基于全卷积神经网络的桥梁裂缝分割和测量方法*
2022-07-27胡文魁付志旭安栋阳
胡文魁 邓 晖 付志旭 安栋阳 段 锐
(华南理工大学土木与交通学院,广州 510641)
0 引 言
裂缝是桥梁病害中最常见的形式,不仅出现频率高,而且对结构的安全性和可靠性均有较大影响,特别对于安全等级较高的钢筋混凝土桥或者预应力混凝土桥,一旦出现明显的结构裂缝,将降低桥梁结构的承载力。如果不及时检查发现并采取有效措施进行修复加固,在车辆荷载、温度作用等多种因素影响下,裂缝会加速发展,一旦发展成贯通裂缝,将引发严重的安全事故,因此,对桥梁裂缝进行长期定期的检测是保证结构安全的重要手段之一。
近年来,为了提高桥梁病害检测自动化水平,快速准确地提取出桥梁裂缝图像,国内外众多学者进行了广泛深入的研究。Hendrickson等提出通过Sobel边缘检测算法,把病害区域的周长计算出来,然后通过设定的阈值(T=20)进行图像去噪[1]。张德津等利用图像空间聚合特征进行沥青路面裂缝的分割,其核心思想是把图像分块,将分块后的图像作为处理对象,使用逐步求精法完成子块图像的分割[2]。Kirschke等提出利用图像直方图技术来提取路面的裂缝病害,这种算法主要是通过作出图像的灰度直方图,然后,利用直方图波谷对应的灰度值来提取路面裂缝,此方法在目标裂缝对比度较强的情况下效果较好[3]。孙波成在大津(OSTU)分割算法的基础上进行改进,提出一种基于最大类内、类间距的方法来确定阈值,分割结果显示:二值图像中不仅含有很多随机分布的噪声点,而且裂缝出现了断断续续的状况,后续通过形态学算法来解决上述问题[4]。Tang等提出一种新的裂缝分割算法,基本原理是先利用灰度直方图谷底阈值法得到裂缝的大概位置,进而利用基于B样条的Snake模型和形态学技术来具体确定裂缝的位置[5]。这些基于传统的图像处理方法都是通过直接处理图像得到裂缝的典型特征,进而提取出裂缝进行几何尺寸的测量。然而存在的问题在于图像增强处理后对比度不足、去噪效果不明显、分割后裂缝连续性较差等。
随着计算机技术的高速发展和深度学习的崛起,国内外学者开始把神经网络用于桥梁的病害检测,目前已取得大量的研究成果。李楠利用caffe框架里面的LeNet-5神经网络模型对图像进行有无裂缝的识别,将该神经网络的激活函数换为Relu,取得不错的识别效果[6]。赵珊珊等在VGGNet网络的基础上进行改进,删除了VGGNet网络中的第五个卷积、池化层以及全连接层,试验结果显示:该网络的裂缝检测效果明显优于传统识别方法[7]。剑桥大学提出一种基于SegNet的模型来分割图像,该模型通过训练1 000张图像,最终得到城市道路的分割网络,并且该模型具有很强的泛化能力[8]。
本文主要研究内容如下:1)选择合适的无人机和云台,使相机能垂直于桥梁表面拍摄,依据被检桥梁的实际情况,制定合理的无人机检测方案,获取大量桥梁图像。2)将采集到的桥梁图像进行预处理,利用BCI-AS全卷积神经网络模型将裂缝图片分割成裂缝二值图。3)通过投影技术最小二乘拟合中心线的算法对分割的裂缝二值图进行宽度测量并与现场实测进行对比,验证本文算法的可行性。研究方法主要结构流程如图1所示。

图1 本文研究方法流程
1 图像数据采集和预处理
1.1 裂缝图像采集与相机标定
通过无人机采集大量桥梁裂缝图像,为避免无人机拍到畸变的图像,必须保证无人机相机垂直于桥梁表面。本文选用经纬 M300 RTK搭载禅思H20采集桥梁图像。禅思H20包含30 Hz高帧率热成像相机、1 200万像素广角相机、2 000万像素变焦相机和激光测距仪,质量为678±5 g,它支持经纬M300 RTK,相机俯仰转动范围为-120°~30°。经纬 M300 RTK配备了上下补光灯,其有效照明距离为5 m,能弥补采光不足的缺陷,内置5 000 mAh、7.2 V电池,正常情况下使用续航时间长达1小时,支持禅思 XT2、禅思 XT S、禅思 Z30、禅思 H20、禅思 H20 T等云台。其具体形式见图2。

