基于深度嵌入聚类的ICU患者生理数据缺失插补
2022-07-21李建华朱泽阳徐礼胜孙国哲
李建华, 朱泽阳, 徐礼胜,2, 孙国哲
(1. 东北大学 医学与生物信息工程学院, 辽宁 沈阳 110169; 2. 沈阳东软智能医疗科技研究院有限公司,辽宁 沈阳 110167; 3. 中国医科大学附属第一医院 心血管内科, 辽宁 沈阳 110001)
重症监护单元(intensive care unit,ICU)是监护和抢救危重症患者的特殊医疗单元,被称为生命的最后一道防线[1].自电子病历出现以来,重症领域的研究者们可以借助于回顾性的ICU患者生理数据开展相关的研究,例如死亡风险评估、生存期预测、器官衰竭预测等[2].这些研究都是依托于电子病历,因此数据质量对研究结果影响很大.
对ICU患者数据而言,存在缺失是常见现象.造成数据缺失的原因是多样的,常见的有人为原因和设备故障等[3].数据缺失会造成样本信息大量损失,进而影响数据分析的结果,因此处理数据缺失是数据分析任务的重中之重.目前相关研究中对缺失值的处理相对简单,El-Rashidy等[4]在进行ICU患者死亡预测模型的研究中,将存缺的样本直接剔除,使用无缺失的样本构建模型,这种做法虽然简单,但是浪费了大量的可用信息.在更多的相关研究中[5-7],均值插补法被用于缺失值插补,这种方法确实能减少缺失对样本的影响,但是如果缺失的样本较多,会造成样本间的差异性被缩小.
针对这些问题,本文提出基于深度嵌入聚类构造邻近度矩阵的缺失值插补算法,本算法可以有效地控制用于替代缺失值的样本数量,更适用于ICU患者数据.
1 实验数据与方法
1.1 实验数据
本研究的所有样本均来自于MIMIC(medical information mart for intensive care)数据库[8].该数据库由贝斯以色列女执事医疗中心、麻省理工学院、牛津大学和麻省总医院的急诊科医生、重症科医生、计算机科学专家等共同建立.本文使用的MIMIC-III V1.4版本包括了2001—2012年期间在贝斯以色列女执事医疗中心重症监护室内接受治疗的约40 000名患者的数据,以关系型数据库表格形式存储,共计26张数据表,包括了人口统计学信息、生理数据、精神状态、用药信息、治疗方式、患病史等重要数据.
此23组变量均存在不同程度的缺失,图1描述了这些特征的缺失情况,图中缺失率由式(1)定义:
(1)
其中:M_rate为缺失率;M_sample为存在缺失的样本数量;All_sample是样本总数.
本文选取了数据库中23组特征均不存在缺失的5 260例样本作为研究对象,首先生成多组缺失率不同的人造缺失数据,然后使用不同方法生成插补后的数据,比较这些数据与原始数据的相似性,进而比较插补方法性能.

