辽河流域干流及部分支流总氮浓度遥感反演研究
2022-07-27王文辉
王文辉,李 艳,雷 坤,张 萌,魏 明
(1.中国环境科学研究院,北京 100012;2.沈阳理工大学,沈阳 110159;3.复旦大学大气科学研究院,上海 200438;4.中国科学院西北生态环境资源研究院,兰州 730000)
0 引 言
水质监测通过对水污染物含量的定量分析,客观评价一个地区水污染程度,为水污染防治和水环境管理提供决策服务[1]。水体中TN 的丰歉与水体是否富营养化、水生生物能否平衡密切相关,是衡量水环境质量的重要指标[2],长期以来,生活污水、含氮工业废水的大量排放及耕地化肥的施用,引起地表水水体TN 含量升高,导致溶解氧(Dissolved Oxygen,DO)浓度急剧下降,水生生物平衡被破坏,水环境质量一度下降到无法满足饮用和灌溉的需求。辽河流域作为我国最大工业基地所在地,接纳了辽宁省境内大多数冶金、石化、药物和印染等重污染行业的废水,水污染状况严峻。自1997年以来,辽河流域的水污染治理经历了从单一的控源截污到流域的污染综合治理[3],“十一五”、“十二五”期间辽河流域以氨氮(NH3-N)作为水污染防治的重点关注指标之一,参与水环境质量的监测与评价,污染程度有所缓解,但通过水质监测数据来看,水质达标状况不稳定,水污染控制程度仍不乐观:2013-2018年五年间,劣Ⅴ类断面占比增长16.7%,2019年又降低11.8%。“十三五”又提出进一步的要求,将TN也列入水环境监测的重要指标。
对水污染物的监测通常以人工现场采样并进行实验分析的方式,或在线自动分析仪器来完成[4]。近年来随着空间探测技术的革新,水环境遥感技术相比于传统的手段,具备监测范围广、速度快、成本低及便于进行动态监测的优势[5],而且还能在一定程度上解决历史数据难获取的问题,因此受到众多研究人员的青睐。早期水环境遥感在研究区域上较多地居于海洋、湖库等宽阔水域,随着传感器成像空间分辨率的提高,逐渐拓展到小面积水域的河流;研究内容从水域的定性识别[6]发展到水质参数的定量估计[7,8];研究方法经历了从分析法[9,10]到经验法[11],再到半经验-半分析法[12,13]的耦合。
对TN 遥感监测的研究以经验法和半分析-半经验法为主。经验法类似于“黑箱”,在一定程度上忽略光在大气与水体之间的传输过程,基于TN 浓度与遥感反射率之间的相关关系,以统计学的方法完成对TN 浓度的反演,无需大量的长时序实测数据,具有易操作的性质,这种方法的核心在于遥感数据源与敏感特征选取,不乏有大量学者对此进行深入的研究,如Torbick等[14]利用TM 影像对密歇根州42 个湖泊的TN 浓度反演取得了较好的结果;雷坤等[15]利用另一种遥感数据源(CBERS-1-CCD),建立了太湖表层TN 浓度的反演模型(MRE=12.2%);何报寅等[16]、杨柳等[17]则以ETM+影像,分别反演武汉东湖和温榆河TN 浓度,取得了较好的结果;而王学军等[18]通过单波段、多波段组合和主成分分析的方式选择敏感特征,基于TM 影像反演了太湖TN 浓度。