图2 大疆经纬M100
在利用无人机进行桥梁裂缝检测时,对于设置有靶点的桥梁,可以依据靶点实现像素的标定。对于没有设置靶点的桥梁,首先依据检测精度确定单张图像所拍摄桥梁底面的实际尺寸,然后根据相机焦距、实物大小和物距之间的关系确定相机的焦距和相机与桥梁底面的距离,从而实现相机的标定。相机拍摄图像的实际大小、相机传感器尺寸、相机焦距和相机摄像头与桥梁表面距离之间的联系见式(1)。
(1)
式中:f为相机的焦距;D为相机摄像头到桥梁底面的距离;w为相机传感器的靶面宽度;W为被拍摄物体的实际宽度。
根据JTG H11—2004《公路桥涵养护规范》[9],桥梁裂缝检测精度应控制在0.2 mm以内,因此单个像素所代表的实际大小也应该控制在0.2 mm×0.2 mm以内。本文采用的相机有效像素为5 000×4 000,当桥梁检测精度为0.2 mm时,拍摄的图像对应结构表面的真实尺寸为1 000 mm×800 mm,当桥梁检测精度为0.1 mm时,拍摄的图像对应结构表面的实际尺寸为500 mm×400 mm。另外,由于经纬 M300 RTK具有自动避开障碍物的功能,在采集图像过程中,应保证无人机到桥梁表面的距离大于飞行的安全距离,确保无人机安全有序地飞行。
通过查询禅思H20的相机参数可得,2 000万变焦相机传感器的靶面尺寸是1/1.7(英寸),即7.6 mm×5.7 mm。当焦距设定为85 mm,桥梁检测精度为0.1 mm时,依据式(1)可得无人机摄像头与桥梁底面的距离为5 600 mm;当焦距不变,桥梁检测精度为0.01 mm时,无人机摄像头与桥梁底面的距离为560 mm。在上述两种状况下,无人机到桥梁表面的距离均大于飞行的安全距离。为了使桥梁病害检测更加准确,本文采用检测精度为0.01 mm的相机参数获取图像。
1.2 裂缝位置的确定
在无人机进行桥梁裂缝检测时,需要依据无人机获取到的图像资料计算裂缝的宽度,同时,尽量通过图像资料确定出裂缝的位置和类型,通过这些信息对桥梁健康状况作出精准的判断。但是,目前在桥梁设计阶段,对桥梁裂缝把控十分严格,桥梁中出现的结构裂缝都很小,并且威胁到桥梁结构安全的裂缝都是从细微的裂缝发展起来的,为了满足检测精度,无人机需要近距离拍摄结构表面的病害图像,这就导致无人机拍摄到的单张图像,只能覆盖桥梁表面很小的面积,对一跨桥梁底面进行裂缝检测就需拍摄成千甚至上万张图像,致使裂缝位置的确定成了一个难题。为了解决上述问题,本文提出一种基于GPS定位和有序拍摄编号相结合的方法来采集图像,即按照不同的构件进行分类编号,按照特定的规则通过GPS定位拍照,并将采集到的图像有序编号。
利用无人机对具体桥梁进行裂缝检测时,首先找到桥梁设计图纸,依据检测精度确定单张图像的大小,然后按单张图像大小平均分块并进行编号,具体编号如图3所示。编号中的第一个数字代表第几跨桥梁,第二个数字代表桥梁横向方向的具体位置,第三个数字代表桥梁纵向的位置。在利用无人机进行桥梁检测过程中,当无人机飞行到每一块中心点位置时,悬停拍摄图像,将采集到的图像利用分块时的序号进行编号,最后,通过卷积神经网络和数字图像处理技术识别出裂缝图像并计算裂缝的几何参数,并依据图像的编号确定裂缝的具体位置。

