融合多维信息的Web服务表征方法
2022-07-21张祥平刘建勋肖巧翔曹步清
张祥平,刘建勋+,肖巧翔,曹步清
1.湖南科技大学 服务计算与软件服务新技术湖南省重点实验室,湖南 湘潭411201
2.湖南科技大学 计算机科学与工程学院,湖南 湘潭411201
随着面向服务体系结构(service-oriented architecture,SOA)技术的发展,Web服务被广泛应用于各个领域。截至2020 年6 月24 日,ProgrammableWeb网站上所包含的Web服务已经达到了31 154个,要从这样一个大规模的服务集合中快速有效地找到满足开发者需求的Web服务犹如大海捞针。已有研究表明:对Web服务进行分类或聚类,再将用户的搜索请求定位到指定的服务类簇中,能够有效地减小Web服务搜索空间,提升Web服务的搜索效率。
目前,针对Web 服务划分已有大量的研究。这些研究通常是将Web服务映射为一个固定长度的表征向量,该表征向量包含Web服务的主要信息,之后在其上使用聚类或分类算法实现对Web 服务的划分。如Liu 等人使用LDA(latent Dirichlet allocation)主题模型和支持向量机相结合,实现了对Web 服务的自动标注。Chen 等人利用LSA(latent semantic analysis)模型对移动服务文本进行全局主题建模,再通过BiLSTM(bi-directional long short-term memory)模型对服务进行分类。这类方法的效果高度依赖主题模型所生成的Web服务表征向量的质量。但是由于Web 服务描述文档篇幅较短,LDA 主题模型无法有效地从短文本中获得丰富的主题信息,进而导致服务聚类效果较差。
与此同时,有些研究考虑将Web 服务的附加信息,如标签、先验知识加入到Web 服务表征向量的生成过程中,以提高Web服务聚类的精度。例如,Shi等人使用概率主题模型获得Web服务描述文档中隐含的主题表征向量,之后使用-means++对其进行聚类,在这过程中加入了额外的先验知识用于提升聚类的准确性。Xiao 等人考虑到Web 服务描述文本长度较短,所包含信息量较少的情况,通过使用维基百科相似词扩充的方法,对原始的Web 服务进行扩充,使用HDP(hierarchical Dirichlet processes)主题模型获得Web 服务表征向量,进而实现Web 服务聚类。Cao 等人将Web 服务语义信息以及Mashup 服务与API(application programming interface)服务之间的调用关系相结合,实现了API 服务的划分。这些方法在一定程度上提高了Web 服务聚类和分类的精度,但是仍然存在以下一些问题:
(1)尽管有些工作采用增强文本内容、引入先验知识等方法,用来丰富Web服务所包含的信息,同时通过改进主题模型以提高模型的主题建模能力,但由于主题模型与Web 服务描述文档固有的矛盾,主题模型难以从篇幅较短的Web服务文档中获得有效的主题表征,实验效果提升有限。
(2)Web服务数据利用率不高。已有的方法往往只考虑一种类型的Web 服务数据,如从Web 服务描述文本中抽取出的主题信息,而没有考虑使用Web服务的附加信息,如标签信息、Web服务流行度、Web服务共现信息。实际上,Web服务的附加信息也能够提高Web服务聚类和分类的准确性。
针对以上两个问题,本文提出了一种融合多维信息的Web 服务表征方法(multi-dimensional information-based Web service representation method,MISR)。该方法综合考虑了Web服务的功能信息以及其他属性信息。该方法首先使用高斯混合模型和Word2Vec模型生成了包含主题信息和语义信息的Web服务表征向量。之后通过融合Web 服务所包含的多维信息,获得包含多维信息的Web服务表征向量。最后,在真实的Web 服务数据集上进行Web 服务分类和Web 服务聚类两个任务,验证该表征方法的有效性。实验结果验证了所提出方法的有效性。
