基于流行学习的降维算法研究
2022-07-21陈小军
陈小军
(贵阳银行股份有限公司,贵州 贵阳 550081)
0 引言
随着M2M(Machine to Machine,M2M)、SNS(Social Networking Services,SNS)、移动互联网的兴起,人工智能(Artificial Intelligence, AI)、 模式识别( Pattern Recognition)、机器学习ML(Machine Learning,ML)、人工神经网络ANN(Artificial Neural Network,ANN 、深度学习(Deep Learning)、数据挖掘(Data Mining)、计算机视觉(Computer Vision)等已成为众多学者的研究热点。由于原始数据经常是Web 数据、图像、视频等半结构化、非结构化的高维数据,如果直接对原始数据进行清洗、分析, 很容易造成维数灾难问题(Dimension Disaster)。 因此需对高维的原始数据进行降维。 通过降维,能有效地避免维数灾难问题,提高计算效率、节省计算资源[1-3]。
现有的经典降维算法主要分为线性降维算法和非线性降维算法, 其中线性鉴别算法LDA (Linear Discriminant Analysis, LDA) 与主成分分析 PCA(Principal Component Analysis,PCA)算法是两种经典的线性降维算法[1]。 LDA 算法是对原始数据的类别进行降维,属于有监督降维算法,PCA 算法是对原始数据的维度直接进行维数约简,属于无监督算法。 LDA 算法和PCA 算法需要假设原始数据服从高斯分布,降维时存在小样本SSS(Small Sample Size,SSS)问题以及样本外(Out of Sample)问题。 非线性降维算法主要是流行学习降维算法、张量降维算法。 本文主要介绍基于流行学习(Manifold Learning)的经典降维算法,并进行分析和比较。
1 流行学习概念
流行学习(Manifold Learning)是借鉴了拓扑流行概念的一种降维方法。 流行是位于局部与欧氏空间同胚的空间,高维数据样本虽然在全局空间不具有欧氏空间的性质,但是在局部空间中仍具有欧氏空间的特点,因此可以在局部欧氏空间建立映射关系,用低维流行嵌入到高维空间中然后再设法将此映射推广至全局。 边缘Fisher 算法(Margin Fisher Analysis,MFA)、近邻鉴别投影NDP(Neighborhood Discriminant Projection,NDP)、NPE 算法(Neighborhood Preserving Embedding,NPE)、LDE(Local Discriminant Embedding,LDE)等算法属于流行学习算法中较为经典的算法。
2 流行学习的主要算法
2.1 边缘Fisher 分析算法
边缘 Fisher 分析 MFA 算法(Margin Fisher Analysis,MFA)主要是利用图嵌(Graph Embedding,GE)方法来构建本征图和惩罚图,本征图是用于描述类内数据的紧密性,惩罚图是用于描述类间数据的分离性。 本征图是由每个样本点的最近同类KNN(KNearest Neighbors,KNN)构成,在KNN 图中,每个点对应于一个样本数据,如果KNN 点是该样本点的KNN 近邻点,且属于同一类别,则两点之间添加一条边。 以此方法,遍历所有样本点的所有KNN 同类样本点。 惩罚图是由每个样本点的异类KNN 近邻点构成,惩罚图中的每个点对应一个样本数据,如果KNN 点是该样本点的所对应的KNN 近邻点,并且属于异类,则在惩罚图中的两点之间添加一条边。

2.2 NPE 算法
近邻保持嵌入NPE (Neighborhood Preserving Embedding,NPE)算法属于子空间流行学习算法,通过保存数据原始流形空间的局部近邻结构来实现,即每个数据点都能用其近邻点线性表示,能较好地解决样本外(out of sample)的问题。 NPE 算法的主要思想:设定原始数据空间中有m个数据,每个数据对应一个节点,第i个节点对应原始数据空间中的第i个数据。 邻接图通过KNN 和ε邻域两种方法来构建,如果用KNN方法构建邻接图,则该邻接图是有向图;如果用ε邻域方法构建邻接图,则该邻接图是无向图。
NPE 算法用KNN 方法构建邻接图,每个数据用其余KNN 数据来表示,该算法的重点是计算KNN 近临数据或节点之间的权重系数。 在低维的子流形空间中,通过每个数据点的近邻及其线性相关系数重构高纬子空间的局部几何特性。 数学表达式:
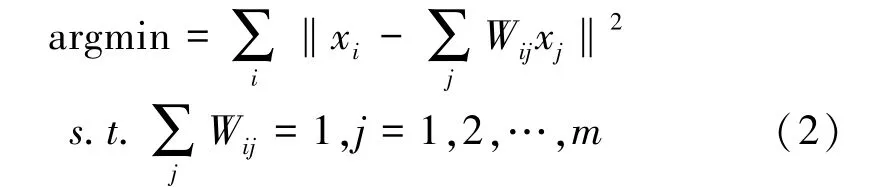
Wij是xi用xj近似线性表示的权重系数。 为了消除在投影子空间中远距离的点,加入任意缩放因子:XMXTa=λXXTa,M矩阵是对称半正定矩阵,约束条件yTy=1,即aTXXTa,其中M=(I-W)T(I-W),I是单位矩阵E,利用SVD 奇异值分解求得最优特征向量与特征值,得到由最优特征向量构成的投影子空间[4]。 当使用NPE 算法进行降维时,KNN 近邻中的K以及ε两个参数,需要根据模型多次训练的结果不断进行调整。
2.3 NDP 算法