图1 所选特征的缺失情况
本文提出一种基于深度嵌入聚类的K近邻插值算法.本算法以深度嵌入聚类为核心,通过多次聚类构造样本邻近度矩阵,再自适应地选择缺失样本的K个近邻样本,用这些近邻样本的平均值填补缺失.本算法无需手动选择K值或聚类的簇数,且能有效控制存缺样本的邻居数量,从而有效解决均值插补方法缩小样本间差异的问题.
1.2 K近邻插值法
在死亡率预测的相关研究中,研究者大多使用均值插补缺失值,因为均值插补计算简单,效果尚可.均值插补很容易降低样本间的差异性,而K近邻数据填充法可以弥补这一不足.K近邻数据填充法的核心思想是利用与含缺失值样本近似的其他样本的值来填补缺失值,常见方法是先根据某种距离度量计算得到样本的“邻居”,然后用K个近邻样本的均值来替代缺失值.求解K近邻的过程也可以视作聚类的过程,先对数据聚类,再在类内做插补.
1.3 栈式自编码器
在解决聚类任务时,一般步骤为先将高维特征映射到低维空间,再对低维特征使用聚类算法.因为在高维空间中,样本间的距离难以衡量,即使距离较远的两个样本在某个平面上也可能是近邻[10],所以降维是聚类前的必要步骤.主成分分析(principal component analysis,PCA)是一种常用的降维方法,其基本思想是在特征空间中找到一条轴,使特征空间的点映射到这条轴上后的方差最大化.PCA作为一种基本的线性降维方法,没有参数的限制,大大降低了计算成本,但是学习到的特征较为简单.
自动编码器(auto encoder,AE)作为一种深度神经网络,在限制了隐含层的维度后,可以学习到比PCA更全面的特征.由于AE学习到的特征是原特征空间在连续非交叉曲面上的投影,相比于PCA学习到的低维超平面投影,AE的隐含层表达包含原特征的更多信息[11].在这种考虑下,诞生了深度聚类网络,即先使用AE学习特征的低维表征,再使用聚类器完成聚类.深度聚类网络(deep clustering net,DCN)本质上是一个分步模型,降维和聚类是两个独立的步骤.深度嵌入聚类则是在DCN的基础上,使用聚类模型的损失函数训练AE的编码过程,使AE能够学习到对聚类任务友好的低维特征[12].图2为深度嵌入聚类模型的结构,其中Xi表示输入特征,f(x)表示编码函数,g(x)表示解码函数,l(X,Y)是自编码器输入和输出的重构误差函数,f(Xi)是原特征在自编码器隐含层的表征,也可以看作是降维后的特征,聚类器为K-means.
AE是一种无监督学习技术,其训练过程可以理解为通过编码函数对输入X进行表征学习得到原始特征的编码,再使用解码函数将编码映射到原特征空间得到重构的X′,并使X≈X′.AE相当于重构了输入,其损失函数为重构误差,如式(2)所示:
(2)
其中:N为样本个数;Xi表示输入特征;f(x)表示编码函数;g(x)表示解码函数.
因为AE的训练是最小化重构误差的过程,为了避免其简单地将输入复制给输出,考虑限制隐含层的输出维数,即限制隐含层的神经元个数,使隐含层的输出维度小于输入维度,限制各层之间能够传递的信息量,以此强制AE学习到有效的信息[13].而栈式自编码器(stacked auto encoder,SAE)则是增加隐含层的个数,扩大网络容量,使编码更复杂.

图2 深度嵌入聚类模型结构图
1.4 K-means聚类
K-means选用欧氏距离作为相似性度量,其目标函数是最小化类内样本到聚类中心的距离[14].对于样本X,假设将其分为K类,类别记作{C1,C2,…,CK},K-means的目标函数表示为
(3)
其中,μi表示类Ci的聚类中心点.
K-means最小化目函数的过程是通过迭代完成的,其步骤为
1) 在样本中随机选择K个点作为聚类中心记作μi,K为指定的聚类簇数.
2) 对于n=1,2,…,N,N为样本的总个数.
①初始化聚类簇,使Ci=φ.
②计算样本Xn到每个簇的中心的欧氏距离,将该样本归入距离最小的聚类中心所在的类.
③将所有样本分类完成后,重新计算每个簇的聚类中心,即该簇中所有样本的均值向量.
④如果聚类中心发生变化,重复步骤①到③,直至聚类中心不再发生变化或达到最大迭代次数,结束迭代.
3) 输出聚类簇.
1.5 深度嵌入聚类网络训练
深度嵌入聚类网络(deep embedded clustering,DEC)将SAE的编码函数加入K-means的损失函数中,编码函数如式(4)所示:
hi=f(Xi,W),f(·;W):RM→RR.
(4)
其中:hi是输入Xi通过多层编码后的瓶颈层输出;在此过程中特征由M维降低到R维;W记录f的全部参数,参数包括连接各层神经元的权重和每个隐含层的偏差.
将hi作为输入,更新K-means的目标函数如式(5)所示:
(5)
其中,Si表示Xi所属的聚类.
随后将此目标函数作为正则项加入SAE的重构误差函数,如式(6)所示:
(6)
其中:λ取1;g(Xi;Z)是解码函数;Z是由隐含层变换到输出层的参数;l是自编码器的重构误差.
SAE的训练过程如下,首先训练一个自编码器,得到隐含层的输出,再使用第一个自编码器的隐含层输出作为输入训练第二个自编码器,最后将所有自编码器堆叠,得到最终的栈式自编码器.如图2所示,本研究使用的SAE共5个隐含层,编码器的三个隐含层维数分别设置为30,20,10,即瓶颈层输出维度为10.通过预训练得到的瓶颈层输出训练K-means,得到初始化的聚类簇和聚类中心点,然后在求最优聚类簇和聚类中心的过程中同时优化参数W和Z,最终得到对聚类任务友好的特征表征hi.
1.6 K-means++初始化
K-means++初始化是K-means初始聚类中心选取的优化方案[15],根据K-means的聚类思想,每个样本到类中心点的距离要尽量近,并且聚类中心点之间要尽量远,K-means++算法就是考虑选取距离最远的点作为初始聚类中心.K-means++算法步骤如下:
1) 随机选择第一个点作为聚类中心,记作C1.
2) 计算每个样本Xn到C1的距离,记作D(X),计算每个样本点被选为下一个聚类中心的概率p(CX),p由式(7)定义:
(7)
3) 累加p,得到每个点被选为下一个聚类中心的概率区间,然后随机生成一个0~1之间的数,其所属的区间对应的点就被选作下一个聚类中心.
4) 重复步骤2)和3),直至选出所有聚类中心,初始化完成.需要注意,当进行步骤2)时已经产生了多个聚类中心,则需要计算样本到每个聚类中心的距离,并选择其中最小的值作为D(X).
2 实验过程
2.1 基于邻近度矩阵的K近邻插值法
本方法结合DEC与集成学习思想构造邻近度矩阵.对包含n个样本的数据X,多次使用DEC,因为聚类初始化点是随机选取的,这样多次聚类会得到不同的划分结果.假设进行了m次聚类,最终得到m个划分,定义同类别矩阵N(n×n),Nij=Nji表示样本i和样本j在m次聚类中被划分在同一类中的次数;式(8)定义了邻近度矩阵D.D度量了一个样本与其他样本被多次划分为同一类的概率,邻近指数Dij越接近1,样本i和j越有可能是近邻.
(8)
邻近度矩阵是一个对称矩阵,图3给出了矩阵示例,每行表示一个样本与其他样本的邻近程度,数值越大则两样本是近邻的概率越大,对角线元素为1.