随着高光谱技术的发展,研究人员又尝试利用基于实测光谱的半分析-半经验法,以期取得更准确的TN反演结果,如巩彩兰等[19]通过分析实测高光谱归一化值、波段比值和微分值与TN 浓度的相关性,以656.53 nm 反射率归一化值与880 nm 反射率归一化一阶微分值反演了黄浦江TN 浓度;徐良将等[20]同样以实测光谱,通过微分和波段比值的方式,发现455 nm 反射率微分值与1 015/528 nm 反射率比值为TN 浓度最敏感变量,并得到了R2=0.839 的TN 反演模型。近几年面对TN反演准确度较低的问题,以机器学习为基础的非参数算法无需确定目标函数的形式,具有更高的灵活性与泛化性,表现略胜一筹,王建平等[21]以人工神经网络模型对鄱阳湖TN 浓度的反演研究、王云霞[22]以最小二乘支持向量机法对辽宁清河水库的TN反演,都取得了较好的结果。
大流域尺度河流水体水质遥感监测受遥感成像空间分辨率、成像幅宽等诸多因素的制约,有待进一步认识。在充分了解遥感水质监测优势和发展现状的前提下,针对辽河流域干流及部分主要支流,采用最大坡度下降算法选取纯水体像元,利用GF1-WFV 遥感影像反演TN 浓度,及时掌握TN 在流域尺度上的时间、空间变化状况,为大流域尺度河流水体的TN 反演研究积累一定的经验参考和数据,为辽河流域水生态环境精细化管理与保护提供科学依据。
1 研究区域概况与数据采集
1.1 研究区域概况
辽河流域(40°31'~45°17'N,116°54'~125°32'E)位于辽宁省境内,流域面积约21.9 万km2,流域内有辽河、浑河和太子河三大水系。流域覆盖辽宁省铁岭、沈阳、抚顺等8 个地市全境,及黑山、北镇和彰武等4县(市)。由于地处东北老工业基地,长期以来形成了以煤炭与石油开采、焦化和钢铁等重工业为主的工业结构,导致污染排放强度高,致使辽河流域污染状况愈加严峻。自“九五”被列为国家重点治理的流域至今,辽河流域干流河段COD 劣V 类已基本被消除,部分区域生境有所恢复,水质退化的趋势已经得到基本的控制,但水质达标状况依旧不稳定:2016年考核断面水质达标率为80%,2017年同比增长3.7%,到2018年又同比下降27.4%;水质优良比例(Ⅰ~Ⅲ类)从2016年的32%增长到2017年的46.9%,2018年又下降了7.3%;丧失水体使用功能(劣V类)占比总体呈上升趋势。
1.2 数据采集与预处理
1.2.1 水质数据
选取流域面积在1 000 km2以上的支流,以谷歌地图(Level=14,空间分辨率约为17 m)为底图,采用人机交互的方式在支流入干前,选取水陆区分度较高、水面宽度大于1 个像元的区域,布设水样采集点位;干流水样采集点位的布设方法与支流相同,尽可能上中下游均布设点位;布设的点位尽量与日常监测点位保持一致,以便对数据进行补充。全流域布设40个水质采样点位(图1)。于2018年4-9月,每月4-10 号采集水样并分析水质。
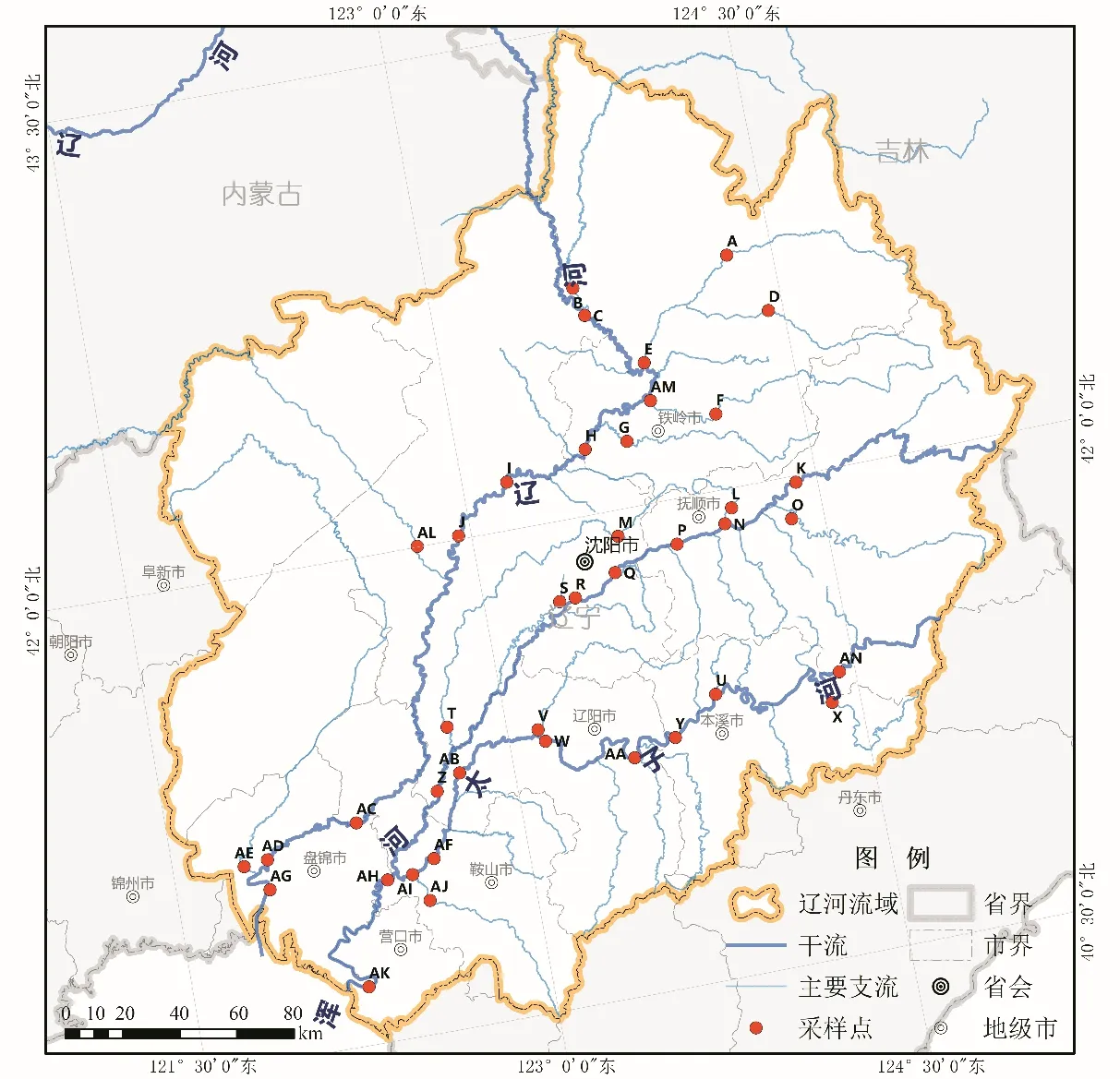
图1 采样点位布设Fig.1 Layout of sampling points
