国有企业并购完成率预测及其影响因素研究*
——基于数据挖掘和随机森林算法的分析
2022-07-29王言
王 言
(1 清华大学五道口金融学院, 北京 100083;2 华夏银行博士后科研工作站, 北京 100005)
一、引言
自1997 年9 月党的十五大报告第一次正式提出混合所有制经济的概念, 至今已有二十余年的历史。在此期间,党中央、国务院多次指出要积极发展混合所有制经济, 促进国有资本和社会资本交叉融合。2015 年9 月,国务院指出,在特定领域的国有企业,坚持国有资本控股,在没有明确规定的其他领域,鼓励通过并购重组进行股权比例调整。可见混合所有制改革及其改革动机实现的关键在于混改后国企的治理问题,而并购重组则是企业重要的外部治理机制(吴超鹏等,2011)。近些年在市场和混合所有制改革的政策引导下出现大量国企并购行为。 同花顺iFinD 数据显示,2017-2018 年, 沪深两市共发生国企重大重组涉及交易总体价值10003.1 亿元,2017 年就沪市而言, 国企并购重组金额就已超过5400 亿元。 2020 年是国企改革三年行动的开局之年,混合所有制改革实践进一步深化,国有资本布局进一步优化,67 家次深市国有控股上市公司披露控制权变更,全年实施重大资产重组23 家次,交易金额2437 亿元。
近几年实践发现,国企在如此大规模并购交易背景下,由于各种因素,很多企业超出自身能力范围盲目进行并购,导致并购未能完成。 有的在证监会批复前取消并购, 如2014 年5 月成飞集成发布公告称由于不可抗力或者双方以外的其他客观原因而终止并购交易协议;2017 年8 月博云新材召开董事会称:“经慎重考虑决定终止本次重大资产重组事项。 ”2022 年1 月金力泰发布公告称:“由于高登科技与公司未能就中科世宇后续经营运作、主营业务未来发展方向等方面达成一致意见,一致同意终止《股权转让协议》。”有的被证监会或交易所暂停、中止或取消,如2018 年11 月中国证监会决定终止对风神股份发行股份购买资产并募集配套资金暨关联交易事项行政许可申请的审查。 2021 年1 月ST 龙韵收到上海证券交易所上市公司监管一部下发的《关于对上海龙韵传媒集团股份有限公司收购股权暨关联交易事项的问询函》,公司与协议相关方一致同意终止本次收购资产暨关联交易事项。 在并购过程中,并购能否最终完成是并购双方最为关注的问题。 对于并购双方来说,能否成功完成并购交易体现并购过程的最终结果,直接关系到并购双方对于并购交易的期望(温日光,2015)。所以,研究影响并购完成与否的关键因素、预测并购完成情况从而规避并购风险、提高并购完成率具有十分重要的现实意义。
二、理论基础与文献回顾
(一)并购绩效的影响因素
现有文献从并购是否完成的视角进行研究的很少,大多是研究并购成功后的经济后果即并购绩效问题,而忽略了并购实施过程中失败的可能性。 对于并购绩效的影响因素分别从理论和实证两方面进行研究,其中实证是主流方向。
在理论方面, 国外学者研究较早,Jensen 和Meckling(1976)从代理理论出发,认为管理者为了追求自身利益而发动了并购,这主要是由于管理者和所有者的利益冲突所致,管理者为了分散个人风险往往会通过多元化并购的方式实现,但基于此目的并购绩效仍需商榷。 Ruback 和Jensen(1983)认为,并购中存在管理效率差异,主并购方、标的方、出让方之间的管理效率差异是推动并购的原动力,也被称为并购Q 理论。 刘峰等(2004)指出,国企偏好将盈利性较好的资产剥离上市,留在母公司的资产质量较差,直接影响了企业并购绩效。邱金辉和王红昕(2006)按照并购动机、并购行为、并购绩效的逻辑顺序,探索并购理论在我国的发展和研究方向,对于非国有企业,并购是一种逐利行为,而对于国有或国有控股企业来讲,并购还反映了政府意志,即政府制定了许多财政、税收优惠政策鼓励并购。
