针对特定领域的新词发现方法研究
2022-07-20申兆媛李晓龙
申兆媛,巢 翌,李晓龙,张 伟
(北京控制与电子技术研究所,北京 100038)
1 引言
随着计算机技术的发展和普及,党政机关、企事业单位推行无纸化办公,越来越多的信息资源以数字化和网络化的方式进行存储管理。在此背景下,保证企事业单位的数据安全工作便尤为重要,因而需要将数据安全工作落到实处,规避敏感信息泄露扩散的风险。而保护特定领域的敏感信息不被泄露的前提,就是要确定文件内容是否包含该领域的敏感词汇。
领域新词发现是用于对特定领域文本进行分析得到该领域相关的词或短语的过程,在特定领域中,新词层出不穷,准确高效地发现领域新词便至关重要。本项目中,领域新词定义为现有领域词典内的未登录词,即不在词典中的本领域词语。
当前新词发现方法主要分为无监督与有监督两类。无监督的新词发现方法通常需要大规模语料的支持,与有监督方法相比,无需构建带有标注的数据集。而无监督方法又分为两大类:基于规则与基于统计。基于规则的新词发现方法,是指利用语言构词规则并且联系上下文关系来发现新词,其中的核心部分是精准发现构词规则,进而匹配字词序列。该方法准确率较高,但由于规则覆盖面有限,其适用性较差,可移植性较低。基于统计的新词发现方法,是指通过统计模型来在大规模的实验语料中发现新词。该方法非常灵活、普适性强、易扩展且可移植性好,但需要对模型进行大量训练,准确率较低。Pecina等进行了大量的新词发现实验,使用了55种不同的统计量来识别2-gram字符串,他们的实验结果表明,点互信息(Pointwise Mutual Information, PMI)是评价文本中词汇相关性的最佳指标。
目前,对无监督的新词发现方法的研究大多基于规则与统计相结合,充分发挥两者的优势,期望使准确率与效率达到最优。杜丽萍等将改进的互信息与少量规则相结合,从大规模语料中自动识别领域词的方法,在基于百度贴吧语料的实验结果精度达到 97.39%,相较于原始互信息方法提高28.79%。雷一鸣等依赖切词系统,提出一种新的新词发现方案,该方案首先对语料进行分词,计算散串之间的互信息值,进而得到候选新词。然后,过滤低频词,通过邻接变化数的计算得到最终新词结果。该算法得到的新词识别的效果会取决于切词系统的好坏。刘伟童等从左至右逐字计算当前词的互信息来候选新词,然后计算邻接熵,并结合少量规则来过滤候选词,得到新词集,该算法解决了部分新词因切词错误而无法识别的问题,与使用N-gram算法后,将大量重复词串和垃圾词串识别为新词的问题,同时依赖词频,所以新词发现效率不高。
而领域新词的界定方法同样分为有监督与无监督两类,陈飞等利用条件随机场对序列输入标注的特点,提出了一系列区分新词边界的统计特征,同时比较了K-means聚类、等频率、信息增益三种离散化方法对新词发现效果的影响。Fu等将语料库的一部分手工标注为训练集(词语、词语链接和词语生成模式),然后使用隐性马尔可夫模型来预测领域词。该方法计算复杂度高,且需要大量手工标注的语料。Goh等引入隐性马尔可夫模型来切分文本并粗略对单词进行预标注,然后训练了一个支持向量机模型来提取关键注释,最后利用这些关键注释的特征从分词结果中识别出领域词,该方法依赖于分词结果与标签的准确性。
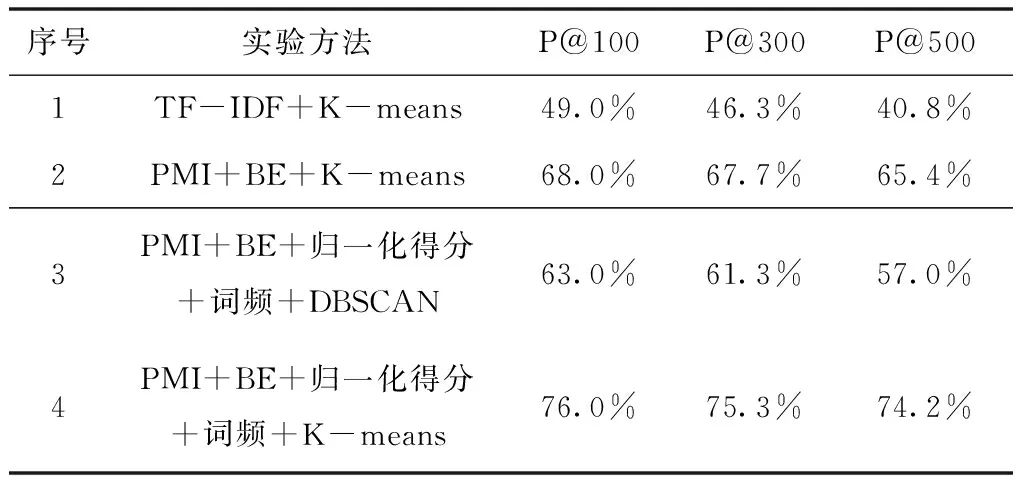