1.2.2 遥感数据
对比非商业多光谱遥感数据之间的参数,综合考虑遥感卫星成像的时间、空间分辨率,及成像幅宽和数据的批量易获取性:高分一号WFV(GF1-WFV)在星下点成像空间分辨率(16 m)上优于Landsat 系列(30 m,Landsat8 融合后为15 m)、MODIS(最高250 m)和HJ1A、1B(30 m),在成像幅宽(800 km)、成像时间分辨率(2 d)和数据批量易获取性上要优于Sentinel-2,多光谱相机成像谱段涵盖蓝光(0.45~0.52 μm)、绿光(0.52~0.59 μm)、红光(0.63~0.69 μm)和近红外光(0.77~0.89 μm),满足研究的需求。选用GF1-WFV 数据作为研究辽河流域干流及主要支流TN浓度反演的遥感数据源。
从资源卫星应用中心网站(http://www.cresda.com/CN/)筛选并获取云量小于10%的研究区域GF1-WFV遥感影像,7月全月云量较多,不能满足研究需求,因此保留了4-6月、8-9月的影像,共计25 景,成像时间与水样采集时间准同步(±5 d)。依次按照辐射定标、大气校正、正射校正的顺序,基于IDL语言,集成了ENVI5.3 下的辐射定标、FLAASH 大气校正和正射校正模块,对GF1-WFV 影像形成流程化的批量处理程序,其中正射校正所使用的DEM数据为ASTER GDEM。
2 研究方法
2.1 数据分析
2.1.1 TN浓度潜在特征构造
GF1-WFV 影像带宽高,波段少,但通过波段之间的数学运算可以增强或屏蔽某些信号[23],使有用的信号更为突出。在GF1-WFV 四个波段的基础上,参考相关研究[24],以双波段、三波段、四波段组合的方式构建了59个TN浓度潜在特征,累计63个潜在特征,计算方式见表1。

表1 TN浓度潜在特征Tab.1 Latent features of TN concentration
2.1.2 纯水体像元与水体提取
水体的反射率通常小于其他地面物体,纯水体像元(遥感影像中只包含水体的像元,以GF1-WFV 为例,1 个像元为边长16 m 的正方形)的归一化植被指数(NDVI)值一般不大于0,为了确保最大限度地降低偶然误差,采取最大坡降算法[25],以采样点的像元为中心,固定与其相邻的8个像元,计算中心像元与临近像元的坡降度[式(1)],选取坡降最大的临近像元作为采样点的纯水体像元。
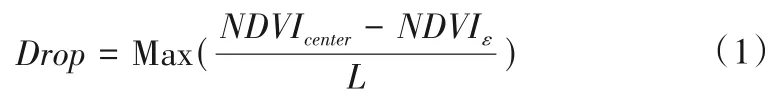
式中:Drop为中心像元与临近像元的坡降度;NDVIcenter为中心像元的NDVI值;NDVIε为 与中心像元临近像元的NDVI值,ε=1,2,3,…,8;L为中心像元与临近像元的距离,对角线临近像元,其余临近像元L=16。
GF1-WFV 不具备中红外波段,无法计算MNDWI,故以NDWI计算结果结合人机交互的方式进行水体的提取,GF1-WFV影像NDWI计算见式(2)。
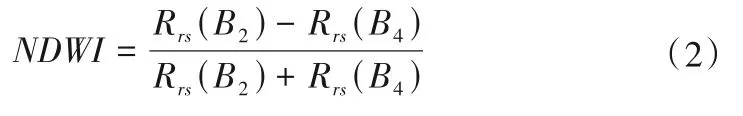
