跨度语义增强的命名实体识别方法
2022-07-19耿汝山陈艳平唐瑞雪黄瑞章秦永彬董博
命名实体识别(named entity recognition,NER)是自然语言处理(nature language processing,NLP)中一项重要的基本任务
,文本中的实体往往携带重要的信息,因此识别实体对于下游任务如关系提取
、问题生成
和实体链接
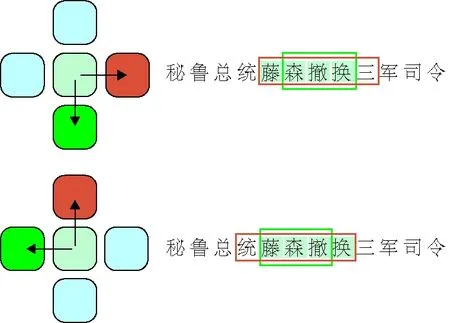
等有重要的影响和积极的意义。由于语言在表达上具有迭代、递归的特点,文本中存在着大量的嵌套语义。例如,“秘鲁总统藤森撤换三军司令”,“秘鲁总统藤森”中嵌套着“藤森”这个实体,且它们归类的实体类型都为“人”。嵌套语义识别依然是自然语言处理中的研究难点。
目前,基于深度学习的命名实体识别的方法可以分为基于序列模型、基于跨度模型和超图的方法。基于序列信息的方法是对语句中的每个字符打标签,其主要思想是通过神经网络的方法对每个字符进行向量表示然后通过一定的编码运算分类。依据每个字符分类的类型再合并为实体
。基于跨度模型的方法是对字符进行组合以形成不同的跨度,跨度信息中包含有每个字符的信息,因此特定的跨度信息代表着特定的实体信息,所以通过对跨度信息的分类来识别不同的实体
。基于超图的方法是允许一条边连接到多个节点,以代表不同的实体,使用神经网络对这些边和节点进行编码最后从超图标签中恢复实体
。虽然深度学习的方法可以加入额外的语义特征信息,但是以上这些方法没有考虑字与字之间的交互问题,会出现语义不足的情况。语义不足会降低模型对于实体的识别精确度,以及无法识别出存在嵌套情况的实体。
循环神经网络(recurrent neural networks,RNN)模型在传统的神经网络模型的基础上发展起来,因而具有很强的非线性数据处理能力,在机器翻译、自动问答、句法解析等自然语言处理任务中被广泛的使用。RNN是一类用于处理序列数据的神经网络模型,序列数据具有前后数据相关联的特点
。但是,RNN在参数过多的时候容易发生梯度爆炸问题,为了改善其局限性,研究人员提出了许多改进的循环神经网络结构,其中长短期记忆网络(long short term memory,LSTM)和门控循环单元(gate recurrent unit,GRU)就是最常用于处理文本循环神经网络变种模型。文献[16]模型使用分层的RNN对人体的姿势进行识别,文献[17]模型使用门控RNN模型增强了模型对长距离信息的学习能力,文献[18]将残差网络引入RNN中处理更长的文本序列。通常,RNN用来处理一维信息,无法处理超越一维的信息。对于此问题,多维循环神经网络(multi-dimensional recurrent neural networks,MD-RNN)
