近红外光谱技术结合教与学算法优化极限学习机实现烤烟等级判定
2022-07-22沈欢超耿莹蕊倪鸿飞吴继忠刘雪松
沈欢超,耿莹蕊,倪鸿飞,王 辉,吴继忠,廖 付,陈 勇,刘雪松*
(1.浙江大学 药学院,浙江 杭州 310058;2.浙江大学 智能创新药物研究院,浙江 杭州 310018;3.浙江中烟工业有限责任公司技术中心,浙江 杭州 310008)
烤烟作为工业卷烟的重要原料,等级判定是其质量评价的重要工作。烟叶等级的主要考量因素有烟叶的着生部位、颜色等,国家烤烟标准将其分为42个等级。目前,烟叶的分级主要依赖行业专家的感官评判,而个人的主观差异将影响分级结果。因此,采用智能化手段实现烟叶等级判定是烟草工业评判烟叶品质的未来发展趋势。
近红外光谱技术(NIRs)具有快速、无损、操作简便等优点,已广泛应用于农业[1-2]、石化[3-4]、食品[5-6]、医药[7-9]等领域,是一种极具潜力的化学分析手段。不少学者已将其应用于烤烟等级判定领域,李士静等[10]比较了不同预处理方法、不同分类模型以及不同特征波段数量对2 个数据集烟叶分类正确率的影响,但烟叶上部与中部数据集的样本容量较小。王超等[11]基于2018 年不同产地的768 份烤烟烟叶样品,分别建立了全国和分产区的偏最小二乘判别分析(PLS-DA)等级预测模型,在类别量化中采用连续数字编码方式,使用定量模型实现质量定性判别具有一定创新性,但其建立的模型预测准确度较低。宾俊等[12]首次提出基于品质相似、价格接近的烟叶分组方法,将极限学习机(ELM)应用于烤烟烟叶的分级判别,但与常规的烟叶分级标准不同,可推广性不强。
极限学习机由Huang 等[13]于2006 年提出并完善,是一种单隐层前馈神经网络(SLFNs),具有学习速度快、泛化能力强的优点,在函数逼近与模式分类领域有着广泛的应用[14-15]。教与学优化(TLBO)算法由Rao 等[16]于2011 年提出,是一种模拟课堂教学的基于群体的启发式优化算法。该算法的参数设置简单,收敛速度快,精度高,在许多工程优化问题中得到了应用[17-18]。
本研究基于近红外光谱技术,比较了竞争性自适应重加权采样方法[19](CARS)、蒙特卡洛无信息变量消除法[20](MC-UVE)以及随机青蛙算法[21](RF)3种变量筛选方法,通过与常规PLS-DA模型的比较验证了ELM模型的优势,首次将TLBO算法用于ELM烤烟等级判定模型优化,在降低建模成本的同时,提高了SLFNs的泛化能力,实现了对广泛性分布烤烟样本的等级判定。
1 实验部分
1.1 数据采集
烟叶样本采集于2016~2018 年,包含来自全国13 个省份的上部烟叶(B)、中部烟叶(C)和下部烟叶(X),共937 份,样本产地来源分布见表1。烟叶的近红外光谱数据及其等级标签均由浙江中烟工业有限公司提供。使用MATLAB(R2020b)软件进行数据处理。

表1 样本的不同产地来源及各部位分布Table 1 Distribution of samples from different places of origin and parts
1.2 基于TLBO-ELM的烤烟等级判定模型
1.2.1 极限学习机(ELM) ELM 是一种新型的快速学习算法,包含输入层、隐含层和输出层(如图1)。在算法运行过程中,随机产生输入层到隐含层的权值以及隐含层节点的偏置,计算得到隐含层到输出层的权值。

图1 ELM的基础结构Fig.1 Basic structure of ELM
给定训练集D= {(xi,ti)},i= 1,2,...,n,xi是d×1 的输入向量,ti是k×1 的目标输出向量,对于具有m个隐含层节点数的SLFNs 与激活函数g(x)的数学模型可表示为:
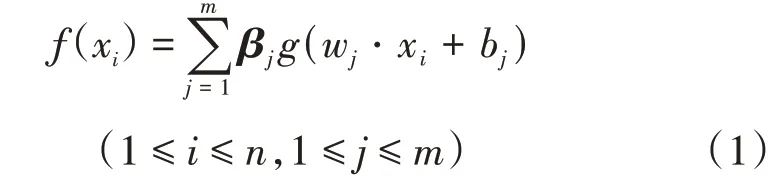
其中,βj=[βj1,βj2,...,βjm]T,是连接第j个隐含层节点和输出节点的权值向量;wj=[wj1,wj2,...,wjd],是连接输入节点与第j个隐含层节点的权值向量;bj是第j个隐含层节点的偏置。wj和bj均随机产生,且满足:

