度稳定得分需除以XK的维度dXK,然后得分经Softmax()函数归一化后与XV相乘,以此来关注Xt中重要的全局相关性;最后,为防止特征丢失需加上Xt。同理,Ht-1也需经过上述变换得到SAattention(Ht-1)。

(a)SA-CGRN
5 实验
5.1 数据集
本文使用Voice Bank+DEMAND[10]数据集验证SA-CGRN的有效性。该数据集共有30个说话人录制的12 396条采样频率为48 kHz的音频。其中,28个说话人的11 572条音频作为训练集纯净语音,2个说话人的824条音频作为测试集纯净语音。训练集的含噪语音是纯净语音与来自DEMAND数据集的8种真实噪声和两种生成噪声,按照SNR为0 dB、5 dB、10 dB、15 dB合成得到。真实噪声为cafeteria、car、kitchen、meeting、metro、restaurant、station、traffic,生成噪声为ssn、babble。其中,ssn是通过与男性说话人长期语音水平相匹配的频率响应滤波器对白噪声滤波产生的,babble是Voice Bank中未被训练或测试使用的6个说话人语音。训练集含噪语音中噪声数量统计如图4所示,ssn噪声数量最多,但各噪声数量之间相差不大。同时测试集按照SNR为2.5 dB、7.5 dB、12.5 dB、17.5 dB合成含噪语音,可有效检验模型泛化能力。本文使用该数据集可减少数据集处理方法对网络增强性能的影响,进而更准确地验证SA-CGRN的有效性。
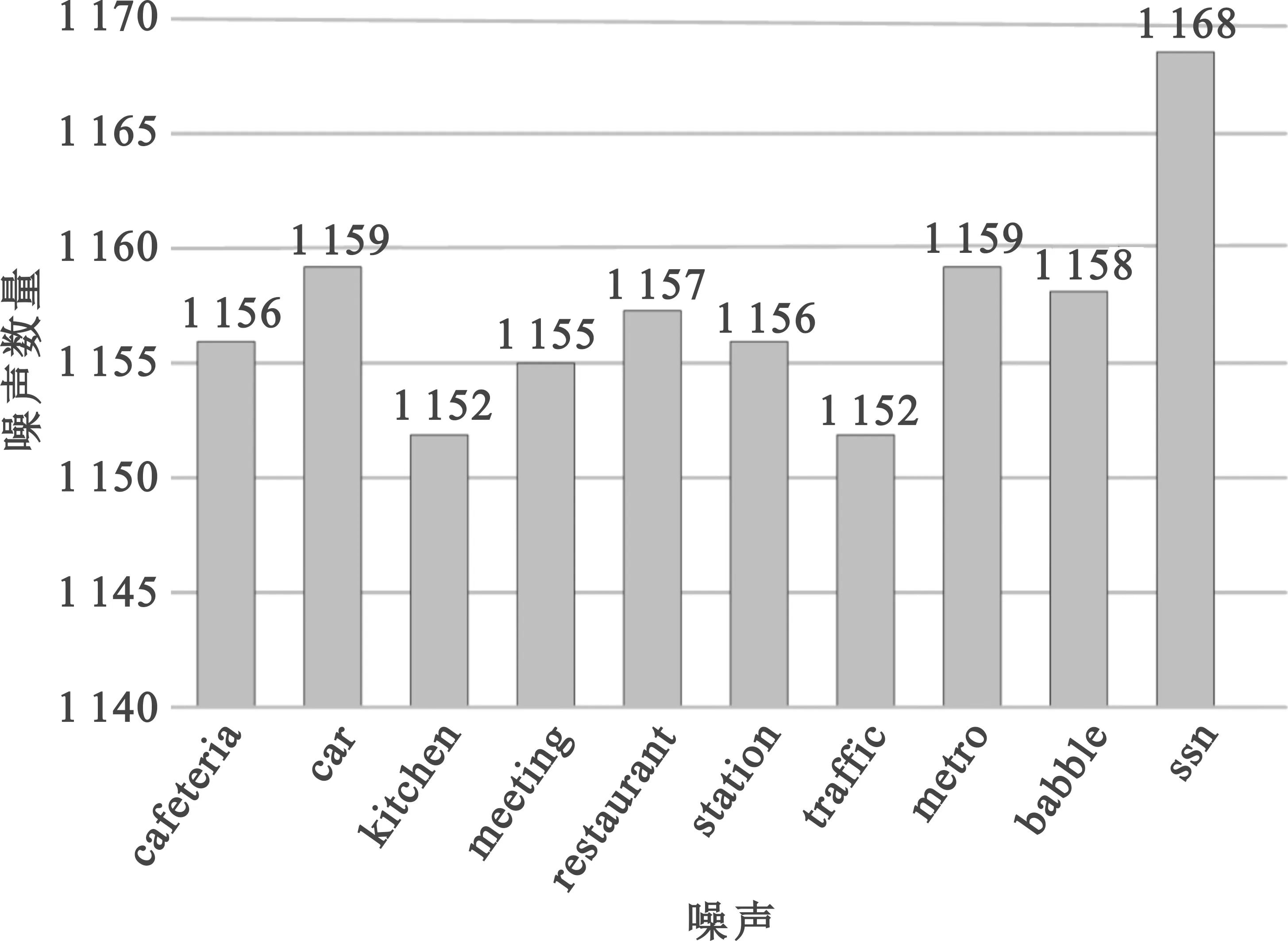
图4 噪声数量统计图
5.2 评价指标
本文以国际电信联盟电信标准化部门P.862建议书给出的语音质量感知评估(Perceptual Evaluation of Speech Quality,PESQ)[11]指标,同时结合语音失真评价(Speech Signal Distortion,CSIG)、整体质量评价(Overall Effect,COVL)、噪声抑制等级评价(Background Noise Intrusiveness,CBAK)[12]三种指标对语音增强模型性能进行量化分析。其中,PESQ得分范围为0.5~4.5,其余指标得分范围为1~5,得分越高表示语音增强模型相应的性能越好。
5.3 实验配置