图3 桥梁底面分块示意
为了利用上述方法实现裂缝的定位,无人机获取图像主要有以下两种途径:
1)依据检测精度计算出单张图片所拍摄的实际大小、焦距以及摄像头与桥梁底面的距离,然后根据飞行速度和单张图片大小确定拍摄的时间间隔,最终让无人机在特定时间间隔内自动拍摄并编号,保证拍摄到的所有图像拼接起来得到桥梁的底面或侧面。
2)根据单张图像所拍摄到的实际大小和无人机摄像头与桥梁表面的距离,可以计算出结构表面每一块中心点具体的空间位置,进而得到无人机悬停时的空间位置,然后把这些空间位置数据输入到无人机的飞控软件中,以此实现无人机的自动飞行和自动悬停拍摄。当应用这种方法时,无人机在飞行过程中完全处于自动飞行状态,这能减少工作人员的调试误差,显著提高检测效率。
1.3 图像预处理和数据集准备
由于多种因素的综合影响,导致采集到的图像不清晰,图像像素灰度值比较集中,目标裂缝对比度较差等状况。所以,必须通过相应的算法来增强图像,改良图像的整体效果。本文利用无人机在随机环境条件下采集大量图片,并筛选出2 500张原始裂缝图片为建立全卷积神经网络分割模型的数据集做准备。为减小网络模型的参数计算量,将全部图片统一按加权平均法进行灰度化处理,效果如图4b所示。考虑到原始图片曝光不足,对比度偏低,且图像中包含大量干扰裂缝检测的噪声,为提高模型训练质量,将灰度图再进行分段线性变换[10]增强和中值滤波[11]去噪。分段线性不仅增强了目标裂缝的对比度,而且算法处理速度快,是比较好的图像增强方法,增强效果如图4c所示。中值滤波是一种能保留图像细节信息的非线性去噪技术,它有效改善了均值滤波处理图像后目标边缘模糊的问题,且能很好地去除图像中的椒盐噪声,去噪效果如图4d所示。

a—原图;b—灰度图;c—分段线性变换;d—中值滤波。
将2 500张裂缝图片进行加权平均灰度化、分段线性变换、中值滤波等图像增强去噪处理,并将图像分辨率归一化为500×400,按照1∶4的比例随机分为测试集和训练集,其中训练数据有2 000张图像,测试数据有500张图像。
将按上述步骤处理得到的数据集和处理方法均命名为GPM(Gray-Piecewise Linear Transformation-Median Filtering),在裂缝图像放入模型训练之前,进行GPM处理,以减小光照、噪声等因素对下一步提取裂缝形状(分割裂缝)带来的影响,提高分割质量和精度,这一步是非常必要的。
2 基于全卷积神经网络的分割算法
传统的基于阈值分割[12]或基于边缘检测[13]的图像分割算法存在一些普遍问题,如需要手动输入阈值等参数,工作量大,占用大量人力资源,无法自动、高效地分割裂缝,达不到智能化提取裂缝的要求。另外,这些算法都是利用像素之间的灰度信息提取目标裂缝,并没有更细致地考虑图像的空间信息,导致分割后的目标裂缝连续性较差。
目前,由于深度学习模型在视觉应用中取得了大量成果,已有大量的工作者致力开发应用于图像分割的深度学习模型。为了更加智能化地将裂缝完整地提取出来,本文引入全卷积神经网络进行裂缝分割。
2.1 全卷积神经网络
卷积神经网络早期主要应用于图像分类领域[14-15],但随着计算机算力逐步增强和研究者对卷积神经网络的深入研究,部分学者着手利用卷积神经网络进行语义分割,其利用像素点周围的像素块作为输入数据,通过大量的数据进行训练得到训练完毕的网络模型,进而可以测试出像素块中心点的类别,最终实现图像像素点分类。该算法存在以下缺陷:1)选择像素点周围的像素块作为该像素点的输入数据时,会增加模型的储存空间;2)图像块大小决定感知域大小,当像素点的图像块选择较大时,不仅计算量会成倍增加,而且还占用更多的内存空间,导致模型训练效率低下;而当像素点图像块选择较小时,又会因感知域较小,只能提取到图像的部分特征,导致图像分割效果欠佳;3)相邻像素点的像素块中包含很多重合的像素点,在图像卷积计算过程中致使计算冗余,降低网络的运行效率;4)卷积神经网络模型中的全连接层[16]附带的大量权重和偏置参数将进一步降低网络的训练效率。基于卷积网络存在的以上问题,卷积神经网络很少被用来解决图像分割问题。
直到2015年,Long等开发了一种能自动将图像目标对象分割出来的全卷积神经网络(FCN)[17],它在没有全连接层的情况下实现了像素点分类,并获得较好的分割效果。全卷积神经网络是端到端的网络模型,在分割精度和速度方面相较于卷积模型都有明显提高。其关键技术是在卷积层或池化层后面紧接反卷积层,反卷积层通过上采样操作使输出层的图像大小与原始图像相同,这种改变给分割模型带来了以下优点:1)网络输入层支持任意大小的图像,不要求所有训练集和测试集的图像大小必须相同,使模型具有更强的泛化能力;2)避免了利用像素周围的像素块作为模型的输入数据,减少了网络的储存空间,使网络训练效率大大提高;3)利用卷积操作在整幅图上提取全局特征,能有效提高图像的分割精度。
全卷积神经网络的层级结构如图5所示,从图中可以看出,全卷积神经网络的编码阶段通过卷积、池化组合实现了图像的特征提取,且在编码阶段的第5次池化运算后,图像大小变成输入图像的1/32,为了实现图像分割,即图像像素级分类,需要对卷积、池化后的特征图采取反卷积操作(上采样),依据上采样具体操作流程的差异将网络命名成FCN-32s、FCN-16s和FCN-8s。FCN-32s是把编码阶段的特征提取结果直接进行32倍的反卷积操作,使其恢复到原图大小,该网络模型对图像细节部分处理过于粗糙,分割后的目标对象比较模糊,效果不佳。FCN-16s首先将卷积、池化阶段的特征提取结果进行2倍反卷积操作,然后把反卷积计算结果与第四次池化操作后的特征图相结合,最后针对结合后的结果进行16倍反卷积操作得到图像分割结果,该网络模型分割效果优于FCN-32s。FCN-8s首先将卷积、池化阶段的特征提取结果进行2倍反卷积操作,把反卷积计算结果与第四次池化操作后的特征图相结合,然后利用2倍反卷积操作处理上述结果,再将其与第三次池化操作后的特征图相结合,最终针对结合后的结果进行8倍反卷积操作得到图像的最终分割结果,该网络模型分割结果优于FCN-16s。