在实证方面,国外学者Bruton 等(1994)发现,在财务困境时候并购,并购经验对绩效的感知测量是正效应。Shahwan(2004)的研究表明,并购商誉与上市公司市场价值之间显著正相关。 国内学者李善民等(2004)分析发现,支付对价是影响并购绩效的主要因素。 陈芳和景世民(2007)则研究了资产结构,包括资产周转率、流动比率与并购绩效的关系。 蒋璐(2009)认为, 监事会对提高公司并购绩效的作用有待加强。翟进步等(2011)指出,债务融资降低了收购公司的市场绩效。郭妍和张立光(2011)则发现,成长性、盈利能力是银行并购绩效的重要影响因素。余鹏翼和王满四(2014)的研究发现,现金支付方式、第一大股东持股比例对中国企业跨国并购绩效具有显著正向影响。周绍妮等(2017)的研究表明,在国企的关联并购中,机构投资者提高并购绩效的治理的作用不再显著。王艳和李善民(2017)通过实证分析表明,主并方社会信任度越高,越有利于提高并购价值创造能力。 雷卫和何杰(2018)分析发现,内部控制对国企并购后绩效影响小于民营企业。宋贺和段军山(2019)研究证明了并购财务顾问会降低并购绩效。
(二)人工智能算法在经济领域中的应用
人工智能算法近年来被广泛应用于现代经济金融服务中, 与传统研究事物关系型的回归分析相比,人工智能算法可以对未来情况进行预测。将人工智能算法引入并购领域,本文尚属首次。
现有文献针对价格、商务、金融等经济问题利用机器学习和深度学习算法进行了预测研究。 Paolella和Taschini(2008)利用GARCH 模型对碳价格进行了预测且预测值与实际值较为接近。 Wang 等(2013)运用支持向量机预测交通速度数据,从模型复杂性和预测精度两方面来看具有一定优势。赵峰和张杰(2014)构建了马尔可夫转换模型预测违约风险溢价。 Zhang等(2016)研究了P2P 网络借贷风险预警,发现决策树效果明显。万昊等(2017)借助BP 人工神经网络模型,通过有监督的机器学习来对项目评审专家组的决策进行打分预测。张若雪(2018)探索利用无监督机器学习算法, 自动识别货币市场质押式回购交易异常波动。 张斌儒等(2018)构建BA-SVR@CSQ 混合模型对酒店平均入住率进行预测。刘美霖等(2018)构建神经网络和STARMA 的时空序列混合模型预测未来发生犯罪的数量变化。 刘金全和张龙(2019) 基于TVPFAVAR 模型测算中国FCI,发现MF-FCI 和经济增长的因果关系在混频Granger 检验下更密切。 祁凯和彭程(2019)基于OCS-EGM 算法构建覆盖网络集群行为在各个阶段的监测及预警模型。 肖艳丽和向有涛(2021)将债券发行主体是否发生违约作为企业债券违约风险变量,搭建了基于GWO-XGBoost 的债券违约风险组合预警模型。
随机森林算法是重要的人工智能算法, 处理问题效率很高,近年来被广泛应用于预测问题研究中。国外学者Kampichler 和Singh(2010,2013)比较5 种机器学习算法后发现随机森林预测效果最好。Markus(2016)利用Sentinel-2A 影像的光谱特征,使用随机森林进行了树种和农作物分类预测研究。 国内学者原欣伟等(2017)以小米社区MIUI 论坛为例提出基于随机森林分类的领先用户识别方法。 陈光慧等(2018) 利用随机森林模型研究了影响劳务众包APP平台上任务完成率的因素。 陈标金和王锋(2019)通过比较4 种模型的预测精度发现随机森林算法对国债期货指数预测能力最强。 陈丹玲等(2019)运用随机抽样Bootstrap 法构造耕地利用效率测度随机森林模型, 结果表明模型不受量纲限制, 运行所需参数少,过程简化,准确率高。 王超等(2019)运用多元线性和随机森林回归方法探索西藏人口分布影响因素及其差异。
(三)文献述评
