融合主题模型分析和时间因素的推荐算法
2022-07-20丁丽,方晓,董娜
丁 丽,方 晓,董 娜
(亳州职业技术学院信息工程系,安徽亳州 236800)
推荐系统是解决现在信息过载问题的有效技术手段,能更好地解决互联网上“噪声”数据,为用户提供想要的信息. 推荐系统的核心是推荐算法,在工业界中,协同算法是目前应用比较广泛的技术. 其主要分为三类:一是基于项目和用户协同过滤算法,主要思想是利用用户对项目的评分矩阵的关系,预测某一用户对未知项目的评分;二是基于项目内容的推荐算法,主要使用的方法是分析项目内容,用标签来表示项目的特征,对于特征的提取有语义分析和统计的两种方法;三是基于模型的推荐算法,主要是运行机器学习中的众多模型的思想来解决推荐系统中排序的问题.
当前推荐系统存在的问题是推荐精确度不高、召回率低、数据稀疏、用户冷启动等. 为解决这些问题,基于多维度融合的推荐算法已成为当前研究的热点之一. 其一,互联网上的标注技术得到飞快的发展,每个用户或者是每个项目在互联网上形成的数据,系统会自动标注,形成特定的标签. 对于用户来说,社会化标签是反映用户的喜好和兴趣,而对于项目来说则是项目特征的一种表现. 在推荐算法的研究中,有许多学者把社会化标签融合到推荐算法当中. 文献[1]提出了基于标签的扩展的途径算法;文献[2]将标签和协同过滤相结合,利用标签计算用户对资源的喜好程度和资源相似性,得到用户偏好矩阵进行top_n推荐;文献[3]通过挖掘用户的标签的权重,产生用户的个性化推荐列表. 但在这些研究中忽忽略了上下文在标签中的作用,即标签的语义. 在文本标签中公认最好的模型是LDA,在文献[4]中即运用LDA 模型结合对项目的评分,计算相似度,得到推荐算法.
其二,随时间的变化,用户的喜好是会发生改变的. 用户给项目打标签的时间越短,越能反映用户当前的偏好就越高;间隔时间越长,则相反. 时间与用户偏好程一定的负相关性,因此,本文针对文献[5-8],分析时间对用户的偏好影响,计算用户的偏好变化率,并应用到推荐算法中,主要是在用户-项目评分矩阵中分解,以提高推荐的精准度.
其三,社交因素影响用户的偏好. 在用户间的社交关系中,运用用户间的社交关系数据计算用户的关系度,从而扩大了用户相似的领域范围. 由此可构建用户间的相似矩阵,再结合用户-项目评分矩阵,进行矩阵分解产生推荐.
本文结合上述的用户社交关系、时间因素和文本分析三者的因素,构建用户偏好模型,其算法的主要思想是:首先采用LDA 模型分析标签之间的语义关系,得到用户对项目的偏好概率;其次,结合时间因素和用户标签相似性,采用动态权重技术融入用户-项目偏好模型中;再次,将用户间社交关系度融合到用户对项目偏好概率的计算中;最后通过用户-项目偏好矩阵产生推荐集合.
1 相关工作
1.1 推荐系统的形式化描述
在一个推荐系统中,项目集合G={g1,g2,…gn}和用户集合U={u1,u2…um},通过推荐算法技术来预测用户对项目的评分,即:
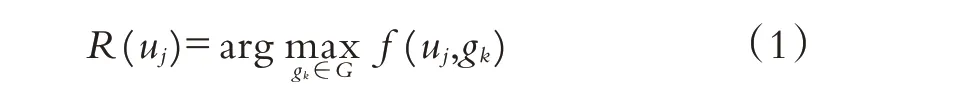
其中f(uj,uk)表示用户uj∈U对项目gk∈G的预测评分,R(uj)为用户uj的推荐项目集合.
1.2 协同过滤算法CF
协同过滤算法核心思想是:利用用户在系统中的历史行为数据,运用模型计算用户或项目的相似度,即:

综上对传统协同过滤算法分析可以得到,传统的协同过滤算法适合与复杂非结构化的项目推荐,对内容异构度高的项目有很好的适应性,善于发现新的兴趣点,但对数据稀疏和冷启动没有很好地解决. 用户-项目评分矩阵是协同过滤算法的基础,在数据稀疏以及在新用户加入、没有评分数据情况下,利用推荐算法推荐出的项目集是不准确的.
2 融合标签和时间加权的推荐模型
本文模型(UTGLDA)的主要思想是:运用LDA模型构建用户-商品UG矩阵,通过时间因素计算用户间的相似度sim(u,v),依据用户间相似度,推荐给top_n商品集、用户-标签矩阵UT和标签-商品矩阵TG,算法主要步骤如下:
Setp1:构建用户-标签矩阵UT和标签-商品矩阵TG.
Setp2:通过LDA 主题模型计算得到用户-商品矩阵UTG.
Setp3:融合时间因素计算用户相似度sim(u,v).
Setp4:依据用户间相似度得到推荐商品集top_n.
2.1 LDA主题模型
LDA 是自然语言处理领域中的主题模型,每篇文档中每个主题以概率分布的形式给出,从而分析文档,抽取主题,并进行聚类,对文档进行分类. 在LDA 建模中,首先计算标签主题在每篇文档中的分布p(z/d),其次计算标签在标签主题上的分布p(t/z),即:
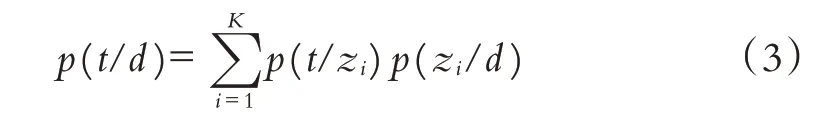
其中:K为标签主题数目,zi为标签主题,t为标签,d表示标签类比文档.
2.2 UTG矩阵构建模型
首先构建用户-标签矩阵和标签-商品矩阵,其次通过LDA 主题模型,计算得到标签主题下用户的分布概论p(z/u)和每个标签主题下特定标签的分布概论p(t/z),然后根据公式(3)计算特定标签下用户的概论分布p(t/u). 同理可计算特定标签下商品的概论分布p(t/g):
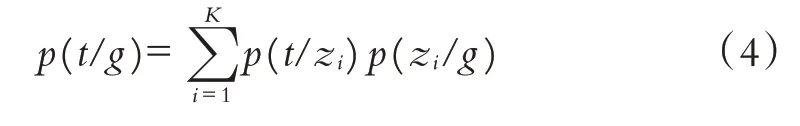
式中g为商品.
标签是一个系统中为研究某一对象的行为关系给定的特有的属性,标签有多重含义或是行为、属性、关系等. 在个性化推荐系统中,标签有显性和隐性之分.设标签主题集合Z={z1,z2,…zk},标签集合T={t1,t2…tl},UT是n×k矩阵(n为用户数),表示为X=[X1,X2…XK],则xi,j表示为:

式中c为用户ui在标签主题zj中使用标签的次数.
同理,标签-商品GT矩阵是k×m矩阵(m为用户数),表示为Y=[Y1,Y2…YK]T,则yi,j表示为:

其中gc为商品gj在标签主题zi中使用标记的次数.
首先对用户-标签矩阵UT利用LDA分析技术,得到用户U的主题分布概率p(z/u),同时得到每个主题Z的标签分布概率p(t/z),根据公式(4)得到用户-标签分布概率矩阵p(t/u).然后利用LDA分析技术得到标签的主题分布概率p(z/t),同时可以得到主题下的项目分布概率p(g/z),根据公式(4)可以得到标签的项目分布矩阵p(g/t). 则根据公式(4)可求得在标签tk下用户U对项目G的偏好概率:

同理,一个用户对项目整个偏好概率为:

2.3 时间权重计算
用户的偏好会随时间的推移而发生变化,在传统的协同过滤算法中没有考虑到时间的因素,因此本文研究中引入时间因素. 设当前时间点为Tn,在时间Ts时用户u1对项目g进行标注;而在时间Tn时,用户u2和u3对项目g也进行标注. 因此,用户相似度sim(u2,u1)小于sim(u2,u3),可利用公式