为验证SA-CGRN在时频域语音增强任务中的有效性,将其与GRU、CGRN的语音增强结果进行对比。由于考虑到非因果网络实际应用的局限性,本文方法采用因果形式的网络结构。实验环境:CPU为AMD Ryzen7 1700,主机内存32 GB,GPU为NVIDIA RTX 2070 Super 8 GB,深度学习框架为PyTorch。本文GRU的隐层节点数和CGRN、SA-CRGN的隐藏层通道数、卷积核大小与文献[13]相同,但三种网络均采用5层顺序结构。
表1为SA-CGRN中SA和CGRN的模块结构,其中的模块和子模块与图3对应。表中3个超参数依次代表CNN的输入通道数、输出通道数、卷积核大小。每个模块的输入为C×H,其中C为通道数,H为频率特征维度。在SA中Xt和Ht-1经输入通道数为64,输出通道数为32的CNN进行降维映射,经注意力信息计算后再恢复特征通道数,得到SAattention(Xt)和SAattention(Ht-1)。
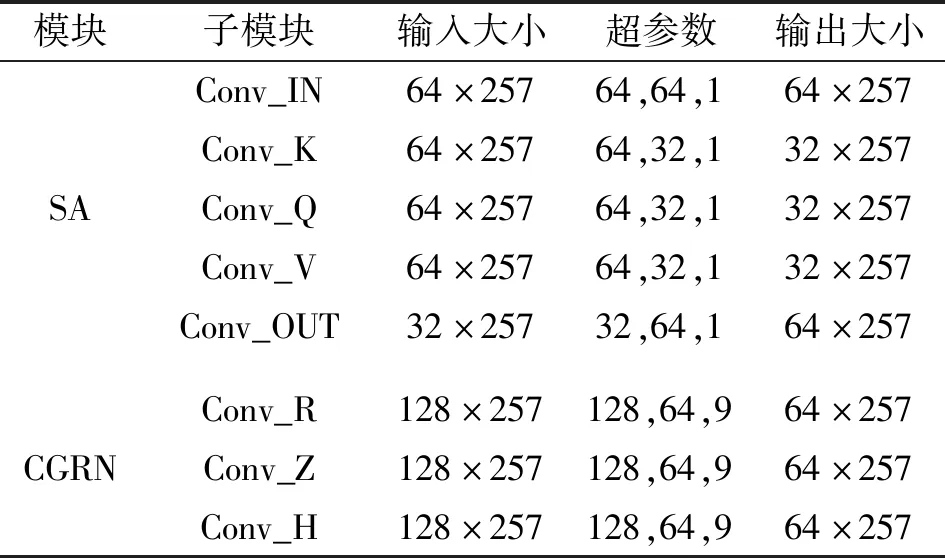
表1 SA-CGRN结构
同时为便于训练,在数据预处理阶段网络的输入和目标都被截取或填充成连续的1 s,三种网络的输入均进行全局均值方差归一化处理,纯净语音和含噪语音频率谱由采样频率为16 kHz的对应音频,经帧长为512点(32 ms)、帧移为256点(16 ms)的STFT得到。
5.4 SA-CGRN与GRU、CGRN的比较
表2为三种网络模型在四种评价指标下对测试集含噪语音进行增强的效果比较,可见基于GRU、CGRN和SA-CGRN的语音增强模型均明显地提升了增强语音的质量;三种语音增强网络模型中,SA-CGRN在所有指标下语音增强性能最好,CGRN次之,GRU的语音增强性能最低。上述结果表明,针对语音时频特征的多种特性对传统神经网络结构进行的优化,能适应时频域语音增强任务。
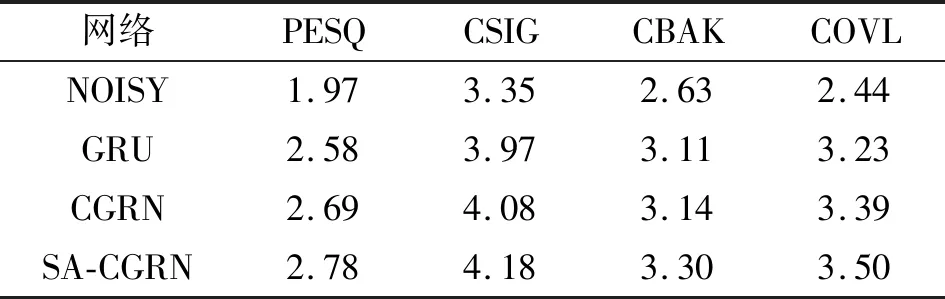
表2 GRU、CGRN及SA-CGRN的语音增强效果
基于语音时频特征特性提出的SA-CGRN,其首先通过对含噪语音的LPS特征在时间维度建模,关注含噪语音LPS帧间的时间依赖性;其次用卷积提取频率特征的局部相关性,使得SA-CGRN在关注时间依赖性的同时关注了频带间的局部相关性;最后通过SA对帧内频率特征进行自注意计算,提取频率的全局相关性。综上,SA-CGRN通过同时关注含噪语音LPS中的时间依赖性、局部相关性、全局相关性明显提升了语音增强性能。