综上所述,现有文献对并购绩效问题进行了大量理论和实证分析, 而忽略了并购实施过程中能否成功完成的问题;针对价格、商务、金融等经济问题利用人工智能算法进行了预测研究, 但还没有针对并购重组问题引入预测模型。 人工智能算法为传统计量方法不能解决的预测问题提供了基础。 随机森林模型是目前应用最广泛的机器学习模型, 属于机器学习中的提升算法,本文研究数据量少,适用机器学习而不是深度学习模型。 基于上述两点,本文首先选取沪深两市A 股国有上市公司2014-2020 年并购事件,然后建立国企并购完成率评价体系,利用同花顺iFinD 和Python 网页、文本提取和抓取数据,并将所有数据归一化处理后进行初步显著性和相关性分析,接着运用Logistic 回归模型(LR)对影响因素进行实证检验,最后基于随机森林算法(RF)构造预测模型对国企并购完成率进行预测, 并将该模型与其他经典机器学习模型决策树(DT)、朴素贝叶斯(NB)、支持向量机(SVM)和传统LR 进行比较,观测其预测精度。 本文探索融合多种影响因素数据,利用机器学习方法构建国企并购完成率预测模型, 有利于国企在并购行为中早防范、早发现、早干预,从而更有效地开展并购活动。
三、模型设计
(一)Logistic 回归模型
本文考察国企并购完成率与可能影响因素之间的关系,如当年国企并购完成,则定义“y=1”;反之,则定义“y=0”。 设p 为完成的概率,则未完成的概率为1-p, 国企并购完成与未完成的比率被称为机会比(odds ratio),即,取自然对数,即对p做Logistic 转换后)的取值范围为(-∞,+∞),所以Logistic 回归模型是以取自然对数机会比为因变量,以影响因素为自变量,具体如式(1)所示:
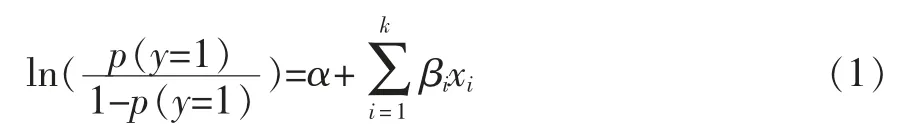
其中,xi表示影响国企并购完成率的第i 个解释变量,k 为解释变量个数,α 为截距项,βi为系数,反映该变量对国企并购完成率的影响方向及程度,用最大似然估计法求得。将(1)式两边取指数函数,则国企并购完成率的Logistic 回归模型的表达式为:

也等同于

其中,eβi反映xi每变化1 个单位所引起的事件发生比变化的倍数。
此外,Logistic 回归模型既可以研究关系型问题,也可以对未来进行预测。 本文主要利用Logistic 回归模型进行关系型研究,针对预测部分,主要将其与随机森林预测模型做对比实验。
(二)随机森林模型
决策树(Decision Tree)是通过对数据反复二分进行回归或分类,从而评估、预测项目风险和可行性的一种决策方法。 随机森林(Random forest)由多个决策树组成,其可以汇总随机化数据和变量后生成的多棵决策树的结果(李欣海,2013)。 具体构造过程如下。
1.抽取样本形成训练集
假设有M 样本, 按照一定比例采取有放回连续从M 样本中抽取M 次,形成一个训练样本集,没有被抽中的称为测试样本,用来评估模型性能。
2.建立决策树模型
假设有N 个样本属性,在训练样本中随机选择n个最优属性进行分支,构建决策树模型,分支过程即为决策树生长过程。
3.建立随机森林模型
重复(1)和(2)步骤M 次,得到M 个训练集和测试集,形成M 棵决策树组,即构成随机森林。
4.利用随机森林模型预测
根据随机森林分类器对测试集进行预测,对每棵决策树的预测结果进行汇总,最终选择预测最多的分类结果。 分类公式为:

其中:xi表示第个测试样本同时具有n 个属性特征,hi(xin)表示第i 棵决策树的预测结果;m 表示预测最多的分类结果;n_tree 表示决策树的个数。 随机森林算法流程如图1 所示。
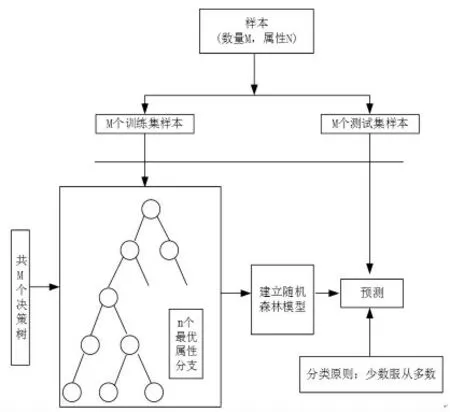
图1 随机森林算法流程示意图
(三)预测结果评价指标
对分类问题的预测结果评价指标有召回率(recall)、查准率(precision)、准确率(accuracy)、F1 score和AUC 面积等。
1.混淆矩阵、召回率与查准率
在衡量模型预测结果时,通常采用混淆矩阵对结果进行区分,具体如表1 所示。 TP 代表实际积极认为积极,FP 代表实际消极认为积极,TN 代表实际消极认为消极,FN 代表实际积极认为消极。

表1 随机森林预测模型的混淆矩阵
则召回率定义如下:

表示实际为积极样本被正确预测为积极样本所占的比例。
查准率定义如下:

表示预测积极样本被正确分类占被分类为实际积极样本的比例。
准确率定义如下:
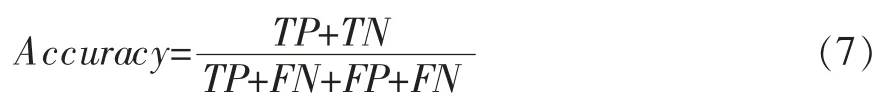
表示所有样本被正确分类的比例。
2.F1 score 和AUC 面积