综上,若仅采用传统的切词工具对实验语料进行切分,会出现切词错误导致无法正确识别新词的现象;若直接采用N-gram算法对实验语料进行切分,则会出现大量的重复词串,因此使用Jieba工具结合本领域的构词策略对句子进行切分,以N-gram算法进行滑动取词,再利用点互信息、邻接熵等统计量与词频、归一化得分相结合来进行新词发现,最后用K-means算法来分离领域新词与常用新词,从而过滤得到领域新词集。
2 相关技术
2.1 点互信息
点互信息(Pointwise Mutual Information,PMI),也称为点间互信息,是信息论中衡量两个随机变量之间相互依赖的量度,即一个随机变量由于已知了另一个随机变量后不确定性的减少量。当应用于文本处理时,它可以可表示一个词内部的凝聚程度,即字与字或词与字之间的相关性越高,点互信息值就越大,成词的概率也就越大,故采用点互信息值来计算候选词串的内部凝聚度。点互信息的计算公式为

(1)
其中p
(x
,y
)表示字或词x
和y
在语料中共同出现的概率,p
(x
)、p
(y
)表示x
、y
单独出现在语料中的概率。PMI
(x
,y
)>0表示x
与y
相关,且值越大表示二者的相关性越高,即二者越可能组成有意义的词。2.2 邻接熵
熵是信息论中评估事件不确定性的统计量,当应用于文本处理时,可以用来衡量候选词的左右相邻字符的不确定程度,即邻接熵(Branch Entropy,BE)。若一个既成的词中的字符是该词的边界字符,那么这个字符的界外相邻字符是多样化的,即其不确定程度越高,说明其与另一侧字符形成词的概率就越高。而衡量某词内的最左字符是否能构成其左边界,使用的是左邻接熵;最右字符是否能构成其右边界使用的是右邻接熵。左邻接熵的计算公式为

(2)
同样地,右邻接熵的计算公式为

(3)
其中s
表示候选词w
左邻接字形成的集合,s
表示候选词w
右邻接字形成的集合;p
(w
|w
)表示w
是候选词w
左邻接字的条件概率,p
(w
|w
)表示w
是候选词w
右邻接字的条件概率;H
(w
)的值越大表示该词的最左边字是这个词的左边界的概率越大,H
(w
)的值越大表示该词的最右边字是这个词的右边界的概率越大。p
(w
|w
)与p
(w
|w
)的计算公式为
(4)
其中N
(w
)表示w
出现的次数,N
(w
,w
)表示w
和w
共同出现的次数,同样地,N
(w
,w
)表示w
和w
共同出现的次数。2.3 N-gram算法
N-gram是一种基于统计语言模型的算法,基本思想是:以字节为单位,将文本内容滑动取大小为N的窗口,形成长度为N的字节片段序列,每个字节片段称为一个gram,并统计语料中该gram出现的频率,根据预设的阈值进行过滤,得到候选词。该算法基于假设第N个词的出现仅与前N-1个词相关,与任何其它词无关。
由于N-gram算法不需要对文本语料进行语言学处理,因此具有语种独立性、书写错误容错性、无需词典等优势。针对特定领域文本内容的创新性和独特性等特点,本文采用N-gram算法对语料进行预处理。目前,二元增量Bigram算法和三元增量Trigram算法的精度较好,因此,使用Bigram算法对语料进行预处理。
2.4 Trie树
Trie树,也称为前缀树、字典树,通常用于对大量字符串进行计数、排序和存储。它具有以下三个基本属性:
1) 树中除根节点外的每个节点都只包含一个字符;
2) 从根节点到叶子节点,路径上的字符连成一个词;
3) 每个非叶子节点的所有子节点包含的字符都不相同。
将具有共同前缀的链接称为串,因此Trie树具有以下三个特点:
1) 前缀相同的词必须在同一个串中;