表3所示为GRU、CGRN、SA-CGRN的模型参数量比较,可见GRU的网络参数量最多。这是因为GRU网络中的门控计算和网络更新需经FC,而CGRN和SA-CGRN经CNN进行门控计算和单元状态更新;SA-CGRN相比于CGRN,在没有明显增加参数量的基础上显著提高了语音增强效果。由此可见,SA-CGRN主要是通过对网络结构的优化来提高增强语音质量,而并非是通过增加网络参数量。

表3 不同网络的参数量
5.5 SA-CGRN与其他方法的比较
为了进一步验证SA-CGRN的有效性,本文与Voice Bank+DEMAND数据集上的其他语音增强方法在PESQ、CSIG、CBAK和COVL四种指标的平均得分下进行对比,结果如表4所示,可见在平均PESQ得分下,本文方法明显优于SEGAN[14]、MMSE-GAN[15]、MDPhd[16]、WaveNet[17]、DFL[18];在平均CSIG和COVL得分下,本文方法同样明显优于其他所有方法;在平均CBAK得分下,本文方法优于SEGAN、MMSE-GAN、WaveNet但稍弱于MDPhd和DFL;同时相比SEGAN、MMSE-GAN、MDPhd、WaveNet的非因果形式网络结构,SA-CGRN因果形式的网络结构在应用性方面具有明显优势。
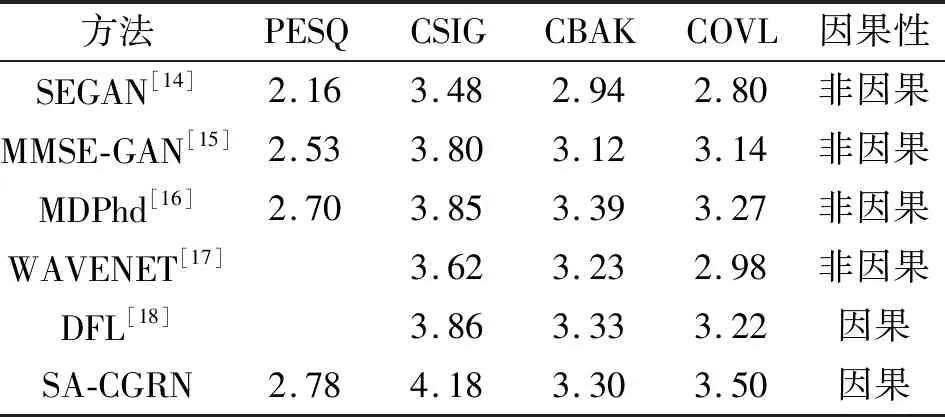
表4 SA-CGRN及其他方法的语音增强性能
6 结束语
在时频域语音增强任务中,GRU可以对连续帧在时间维度建模,捕获含噪语音帧之间的长时依赖关系,但由于结构限制,GRU无法捕获帧内的空间相关性。因此本文首先利用CNN代替GRU网络中的FC构成CGRN,该网络在时间维度建模的基础上可以提取帧内频带间局部相关性,提高了语音增强性能。但由于CNN受限于卷积核大小无法关注帧内频带间的全局相关性,本文进一步在CGRN的基础上通过引入SA提出了SA-CGRN。相比GRU和CGRN,SA-CGRN在捕获时间依赖关系的同时关注了帧内局部空间相关性和全局空间相关性,进一步提高了语音增强性能。在下一阶段研究中可以根据语音时域特征特点改进网络结构,以提高语音增强性能。