式中:Rrs(B2)为绿波段遥感反射率,GF1-WFV 为第2 波段;Rrs(B4)为近红外波段遥感反射率,GF1-WFV为第4波段。
2.2 参数回归模型
参数回归模型对自变量和因变量之间有明确的函数式,通过分析潜在特征与TN 浓度的相关性,确定TN 浓度的敏感特征,以TN 浓度作为因变量,敏感特征作为自变量,建立一个相关性较高、且具有明确函数关系的方程,实现对TN 浓度的反演。但高维度的可能存在冗余特征,将这些特征全部引入模型,虽然拟合效果较理想,但冗余特征的共线性会过度稀释有用特征的信息量,使目标值的特征难以被解释。逐步回归的方法将特征逐个引入模型,根据特征对目标值的解释度剔除掉冗余特征,从而保留解释度较高的特征。按照8∶2 的比例分割数据集,采用逐步线性回归的方法,80%的数据来建立逐步回归模型,剩余20%以作验证。
2.3 非参数回归模型
非参数回归是随着近年机器学习的兴起而衍生的一类算法,这类算法根据特征集预测目标值时,无需假设目标函数的形式,具有更高的灵活性与泛化性能。采用随机森林[26](Ran‐dom Forest,RF)和极端梯度提升[27](Extreme Gradient Boosting,XGBoost)两种非参算法探索辽河流域干流及主要支流TN 浓度反演最优方式。同样按照8∶2 的比例分割数据集,80%的数据作非参数算法的训练集,其余的20%验证算法的预测准确度。
2.3.1 随机森林算法
随机森林算法是一种以决策树为基学习器的有监督集成学习算法,面对回归分析的问题时,取多个决策树预测结果的均值作为目标值,具有泛化能力突出、易于实现、抗噪能力强、计算速度快等优势,有利于辽河流域干流及主要支流TN 浓度的预测。RF 在训练的过程中使用bootstrapping 抽样方法,约有36.8% 的数据不会参与RF 的训练:对于数据集D={Y|X1,…,Xn},RF先使用这部分数据计算预测错误率,随机打乱某一特征Xa的排序后,再次计算预测错误率,取两次错误率之差量化特征Xa的权重,若RF 构建了β个基学习器,则特征Xa的权重为β个基学习器前后两次预测错误率之差的均值,因此RF也具备特征选择的能力。
2.3.2 极端梯度提升算法
首创于2016年的XGBoost 也是一种集成学习算法,其基学习器可以是树模型,也可以是线性模型。与RF 不同的是,XGBoost采用了boosting 集成框架,使学习器根据当前的损失残差,以梯度提升的方式加入另一个学习器,降低损失残差,通过不断地迭代达到更高的预测准确率,属于RF模型的拓展。
2.4 结果验证
参数、非参数两类回归模型反演辽河流域干流及部分支流TN 浓度的准确度采用决定系数(R2)、均方误差(Root Mean Square Error,RMSE)、平均相对误差(Average Relative Error,MAE)评价,计算公式见式(3)~(5)。
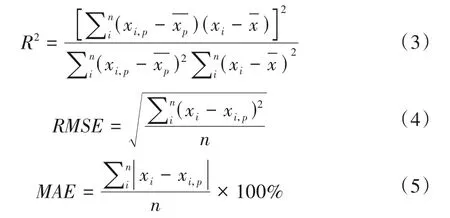
式中:xi为验证数据集中第i个样本的实测值(或实测值对数),i=1,2,3,…,n;xi,p为验证数据集中第i个样本的对应的预测值(或预测值对数),i=1,2,3,…,n。