被提出并可以在高维度的信息上进行语义增强。目前,多维循环神经网络已经在图像分类
和语音识别
等领域都取得了优异的效果。MD-RNN是RNN的一种泛化,通过将单个循环神经网络的连接替换为与数据维度相同的连接来处理多维数据。为了增强MD-RNN利用上下文信息的能力,同时避免环节RNN在处理长序列数据时梯度爆炸或梯度消失的问题,通常将长短期记忆网络(LSTM)和门控循环神经网络(gated recurrent unit,GRU)用作隐藏单元。
基于上述研究,MD-RNN为融合跨度语义信息提供了一种有效的手段,在一定程度上解决了语义不足的问题。本文提出了一种增强跨度信息的方法,在利用跨度信息进行实体识别的基础上,增强跨度之间的语义特征,从而有效地增加了跨度的语义信息。首先,使用预训练语言模型提取字符向量信息,对字符向量进行枚举拼接形成矩阵。其次,对矩阵使用MD-RNN进行跨度级的语义增强。最后,对矩阵中的跨度进行分类。模型在ACE2005英文数据集与中文数据集上进行了实验,分别取得了86.92和81.16的
值,与其他主流的方法相比,该方法取得了最优的结果。
期望、熵和超熵是代表云模型的三大数字特征。期望作为整个云图的中心值,是隶属度最大、最能表达定性要求的点;熵值则表达出了云的模糊性,指的是云模型在整个坐标区域的跨度大小;超熵代表了不确定性,超熵越大,云模型的离散程度越大,云图越分散。
1 跨度语义增强模型
模型的整体结构如图1所示,主要分为编码、表填充、跨度语义增强、输出4个模块,其中表填充和跨度意义增强可以反复叠加多层,下面分别介绍各个模块。
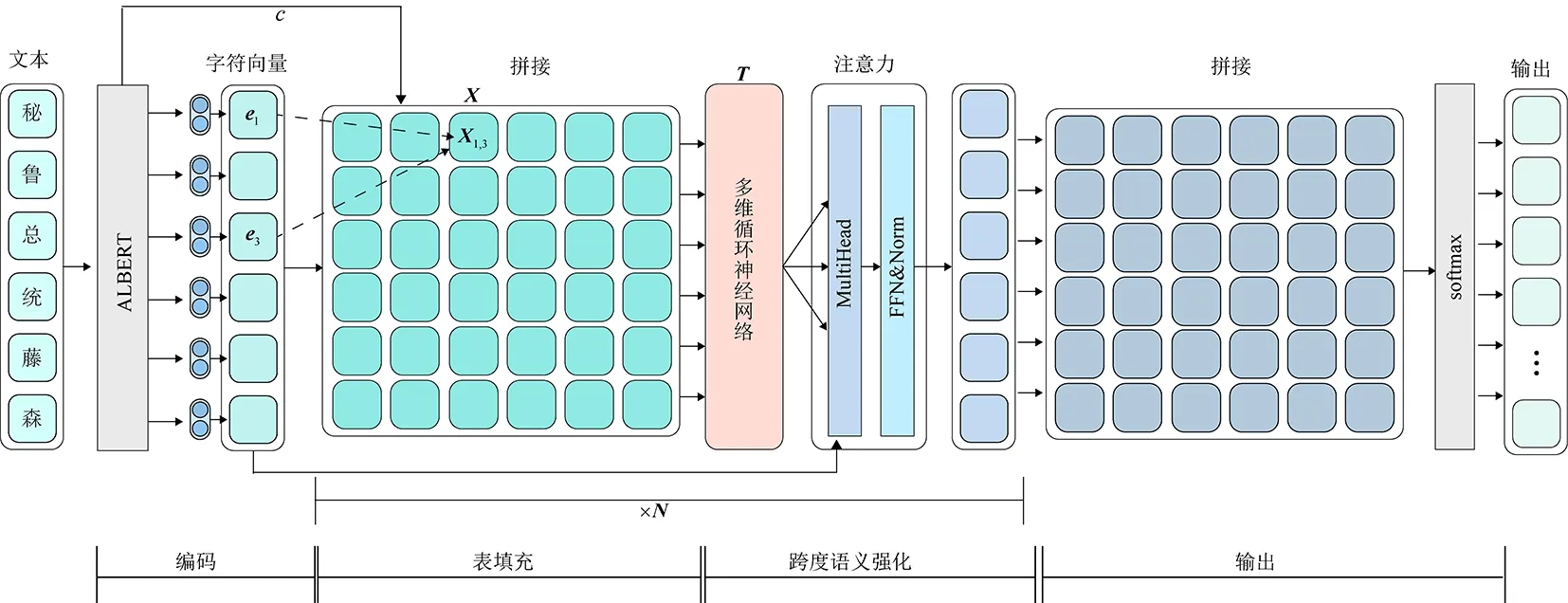
1.1 编码
假设输入模型的一句话
=〈
,
,…,
〉,
表示句子中的第
个字。对
通过ALBERT的预训练语言模型提取出含有上下文信息的连续稠密向量
∈
×
,
表示句子长度,同时使用GloVe预训练字向量将其编码为连续稠密向量
∈
×
,公式如下
本模型的注意力的计算流程如图4所示。将注意力机制扩展到多个头,并且都有独立的参数。拼接输出,使用全连接层来得到最终的注意力向量,其余部分与Transformer类似。
,
=
(
)
(1)
=
(
)
(2)
这件事情翠姨是晓得的,而今天又见了我的哥哥,她不能不想哥哥大概是那样看她的。她自觉地觉得自己的命运不会好的。现在翠姨自己已经订了婚,是一个人的未婚妻;二则她是出了嫁的寡妇的女儿,她自己一天把这个背了不知有多少遍,她记得清清楚楚。
(3)
2
1
2 评价指标
1.2 表填充