图3 典型的邻近度矩阵
将样本及其特征构成的矩阵称为特征矩阵.对缺失值的插补算法过程如下,对特征矩阵中的每一列特征进行如下操作.
1) 计算当前特征存在缺失的样本行号,对应邻近度矩阵D的行号.
2) 对D中相应的行从高到低排序,取前K个值,计算其对应的样本在特征矩阵中的行号,获取这些样本对应的特征值.
3) 检查这K个特征值中是否存在缺失,若存在,用D中第K+1个样本对应的特征值替换,重复此步骤至此K个特征中不含有缺失值.
4) 用此K个特征值的均值代替缺失值.
相比于直接在聚类簇内使用均值插补,本方法可以通过参数K的选取控制用于计算插补值的样本数量,相当于控制聚类簇中的样本数量,同时保证了每个簇中只有一个缺失值.本方法主要参数有聚类划分次数m,每次划分的聚类簇数C以及用于计算缺失特征替代值的近邻样本个数K;根据集成聚类的相关研究[16],C取近似于m的值效果较好,一般C=m+1,本文根据重复实验选取m值为20.对K值的选取主要依据每个样本的高近邻样本的个数来选取,根据对样本的观察,选取邻近指数在[0.9, 1]之间的样本作为邻近样本,邻近样本个数K由缺失样本在规定区间内的邻居个数决定.
2.2 评估指标
本文主要使用插补后数据和原数据的相似性以及样本集内样本之间的差异性来衡量插补方法的性能.
使用余弦相似度作为相似性指标,两个n维向量A和B的余弦相似度Sθ由式(9)定义,Sθ越接近1说明两个向量越相似,使用特征矩阵行向量余弦相似度的均值表示两个矩阵的相似度.
(9)
式(10)定义了一个样本集的总体差异性指标,对一个含有N个样本集X,每个样本为Xi(i=1, 2,…,N),其含义为每个样本与其他样本的差异性的平均值.
(10)
3 结果与讨论
3.1 数据缺失对样本的影响
为了直观地展示数据缺失对样本的影响,本文使用PCA方法将原始特征映射到三维空间以便于观察,将三个维度的特征命名为f1,f2和f3.以此三个特征建立空间坐标系,其中图4是1 000个无缺失样本的空间分布,图5是原始样本人工加入5%缺失数据后在特征空间的分布情况.

图4 1 000例无缺样本在三维特征空间的分布图
如图5所示,在无缺失原始样本中人为地添加缺失值后,样本发生了肉眼可见的偏移,且样本更加分散.