3 结果与讨论
3.1 水质变化趋势与大气校正结果
从水样检测结果来看,辽河流域干流及部分支流TN 浓度较高。240 组TN 浓度检测结果中超地表水Ⅴ类标准(>2 mg/L)的占比76.67%,其中4月、9月劣Ⅴ类占比均在80%以上,8月最低为65%。在时间上也存在较大的差异,4-9月变异系数(CV)在0.67~1.14 之间,其中6-8月3 个月TN 浓度均值均小于4 mg/L,低于4-5月、9月[图2(a)],由于辽河流域年内降水量分布差异较大[28],降水集中在6-8月,故而径流量较大,污染物浓度低。
抽取30%的点位,观察大气校正后的光谱曲线,如图2(b)所示,蓝光(B)区普遍呈吸收状态,随着波长的增加,约81.1%的点位在绿光(G)区出现明显的反射,红光(R)与近红外(NIR)区反射率逐渐降低,光谱曲线形态整体呈“倒U”形,反射率均小于10%;其余点位峰值由绿光区向红光区偏移,反射率值高于10%。根据已有的研究[29]:天然水体的反射率普遍居低(小于10%),在绿光区会存在明显的反射峰,随着波长的增加,反射率与波长成反比;当水体浑浊或含沙量较高时,反射峰会从绿光区移向红光区,反射率甚至会高于10%,这种现象通常出现在河流下游区域。大气校正结果接近准确。
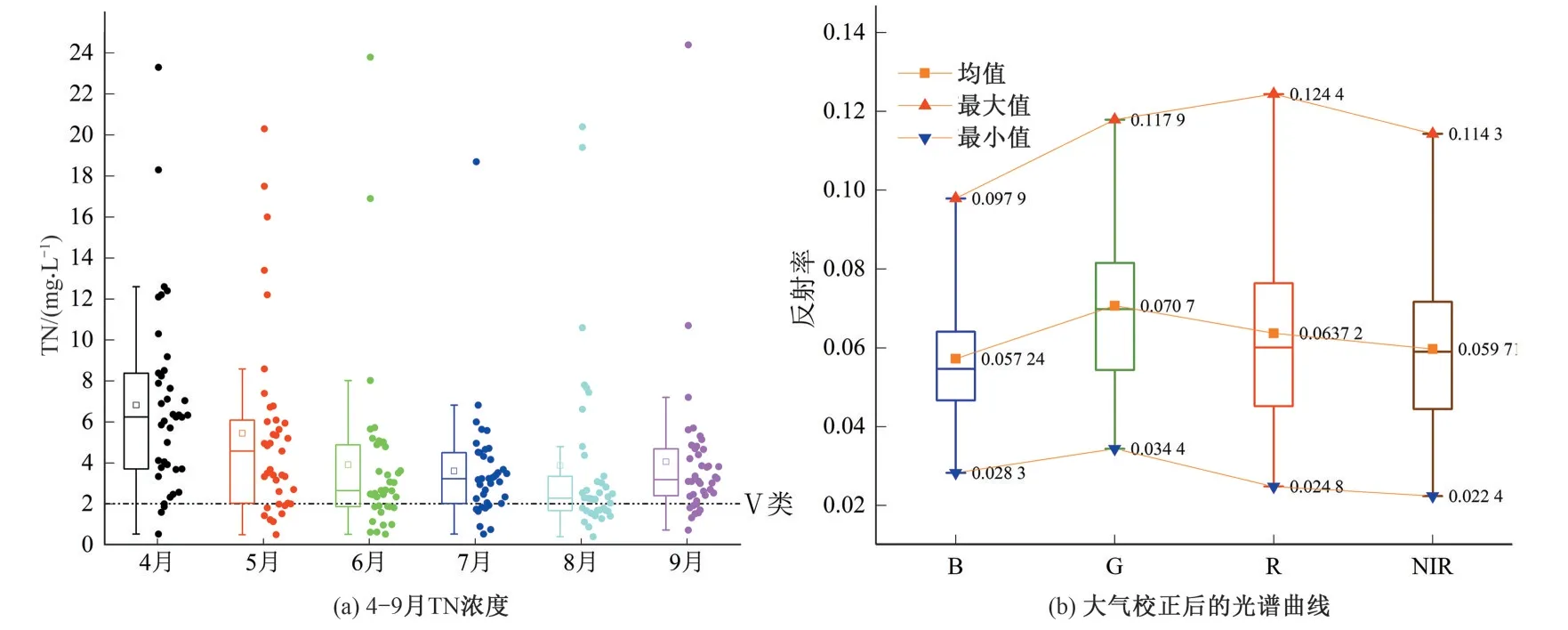
图2 TN浓度(4-9月)与大气校正后的光谱曲线Fig.2 TN concentration(April to September)and Water spectrum curve after atmospheric correction
3.2 基于参数回归模型的TN浓度反演
为探究辽河流域干流及部分支流TN 的反演是否可以按季节、水期分布,将时间按照春季(4-5月)、夏季(6-8月)、平水期(5-6月)、丰水期(8-9月)进行划分。对各月、各季度、各水期TN 浓度的正态分布性进行了检验,均不服从正态分布(K-S 检验Sig<P=0.05),故采用Spearman 秩相关系数来描述TN 浓度与63个潜在特征的相关性,以相关显著的特征参与参数回归模型的建立。相关性计算结果如图3所示,4-6月、8-9月、春季、夏季、平水期、丰水期分别与TN 浓度相关性显著的特征累计为54、26、30、15、5、37、31、41和16个。
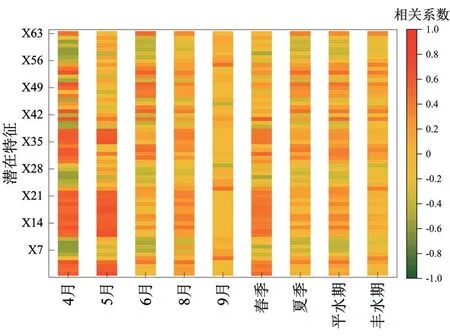
图3 潜在特征与TN浓度的Spearman秩相关性Fig.3 Spearman rank correlation between latent featuresand TN concentration