首先将得到的编码层输出
=[
,
,
,…,
]进行枚举拼接。将一个长度为
的句子拼接为
×
的表格
∈
××
,其中表格
行
列的位置对应句子中第
个词与第
个词进行拼接,此时
并不包含上下文的信息,公式如下
,,
=max(0,[
-1,
;
-1,
])
(4)
式中
表示当前运算的层数。表格
中每一个格子都代表着一个子序列跨度,这样就将句子中所有可能的子序列都表示出。同时,将ALBERT预训练模型中得到的注意力权重
与表格拼接,作为补充信息,更新公式如下
,,
=max(0,[
-1,
;
-1,
;
,
])
(5)
通过这种方式,可以将预训练模型的权重
添加到跨度语义增强中,补充语义信息。
(3)重介质选和浮选效果差,实际生产数据与理论数据偏差大。主要表现在介耗高达4.5 kg/t,远高于同行业水平;循环水浓度高,为保证矿井生产,不得不强制洗煤生产,导致重介质选和浮选效果恶化;重介质操作困难,不稳定,导致矸石中小于1.80 kg/L密度级达到4%左右,洗混煤中小于1.40 kg/L密度级在10%上下。
1.3 跨度语义增强
通过拼接得到的每个表格只有边界的信息,缺少句子的上下文信息,因此使用MD-RNN增强跨度语义信息以弥补缺失的信息。由于传统循环神经网络是在一维的信息上进行计算,因此只接受上一个位置的隐藏层输出。然而,表格具有二维结构的特点,所以二维循环神经网络可以充分利用表格信息。在表格中每个位置的隐藏层不仅接受表格横向的上一个位置的隐藏层输出,也接受表格纵向的上一个位置的隐藏层输出。
将表格
输入到使用GRU作为隐层的MD-RNN中计算,得到表格
。整个计算过程分为门控计算和隐层计算两部分。计算门控的过程如下
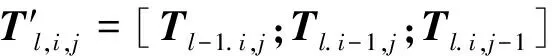
(6)
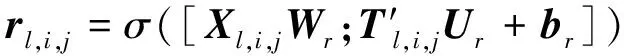
(7)
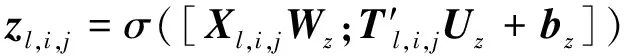
(8)
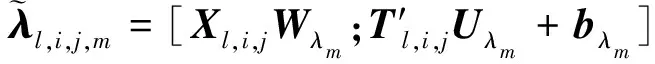
(9)
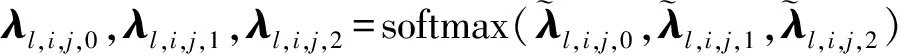
(10)
实体识别需要同时识别出实体准确的位置和类别,只有当实体位置和类别都识别正确时结果才算正确。本文实验使用综合指标
值来衡量模型性能,公式如下
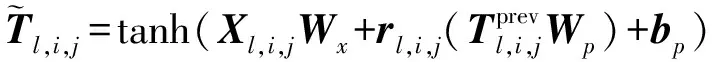
(11)
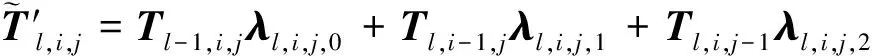
(12)
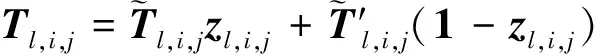
