低冗余知识图谱实体关系检索与仿真
2022-07-20钱涵笑
钱涵笑,韩 斌
(江苏科技大学计算机学院,江苏 镇江 212000)
1 引言
智能化应用的深入研究令包含海量知识内容的知识图谱成为满足用户实际信息应用需求的主要工具[1],被普遍应用于各个领域中。知识图谱利用资源表达框架数据模型,以图结构形式展示知识[2],图内节点与有向边可分别代表不同类别的实体和实体间的关系。用户在利用知识图谱获取所需信息的过程中,通过在知识库内检索实体关系获取相关信息的实际答案[3]。但实体关系检索过程中由于知识库内文档包含大量碎片化信息,导致当前普遍使用的基于图数据库的实体关系检索方法和结合实体词与句子语义的实体关系检索方法等[4,5]均存在效率差以及检索效果不佳等问题。针对此类问题,研究一种基于本体的低冗余知识图谱实体关系检索方法,期望通过所研究方法为知识图谱应用的拓展提供新的研究方向。
2 基于本体的低冗余知识图谱实体关系检索方法
2.1 检索方法体系架构设计
基于本体的低冗余知识图谱实体关系检索方法体系架构如图1所示,由左向右可划分为三个主要部分,分别是:数据源、图谱及索引构建与检索应用。

图1 实体关系检索方法体系架构
2.2 知识图谱构建
2.2.1 本体模型关系构建
1)本体模型构建
数据源内包含的各类基础数据大多存在不同种类的本体模型,这些本体存储过程中的单位一般为表,不同本体间的相关性构建以主外键为工具[6,7]。在获取数据表内全部表结构的基础上,依照表的存储信息构建本体模型,利用字段间的相关性在本体模型内引入关联信息,构建若干个具有对象对立特征的本体模型[8],以此提升数据源内数据结构信息获取的速度,并依照需求访问数据。
2)本体模型关系构建
图2所示为个体本体与组织本体间的相关性。

图2 个体与组织本体模型关系
成功构建本体模型后将产生若干个具有独立特征的本体,这些本体间具有较大相关性,这些相关性在数据源内通常以关联表形式展示[9]。在构建个体与组织本体模型关系时采用基于知识图谱的本体模型关系构建方法,详细过程如下:
1)选取需构建相关性的若干个数据模型,模型数量可表示为M1,M2,M3,…,MN。
2)确定不同模型的相关性字段,构建字段间的相关性。
3)在图数据库内存储本体模型关系,其中包含本体模型的字段信息、具有相关性的模型名称与参数等。
2.2.2 实体关系构建
完成本体模型关系构建后,即可依照关系参数构建实体关系,详细构建过程如下:
1)利用统一的数据访问接口获取全部参与实体关系构建中各本体模型的全部数据;
2)为提升全部数据表现的直观性,依照数据库内表与表内字段的描述转换实体数据属性名(由英文转换为中文);
3)在图数据库内存储全部本体模型的实体数据;
4)构建实体关系,具体构建过程中以本体模型的相关参数为依据[10];
5)循环1)—4)过程,至全部本体模型关系均完成对应实体关系构建为止。
2.3 低冗余实体摘要生成
知识图谱数据量的显著提升,令其中包含的实体数量显著提升,在部分需直观展示实体信息的应用中,以防止产生用户信息过载及满足展示空间约束为目的[11,12],需采用ESSTER法生成具有高可读性和低冗余性的实体摘要。
2.3.1 结构重要性
知识图谱内属性的流行度可描述其通用性,能够表现此知识图谱内着重关注的关键含义。针对存在高流行度属性的三元组,区分当前实体和知识图谱内其他实体较为困难,用y表示三元组,ppopg(y)∈[0,1]和vpop(y)∈[0,1]分别表示知识图谱内y属性的整体流行度和取值的流行度,则可利用式(1)描述此类度量
ch(y)=ppopg(y)·(1-vpop(y))
(1)
为提升实体摘要内容的多样性,可依照局部结构内属性的流行度划分多值属性,设置相应惩罚。同时针对高流行度的取值可设置相应奖励,以防止所选y存在过度偏重技术应用的问题。利用ppopl(y)∈[0,1]表示y的属性在实体描述所对应局部结构内的流行度,其计算过程如下
div(y)=(1-ppopl(y))·vpop(y)
(2)
为优化知识图谱内不同数据集对整体流行度与局部流行度偏好的差异性,引入参数φ∈[0,1],由此可利用式(3)确定y的重要性
Ws(y)=φ·ch(y)+(1-φ)·div(y)
(3)
2.3.2 文本可读性
量化知识图谱内文本可读性,可确定不同y在用户阅读感受上的差异性。以G(y)表示y的可读性,其计算过程需以属性prop(y)的文本为基础,不同属性的理解对知识储备的需求也有所差异。在仿真用户日常阅读环境时需参考开放域文本语料,若语料内文档数量为B,则b(y)和n(y)分别能够分别表示语料库内文档属性为prop(y)的文本的数量和b(y)个文档内用户可获取的文档数量。由此可将G(y)理解为n(y)的函数,公式描述如下
G(y)=familiarity(n(y))
(4)
式(4)内,familiarity表示与n(y)相关的非递减函数,其取值范围为[0,1],其计算过程如下