式(2)可简写成:

其中

且

H是隐含层的输出矩阵,H的第i行是输入xi时隐含层的输出向量,H的第j列是输入为x1,x2,...,xn时第j个隐含层节点的输出向量。T是目标输出矩阵。
式(3)的最小二乘解为:

H†是H的广义逆矩阵。
ELM算法如下:
输入:训练集D={(xi,ti)},激活函数g(x),隐含层节点数m。
输出:隐含层到输出层的权值矩阵β。
第一步:随机产生输入权值wj和偏置bj,j=1,2,...,m;
第二步:计算隐含层输出矩阵H;
第三步:计算输出权值矩阵β=H†T。
1.2.2 教与学优化算法(TLBO) TLBO 的优化过程包括教师阶段和学习者阶段。在教师阶段,每个学生均向最优秀的个体学习;在学习者阶段,每个学生均以随机的方式向其他学生学习。在TLBO 中,种群被视为一类学习者,每个学习者代表着优化问题的一种可能的解决方案,成绩代表着适应度值。在教师阶段,教师T是在该种群中具备最大适应度值的解决方案,M是该班级的平均成绩。学习者试图通过教师的教学提高班级的平均成绩。对于第i个学习者Xi,候选解决方案newXi的计算公式如下:

ri是在[0,1]之间产生的随机数;TF是决定M值的教学因子,取值为1或2。
在学习者阶段,每个学习者通过与随机选择的学习者进行互动来提高成绩。Xj(i≠j)是从种群中随机选取的学习者,若要优化的目标函数值ƒ(Xj)>ƒ(Xi),则优化的解决方案计算公式如下:

反之,则:

最终得到最佳解决方案newX。
1.2.3 TLBO-ELM 模型 本研究旨在通过TLBO 算法对ELM 运算过程中的隐藏层节点数进行寻优,使TLBO-ELM烤烟等级判定模型达到更高的分类正确率。
TLBO-ELM算法如下:
第一步:输入训练集D={(xi,ti)},激活函数g(x),学生数nPop,最大迭代次数MaxIt,变量数nVar,变量取值范围VarMin及VarMax;
第二步:初始化,每次TLBO的迭代结果代表一个包含ELM参数(权值wj和偏置bj)与隐藏层节点数的解;
第三步:使用适应度函数(本研究中即分类正确率的倒数)对所有候选解决方案进行评估,当迭代次数达到最大值时,停止搜索过程并返回寻优结果。
2 结果与讨论
2.1 异常点剔除
由于光谱扫描过程可能存在人为操作差异或仪器误差导致采集光谱异常,通常采用化学计量学方法剔除异常值。本研究采用蒙特卡洛交叉验证(MCCV)方法对937个样本进行异常点剔除。
根据文献[22],剔除均值(Mean)大于1、标准偏差(STD)大于0.1的样本。本实验剔除了24个异常点,剩余913个样本。剔除的异常点编号为881、519、922、520、902、462、19、439、883、621、436、512、389、894、526、897、654、878、137、392、277、346、770、928(见图2)。

图2 蒙特卡洛剔除异常点的结果Fig.2 The results of Monte Carlo elimination of outliers
2.2 样本划分
在除去异常点后,采用Kennard-Stone(K-S)算法[23]以6∶2∶2 划分训练集、验证集及测试集。样本划分结果见表2。

表2 样本划分结果Table 2 The results of samples division
2.3 光谱预处理
为减少光谱噪声以及基线漂移等对实验结果的影响,本研究采用Savitzky-Golay 卷积平滑[24]方法进行光谱预处理(number of points=15,polynominal order=2,derivative order=1)。
2.4 变量筛选
为得到预测能力更强、稳健性更好的校正模型,首先对光谱数据中的冗余信息进行剔除。本研究比较了CARS、MC-UVE以及RF 3种变量筛选方法。上述3种变量筛选方法最终从1 609个变量中分别筛选出151、66、223个关键变量。
为比较不同变量筛选方法对烤烟等级判定建模效果的影响,设置相同参数:激活函数采用Sigmoid(sig)函数,隐藏层节点数设为50,分别建立ELM 模型。考虑到ELM 建模过程中存在一定的随机性,以运行10次得到的分类正确率均值作为建模效果的评价指标,实验结果见表3。