图5 加入5%缺失后1 000例样本在三维特征空间的分布图
3.2 插补后与原数据的相似度对比
在PCA降维后的三维特征空间中,图6~图8分别是均值插补、中值插补和本算法插补后的数据在三维特征空间内的分布情况.
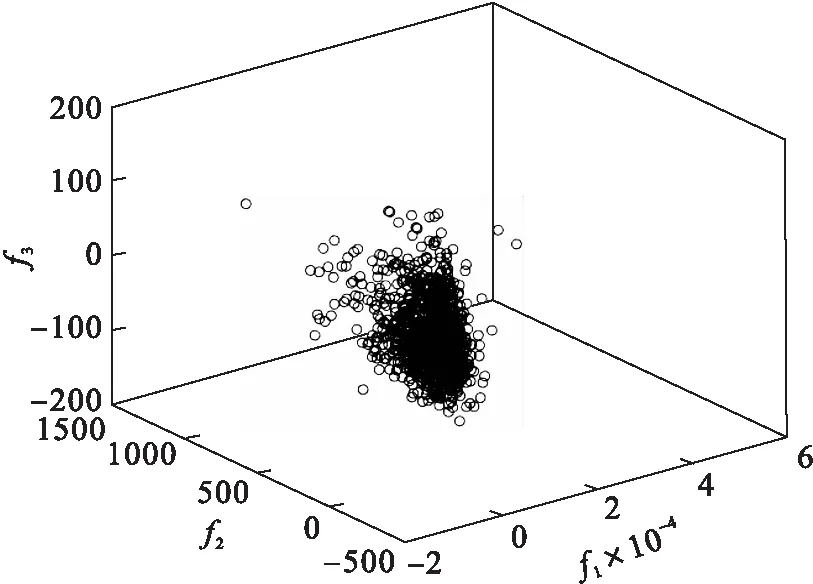
图6 使用均值插补法补缺后样本在三维特征空间的分布图
由图6~图8可知,经过插补的数据与原数据分布近乎一致, 证明插补是一种有效的预处理手段,但是与本文的方法相比,均值插补和中值插补后的数据存在细节上的不足,一些离群点出现失真.

图7 使用中值插补法补缺的数据在三维特征空间的分布图
以余弦相似度作为度量,表1比较了均值插补、中值插补、后验分布估算插补、条件均值插补和基于邻近度矩阵的插值的性能.从表中可见,本文的方法插值得到的数据更接近真实数据,在缺失率较高时这种优势更加明显.例如,当缺失率从5%升至15%时,作为对照的4种方法中性能最好的条件均值插补法,余弦相似度从0.993 2降至0.975 4,下降了1.79%;本文方法,相应从0.994 8降至0.987 5,仅下降0.73%.

图8 使用邻近度矩阵插值法补缺后样本在三维特征空间的分布图

表1 使用不同插补方法得出的数据与原数据的余弦相似度
3.3 样本间差异性分析
计算可得5 260例样本的总体差异度为0.869 7,表2给出不同插补方法得出的数据的总体样本间差异度.以均值插补法为例,对于缺失率大于10%的样本,得到的补缺数据样本间差异度明显小于原始数据.当大量样本存在缺失时,均值插补、中值插补等方法为所有的缺失值都给定相同的替代值,这种计算方法会缩小样本间差异,对后续的数据分析任务带来难度.相比之下,提出的方法在低缺失率时,可以很好地还原数据,样本间差异度十分接近原始数据;而在高缺失率时,样本差异性的缩小并不明显,说明本算法很好地还原了数据的真实情况.例如,当缺失率从5%升至15%时,4种方法中后验分布估计插补的总体样本间差异度变化最小,从0.853 9降至0.835 6,下降了2.14%;本文的方法,相应地从0.867 0降至0.860 5,仅下降0.75%,较好地保持了样本间的差异性.

表2 使用不同插补方法得出的数据的总体样本间差异度
4 结 语
ICU患者的回顾性生理数据中存在缺失值是一种常见现象,在使用数据进行统计分析时,缺失值会产生不利影响.缺失值插补是使用估计值代替缺失值,因为ICU患者生理数据本身具有变异性,生理参数值很可能不在正常值范围内,对其缺失值的插补是一项具有挑战性的工作.
本文提出了一种基于深度嵌入聚类构造邻近度矩阵的缺失值插补算法.与ICU患者回顾性数据分析的相关研究中常用的插补方法相比,本算法插补后的数据与原始数据近似程度较高.本算法能够有效地确定替代样本的数量,根据样本间差异性的对比,更好地保留了原样本的数据特性.
此外,本研究还可以在数据方面做深入工作.因为MIMIC数据库中不包含中国人的数据,对国内的ICU患者数据是否效果较好还需要进一步验证.未来将与医院积极合作,进一步验证本算法的适用性.