使用F1 score 评价综合预测能力,F1 score 计算如公式(8)所示,即为查准率与召回率的乘积除以两者和的二倍。当两者其一值比较小时F1 会急剧下降,是查准率与召回率的加权体现。 根据定义,F score 的取值范围在[0,1]区间,取值越大,表明模型的预测能力越强。
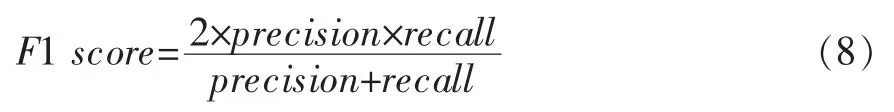
由于国企并购完成率的样本为非平衡数据,所以需要同时将AUC 面积作为评估指标之一 (Janitza et al.,2013)。 AUC 取值范围在[0,1]区间,AUC 值越大,面积越大,模型预测能力越强,其计算公式为:
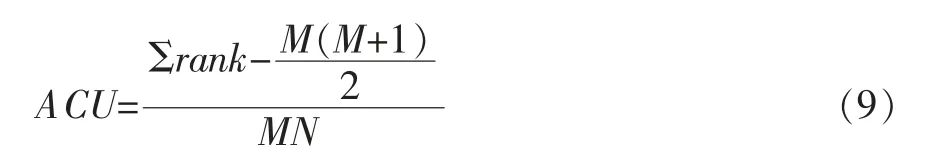
其中,M 为积极类样本的数量;N 为消极类样本的数量。
(四)国企并购完成的界定和影响因素分析
本文确定国企并购完成的方法为,在当年国企并购样本中找到完成、未完成标签,即为本年国企并购完成与未完成样本。明确影响国企并购完成率的关键因素是进行完成率分析和预测的重要前提。在综合分析了现有文献有关影响并购及国企并购绩效的因素,借鉴中关村国睿金融与产业发展研究会评价上市公司指标体系,考虑数据可得性之后,总结了包括企业资产结构、创利能力、价值再造、法人治理、外部监管、并购事件特征共同作用六大系统共26 个影响国企并购完成率的指标,具体如表2 所示(表中列示的每一个三级指标同时析出了支撑文献)。
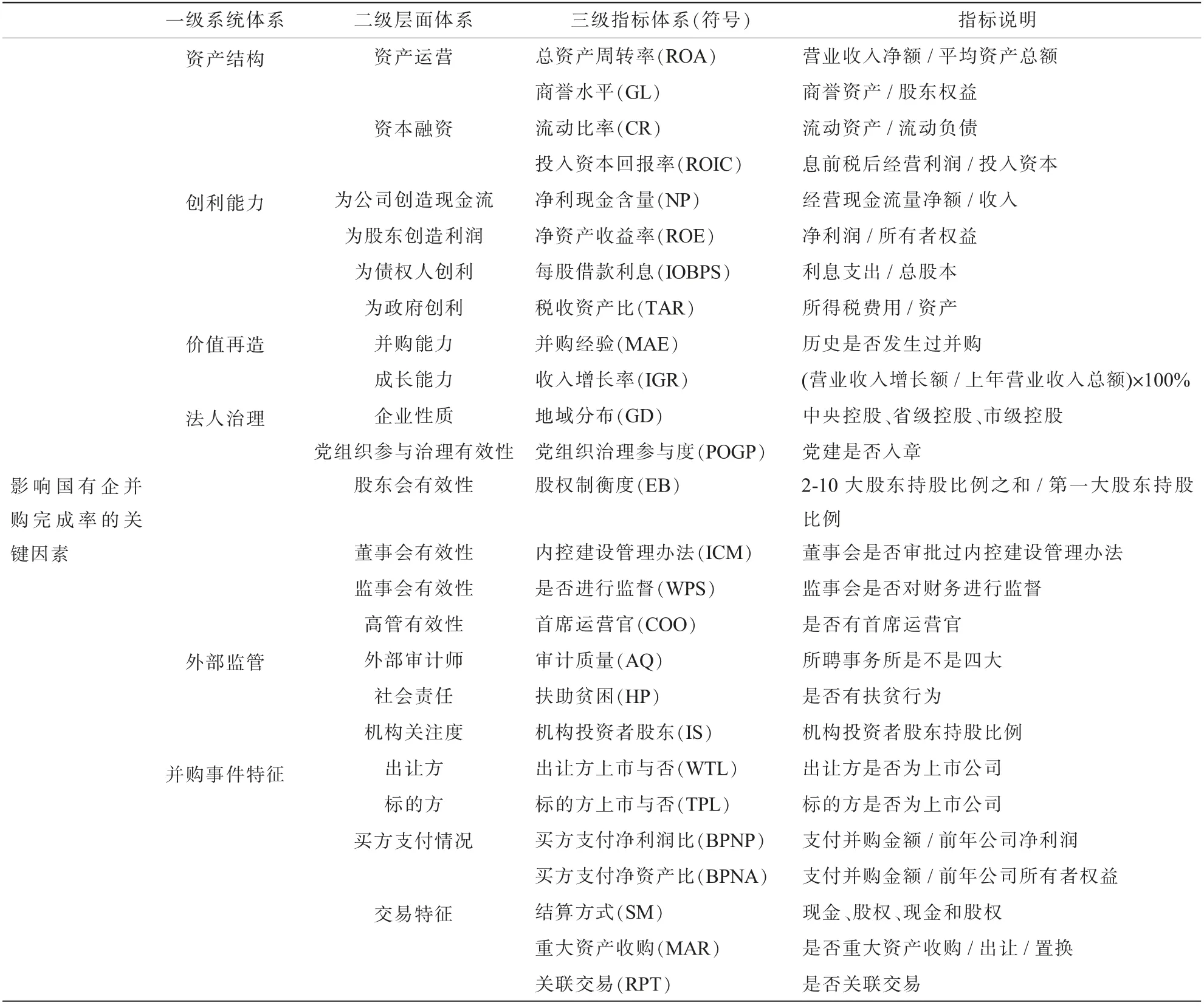
表2 影响国企并购完成率指标评价体系
四、实验过程
(一)数据选取及处理
1.并购事件
本文基于同花顺iFinD 数据库选取沪深A 股国有上市公司2014-2020 年并购事件为研究样本,并购收购标的为股权,剔除资产剥离、资产置换、资产收购、债务重估以及吸收合并等广义并购形式。 由于承债和无偿的收购支付结算方式样本很少, 所以删去,保留现金、股权、现金和股权三种收购方式。经过以下筛选和处理最终得到555 条并购样本:①首次公告日实际控制人为国务院、地方国资委或其他具有政府机构性质的行政机关、事业单位、国有企业等研究对象,不包括国有股东为第一大股东但无实际控制人的并购交易1例如,2014 年的万科A(000002.SZ,2014 年底第一大股东为华润股份有限公司,持股比例14.97%)。;②上市公司为收购方的样本;③剔除并购交易正在进行中的样本;④剔除金融类企业;⑤剔除被特别处理(ST)的样本;⑥剔除关键研究数据不全或缺失的样本。
2.指标数据搜集
在国企并购完成率指标评价体系中,除系列财务数据外,很多治理、监督指标数据不能直接从数据库获得,这些指标获取难度大且可能会对国企并购完成率分析及预测产生很大影响。 所以,本文首先利用同花顺inFnD 数据库提取部分直接可获得数据,然后基于扎根理论(Grounded Theory)(郭宇等,2018),利用文本挖掘(textual mining)(温有奎等,2019)和网络爬虫(web crawler)(韩贝等,2019)技术,通过词典法列出指标关键词, 根据Python 和正则法则进行匹配,抓取了不易获得的上市公司一手数据。详细操作过程如图2 所示。

图2 基于扎根理论的文本挖掘和网络爬虫抓取数据分析框架与流程
在进行抓取数据前, 还需制作指标抓取具体规则,即需求文档。 针对不可直接获得的6 项指标数据(POGP、ICM、WPS、COO、AQ、HP) 的需求文档总结如表3 所示。
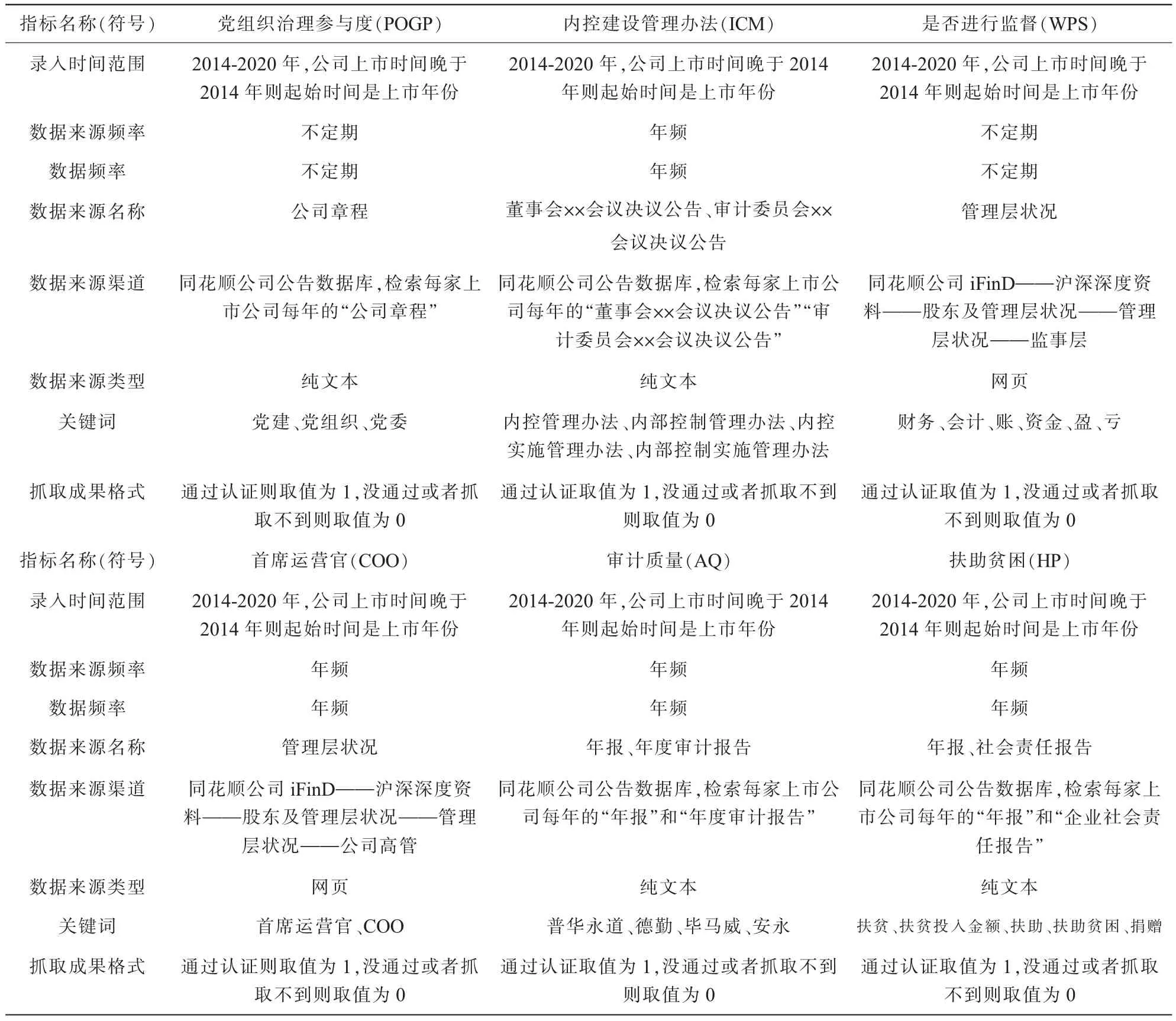
表3 利用正则法则和python 抓取网页和文本数据的需求文档
3.非连续属性值和归一化处理
属性值处理即非数值属性的数值化, 本文26 项指标中非数值属性数据都属于属性值之间有趋势的文本属性。 其中,MAE、POGP、ICM、WPS、COO、AQ、HP、WTL、TPL、MAR、RPT, 采用0 和1 量化的方法进行取值,若是则取值为1,反之为0;SM 为现金、股权、现金和股权,分别取值1、0.5、0;GD 为国企中央控股、省级控股、地市控股,分别取值1、0.5、0。 由于有些连续数值规模较大,对收敛速度有很大影响,所以为了使各项指标间具有可比性以及模型的预测结果更加准确,本文利用Python 软件按照归一化公式对各项连续指标进行归一化处理。