本文工作主要贡献有以下两点:
(1)提出了一种Web服务表征方法,该表征方法能够获得Web 服务主题信息与功能语义信息,可以有效地提高Web服务聚类和分类的精度。
(2)在真实数据上进行Web 服务聚类和分类对比实验,验证了Web 服务中所包含的多维信息能够用于提升Web服务聚类和分类的效果。
1 相关工作
随着服务计算和云计算的发展,互联网上出现了大量网络服务,Web服务发现成为一个热门的研究方向。精确高效地对Web服务进行分类能够有效提高Web 服务发现的性能。其关键技术在于如何对Web 服务进行建模,获得有效的Web 服务表征向量用于Web服务分类。现有的Web服务表征技术可以分为两类:一类是基于服务质量(quality of service,QoS)的表征技术,一类是基于功能语义的表征技术。
基于服务质量的服务表征技术主要将Web服务的服务质量特征作为Web 服务的表征向量,包括服务的吞吐量、可用性、执行时间等。Xia 等人使用Web 服务质量属性,将Web 服务聚到不同的类中。Michael 等人提出了一种基于QoS 参数和KNN(nearest neighbors)算法的Web 服务选择方法,使用并行分类模型对Web 服务进行分类。这类方法的缺点在于仅仅使用Web服务一部分特征作为Web服务的表征,所获得的表征向量包含的信息有限。
基于Web 服务功能语义的表征技术,通常是利用主题模型(如LDA、HDP)将Web 服务功能描述文档转换为给定长度的表征向量。Liu 等人使用LDA主题模型和支持向量机相结合,实现了Web 服务的自动标注。李征等人提出一种领域服务聚类模型,对Web 服务进行面向主题的聚类,把特定领域内具有相似功能的服务聚合为主题类簇。
有些工作通过改进主题模型抽取信息的能力,能够获得更有效的Web 服务表征向量。Cao 等人提出了双层主题模型用于获得Web服务功能内容和结构内容的表征向量,进而完成对Web 服务的聚类。Shi 等人使用Word2Vec 模型对Web 服务中包含的词汇进行聚类,用于增强的LDA主题模型,以获得信息更加丰富的Web 服务表征向量。这些工作使用主题模型及其变形从Web 服务功能文档中抽取出Web服务的功能信息,但由于Web 服务功能描述文档内容单一,所包含信息有限,也没有很好地解决问题。
还有一些工作使用基于机器学习的方法。如Cao 等人使用注意力机制生成包含Web 服务功能描述文档语义信息的Web 服务表征向量,实现对Web服务的分类任务。肖勇等人考虑API服务于Mashup服务之间的结构信息,使用随机游走和SkipGram 方法获得Mashup 服务的表征向量,之后使用支持向量机实现Web服务分类,但由于其需要考虑众多服务之间的结构关系,在实际应用中会比较复杂。
2 方法介绍
本章将对提出的方法MISR 进行详细的介绍。本文提出的Web服务表征向量生成方法主要包括以下四个步骤。
(1)主题信息增强的词向量生成。使用Word2Vec模型生成Web服务功能描述文档中所有词汇对应的词向量。通过高斯混合模型对所有词向量进行聚类,获得每个词的词向量属于不同主题簇类的概率。词向量与该概率相结合,生成主题信息增强的Web服务词向量。
(2)标签信息增强的词向量。通过计算Web 服务描述文档中所有词汇与标签信息的相互关系,获得标签-词之间的信息,用于增强Web 服务词向量所包含的信息。
(3)Web服务表征向量。在获得了每个词汇的增强表征向量之后,需要获得每一个Web 服务的表征向量。本文通过使用逆文档频率对Web服务中的词汇进行加权求和,获得每个Web服务的表征向量。
(4)流行度与共现系数。在已有的API服务数据集中计算每个API 服务的流行度以及不同API 服务之间共现系数,与(3)中生成的Web 服务向量相结合。再通过随机映射方法对API服务向量进行降维,最后获得API服务的表征向量,用于Web服务聚类和分类任务中。
表1为本文中出现符号的符号含义说明,以便读者查阅。