计算时间权重,式中α即为时间权重参数.
将时间因素引入用户相似度计算公式中,可减少真实用户相似度与理论用户相似度之间的误差.把用户对项目的标记代替协同过滤算法中用户对项目的打分,结合时间因素权重,根据皮尔斯用户相似度计算公式得:
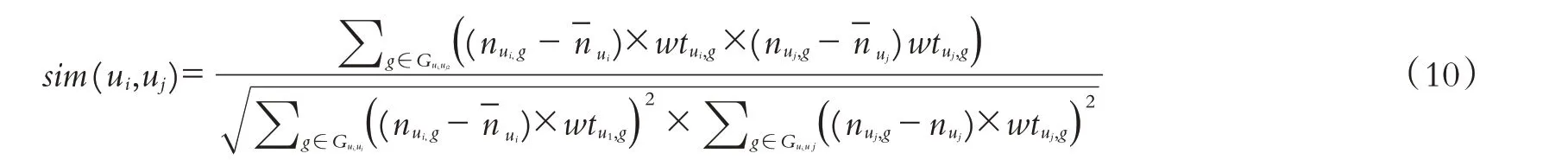
式中:sim(ui,uj)为用户ui和uj为时间因素下的相似度,wtui,g为用户ui对项目g标注的时间权重,nui,g为用户ui对项目g的标记次数.
2.4 用户-项目偏好矩阵
用户ui和uj之间的相似度定义权重wi,j,用户ui对项目g的偏好概率p(g/ui),即用户uj在用户ui影响下对项目g的偏好概率为:

若用户集合规模为N,那么,用户uj对项目g的偏好概率为:

由公式(12)得到用户-项目的偏好矩阵,然后对矩阵的值进行排序,取排名靠前的N个项目推荐给用户,当新用户加入用户集合时,将标记次数高的项目推荐给用户,避免推荐中的冷启动问题.
3 实验
3.1 实验数据集和评价指标
实验数据集采用delicious-2k,数据集有用户对bookmark 的标记信息、用户间的关系、bookmark 的标题和url,具体数据如表1.

表1 delicious-2k数据集信息
首先对数据集进行预处理,剔除用户标记数少于37 的用户,然后按照标记时间进行排序,按照前75%为训练集,后25%为测试集,14 次实验求平均值.
本文采用分类准确率这一评价指标,其中包括准确率、召回率和F1衡量指标[9].
准确率是标记项目数与总项目数的比重,即:

其中:Ntag为用户u的标记过的项目总数,N为用户u的项目集合数目.
召回率是指用户标记过的项目数与理论上可能标记的最大值的比重,即:

式中Ntest为用户在测试集中可能的项目最大推荐数值.
F1是对召回率recall和准确率precision的加权平均,以平衡两者之间的误差:
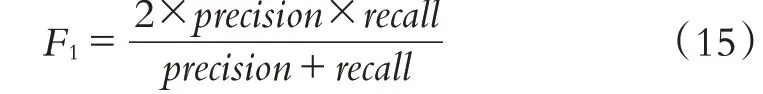
F1的值越大,反应模型的效果越佳.
3.2 实验结果分析
依据文献和实际实验总结,对LDA 中参数α和η的取值分别为0.1和0.01,迭代次数为600.
(1)LDA 主题数与F1的关系分析. 将LDA 主题数目分别取值20、40、60、80、100,推荐项目数topN取不同值时,F1值发生变化,如图1所示.
从图1 可以看出,F1值随LDA 主题数目变化而变化,且有整体上升趋势. 但在topN=45 时波动范围较大,LDA 在达到100 时F1值最大. 实验发现,随着LDA 数目增加,建模的时间复杂度随之增加. 以topN=55 为例,LDA 主题建模消耗时间与数目之间的关系如表2所示.