(二)并购地域统计
如图3 可知,广东、北京、上海分别是所选取国企并购样本发生次数的前三名,由此可见,国企并购与当地经济发展水平之间具有高度相关性。
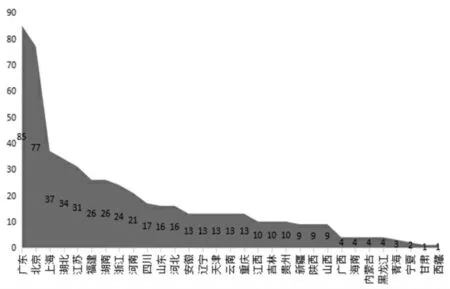
图3 各省(区、市)并购发生的事件数(不包括港澳台)
(三)显著性和相关性分析
1.显著性检验
由于国企并购完成(377 个)和未完成样本(178个)存在显著差异,因此,必须检验指标对于两类样本是否存在显著差异以进一步选取指标。本节所有操作均通过SPSS 20.0 软件得出。
(1)样本数据的正态性检验。表4 列示了Kolmogorov-Smirno(K-S)和Shapiro-Wilk(S-W)正态分布检验结果。 由表4 可知,在完成组中,不管是K-S 还是S-W检验显著性水平都为0.000 且小于0.05, 即不符合正态分布;在未完成组中,除机构投资者股东外的显著性水平都为0.000 且小于0.05,机构投资者股东在KS 检验中显著性水平虽然为0.200 且大于0.05, 但在S-W 检验中显著性水平为0.080 且小于0.05,还考虑到该变量在完成组中的非正态分布状况,所以该组同样不符合正态分布。 因此,13 个连续变量应选择非参数检验方法验证相关性。
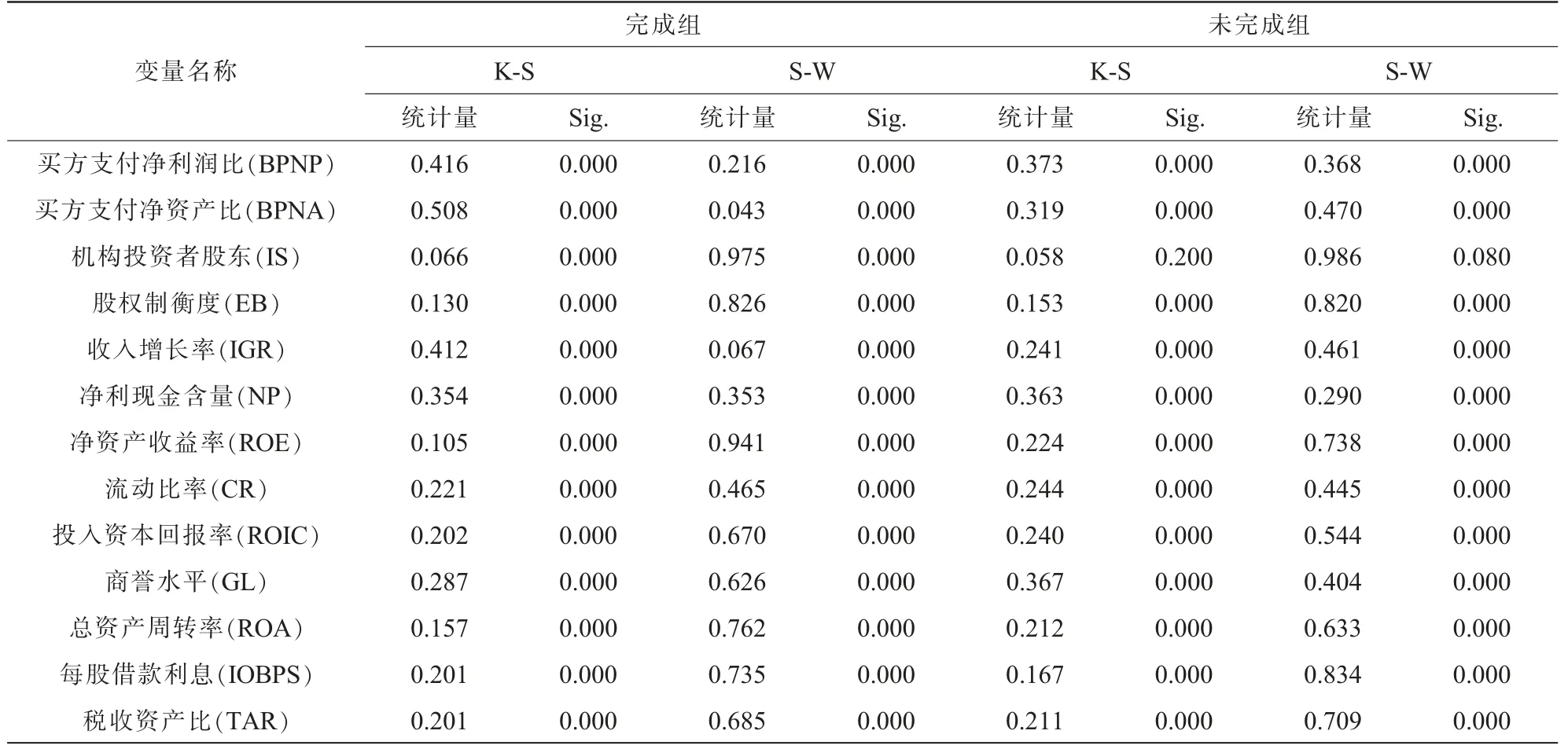
表4 单样本K-S 和S-W 检验结果
(2) 非正态分布连续变量Mann-Whitney U 检验。本文采用P 值0.05 的显著性水平为临界值判断变量是否显著。 从表5 受检验的13 个变量可知,有8 个变量在完成组和未完成组之间显示出了差异性, 即显著性水平小于0.05; 在其余5 个变量显著性水平均大于0.05,即完成组和未完成组之间没有明显的差异性。
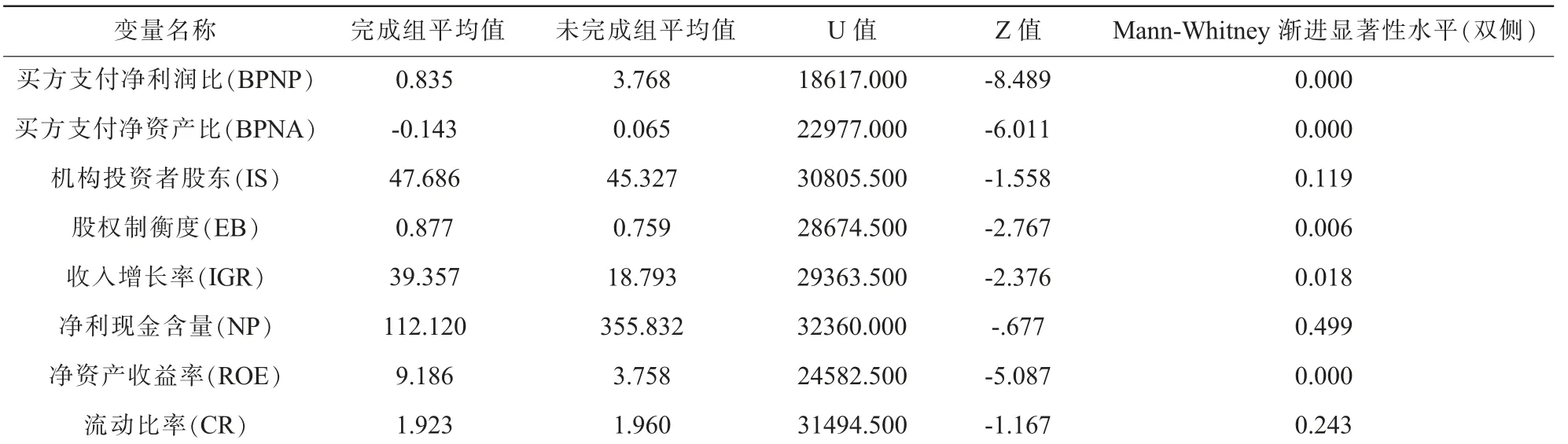
表5 连续变量差异的Mann-Whitney U 显著性检验

数据来源:本文整理。
(3)非正态分布分类变量卡方检验。由于GD、POGP、COO 变量中存在频数小于1 的项,因此其显著性检验观察Fisher 精确检验Sig 值(双侧);TPL、HP、AQ 变量中存在频数大于或等于1 且小于5 的项,因此显著性检验观察连续校正渐进Sig 值(双侧);其余变量中存在频数大于或等于5 的项, 因此显著性检验观察Pearson 卡方渐进Sig 值(双侧)。表6 列示了分类变量差异的卡方显著性检验,结果显示有7 个变量显著性水平小于0.05,即具有有显著性影响,其余6 个变量显著性水平均大于0.05,即没有显著性影响。
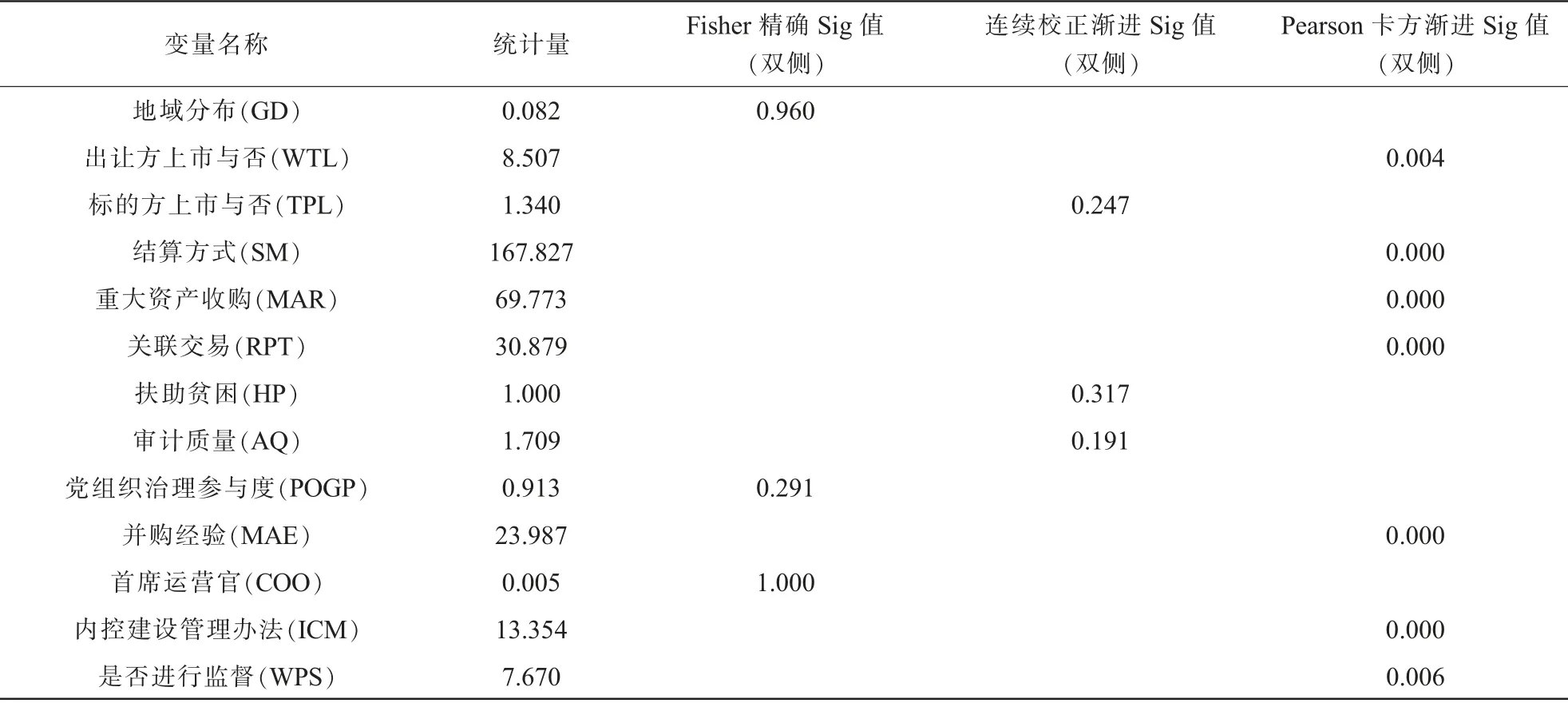
表6 分类变量差异的卡方显著性检验
2.相关性分析
本文同时选用Kaiser-Meyer-Olkin (KMO) 统计量、Bartlett's 球形、Pearson 和Spearman 相关性矩阵以及方差膨胀因子(Variance Inflation Factor,VIF)四种方法进行相关性验证。其中,由表7 可知,在Bartlett 的球形度检验中,Sig 值为0.000, 小于0.05, 但KMO 值为0.558,小于0.6,表明变量不太适合因子分析;由表8 可知,VIF 最大值为2.272,均值为1.432;由表9 可知,变量之间的相关系数都小于0.65。所以,综上四种方法说明变量间不存在多重共线性的干扰, 并且变量选取合理。 本节所有检验均通过SPASS 20.0 软件得出。

表7 KMO 和Bartlett 检验

表8 方差膨胀因子检验
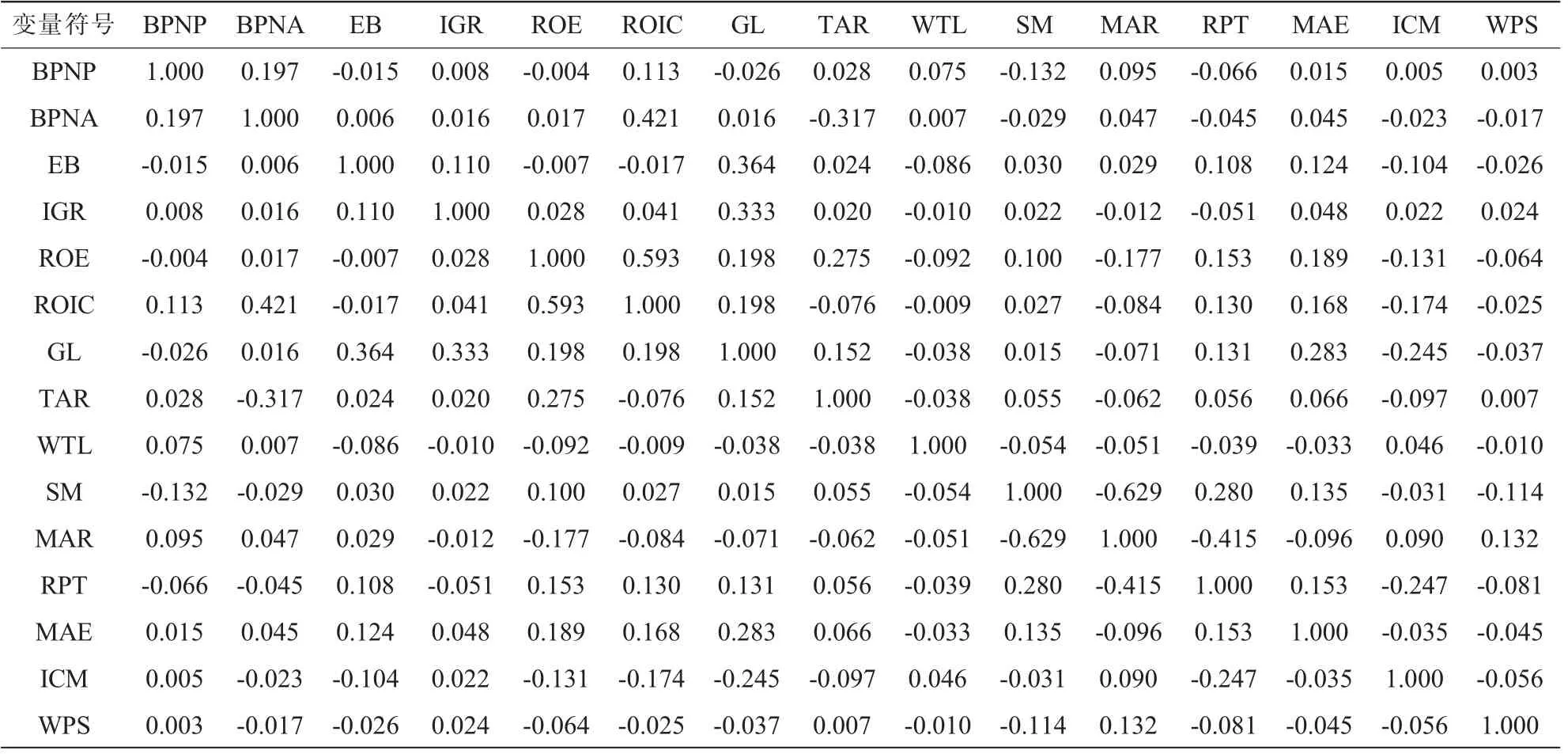
表9 变量相关系数矩阵
五、实验结果分析
(一)Logistic 回归检验结果与分析
1.模型估计结果