表1 符号说明Table 1 Description of notations
2.1 主题信息增强的词向量
传统的Web服务聚类方法通常使用如LDA主题模型对Web 服务的功能描述文档进行主题建模,力图获得Web服务描述文档中所包含的功能主题信息用于Web服务聚类。由于Web服务描述文档通常文本长度较短,主题模型不能有效地找到文本中特定的词共现模式,无法精确地获得Web 服务所包含的主题信息。主题模型的主要思想是使用词汇的概率分布来表示主题。如果对Web服务语料中的所有词汇进行聚类,划分为不同的词汇簇类视为Web 服务的不同主题类,那么就能够将不同词汇属于不同簇类的概率视为不同词汇属于不同主题的概率。
如图1 所示,为了获得不同词汇属于不同簇类(主题簇类)的概率分布,首先对原始的文本进行预处理。本文中对文本的预处理流程与文献[6]中的处理方式相同。先将文本转换为小写,去除所有标点符号,之后对文本进行分词和移除停用词。最后移除词汇的后缀,再对其进行词形还原。

图1 主题信息增强的词向量生成过程Fig. 1 Generation process of topic-augmented word embedding
接下来使用Word2Vec模型将词汇转换为给定长度的词向量。Word2Vec模型能够在大规模的语料库上构建出包含语义和词法信息的词向量。词汇之间的相似度可以简单地通过计算不同词向量的余弦距来得到。
高斯混合模型是统计学领域中用于计算连续型特征的概率分布的参数模型,而Word2Vec 模型生成的词向量就是一种连续型的特征向量。因此使用高斯混合模型对Word2Vec模型生成的词向量进行聚类,从而获得不同词汇属于不同簇类(主题类)的概率分布。
高斯混合模型可以人为设定个簇类视作个主题。通过计算不同组件的概率密度分布,进而获得每个单词与簇类(主题)之间的概率分布。在本文中,假设每个簇类(主题)的权重为π,每个簇类(主题)中的单词w服从高斯分布N,记为N(w;u,Σ),那么单词w属于簇类c的概率可以由式(1)计算得到:
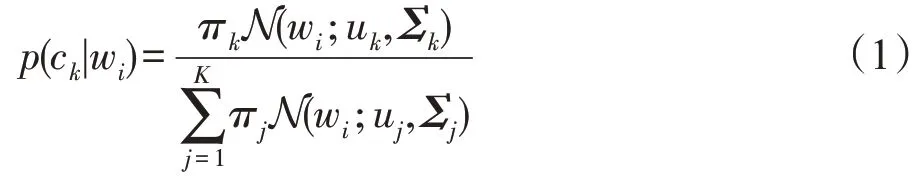
其中,u表示第个簇类(主题)概率分布的均值,Σ表示第个簇类(主题)概率分布的方差。
通过高斯混合模型,可以得到每个词汇属于不同主题的概率分布(c|w)。通过对词向量进行加权拼接的方式将主题信息与词向量信息相结合,具体步骤如下:将概率分布(c|w)与词向量wv相乘,获得个不同的向量wvc,之后将这个向量首尾拼接,获得长度为×的长向量作为词汇w的包含语义与主题信息的向量表征wvc,其中表示Word2Vec 算法中人为设定的词向量长度,本文实验中=200。具体操作如式(2)、式(3)所示:

其中,=1,2,…,,=1,2,…,,表示词汇数量,表示预先设定的主题个数。⊕表示拼接操作。
这步骤的优势在于:(1)不同于主题模型生成的Web 服务主题表征,本文在Word2Vec 生成的词向量的基础之上使用高斯混合模型对词汇进行聚类。在该过程中,不但考虑了Web 服务描述文本中隐含的语义信息,同时也考虑了其主题信息。(2)高斯混合模型的时间复杂度()要低于LDA 主题模型的时间复杂度()。其中,为语料库中词汇的数量,为语料库中文档的数量,为所需要生成的主题数量。进行向量拼接所消耗的时间可以不予考虑,因此采用高斯混合模型在时间复杂度上要优于LDA主题模型。
2.2 标签信息增强的词向量
当开发者推出他们所开发的Web 服务时,为了便于用户检索到这些服务,开发者通常需要提供一些单词或者短语作为Web服务标签用来概括和标记他们所开发服务的功能。通常情况下,开发者提供的标签要么会直接出现在Web 功能描述文本中,要么就是和Web 服务功能高度相关。标签信息是Web服务功能最简练、准确的概括。将标签信息加入到Web 服务的表征向量中能够增强Web 服务功能信息的表达,提高基于Web 服务功能的Web 服务发现方法的效果。
本文使用贝叶斯定理来计算词汇与标签之间的关联程度(t|w),表示词汇w被标签t标记的概率。(t|w)可以通过式(4)进行计算。其中,(t,w)表示词汇w被标签t标记的数量,(w)表示词汇w出现的数量。