图5 全卷积神经网络结构
2.2 BCI-AS全卷积模型
为了更好地提取图像中的目标裂缝,本文提出一种基于全卷积神经网络的桥梁裂缝图像自动分割模型(Bridge Crack Image-Automatic Segmentation, BCI-AS),BCI-AS全卷积模型依据关键技术可以分为收缩路径和扩张路径两部分,收缩路径主要通过多个卷积层以及池化层的组合来提取重要特征,扩张路径主要利用反卷积操作还原图像大小并实现目标裂缝的提取,该网络模型的框架结构如图6所示。
从图6可以看出,除去输入层和输出层,BCI-AS模型包含9个模块,具体内容如下:
输入层的输入对象是经过预处理后大小为L×L×1的图像。
第一模块由两个卷积层以及一个池化层构成,两个卷积层均有64个卷积核。除了输出层以外,模型中所有卷积层都利用“Relu”激活函数,卷积核窗口均为3×3,步长为1;模型中所有池化层均采用最大池化的方式,池化模板为2×2,步长为2。第一模块输出特征图大小为(L/2)×(L/2)×64。
第二模块的层级结构和第一模块相似,区别在于这两个卷积层均有128个卷积核,即两个卷积操作后得到图像的128个特征。第二模块输出特征图大小为(L/4)×(L/4)×128。
第三模块的层级结构与第二模块相似,只是两个卷积层的卷积核数量不同,该模块卷积核的个数为256。第三模块输出特征图大小为(L/8)×(L/8)×256。
第四模块的层级结构与第三模块相似,也是两个卷积层的卷积核数量不同,该模块卷积核的数量为512个。第四模块输出特征图大小为(L/16)×(L/16)×512。
第五模块仅有两个卷积层,它们的卷积核数量都是1 024个。该模块没有池化层,输出特征图大小为(L/16)×(L/16)×1 024。
第六模块由一个反卷积层、一个特征组合层和两个卷积层构成,其中,所有模块中反卷积层的卷积核都为3×3,步长为2。该模块反卷积操作后,图像大小扩大一倍,得到的图像特征数量为512;特征组合层是将本模块上采样层得到的结果与第四模块卷积操作后得到的特征组合起来,将图像的特征扩展一倍,此时图像特征数量为1 024;经过两个卷积操作后,图像的特征数量变为512个。第六模块输出特征图大小为(L/8)×(L/8)×512。
第七模块的层级结构和第六模块相似。该模块反卷积操作后,图像相较上一模块扩大一倍,得到的图像特征数量为256;特征组合层是将本模块上采样层得到的结果与第三模块卷积操作后得到的特征组合起来,将图像的特征扩展一倍,此时图像特征数量为512;两个卷积层操作后,得到图像的256个特征。第七模块输出特征图大小为(L/4)×(L/4)×256。