利用SPSS 20.0 统计软件对经过初步显著性检验得到的影响国企并购完成率的15 项指标进行二元Logistic 回归分析,结果见表10。由表10 可知,模型系数的综合检验步骤/块/模型显著性概率为0.000,通过了5%的显著性水平检验,模型在统计上是有意义的。此外,用Hosmer-Lemeshow 拟合优度检验来检验模型的拟合优度,卡方值为13.188,自由度为8,显著性概率为0.106,大于0.05,这表明该模型的效果非常好,自变量提供的信息能较好地解释因变量。

表10 Logistic 回归模型估计结果
由表10 得出以下模型:
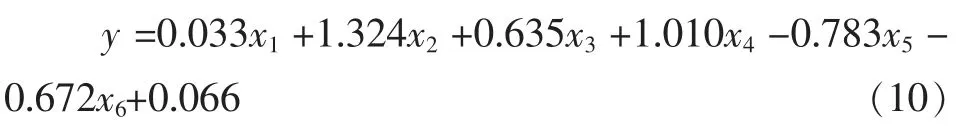
即Logistic 回归模型为:
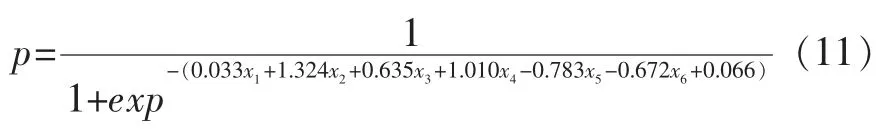
2.结果分析
通过初步变量差异显著性检验和进一步LR 回归检验,得到以下结论:
(1)创利能力中净资产收益率(=0.033,p<0.05)对国企并购完成率具有正向显著作用,并购公司净资产收益率越高,越有利于国企并购成功完成,即净资产收益率每提升一个单位, 并购完成率相应提升0.033倍。净资产收益率是公司经营管理业绩的较为理想的衡量标准,净资产收益率越高,表明公司经营管理业绩越突出, 越容易被并购双方和其他利益相关者接受。
(2) 并购特征中出让方上市与否(β=-1.010,p<0.05)、重大资产收购(β=-0.783,p<0.05)对国企并购完成率具有负向显著作用, 而结算方式 (β=1.324,p<0.01)对国企并购完成率具有正向显著作用,即出让方为上市公司相比非上市公司对并购完成率降低约50%, 并购事件为重大资产收购要比非重大资产收购对并购完成率降低21.7%, 并购结算方式以现金结算相比股权、现金和股权对并购完成率提高1.324 倍。这是由于一般公司的并购实施起来相对容易,并购双方就可以决定交易成败,上市公司的并购则不同,交易变量和约束条件均大大增加,证券监管部门、行业主管部门、 公众股东都成为并购交易中的重要角色,证券法律法规、第三方机构意见、媒体舆论都会不同程度地影响交易进程, 还有牵涉极为广泛的公众利益。此外,如果并购交易还涉及重大资产收购、出让和置换,则更是难上加难,使得并购完成概率大大降低。 现金结算方式有利于国企并购的完成是由于现金结算方式是公认为更容易被接收的一种并购结算方式。
(3)价值再造中历史是否发生并购(β=0.635,p<0.01)对国企并购完成率具有正向显著作用,即历史发生过并购的公司相比未发生并购的公司对并购完成率提高0.635 倍。 一些学者已经发现并购经验与并购绩效之间存在正相关关系。 Bruton 等(1994)发现,在财务困境的时候进行并购,并购经验对绩效的感知测量是正效应。有并购经验的国企熟悉并购的一系列流程,从而规避影响并购未完成的各种风险,极大地提高了并购完成概率。所以,国企并购经验越丰富,越有利于国企并购的完成。
(4)法人治理中董事会审批过内控建设管理办法(β=-0.672,p<0.01) 对国企并购完成率具有负向显著作用,即董事会审批过内控建设管理办法的公司相比未审批的公司对并购完成率降低32.8%。 企业并购存在风险,内部控制是防范企业并购风险最为行之有效的一种手段。 董事会审批过内控建设管理办法,一方面说明了公司治理结构和内控机制的健全,另一方面通过对企业并购风险的有效评估将企业的并购风险消灭在萌芽状态。 所以,董事会审批过内控建设管理办法有利于降低并购失败率和并购完成率。
(二)随机森林分类预测分析
1.类别聚合
为了加强样本分类方法训练集与测试集的泛化能力,验证分类方法的精度,使用K 折交叉验证法进行估计(Kohavi,1995),如式(12)所示。 本文采用更为严格和精确的五折交叉验证方法,按照4∶1 比例将样本大体分为5 份,每份111 个样本。 从5 份样本中逐次抽取4 份即444 个样本作为训练集,剩下111 个样本作为测试集。 一个用来训练分类器,一个用来检验分类器的效果,总共训练5 次,计算5 次结果的均值求得模型精度估计值。
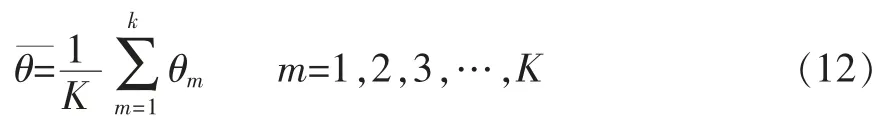