标签加权向量的生成过程如图2 所示。在获得了每一个词汇w所对应的词向量wv之后,将词向量wv与其权重(t|w) 相乘,得到标签加权向量wvt,表示词向量wv在标签t下的加权向量。与之前步骤一致,将所有的标签加权向量拼接起来,获得一个长度为×的向量作为词汇w的使用标签信息增强的向量表征wvt。具体操作如式(5)、式(6)所示:

图2 标签信息增强的词向量生成过程Fig. 2 Generation process of tag-augmented word embedding

其中,=1,2,…,,=1,2,…,,表示词汇数量,表示标签个数。⊕表示拼接操作。
在经过之前两个步骤后,得到了主题信息增强的词向量wvc和标签信息增强的词向量wvt。将这两种向量进行拼接操作,获得每个词汇对应的信息增强的向量表征awv,如式(7)所示:

至此,获得了所有词汇对应的信息增强的词向量awv。
2.3 Web服务表征向量
一般情况下,一个Web 服务描述文档的文档表征向量可以简单地通过将该文档中的所有词汇对应的词向量加权平均来得到。这种做法认为文本中的所有单词所具有的信息是相等的。而实际上,文档中的不同词汇所包含的信息是不相同的,有些词汇能够明显体现出该文档所包含的功能信息,而有些词汇仅仅只有充当语气词的作用。因此,本文考虑使用逆文档频率来对词汇的重要程度进行度量,以期获得更加符合实际情况的Web服务表征向量。
词汇w的逆文档频率(w)可以通过式(8)进行计算得到:

其中,||表示Web服务描述文档的数量,|{:w∈d}|表示包含词汇w的Web服务描述文档的数量。
将一个Web服务描述文档中的每个词汇w对应的词向量awv与词汇w对应的逆文档频率相乘再相加,得到Web服务的表征向量sv,如式(9)所示。

其中,M表示在第个Web服务描述文档中包含的词汇个数。
2.4 Web服务流行度与共现系数
传统的Web服务推荐方法通常会考虑将Web服务的非功能属性作为推荐的指标,如安全性、可用性、响应时间等。目前,ProgrammableWeb 网站上的Web 服务缺少相关指标信息,因此,本文考虑将API服务与Mashup服务之间的关系以及API服务与API服务之间的关系用于增强之前所学得的Web服务表征向量。
文献[1]中使用Web服务的流行度和共现系数用于Web API 服务的推荐。流行度用于衡量Web API服务的流行程度,数值越高表明该API 服务越受欢迎。具体的API服务流行度计算方式如式(10)所示。

其中,(a)表示API服务a被Mashup服务调用的总次数;(a)表示同属于(a)所属分类的所有API 服务;max 和min 操作分别表示取所有元素中的最大值和最小值操作。
通过对ProgrammableWeb数据集进行统计分析,发现在本文数据集中所有Mashup 服务中,仅仅只有4.7%的Mashup服务中存在所使用的API服务是属于同一个类别的。这说明组成Mashup服务的API服务大部分是属于不同类别的。共现系数可以用来衡量两个API 服务之间的历史组合关系,共现系数越大,表明这两个API服务同时被同一个Mashup服务调用的次数越多,那么它们有较大的概率是属于不同类别的服务。共现系数的计算如式(11)所示。