第八模块的层级结构与第七模块相似。该模块反卷积操作后,图像大小相较于上一模块扩大一倍,得到的图像特征数量为128;特征组合层是将本模块上采样层得到的结果与第二模块卷积操作后得到的特征组合起来,将图像的特征扩展一倍,此时图像特征数量为256;两个卷积层操作后,得到的特征数量为128。第八模块输出特征图大小为(L/2)×(L/2)×128。
第九模块的层级结构与第八模块相似。该模块反卷积操作后,图像大小相较于上一模块扩大一倍,得到的图像特征数量为64;特征组合层是将本模块上采样层得到的结果与第二模块卷积操作后得到的特征组合起来,将图像的特征扩展一倍,此时图像特征数量为128;两个卷积层操作后,得到的特征数量为64。第九模块输出特征图大小为L×L×64。
输出层只有一个卷积层,其中卷积核窗口为1×1,卷积核数量是2个,即图像的前景(目标裂缝)与背景,激励函数为“Sigmoid”。最终输出图像大小为L×L×2。
本文采用Python语言并调用TensorFlow深度学习框架来搭建BCI-AS卷积模型。
2.3 训练与分割结果
2.3.1数据集的准备
训练BCI-AS全卷积网络模型前,第一步,选取上述预处理后的GPM数据集制作相应的标签图像,即将图像中的裂缝用白色(像素灰度值255)标记出来,图像的其余背景部分设置为黑色(像素灰度值为0),并将标记好的图像保存为PNG格式;第二步,将标记好的标签图像与数据图像一一对应起来并进行编号;第三步,对训练数据进行批量处理,即数据的batch操作,批量输入多张训练图像,并且输入数据中的图像与标签一一对应,经过上述步骤后就得到BCI-AS模型的数据集。
2.3.2模型超参数的设置
本文以训练过程的损失函数值和准确率来评判模型训练效果,以测试的准确率来评判模型的泛化能力,然后通过对比不同参数下模型的测试结果,在Tensorflow深度学习框架中调用sparse_softmax_cross_entropy_with_logits函数作为训练BCI-AS模型的损失函数,采用自适应矩(Adaptive Moment Estimation)依据训练情况动态调整学习率,初始学习率(init_learning_rate)设置为1×e-3,训练批次(batch_size)大小为6,训练轮数总计3 000次。
2.3.3模型训练结果
随着训练过程的推进,经过3 000次迭代,分割准确率达到94.45%。最终模型训练阶段的损失函数值和准确率的变化曲线如图7和图8所示。
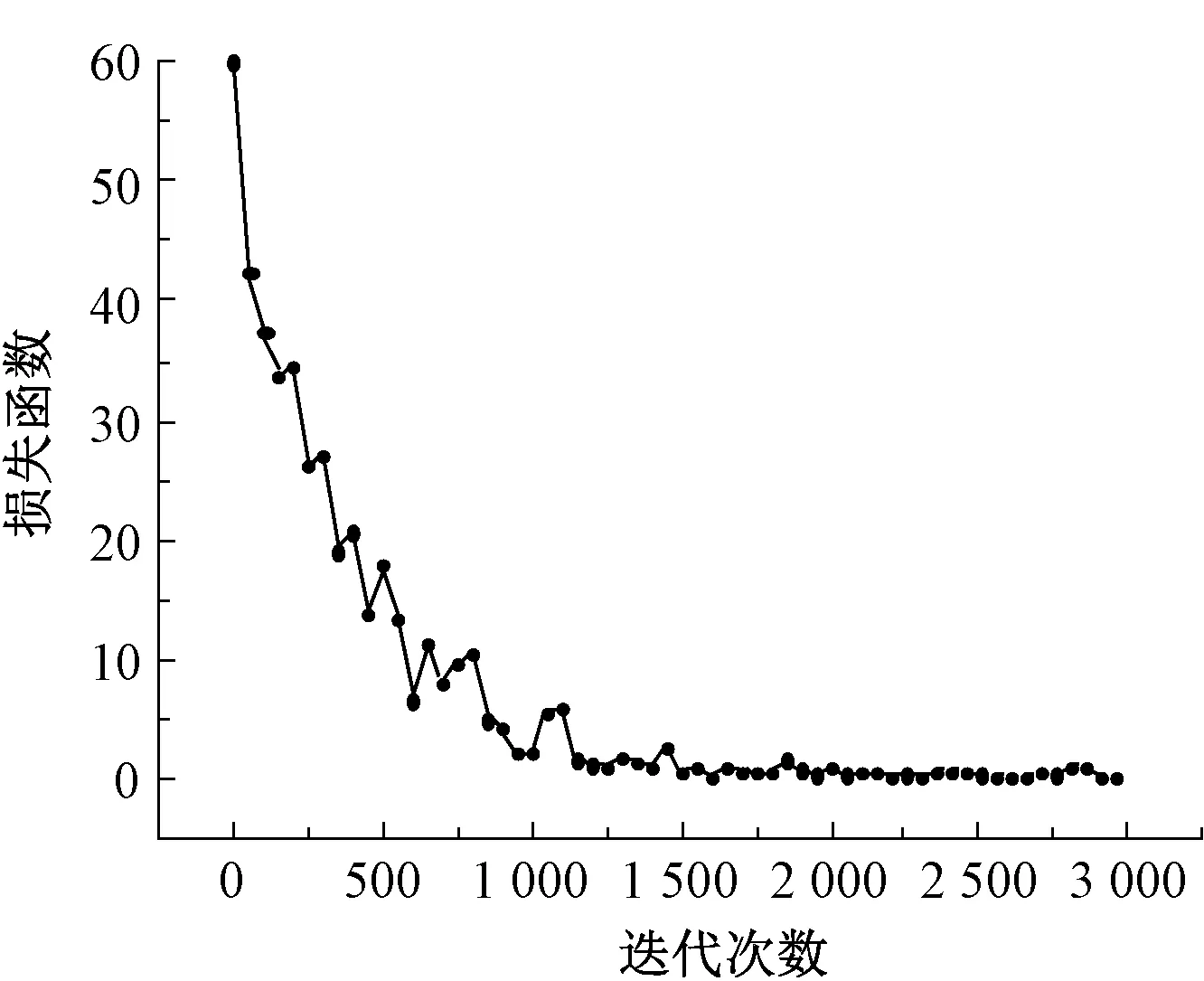
图7 BCI-AS模型训练损失函数变化曲线