其中,θ 为K 折正确率平均值,θm为第m 折的正确率,K 为折数。
2.基于随机森林算法的国企并购完成率预测模型结果及对比
(1)准确率。利用初步显著性筛选后的15 个变量对国企并购完成率进行预测,按照bootstrap 法从444个训练样本中随机抽取i 种组合方式组成数据集Ai,i的取值即为决策树的数量(n_tree),从0 到50 分别测试不同的取值对模型预测结果的影响。 对数据集Ai,使用式(4)即f(x)=m{hi(xin)}i=1n_tree建立国企并购完成率预测决策树:x 是自变量矩阵,即每个测试样本n 是决策树可以利用的属性特征。 经过训练,得到决策树序列{h1(x),h2(x),…,hi(x)},将决策树序列组合起来,设置最多分类结果为输出类别。然后结合类别聚合分析进行5 次试验,通过对111 个测试数据预测,可得模型对测试集的最终预测正确率。 从图4 中可以看出,综合考虑模型的运行速度和模型的效率,选择i=30 作为随机森林算法中决策树的数量, 同时模型的正确率在30 时达到最高,为85%,初步说明了模型的科学性与有效性。
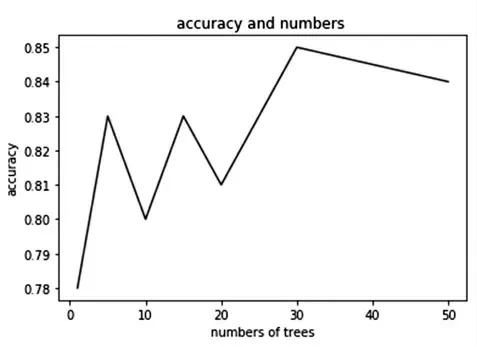
图4 树的棵数对模型预测正确率的影响
(2)查准率和召回率的比较。 分别采用经典机器学习模型DT、NGB、SVM 和传统LR 模型与RF 作对比实验。图5 展示的是5 个模型的查准率与召回率对比。如图5 所示,RF、DT、NGB、LR 和SVM 模型的查准率分别为84%、82%、55%、51%和32%,召回率分别为82%、87%、67%、33%和66%。RF 查准率与DT 较为接近,分别比NGB、LR、SVM 高29%、33%、52%;RF 召回率比DT 偏低, 分别比NGB、LR、SVM 高15%、49%、16%。由于RF 查准率和召回率与NGB、LR、SVM 差距较为明显, 但与DT 不能明显看出差距, 需要继续用F1 score 进行判断。
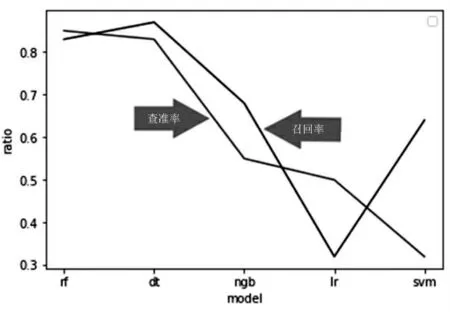
图5 国企并购完成率预测模型的查准率和召回率
(3)国企并购完成率预测模型变量全集和子集的比较。为了比较不同解释变量对于预测国企并购完成率的重要程度, 按照经初步显著性筛选后的15 个变量所涉及的系统门类, 针对5 种模型进行分别预测,其中包括资产结构、创利能力、价值再造、法人治理、并购事件特征五大系统。第一个子系统是企业内在结构的体现,良好内在肌体是并购完成的前提;第二个子系统是企业盈利能力的体现,强有力的赚钱能力是并购完成的基础;第三个子系统是企业成长能力的体现,并购经验丰富、价值较大、未来增长快是并购完成的动力;第四个子系统是企业的大脑中枢神经,是决定并购能否成功完成的指挥棒;第五个子系统是并购发生的现实状况, 是并购能否成功完成的最直接动因。 如果将五个子系统全部变量纳入模型, 并以LR为基准,则结果如图6 和图7 所示。 譬如,从F 值来看,SVM 比LR 的预测能力提高了3%,NB 比LR 的预测能力提高了23%,DT 比Logistic 的预测能力提高了44%,而RF 比LR 的预测能力提升了47%,表明RF的预测能力最强,其次是NB,然后是DT,最后是SVM和LR。 从AUC 值来看,RF 最优,其次是DT,然后是SVM,最后是NB 和LR,可见RF 模型的优势比较明显。 综合考虑F 值与AUC 值这两个评价指标,RF 模型对于国企并购完成率的预测效果最好。 但注意到,如果仅以并购特征作为解释变量进行建模时,DT 的F 值和AUC 值都稍高于RF; 如果仅以资产结构和创利能力作为解释变量进行建模时,NB 和LR 能够取得较高的AUC 值,因此,DT、NB 和LR 在某种情境下也不失为一种可用的国企并购完成概率预测模型。
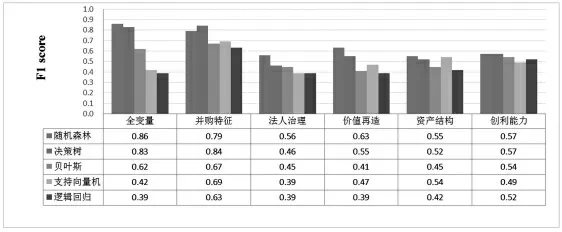
图6 国企并购完成率预测模型的F 值
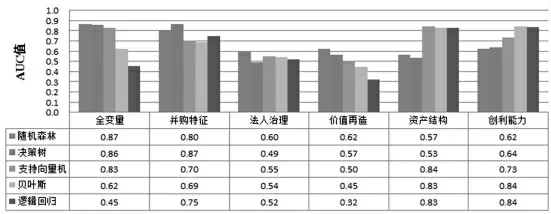
图7 国企并购完成率预测模型的AUC 值