其中,|a∩a|表示a和a被同一个Mashup 服务调用的次数,|a∪a|表示a和a被所有Mashup 调用的总次数。
将获得的共现系数组合为共现系数矩阵Co,该矩阵的第行、第列的元素等于(a,a)。其中,表示API 服务的数量。本文将之前获得的每个Web服务的表征向量sv与该矩阵通过式(12)相结合,获得包含服务共现信息的Web服务表征向量svc。

其中,Co表示矩阵Co的第行数据。
最后,将Web 服务的流行度与其表征向量svc相乘,获得包含多维信息的Web服务表征向量,如式(13)所示。

通过计算可得,sr的向量长度为(××+)。如果直接应用于聚类和分类算法中,会导致计算时间变大。因此为了降低实际应用中算法的运行时间,还需要对其进行降维。
本文采用随机映射算法对长向量进行降维。随机映射算法能够在保留尽可能多的原始信息的情况下将向量的维度降到人为指定的长度,本文实验中设定=500。该算法的具体实现细节请参照文献[17]。最终如式(14)所示,获得的Web服务表征向量s可以直接用于相似度计算。

3 实验
为了研究本文方法所生成服务表征向量的有效性,进行了Web 服务聚类和Web 服务分类两类实验。接下来将具体介绍实验所使用的数据集以及具体每个任务的实验设置。
3.1 实验数据集
本文所使用的数据集为ProgrammableWeb 数据集。该数据集包括12 919 个API 服务和6 206 个Mashup服务。为了降低数据分布不均衡对实验效果比较的影响,本文在实验过程中分别选取了API服务中数量最多的前20 类API 服务共计6 718 个以及Mashup 服务中数量最多的前20 类Mashup 服务共计3 950个进行实验。
3.2 评价标准
由于实验中所使用的数据集类别分布不均衡,为了考虑不同类别样本大小对实验结果的影响,采用准确率、召回率以及Micro-F1指标用于衡量不同模型的分类和聚类效果。三个指标的计算方式如下:

其中,表示Web服务被正确划分的数量,表示不属于类而被错误地划分到类的Web 服务数量,表示属于类别但是被错误地划分到其他类别的Web 服务数量。模型的准确率、召回率以及-1 的数值越大,表明该模型的效果越好,反之越差。对于聚类实验,簇类中数量最多的那一类将作为该簇类的正确类别。
3.3 对比方法
LDA:该方法将Web服务中的功能视为模型中的主题信息,通过使用LDA主题模型获得Web服务的主题向量,之后使用聚类或分类算法对服务进行划分。
Word2Vec:该方法能够保留Web 服务功能描述文本中所包含的隐含语义信息,通过对文本中所有词汇的向量的和进行平均获得Web服务表征。
Doc2Vec:该方法是Word2Vec 算法的改进版本,通过同时学习单词向量和文档向量获得整个Web服务描述文本的向量表征。
WT-LDA(user tagging augmented LDA):该方法考虑了Web服务中标签信息与Web服务的主题信息,用于生成包含标签信息的主题向量。
HDP-SOM:该方法考虑了Web 服务数据稀疏的问题,使用HDP(hierarchical Dirichlet processes)算法对扩充后的Web 服务进行主题建模,之后使用自组织神经网络(self-organizing feature map,SOM)进行Web服务聚类。
GWSC(GAT2VEC-based Web service classification):该方法考虑了Web 服务之间的结构关系和Web服务自身的属性信息,获得包含结构信息和属性信息的Web服务表征向量。最后使用SVM算法实现对Web服务的分类。
MISR:该方法为本文提出的方法。采用高斯混合模型和Word2Vec算法获得包含主题信息的词向量表示,再结合Web服务的属性信息,如标签、流行度、共现系数,生成融合多维信息的Web 服务表征向量。该表征向量可以直接用于Web服务聚类和分类任务中。
3.4 Web服务聚类实验与分析
Web服务聚类是一个无监督的学习过程,在聚类的过程中只能根据服务表征之间的相似性对服务进行划分。因此要获得较好的聚类效果,对Web 服务表征向量的质量要求更高。
在本实验中,使用MISR 方法,将API 服务转换成了对应的API 服务表征向量。同时,对Mashup 服务数据使用没有添加流行度和共现系数的MISR 方法,也将其转换为了对应的服务表征向量。之后,使用基本的-means 算法对不同方法所生成的Web 服务表征向量进行聚类。在实验过程中,为了降低初始值的选取对-means算法效果的影响,本文对每组实验重复了10 次,取实验结果的平均值作为最终实验结果。
从表2、表3 中发现,使用标签信息增强的WTLDA 方法的效果要优于只使用LDA 对Web 服务建模的方法。这说明标签信息确实能够有效地提高Web 服务聚类的精度。同时,Word2Vec 和Doc2Vec模型的效果并没有比LDA 主题模型的效果好,这可能表明前两种方法所提取出的局部文本语义信息在实际Web服务聚类过程中并没有比LDA提取出的主题信息更加有效。WT-LDA 和HDP-SOM 方法虽然采用了附加信息,但是由于所采用的基本方法仍然是基于主题模型的方法,实验效果提升有限。本文方法在API 数据集上相比于LDA、Word2Vec、Doc2Vec、WT-LDA、HDP-SOM、GWSC方法在Micro-F1指标上分别有38.8%、54.5%、15.3%、33.3%、44.7%、9.7%的提升。这表明包含丰富信息的Web服务表征向量有效提高了Web服务聚类的效果。