(5)
实际应用过程中,可将G(y)作为y分值确定的辅助权重。通过对数函数优化G(y)的取值,可防止其取值分布倾斜过量导致的惩罚过度问题,优化后知识图谱内文本可读性权重计算公式如下
Wt=log(G(y)+1)
(6)
2.3.3 低冗余度
1)由于本体知识存在属性与类别间的相关性,因此,可基于本体知识确定逻辑冗余。实体关系表示过程中,属性为rdf:type的y可表示实体关系所属类别,假设两个y表示的实体关系类别具有相关性,那么以其中一个y为基础可推导获取另一个y,由此确定这两个y间具有逻辑冗余。
2)针对其他冗余关系,分别确定y属性间或取值间的一致度确定其冗余程度。以simp(yi,yj)∈[-1,1]和simv(yi,yj)∈[-1,1]分别表示两个y属性间的一致度和取值间的一致度,可分别通过字符串一致度指标和数值大小获取。
3)以ovlp(yi,yj)∈[0,1]表示基于以上过程获取的两个y间的冗余度,其值与两个y间冗余度呈正比例相关。通过实体关系内y间成对冗余度确定实体摘要冗余度。
2.3.4 实体关系检索实现
以S表示实体摘要,基于上述各指标的量化方式,可利用式(7)表示S的质量分值,将其作为生成高重要性、高可读性与低冗余性实体摘要的依据。

(7)
式(8)内,λ表示待调参数,其取值范围为[0,1],主要功能是优化实体摘要对冗余的认可度。设定score(S)阈值,当计算score(S)值高于阈值时即可确定所生成的实体摘要满足低冗余要求。
针对所生成的低冗余实体关系摘要构建索引,依照低冗余摘要索引类别快速检索知识图谱内的数据与文档数据中的实体关系。
3 实验分析
实验为验证本文所提出的基于本体的低冗余知识图谱实体关系检索方法在实际知识图谱实体关系检索中的应用效果,利用Java语言在Elasticsearch系统之上对本文方法进行仿真实验。选取油茶树为仿真对象,采用本文方法构建油茶知识图谱,采用本文方法检索油茶树知识图谱内的实体关系,实验结果如下。
3.1 知识图谱构建仿真结果
针对仿真对象油茶树,采用本文方法构建其知识图谱,图3所示为仿真对象知识本体模型。

图3 实验对象知识本体模型
图3所示的仿真对象知识本体模型内包含实验对象培育、加工与应用全产业链的知识,其中“工作单位”“研究成果”“培育人”“发明人”“作者”与“来源”均为本文方法所生成的低冗余实体摘要。知识本体内包含的不同类别数据均来自于国家相关部门或平台文件数据。
3.2 实体关系检索实验结果
基于图3所示的知识本体模型,依照关系参数构建实验对象实体关系。针对知识本体模型内包含的工作单位与研究成果数据集,以二值相关度、召回率以及平均准确率均值为判断指标判断本文方法检索结果,各指标值与实体关系检索结果之间呈正比例相关,也就是判断指标值越高,本文方法实体关系检索性能越好。表1所示为本文方法实体关系检索结果。