2) Trie树中的词只能共用前缀,不能共用词的其它部分;
3) Trie树中任何一个完整的词都必须从根节点开始到叶节点的结束,这意味着对一个词的搜索也必须从根节点开始,到叶节点结束。
这些特点也使其在检索方面与哈希树相比具有以下两大优势:
1) 公共前缀的词都在同一个串中,即排除与当前搜索字符不同的串后,搜索范围大大缩小;
2) Trie树本质上是一个有限状态自动机,这意味着从Trie树的一个节点到另一个节点的转移行为完全由状态转换函数控制,即逐字搜索Trie树时,从一个字符到下一个字符的比较不需要遍历该节点的所有子节点。
也就是说,Trie树可以最大限度地减少不必要的字符串比较,提高搜索效率,因此,使用Trie树存储候选词串。
3 针对特定领域的新词发现方法
3.1 算法设计
在对特定领域文本数据进行新词发现的研究过程中,发现传统的基于统计的新词发现算法效果不太理想。通常由于特定领域词的特殊性,语料预处理时保留的连字符或双引号等的特殊符号,使得传统算法在新词发现过程中产生误分现象;新词发现后的结果并不能有效区分该新词是否属于本领域。为解决以上问题,本文对基于点互信息和左右邻接熵的传统新词发现算法进行了以下改进:
1)可根据需求加入特定领域的成词策略,使切分与组合候选词串时更适应本领域,更加准确、有效。
2)在过滤时除了点互信息、左右邻接熵过滤,加入归一化得分与词频阈值的成词筛选,使分词结果得到进一步的提升。
3)使用K-means划分聚类算法实现领域新词与常用新词的分离。
3.2 算法流程
本文是针对特定领域的语料进行领域新词的发现算法的设计与实现,由于语料主要为中文,所以首先对语料进行预处理;利用Jieba结合本领域的成词策略分词,再采用N-gram方式组合出候选词串;计算候选词串的点互信息、左右邻接熵、归一化得分与词频,筛选新词;再向量化新词并降维,采用K-means划分聚类算法分离出领域新词与常用新词,最终得到领域新词集,供下游任务使用。算法流程图如图1所示。

图1 算法流程图
3.3 处理过程
1) 语料预处理
语料为段落式文本内容,故首先对文本进行预处理。将文本按照除中文、字母、数字、连接符、双引号(示例)外的字符进行分句,并去除用于分句的符号与停用字,留下候选短句。
输入:语料位置P
输出:候选短句集合M
① C=readFile(P) #读入语料
②M=rmvNeedless(C) #换行符代替非中文、字母、数字、连接符、双引号外的字符
③M=rmvStopwords(M) #去除停用字
④ return M
2) 形成候选词串
利用Jieba工具结合成词策略对候选短句进行分词,并利用Bigram算法组合候选词串。
输入:候选短句集合M
输出:候选词串集合W
①specrules=’…’ #本文适用的特定领域成词策略
② jieba.load_userdict(re.find(specrules))
W=jieba.cut(M) #Jieba加载成词策略并分词
③W=ngrams(2,W) #Bigram组合成词
④ return W
3) 新词筛选
当前词串的点互信息、左邻接熵、右邻接熵、词频与归一化得分,当均大于阈值,且小于最大扩展次数时,成为候选新词串;当右邻接熵或左邻接熵小于阈值时,向右或向左扩展一个词串,计算扩展后的点互信息,直至扩展次数超过阈值。在上述候选新词集中,去除旧词典已有的词,形成新词集。
输入:候选词串集合W
输出:新词集合N
FORw
(x
,y
) :W