表3 不同变量筛选方法的ELM分部位模型效果Table 3 ELM model effect of different variable screening methods in different parts
从正确率的均值结果来看,RF 法优于CARS 法以及MC-UVE 法,但t检验结果表明,3 种变量筛选方法的结果无显著性差异。考虑到3 种变量筛选方法均在一定程度上降低了光谱数据维度,且在模型效果无显著性差异的情况下,MC-UVE 法从原光谱的1 609个变量中筛选出66个关键变量,大大降低了计算成本,故采用MC-UVE 法进行变量筛选。为检验该模型的泛化能力,使用测试集对模型进行外部验证,参数设置保持一致,以运行10 次的结果均值作为评价指标,实验结果见表4。外部验证结果表明该模型表现良好,泛化能力好。

表4 测试集检验ELM分部位模型的效果Table 4 The ELM model effect verified by testing set in different parts
2.5 PLS-DA和ELM
通过建立常规的PLS-DA烤烟等级判定模型,与已建立的ELM烤烟等级判定模型比较,验证ELM模型的优势与应用意义。
PLS-DA 的最佳潜变量数根据十折交叉验证确定为24(RMSECVmin=0.375 7)。采用与ELM 模型相同的光谱预处理方法(SG卷积平滑,number of points=15,polynominal order=2,derivative order=1)及变量筛选方法(MC-UVE)筛选出对应的关键变量,并进行计算。ELM 与PLS-DA 等级判定模型的结果比较见表5。PLS-DA模型训练集、验证集以及测试集预测结果相应的混淆矩阵见图3。

表5 PLS-DA与ELM分部位模型效果的比较Table 5 Comparison of the effects of PLS-DA and ELM models in different parts
表5结果显示,使用ELM建立的等级判定模型训练集、验证集以及测试集的分部位分类正确率均优于传统的PLS-DA法。由图3可知,PLS-DA建立的等级判定模型对下部烟叶的分类正确率较低,多误判为中部烟叶,降低了总体分类正确率。因而本研究使用ELM建立等级判定模型具有现实意义,在此基础上使用TLBO进行优化,突出了本研究的优势。

图3 PLS-DA模型预测结果的混淆矩阵Fig.3 Confusion matrix of the prediction results about PLS-DA model A:training set;B:calibration set;C:testing set
2.6 TLBO-ELM模型建立
尽管前期建立的ELM 模型泛化能力较好,但其分类正确率不佳,因而考虑采用TLBO算法对其隐含层节点数进行优化。将隐藏层节点数最大值设为250,ELM 激活函数g(x)= ‘sig’,TLBO 参数设置如下:nPop=30,MaxIt=50,nVar=1,VarMin=30,VarMax=250。参数寻优过程如图4 所示,得到最佳隐藏层节点数为111,适应度最小值为1.109 1,验证集的分类正确率提升至90.16%,相较于ELM 模型(83.28%)提升了6.88%。测试集对该模型进行外部验证,分类正确率达89.07%,相较于ELM模型(87.38%)略有提高,混淆矩阵结果见图5。

图4 TLBO-ELM的参数寻优过程Fig.4 Parameter optimization process of TLBO-ELM
由图5 可知,从测试集的预测结果分析,上部烟叶的分类准确率为89.13%,其中10.87%被错分为中部烟叶;中部烟叶的分类准确率为89.83%,其中7.63%被错分为上部烟叶,2.54%被错分为下部烟叶;下部烟叶的分类准确率为84.21%,其中15.79%被错分为中部烟叶。尽管存在错误预测的情况,但普遍被误判为相邻类,分类效果在可接受的范围内。且由于整体样本量不够大,下部烟叶样本总体偏少,导致分类结果的偶然性影响增大,在一定程度上降低了总体分类正确率。

图5 ELM模型测试集预测结果的混淆矩阵Fig.5 Confusion matrix of the prediction results about ELM model testing set
3 结 论
本研究基于NIRs技术,以2016~2018年来自13个省份的937个烤烟样本为研究对象,比较了CARS、MC-UVE、RF 3 种变量筛选方法的ELM模型效果,通过与PLS-DA模型进行比较验证了ELM模型的优势,并通过TLBO 算法对ELM 模型进行优化,建立了烤烟等级判定模型。首次将TLBO-ELM 应用于烤烟等级判定,TLBO 寻优过程不仅大大减少了ELM 模型反复尝试隐藏层节点数的时间,而且将验证集的分类正确率由83.28%提升至90.16%,相较于ELM 模型,正确率提升了6.88%。测试集的外部验证效果良好,表明TLBO-ELM 模型泛化能力强,为烤烟分级提供了一种新的思路。