(4)变量重要性排序。基于RF 模型的训练结果探讨了15 个并购完成率预测变量的相对重要性。 由图8 可知, 排名前三位的指标分别为:BPNP (权重系数0.247)、BPNA (权 重 系 数0.165)、SM (权 重 系 数0.101)。 与其他变量相比,这三项指标对于并购完成率的区分能力明显强于其他指标,它们的共同特点是都和并购事件特征相关,说明并购事件本身的系列属性对于并购完成率的预测更加重要和有效。

图8 影响国企并购完成率指标的相对重要性排序
六、结论、建议及展望
(一)研究结论
本文基于同花顺iFinD 数据库选取沪深A 股国有上市公司2014-2020 年并购事件为研究样本,旨在通过对国企并购是否完成做出假设,研究影响并购完成的相关因素,利用Python 网页、文本提取和抓取数据, 运用LR 模型分析影响因素与并购完成率的相关关系。 首次将人工智能算法引入并购重组领域,基于RF 算法构建国企并购完成率预测模型进行预测,并将该模型与其他经典机器学习模型进行比较,观测其预测精度,并探究了各影响因素对并购完成率预测的重要程度,得到了如下结论:
第一,净资产收益率每提升一个单位,并购完成率相应地提升0.033 倍;并购结算方式以现金结算相比股权、 现金和股权对并购完成率提高1.324 倍;历史发生过并购的公司相比未发生并购的公司对并购完成率提高0.635 倍;出让方为上市公司相比非上市公司对并购完成率降低1.010 倍;并购事件为重大资产重组比非重大资产重组对并购完成率降低0.783倍;董事会审批过内控建设管理办法的公司相比未审批的公司对并购完成率降低0.672 倍,同时,该项指标为利用文本挖掘技术抓取的治理指标之一,这说明除财务、并购特征等容易获得的数据外,不容易获取的治理数据同样会对国企并购完成率预测产生很大影响。
第二, 基于RF 算法构建的国企并购完成率预测模型正确率为85%;查准率与DT 较为接近,分别比NGB、LR、SVM 高29%、33%、52%;召回率比DT 偏低,分 别 比NGB、LR、SVM 高15%、49%、16%;F 值 为86%, 分 别 比DT、NB、SVM、LR 高3%、24%、44%、47%;AUC 值为87%,分别比DT、NB、SVM、LR 高1%、4%、25%、42%。 所以,RF 相比DT、NB、SVM、LR 对国企并购完成率具有最优的预测效果。
第三, 经初步显著性筛选后的15 个变量都对并购预测具有影响, 且发现从一级系统体系整体来看,并购事件特征对并购完成率预测较为重要,其中买方支付净资产比(0.25)、买方支付净资产比(0.17)、结算方式(0.10)三项指标最为重要。
(二)启示及建议
针对上述研究结论,并购国企可以采取以下具有针对性的措施,以有效地控制并购风险,提高并购完成概率:
第一,国企应创新产品,开拓市场,努力增加销售收入,加大控制成本力度,降低各种费用、减少固定资产、存货和应收账款,加快各项资产周转,从而提高净资产收益率。
第二, 国企应选择出让方为非上市公司进行并购,尽量避免重大资产收购,尽可能使用现金结算方式。
第三,国企应根据自身情况,制定清晰的发展战略,争取外延式发展,熟悉并购的一系列流程,提升并购经验,增强并购能力。
第四,公司治理结构和行为是影响国企并购完成的重要因素, 公司治理的部分数据虽然较难获取,但却不容忽视,公司治理结构类似人的神经系统,是现代企业制度中最重要的中枢。国企应建立健全公司治理结构,实现规范的公司治理行为。 虽然董事会审批过内控建设管理办法对国企并购完成率具有负向显著作用,但这并不意味着要减少董事会审批,反而要进一步对并购严格把关,减少不良并购,从长远视角提高并购绩效。
(三)未来展望
在未来研究中,将继续寻找影响国企并购完成率的关键因素,更加关注公司治理结构和行为,对RF 算法参数和模型融合进行优化,以进一步提高算法分类准确性和计算效率,完善并购完成率预测模型及其应用。 总之,随着国有资本和社会资本交叉融合的国企改革不断深入,国企并购重组业务不断涌现,并购风险也随之加剧,人工智能算法对于构建并购风险预警模型并进行风险预警具有重要的应用价值,可以早防范、早发现、早干预,从而使国企更有效地开展并购活动。