“3σ”法对异常数据分析后,步进条件设置为0.15<Per‐cent_F<0.25,参数回归模型的建立与验证结果见表2,4-6月、9月宜逐月反演,8月宜划分为丰水期来反演,所对应特征组合分别为(X41)、(X41,X1,X11)、(X41,X36)、(X53)和(X53,X49,X17)。随着敏感特征的逐步增加,R2不断递增,F在递减,但并非最高R2所对应的验证R2也最高,可能是冗余特征稀释了敏感特征的信息,产生了过拟合的情况。综合考虑验证R2、验证RMSE和验证MAE,最终以X41 作为4月和平水期TN 浓度的敏感特征;X53 为8、9月和夏季TN 浓度敏感特征;X41、X1 和X11共同作为5月TN 浓度敏感特征;X41和X36共同作为6月TN 浓度敏感特征;X41、X10、X4 共同作为春季TN 浓度敏感特征;X53、X49 和X17 共同作为丰水期TN 浓度敏感特征。同时从验证R2来看:夏季参数回归模型验证结果最好,5、4、8月、平水期和9月次之,6月、丰水期和春季居后;但从验证RMSE和MAE来看,夏季和平水期均要高于6月,因此6月TN 浓度不宜划分为夏季来反演;8月验证RMSE虽然小于夏季,但与丰水期相比,验证RMSE与MAE较高,且在模型建立时R2也不及丰水期,因此8月TN浓度宜划分为丰水期来反演,4-6月、9月逐月反演。

表2 TN浓度反演的参数回归模型Tab.2 Parameter regression model for TN concentration inversion
3.3 基于非参数回归模型的TN浓度反演
非参数回归模型能够很好地处理高维特征数据,先将63个特征全部引入RF 的训练,超参数的寻优采用3 折交叉验证(20%的验证数据)与网格搜索法。从预测结果的准确度上来看(图4),非参算法反演TN浓度宜逐月进行。图4中曲线为R2,柱状为特征权重,随着将特征按照权重高低依次加入RF,R2不断波动,总体呈上升趋势,到曲线尾部逐渐趋于平直。可以发现:并不是所有的特征都参与到RF 的训练才使得R2最高,因此非参算法反演TN浓度时,先要对特征进行筛选。
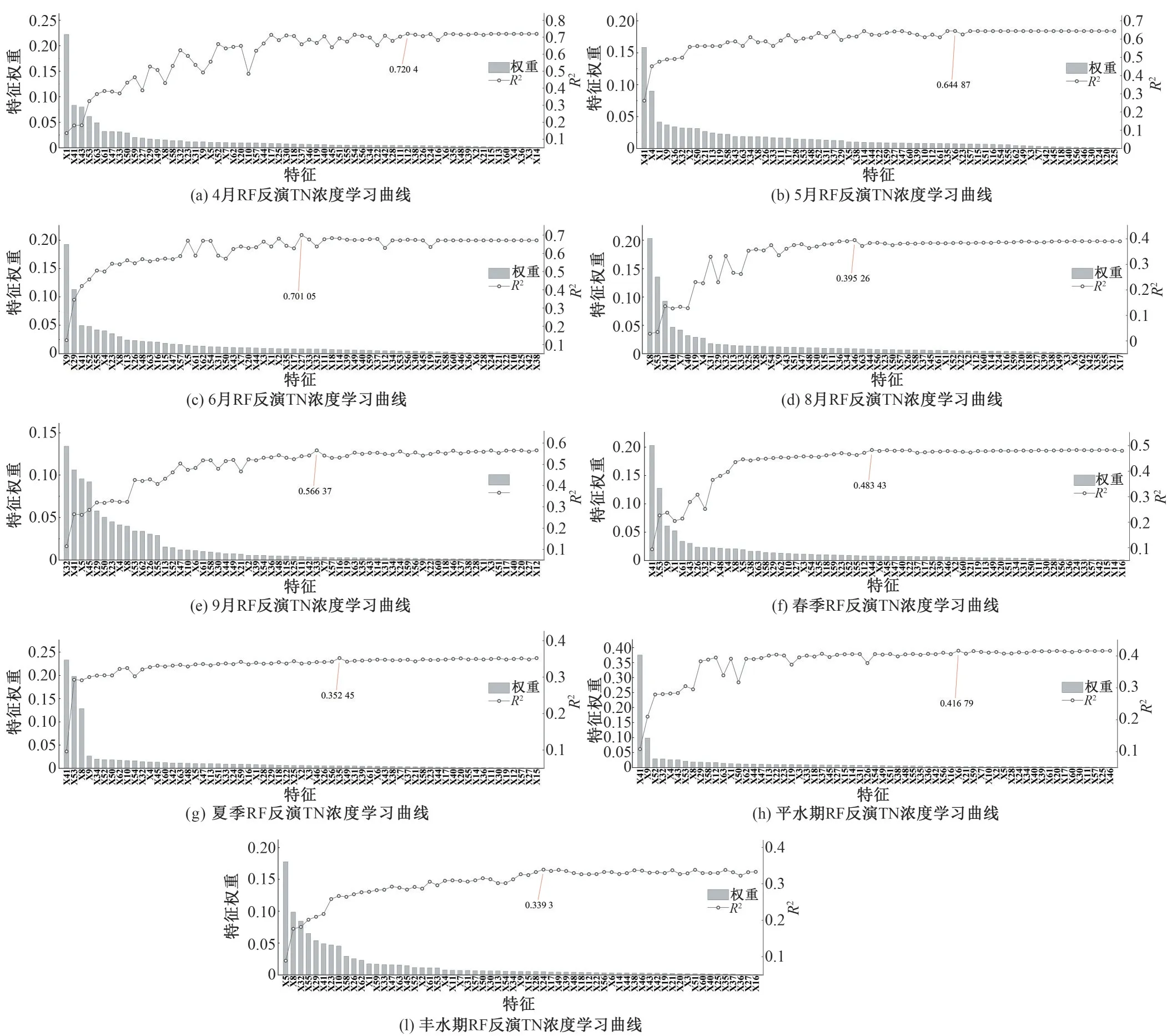
图4 RF反演TN浓度学习曲线Fig.4 The learning curve for RF inversion of TN concentration
为了使特征的可解释性更高,进一步压缩特征维度,取RF验证集最高R2对应的特征组合与Spearman 秩相关性显著的特征组合的交集XS=Xrf∩XSpearman,在XGBoost 中进行逐月反演,超参的寻优同样采用3折交叉验证(20%的验证数据)与网格搜索,从图5可以看出:整体的反演效果相比RF略有提升,MAE分布在7.27%~26.99%之间,5月最佳,8月R2较低,TN 浓度大于10 mg/L时,反演效果较差。

图5 XGBoost反演TN浓度的结果Fig.5 XGBoost inversion results of TN concentration