表2 API服务聚类结果对比Table 2 Results of API services clustering

表3 Mashup服务聚类结果对比Table 3 Results of Mashup services clustering
3.5 Web服务分类实验与分析
服务分类与服务聚类不同在于服务分类是有监督的划分方式。通过给定Web 服务的标准分类,使用机器学习等方法学习Web服务表征向量与其对应的类别之间的关联规则。与文献[14]相同,本文考虑使用支持向量机作为Web服务分类任务中的基本分类器。在实验过程中,将选取的服务数据按照3∶1的比例划分为训练集和测试集数据,并且使用了10-折交叉验证,以降低实验误差。使用GridSearch技术寻找SVM算法的最佳参数。
从表4、表5 可以看到,在同一个基本分类模型下,本文提出的Web 服务表征方法在Web 服务分类任务上取得了最好的效果。本文方法将Web服务中的功能主题信息和描述文档中隐含的语义信息相结合,同时考虑了Web服务的标签信息、流行度和共现信息。因此,生成的Web 服务表征能够明显地提升Web分类任务的效果。

表4 API服务分类结果对比Table 4 Results of API services classification

表5 Mashup服务分类结果对比Table 5 Results of Mashup services classification
3.6 多维信息有效性实验与分析
本文方法不但考虑了Web服务功能层面上的信息,同时也考虑了Web服务其他附加信息,如标签信息、流行度、共现信息。本节将验证多维信息对实验效果的影响。在API 数据集上进行Web 服务分类任务来验证附加信息对Web服务表征向量的影响。
分别取数量最多的前类API服务作为本实验的数据,其中=5,10,15,20。实验设置与之前Web服务分类实验相同,也采用了10-折交叉验证的方式,以降低实验误差。使用添加了多维信息的Web服务表征向量和未添加多维信息的表征向量进行实验对比,实验结果如图3所示。

图3 Mashup服务分类结果对比Fig. 3 Results of Mashup services classification
从图3可以看出,添加了多维信息的Web服务表征向量的效果明显优于未添加多维信息的向量。这表明Web服务中所包含的多维信息能够提高Web服务分类任务的效果。同时随着API 服务类别数量的增加,实验效果也在逐步降低,这是API 服务数量增加使得实验数据分布不均衡导致的。
4 结论
本文提出了一种融合多维度信息的Web服务表征方法。该方法能够获得Web服务主题信息与功能语义信息,进而融合多维度信息生成高效的服务表征向量。同时在真实数据集上验证了包含Web服务多维信息的服务表征向量能够有效地提升Web服务聚类和分类的效果。