(13)
式(17)表示3种输入之间的运算关系。
将序列信息升为表格信息带来了计算量上的指数增加,因此需要考虑对表格和计算进行一定的优化。在表格存储的信息中反对角线是相同的,因此为了加速计算以减少运算量可以只关注矩阵的上三角信息。一个长度为
的序列更新为表格信息后只需要计算(
+1)×
2个格子,MD-RNN可以在行与列方向上任意挑选方向组合。如图2所示,MD-RNN在
维上有2
种计算方向,在二维的数据上共有4种方式。
根据文本信息的特点,使用所有方向上的信息会导致一些计算的重复利用,并不能很好增强跨度语义信息。为了降低计算量同时尽可能使当前跨度学习到临近跨度的语义信息,可只选择两个方向(
)(
)进行计算,并将计算的结果拼接作为跨度语义增强后的输出,计算公式如下
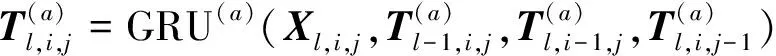
(14)
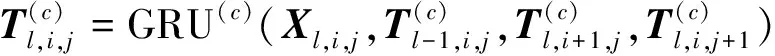
(15)
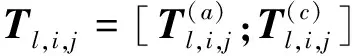
(16)
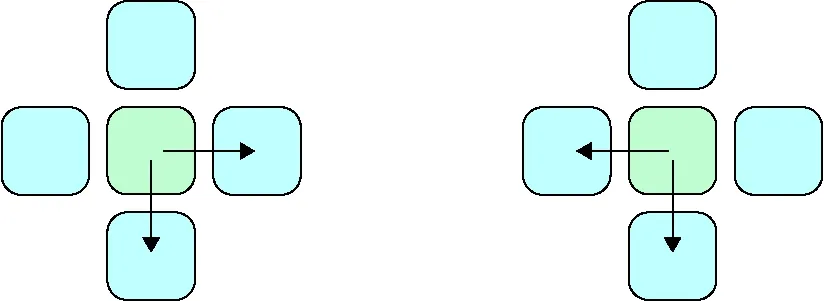
如图3所示,绿色方块代表当前的跨度,蓝色的方块代表了临近的跨度,(
)方向上的当前跨度会增强后一个跨度的信息,(
)方向上的会增强到之前跨度的信息,最后将两个方向上的结果进行拼接,得到包含跨度上下文信息的表格
。
注意力的使用是为了梳理跨度信息,跨度信息在经过语义增强后会出现语义信息混乱的情况。注意力运算将根据序列信息调整跨度信息,输入是一条句子的向量,第
个向量代表着句子中的第
个字,以及MD-RNN的输出表格
,其整体结构是基于Transformer,将自注意力机制(self-attention)中的缩放点乘替换成跨度引导的注意力机制
。Transformer在自然语言处理领域取得了优异的成绩,其采用的自注意力机制是成功的关键因素
。传统的自注意力机制有查询(
)、键(
)和值(
)3个输入,计算过程如下
总之,语文生活化,生活语文化。无论哪种方式读写结合,无不彰显《普通高中语文新课标》“语文学科素养是学生在积极的语言实践活动中积累与构建,并在真实的语言运用情境中表现出来的语言能力及其品质,是学生在语文学习中获得的语言知识与语言能力,思维方法与思维品质,情感、态度与价值观的综合体现”这一理念,因为读写结合是语文科本质性的行为表现,语文核心素养的研究也需要以促进学生发展为基础、以语文科塑造人的独立品格与所需能力为基础实现学生终身教育,让我们一起努力践行让生活生命作文与语文核心素养齐飞吧!