此外,通过对比,非参数回归模型与参数回归模型类似,特征X41,即(B1+B3)/B2均为4-6月逐月、春季、平水期TN浓度的敏感特征;在特征X41 的基础上加入B4 后,生成(B1+B3+B4)/B2即特征X51,均为8-9月逐月、夏季、丰水期TN浓度的敏感特征。从每月水样采集期间水文监测站泥沙含量来看[图6(a)],8、9月日均泥沙浓度分别为0.044 91、0.054 44 kg/m3,明显高于4-6月[0.022 34 kg/m3,0.025 39 kg/m3];从遥感反射率来看[图6(b)],B3 波段(R)到B4 波段(NIR),8、9月反射率开始增高,而4-6月均呈下降趋势。由于8、9月泥沙浓度的升高,水体较为浑浊,引起水体光谱反射率的变化,反射峰值移动到NIR[23,29],而水体中的氮元素会以泥沙作为吸附载体[30],故NIR 波段反射率对8-9月TN浓度的反演起到重要的作用。

图6 采样期间抚顺(二)站日均泥沙浓度和遥感反射率Fig.6 During the sampling period,the daily average sediment concentration and remote sensing reflectivity of Fushun(2)Station
3.4 模型适宜性评价及误差分析
对比两类算法反演结果表明:使用XGBoost 模型的反演效果较好,适合辽河流域干流及部分主要支流TN 浓度反演。由于水体的光学特性较为复杂,影响因素众多[31-33],可以说明辽河流域干流及部分支流TN 浓度与遥感反射率(或组合)之间不具有明确的线性关系,非参数回归模型类似于“黑箱”,无需确定的函数关系,且对复杂的高维特征也能够较好地应对。
XGBoost 模型反演辽河流域干流及部分支流TN 浓度的实测值与预测值之间存在7.27%~26.99%的相对平均误差。可能由以下原因引起:
(1)流域尺度遥感数据的局限性。亚米级分辨率的遥感影像对于细小河流的观测效果固然更好,以GF2-PMS 影像为例,23 km 的成像幅宽对方圆21.9 万km2的辽河流域而言,经济适用性较低。国产GF1-WFV 成像空间分辨率比广泛使用的Landsat 系列等要高,尽管在采样时尽可能选取在河道中央,但对于河宽不足16 m的河段,单个像元内混合了河流及两岸其他物体的信息,其记录的反射率值仍可能不属于真实水体。
(2)大气校正的系统误差。FLAASH 大气校正模型能最大程度上消除大气对地表真实情况的影响,尽可能达到逼真的效果,但校正过程中所使用的经验参数无法消除卫星成像整个过程中的系统误差,影像所记录的地表信息与实际不完全相符。
(3)水质监测数据与遥感数据的时间吻合度。水质与遥感反射率都是水体的瞬时信息,水样采集时间与卫星成像时间虽控制在±5 d 以内,但这段时间内采样点的TN 浓度是存在波动性的,总会存在差异,客观上与遥感反射率不完全吻合。
3.5 TN浓度的时空分布
对三条水系的反演结果进行局部展示(图7),从时间上来看,辽河流域干流及部分支流TN 浓度在4-6月、8月期间呈逐月递减趋势,9月又开始增加,丰水期低于平水期与枯水期;从空间上来看,太子河本溪段下游TN 浓度在0.43~8.02 mg/L,明显优于清河入干前(0.96~8.17 mg/L)和浑河沈阳城区段下游(1.13~9.88 mg/L)。
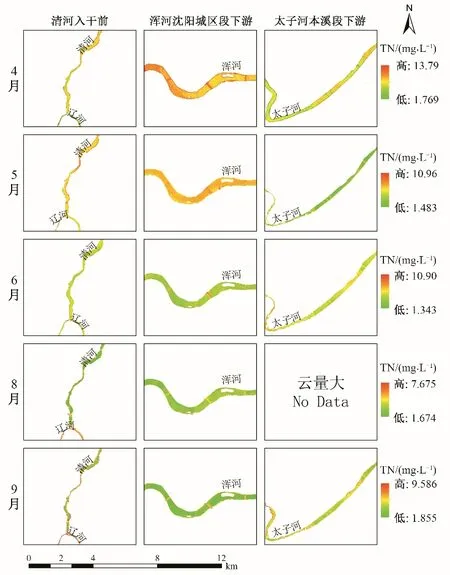