表2 消耗时间表
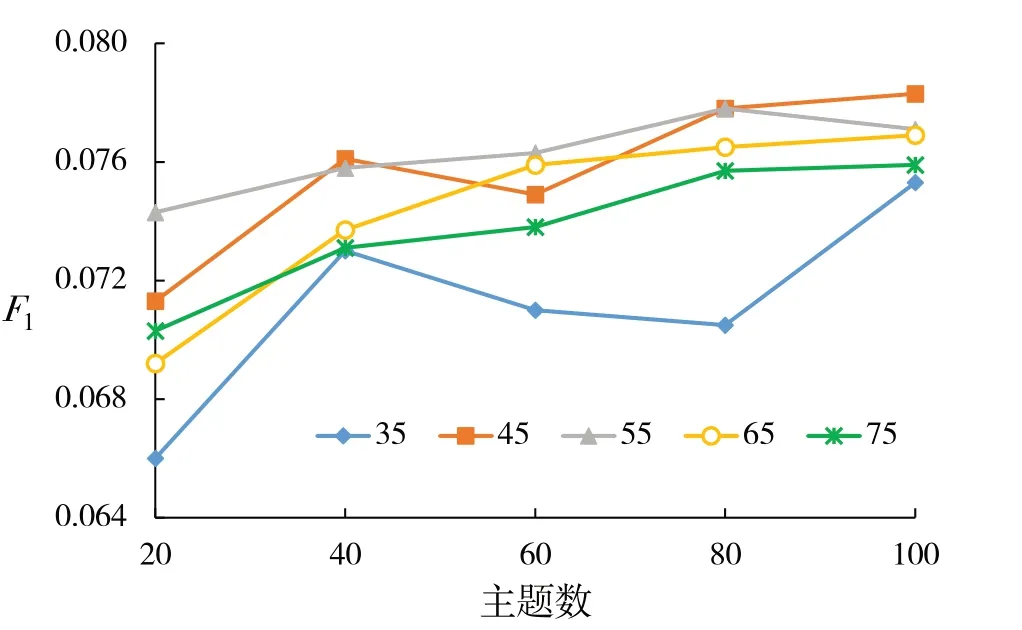
图1 LDA主题数与F1的变化关系
(2)项目推荐数目N与F1关系分析. 设N分别为35、45、55、65、75,LDA 主题数目分别为20、40、60、80、100进行5组实验,结果如图2所示.
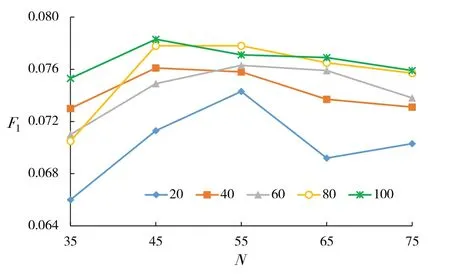
图2 项目推荐数目N与F1变化关系
从图2 可以看出,随着N的变化,F1值发生改变,N值增加,F1趋势性增加;但F1值整体趋势在N=45 和N=55 间出现递减现象. 本文确定N=50为最佳项目推荐数目.
3.3 算法对比分析
为了验证UTGLDA 算法的质量,与其他3 种常见的推荐算法进行对比分析.它们分别是:(1)PB推荐算法(Profile-based),该算法主要在user 与user 之间计算相似性,然后将相似度高推荐给目标用户[10].(2)传统的协同过滤算法CF,该方法直接利用用户关系间联系,计算用户间的相似性,然后推荐前topN个最相似的用户给目标用户.(3)基于主题模型的个性化推荐算法LDA[11].
在delicious-2k 数据集上,以75%为训练集,25%为测试集,各算法在不同推荐项目数(top35、top45、top55、top65、top75)下的F1指标对比分析如图3所示.
从图3 可以看出,随着topN的变换,F1值也随之改变,4 种算法在本实验中F1值的趋同性是一致的.不同的topN下本文的UTGLDA 算法优于其他3 种算法.

图3 不同算法的F1指标对比
LDA 推荐算法主要是挖掘用户-项目的潜在信息,相比CF 算法在用户和项目的相似度上的计算,推荐质量有所提高. 而本文的UTGLDA 算法在LDA 技术的基础上,从时间维度上对用户和项目标记次序进行计算,融合时间权重,更能体现用户偏好的先进性和有效性,因此本文提出的UTGLDA 推荐算法有效地提高了推荐质量.
4 结语
在推荐系统中,用户与用户之间的社交关系对用户的偏好度有着重要的影响,随时间的推移用户间的社交关系也随之改变. 本文把时间因素融合到用户间相似度计算中,使用LDA 技术建立偏好算法模型,增强推荐的有效性,提高推荐的质量.
下一步研究重点将在用户评论和项目评论的社交数据的基础上,通过文本分析技术挖掘用户间的社交关系的程度和社交主题,计算用户的偏好概率,更好反映现实用户的偏好情况,有效提高系统推荐质量.