图8 BCI-AS模型训练准确率变化曲线
2.3.4图像分割结果
将图像输入到训练完毕的全卷积神经网络分割模型中,图像的分割效果见图9。

a—预处理后的图像;b—分割后的效果。
由图9可以看出,基于全卷积神经网络分割算法定位精度高,噪声相对较少,分割后裂缝具有良好的连续性,能为后续裂缝几何参数计算做好充分准备。另外,该算法只需在训练时调整超参数,待模型训练好后,可直接对裂缝图像进行分割,操作方便,在处理大批量图像时具有显著优势。
3 裂缝宽度测量
3.1 连通域分析
连通域标记是分析二值图像的重要手段,它主要通过特定的规则标记二值图像中的目标对象,让图像中每个单独连通的目标区域成为有特定标签的块[18],进而计算各个标识块的几何特征值,最终达到去除噪声或对目标区域进行分析计算的目的。
由于像素是分析二值图像的基本单位,它的邻域范围内有8个像素点。根据邻接像素点的数量和位置的差异,连通域标记可以具体分为4连通域标记和8连通域标记,其中,4连通域标记的4个位置对应中心像素的左、右、上、下4个像素点,8连通域标记的8个位置对应中心像素的左上、上、右上、左、右、左下、下、右下8个像素点,上述两种连通域标记的邻接关系如图10所示。

a—4连通;b—8连通。
连通域标记是对目标对象进行几何特征分析的前提,它的实质就是依序扫描整张图像,然后将目标像素点编号标记,同一连通域的像素点使用相同的编号。若M为裂缝二值图像,分别利用4连通域和8连通域对其进行标记,标记后的结果分别为M1和M2(0、255为图像的灰度值,A、B、C为标记后连通域的编号),如图11所示。