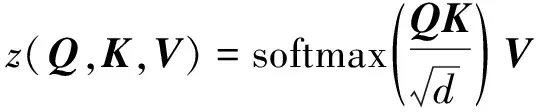
(17)
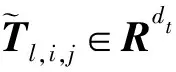
本模型的数据输入来自前一个序列表示层
-1
。在self-attention中考虑
=
=
=
,可以发现函数softmax的输出是一个基本的注意力权重,而MD-RNN输出的
来自于
-1
。因此,可以用
来代替计算
和
的相似度,这样就可以把
带入到self-attention公式。这个过程称为跨度引导的注意力机制,公式如下
语文学习中,若学生具备综合阅读能力,能够帮助学生更好地理解课文内容,加强学生对课本中文字及词语等知识的理解,这对学生获取优异的语文成绩有很大帮助。此外,学生综合阅读能力的提高还对学生口语表达能力及写作能力的提升有巨大帮助。学生具备综合阅读能力,可以对文章内容获得全方位的理解,掌握文章的表达方法,体会文章的思想情感,这样可以让学生在口语表达的时候用词更加准确,并且有效表达自己的思想情感,同时借助综合阅读还可以积累一些有效的写作方法与写作素材,为学生进行文章写作奠定了良好的基础。
(
,
)=
(18)
式中:
表示可学习参数,用于调整
的维度;
来自于字符序列
-1
。与传统的注意力的计算方法相比,使用跨度信息来引导计算会有一些相对应的优势:①不需要计算相似度,而使用
来减少计算量;②
的计算过程有关于行、列和前几层的信息,这可以更好地获得上下文信息;③使用
允许表格编码器参与序列表示学习过程。
式中:X为样品中元素的含量,mg/100 g;c为测定用样品中元素的浓度,μg/mL;c0为试剂空白液中元素的浓度,μg/mL;V为样品定容体积,mL;f为稀释倍数;m为样品质量。
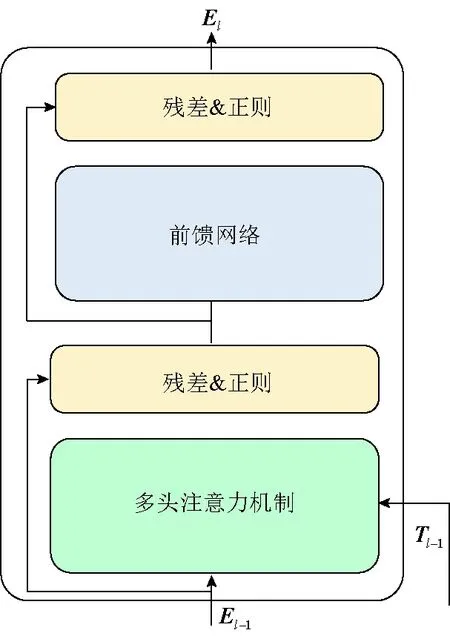
在注意力机制后使用前馈神经网络(FFNN)对关注权重进行串联和归一化,公式如下
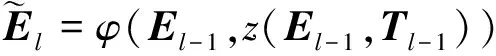
(19)
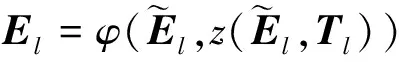
(20)
式中
表示层规范(LayerNorm)运算。
1.4 预测与损失函数
在最后一层跨度意义增强后,对输出的序列信息进行枚举拼接,并使用拼接的表格信息
去预测嵌套的实体标签,公式如下
(
)=softmax(
+
)
(21)
式中:
表示预测标签的随机变量;
表示模型参数的估计概率函数。使用交叉熵函数被用作损失函数,给定输入
和标签
计算损失函数,公式如下
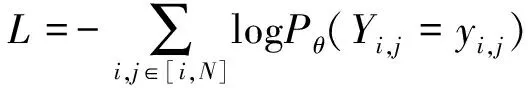
(22)