图7 辽河、浑河和太子河局部反演结果Fig.7 Local inversion results of Liaohe,Hunhe and Taizihe
清河在入干前与浑河沈阳城区段下游TN 浓度在时间上的变化趋势一致,4-5月明显高于6、8、9 三个月。据《辽河治理攻坚战支流河目标清单》,清河支流马仲河、浑河上游抚顺段支流东洲河、章党河、将军河为重污染河流,考核断面水质现状均为劣Ⅴ类,且2018年上半年清河支流寇河进行了河道清淤工程,这期间水质较差,可能是支流汇流对干流的水质产生了较大的影响;此外,2018年上半年,受降水影响,浑河流量同比减少47.9%,且抚顺、沈阳城区筑坝较多,使水流不畅,水质也可能会随着变差。
4 结 论
目前对湖库等宽阔水域水环境参数定量遥感反演的研究相对成熟,大流域尺度河流水体因受遥感成像空间、时间分辨率与幅宽的制约,有待进一步认识。以辽河流域为研究区域,TN 为反演对象,利用2018年4-9月(不含7月)实测水质数据和准同步GF1-WFV 遥感影像,基于参数、非参数两类回归模型,对辽河流域干流及部分支流TN 浓度进行了反演研究,得出结论:
(1)GF1-WFV 影像空间分辨率16 m,时间分辨率2 d,成像幅宽800 km,多光谱相机成像谱段涵盖蓝、绿、红和近红外4 个波段,大气校正后的反射率普遍小于10%,绿光区为反射峰,随着波长的增加,反射率下降,满足辽河流域干流及主要支流TN浓度反演的需求。但8-9月(丰水期)由于降雨冲刷导致泥沙量增大,反射峰朝近红外偏移,水体中的氮元素会吸附在泥沙上,因此近红外波段反射率在8-9月辽河流域干流及部分支流TN浓度反演中具有重要意义。
(2)辽河流域干流及部分支流TN 浓度与遥感反射率(或组合)之间线性关系较弱,使用参数回归模型反演结果不及非参数回归模型。非参数回归模型中,极端梯度提升的树模型(XG‐Boost)比随机森林(RF)反演效果更好,4-6、8-9月逐月的R2均在0.575 以上,RMSE在0.54~1.899 之间,MAE在7.27%~26.99%之间。当TN浓度在10 mg/L以上时,反演效果不理想。
(3)内陆水体的光学特性较为复杂,影响因素众多,辽河流域干流及部分支流TN 浓度反演需多个特征参与。与TN 浓度相关的潜在特征中存在非相关、低相关的冗余特征,不仅不能提高反演的准确度,还难以被解释,因此使用XGBoost模型前要对特征进行选择。取RF 验证集最高R2对应的特征组合与Spearman 秩相关性显著的特征组合交集(XS=Xrf∩XSpearman)的方式能够较好地完成对特征的选择。
(4)2018年辽河流域干流及部分支流TN 浓度在时间上存在较大的差异,4-6月明显高于8-9月,8月达到最低(1.675~7.675 mg/L);受清河支流马仲河、寇河,浑河上游抚顺段支流东洲河、章党河、将军河劣Ⅴ类水体汇流,以及浑河流量减少的影响,4-5月清河入干前(1.47~8.17 mg/L)和浑河沈阳城区段下游(1.13~9.88 mg/L)TN 污染情况比太子河本溪段下游(0.48~8.02 mg/L)严重。