关于类间子流形,构建类间图G′,使不同类间的投影向量相互远离。 类间图G′与类内图G的构图过程类似,其权重系数是热核函数,即wij′=exp(-‖xi-xj‖2/t)。 在类间图G′中,权重系数wij′ 说明样本数据的距离情况,如第i个节点与第j个节点之间有边相连,则wij′ =1,反之,则wij′ =0;如果不同类间的数据点距离很远,则wij′ 很小,也可以近似等于0。 数学表达式:
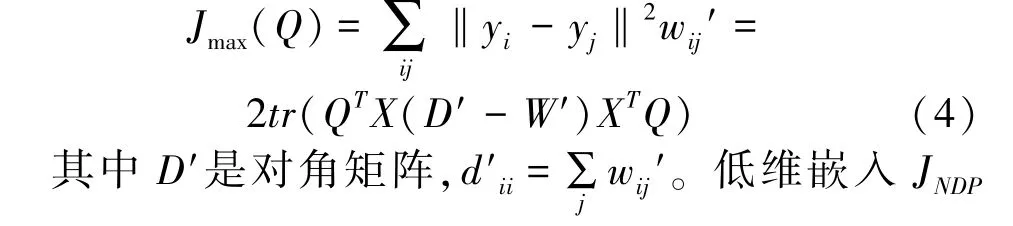

2.4 LDE 算法

其中v是方程中最大特征值对应的特征向量,嵌入向量zi=VTxi,V=[v1v2…vl][6]。
2.5 DNE 算法
鉴别近邻嵌入DNE(Discriminant Neighborhood Embedding,DNE)算法根据类内同类数据的紧密性以及异类间的分离性,即类内数据的吸引力和类间数据的排斥力构建类内图G,将原始数据的潜在低纬流行嵌入其高维数据空间中。 假设在原始数据中每个点都存在相互作用,两个数据点相互作用会随着距离增大而变小。 如果一个数据点近邻点都属于同一类,则该近邻点是类内点;如果其近邻点全部属于类间点,则该点称为奇异点。 奇异点被不同类的数据点隔离,只受局部的类间排斥力。 还有一种数据点,其近邻点包括类间点和类内点,称为边缘点。 边缘点同时受到类间的排斥力以及类内的吸引力。

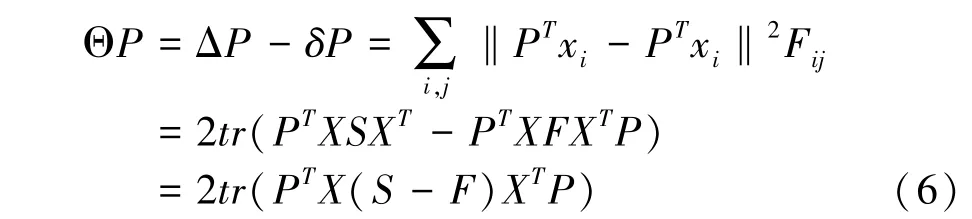
约束条件PTP=I,I是单位矩阵[7]。
3 流水学习算法分析与比较
3.1 MFA 算法与LDE 算法
MFA 算法具有以下特点:(1)获得较大的投影向量,其维度值由惩罚图KNN 中的K值来决定,即所选择的类内、类间KNN 近邻点最小值所决定;(2)无须假设原始高维数据分布情况;(3)类间样本点的分离性由每个样本点的KNN 异类样本点之间欧式距离求和来描述;(4)MFA 算法更具有一般性和广泛的适用性。 LDE算法和MFA 算法都是用PCA 算法处理小样本问题SSS问题,但LDE 算法可能会丢失一些重要的鉴别信息[8]。
3.2 NDP 算法与LLE 算法
NDP 算法通过合成类间的近邻信息以及类内的近邻信息构成类内子流形以及类间子流形保存高维原始数据空间的近邻信息,使得样本数据中不同类的投影向量远离,同类的投影向量相互靠近。 类内子流形由样本内用于表征本征近邻几何结构的权重系数重构,其权重系数由类似LLE 的方法来计算。 类间子流形由样本数据的类间权重系数构建,其权重系数根据拉普拉斯特征映射方法计算。
NDP 算法考虑了类内子流形和类间子流形,所到的投影线性子空间不仅保存了类内的近邻几何结构,也保存了样本数据不同类的投影向量。 LLE 算法是通过欧氏空间的线性表示重构,由于没有考虑原始数据的类别信息,因此会丢失数据的类别信息。
3.3 LDE 算法和LPP 算法
LPP 算法保存局部的近邻距离信息,不仅对于训练样本数据有效,对于新的样本数据也有一定的效果,解决了很多非线性降维算法存在的样本外(out of sample)问题,但是没有利用类别标签信息,不利于降维分类。 LDE 算法在构建邻接图时,充分地利用了类别信息,构建了类内邻接图以及类间邻接图,从而在低维子空间中,利用KNN 近邻类别信息进行分类,但LDE算法忽略了将会对LDE 算法总的代价函数产生影响的相距较远的数据点,从而降低分类性能。
当训练样本的数量小于样本维度时,LDE 算法和LPP 算法都存在有奇异矩阵的问题。
4 结语
文中所述的降维算法,在其投影子空间中,求最优特征值以及特征向量的时间开销较大,学者在研究上述算法过程中,对其进行拓展,在原始算法思想的基础上,引入核函数或张量,将其升维,常用的核函数有线性核函数、高斯核函数、拉普拉斯核函数、高斯核函数等,本文对其衍生的核函数化或张量化后的算法没有涉及。
本文详细介绍了流行学习中的经典算法,并对其优劣进行了比较,同时指出各算法在降维应用时所需的假设条件以及存在的问题,如小样本问题也即奇异值问题,样本外问题等。 目前基于流行学习的降维、分类算法仍在研究中,但有几个问题值得学者关注和研究:(1)在降维过程中,采用KNN 或ε领域方法来构建邻域时,参数怎么确定;(2)流行学习算法大多为局部方法,如何提高算法的以及算法的鲁棒性。