在训练的过程中,只考虑矩阵中上三角的内容,选择最可能的标签作为答案进行输出,公式如下
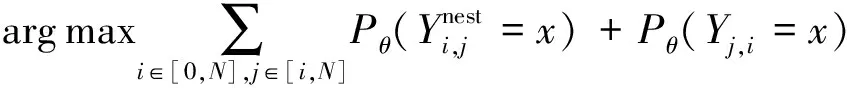
(23)
2 实验与结果分析
为了验证本文提出的基于跨度语义增强的嵌套命名实体识别模型的效果,所以选择与其它基于深度学习的命名实体识别模型进行对比。本文在ACE2005中文数据集和ACE2005英文数据集上进行实验。使用精确率
、召回率
以及
值作为实验的主要评估指标,通过在相同数据集上进行实验,验证本模型的各项性能。
2.1 实验设置
2
1
1 数据集介绍
第二,善用教材中隐性数学文化知识进行拓展训练.当前教材中出现了许多高考数学文化命题素材来源题.如“阿波罗尼斯圆”、“回文数”、“三角形数”分别出现在人教版高中数学必修2第131页习题4及必修3第51页第3题和必修5第28页的正文部分.因此,教师上课时要有意识的对这些数学文化素材或历史名题进行拓展改编.比如根据布洛卡点的基本性质,就可以结合余弦定理、外森比克不等式和等比数列等知识拓展许多变式问题[6].
ACE2005中文数据集和ACE2005英文数据集是语言数据联盟(Linguistic Data Consortium,LDC)于2006年发布用于各项自然语言处理任务的公共数据集。ACE2005英文数据集包含7种实体类别,共599篇英语文档,分别为PER(人物,person)、ORG(组织机构,organization)、GPE(地理/社会/政治实体,geo-political)、LOC(处所,locations)、FAC(设施,facilities)、VEH(交通工具,vehicle)、WEA(武器,weapon)。ACE2005中文数据集包括同样的7种实体类别,共633篇中文文档。
=([
;
])
+
两个数据集都按照8∶1∶1划分位训练集、验证集和测试集,其中ACE2005英文数据集采用文献[5]的数据集划分方法。
式中:
表示ALBERT语言模型的运算;
表示GloVe语言模型的运算;
∈
××
表示ALBERT的注意力向量;
∈
×
表示编码层的输出向量;
∈
×
和
表示可学习参数。通过将两种向量进行拼接,并经过线性层来代表编码层输出向量。
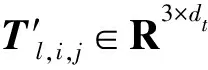
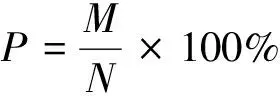
(24)
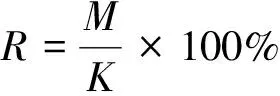
(25)
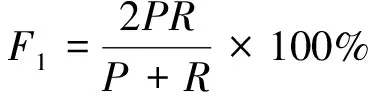
(26)
式中:
表示正确识别出的命名实体个数;
表示识别出的命名实体个数;