图11 4连通域和8连通域的标记结果
从图11连通域的标记结果可知,采用4连通和8连通标记结果具有很大差异,针对目标裂缝自身特性以及后续计算的便利性,本文采用8连通进行连通域的标记,通过Open CV2中的findContours()函数来检测图像中的连通域,得到返回参数Contours,利用Contours可以获取各个连通域的面积、最小外接矩形、周长、矩形度、最小外接椭圆的长短轴比和圆形度等特征参数。
在图像分割操作后,对得到的二值图像采用8连通域进行标记,并利用红色的最小外接矩形框出二值图像中的每个连通域,同时对每个连通域编号,连通域标记编号后的二值图像如图12所示。

a—形态学处理后裂缝;b—最小外接矩形框出的裂缝。
图12中各个连通域的几何特征值的计算结果如表1所示。

表1 二值图像连通域几何特征计算结果
3.2 剔除噪声区域的连通域
由图12和表1中各个连通域的数量和对应的几何特征值可以看出,经过分割后的裂缝二值图像中仍然存在部分噪声,对后续桥梁裂缝相关信息的计算带来干扰。本文主要利用桥梁裂缝自身的特性估算出裂缝连通域特征参数的大致范围,通过连通域特征参数将噪声连通域删除,得到无噪声的裂缝二值图像,为后续裂缝宽度的计算奠定坚实的基础。
混凝土桥梁表面的裂缝主要呈现细长连续的线性形态,其面积明显大于噪声的面积,分布是随机的、不规则的、比较复杂的。
根据裂缝特性,具体通过以下四点来识别目标裂缝:
1)二值图像中,噪声连通域的面积比裂缝小,可以设定一个阈值T,当连通域的面积不超过设定阈值T,将此连通域视为噪声区域,并将其删除。
2)大多数情况下,桥梁裂缝在图像中呈现细长的线性形态,因此其最小外接矩形的长宽比通常比较大。
3)裂缝大多呈一定的弯曲状,另外,由于混凝土桥梁裂缝宽度都很小,它呈现在图像中也比较纤细,所以,它的连通域矩形度值也比较小。
4)裂缝形状是复杂的、不规则的和无规律可循的,因此它的连通域圆形度值也很小。
根据裂缝连通域的特性,本文将面积S<300、最小外接矩形长宽比P1<5、矩形度P2>0.5、圆形度D>0.5的连通域判定为噪声,把这些判定条件加入到程序中,并使用 cv2.drawContours(img,[contours[i]], 0, 0,-1)函数把判定为噪声的连通域变为背景,最终得到剔除噪声后的效果如图13所示。

a—分割后的二值图;b—剔除噪声区域后的二值图。
3.3 裂缝宽度计算
裂缝宽度是评价桥梁结构安全的重要指标之一,当桥梁裂缝宽度超过限值时,部分混凝土会退出工作,导致预应力钢束和普通钢筋承受更大的负荷,此外,超过限值的裂缝还会造成钢筋锈蚀,危及结构安全。
近几年研究者提出多种计算裂缝宽度的方法,代表性算法以以下两类为主:王聪雅直接采用投影法进行计算,即将裂缝上下边缘的最大像素点数,经比例计算后的值作为裂缝宽度[19]。王鹏利用裂缝连通域面积与裂缝细化后长度的比值作为裂缝平均宽度。但是由于大多数情况下,桥梁结构裂缝是不规则的曲线,裂缝不同位置的宽度差别很大,并且裂缝宽度方向需垂直于裂缝走向,所以采用以上两种方法进行裂缝宽度计算存在较大误差[20]。为了使计算结果更准确,本文提出利用基于投影技术的最小二乘拟合中心线法计算裂缝宽度。
基于投影技术的最小二乘拟合中心线法是在投影法的基础上,依据目标裂缝上下边缘像素点的坐标,进而获得裂缝中心线像素点的坐标,然后利用最小二乘法拟合裂缝中心线的函数,依据函数表达式可知裂缝中心线的斜率,进而得到裂缝切线方向的夹角,最终计算出裂缝的实际宽度。基于投影技术的最小二乘拟合中心线法的裂缝宽度计算示意如图14所示,其具体算法如下:

图14 基于投影技术最小二乘拟合中心线法裂缝宽度的计算示意
1)将分类后的二值图像进行旋转。将纵向裂缝图像旋转90°,斜向裂缝图像旋转45°,横向裂缝图像不用旋转。
2)将旋转后图像的水平方向作为横坐标(X轴),然后,把图像向X轴投影,得到横坐标下裂缝的像素点数。


5)图像第n列裂缝的宽度值wn=w′ncosθ。
6)重复步骤3)至步骤5),直到扫描完整张图像。
7)最终取max(wn)作为该条裂缝的宽度值。
按以上步骤计算桥梁裂缝宽度,把裂缝的上述信息标记在图中,如图15所示。

L和W分别为裂缝的计算长度和宽度。
为了更好地对比上述两种方法计算结果的准确率,本文将实测结果与图像处理结果进行对比,结果如表2~4所示。

表2 本文方法裂缝宽度测量结果
从表2中,基于投影技术的最小二乘拟合中心线的方法计算结果相对误差较小,相对误差都在6%以下,检测准确率较高,并且该算法计算速度快。
从表3和表4可看出,由于文献[19]的方法没有准确地定位裂缝的边界,因此准确率偏低。文献[20]的方法由于是通过面积和周长的比值作为裂缝的平均宽度,产生的随机误差也相对较大。因此本文算法准确率更高。为了进一步验证利用基于投影技术最小二乘拟合中心线算法对裂缝宽度计算的精度,在200张原图上利用本文算法统计检测结果与实际测量结果并进行对比。试验结果表明:200张裂缝图片宽度提取平均误差为6.76%,表明本文提出的算法具有理想的计算能力。

表3 文献[19]方法裂缝宽度测量结果

表4 文献[20]方法裂缝宽度测量结果
4 结束语
混凝土结构表面裂缝的提取一直是图像处理中的难点[21],早期的基于阈值和基于边缘检测算法在混凝土桥梁裂缝分割中应用颇多,但存在去噪效果不明显、分割后裂缝连续性较差等问题,这会直接影响到最终裂缝提取的准确性。近年来,由于深度学习模型在广泛的视觉应用中取得了成功,已经有大量的工作致力于开发使用深度学习模型的图像分割方法。基于此,本文提出一种基于全卷积神经网络的桥梁裂缝图像自动分割模型(BCI-AS)和一种基于投影技术的最小二乘拟合中心线的裂缝宽度测量算法,通过对比分析,研究得到的主要结论如下:
1)目前桥梁裂缝检测方面缺乏开放的、通用的大样本图像数据库,而深度学习的准确性依赖于大规模数据集样本的训练,因此本文利用无人机摄取了大量桥梁裂缝图像,但是数据量还远远不够,开展数据样本采集整理是未来主要任务之一。
2)由于图片中光照和噪声的干扰,将会很大程度上影响裂纹的提取准确性,因此图像增强是裂缝分割的前期和不可缺少的工作。本文提出了GPM图像预处理方法,然而存在的局限性在于其对于单一或小样本图像数据处理效果较好,而对大规模图像数据集做统一处理自适应性较差,因此开展针对BCI-AS模型训练的大规模图像自适应预处理方法是未来的重要任务。
3)BCI-AS全卷积模型分割结果显示,该算法能高效准确地提取裂缝,同时保证了裂缝的连续性,为后续裂缝宽度计算做好充分准备。
4)对分割后的二值图像进行连通域标记,同时,计算连通域的几何参数,通过裂缝连通域所具有的特性设定阈值,剔除噪声区域的连通域,获得纯净的裂缝二值图像。
5)本文提出基于投影技术的最小二乘拟合中心线的方法进行计算,经实测验证,计算误差在7%以内,证明了本算法计算的有效性。