表1 本文方法实体关系检索结果
分析表1得到,采用本文方法对本体模型中包含的两个主要数据集进行实体关系索引,本文方法下实体关系检索的二值相关度等各指标值均在0.8以上,满足实际应用需求,说明本文方法具有较好的实体关系检索效果。
为进一步验证本文方法知识图谱实体关系检索的性能,选取文献[4]中基于图数据库的实体关系检索方法和文献[5]中结合实体词与句子语义的实体关系检索方法为对比方法,采用对比方法检索两个主要数据集内的实体关系,两种对比方法实体关系检索结果的各判断指标如表2所示。
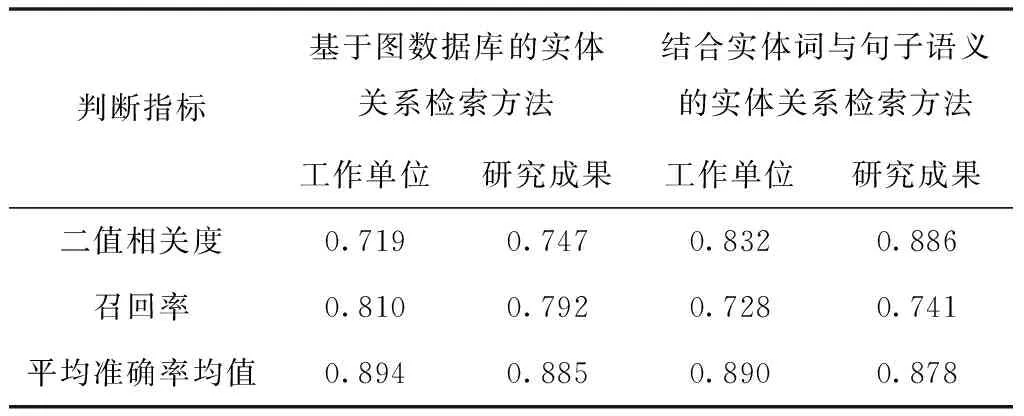
表2 两种对比方法实体关系检索结果
结合表1与表2内数据可知,采用结合实体词与句子语义的实体关系检索方法检索数据集内实体关系时,二值相关度指标结果稍高于本文方法,但召回率与平均准确率均值均低于本文方法与基于图数据库的实体关系检索方法;而基于图数据库的实体关系检索方法与本文方法相比各判断指标值均有一定差距。上述实验结果可充分说明本文方法具有较好的实体关系检索性能。
3.3 低冗余摘要生成实验结果
本文方法中采用低冗余实体摘要生成方法生成知识图谱内实体关系摘要。以F-measure为衡量实体关系摘要质量的指标,以S′和S*分别为生成时实体关系摘要与理想实体关系摘要,对比本文方法与两种对比方法针对工作单位与研究成果数据集所生成的实体关系摘要质量,结果如表3所示。
衡量指标计算过程如下:
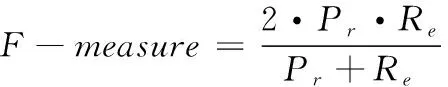
(8)
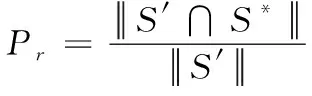
(9)
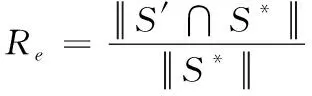
(10)
表3为不同方法下实体关系摘要质量对比结果。

表3 实体关系摘要质量对比结果
分析表3得到,三种不同方法所生成的实体关系摘要质量排序为:本文方法>结合实体词与句子语义的实体关系检索方法>基于图数据库的实体关系检索方法;三种不同方法检索实体关系摘要所花费的时间排序为:结合实体词与句子语义的实体关系检索方法>基于图数据库的实体关系检索方法>本文方法。由此可知本文方法所生成的实体关系摘要质量高于对比方法,并且可以显著提升实体关系摘要检索的效率。
4 结论
本文研究基于本体的低冗余知识图谱实体关系检索方法,基于本体与实体关系构建知识图谱,采用低冗余摘要生成方法生成实体关系摘要。仿真结果显示本文方法具有较好的检索性能,说明该方法具有较高的应用价值。