表示标准结果中的命名实体个数。
2.1.3 实验环境与参数设置
本文提出的跨度语义增强模型在Python3.7和Pytorch1.8的环境下进行实验。设置模型在训练、验证与测试时的Batch_size分别为16、8、8。为降低神经网络在训练过程中过拟合造成的影响,设置Dropout为0.5。初始化的字嵌入向量使用了GloVe模型进行训练并将其保存,其维度为100。在模型训练中不更新单词的GloVe向量,将隐藏层的大小设置为200,并且将每个MD-RNN的隐藏层大小设置为100。学习率设置为0.001,Adam作为模型的优化工具,上下文的信息使用ALBERT进行训练并保存最后一层的输出作为文字的上下文信息。ALBERT是一个共享Transformer参数的轻量型BERT模型
,在模型中使用的版本是albert-xxlargev2,其隐藏层的维度为4 096。
2.2 结果分析
本文选取了几个在命名实体识别上取得了较高性能的模型进行对比,表1展示了与这些方法在ACE2005英文数据集上的性能区别,通过使用ALBERT作为预训练语言模型来提供上下文的信息。本文模型的
值达到了最优的86
92,
、
值也达到了最好的性能,表明了本文方法的优越性。
在鱼、蟹、甲鱼等养殖中,也可以套种一些青虾、黄鳝等新品种来养殖。还需要促进整体的混合养殖,将龟、蟹、青虾等养殖品种和鱼类进行混合养殖,可以将其中的一个品种作为主体,并在有限的水体资源中充分应用,将达到经济效益的提升。
2.3 PCR敏感性试验 测定模板DNA浓度为50 ng/μL,通过1∶10倍比稀释法稀释模板进行PCR敏感性试验,当模板稀释度为10-8时,没有扩增条带出现,见图3,即PCR法检测下限达到10-7,即本PCR方法检测DNA的灵敏度达到fg水平。
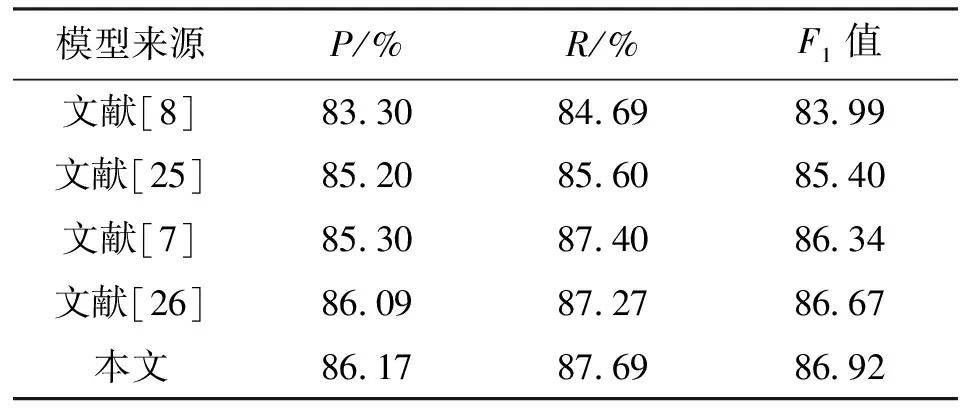
从整体上看,文献[8]的模型使用次佳最优路径的方法识别嵌套命名实体在精确率
和召回率
的
结果上明显低于其他方法。这与其使用的选择次佳路径的方式有关,选择次佳路径的算法会对结果有着明显的影响和限制。文献[26]的回归模型性能与其他传统方法比取得了最好的F
值,其模型在设计的过程中考虑到了跨度信息利用不充分的问题,以及长实体识别较困难的现象,用回归来生成跨度建议来定位实体位置,然后利用相应的类别标记边界来对跨度建议再次调整。与其相比,本文的模型在精确率、召回率和F
值上都高于回归模型,这说明本文模型识别出的实体绝大多数是真实有效的。这是由于结合了跨度级上下文信息为模型提供了更加准确的实体表示,使得分类器有能力确定矩阵中的每一个单位是否为有效的实体跨度。
鼓励发展煤矸石烧结空心砖、轻骨料等新型建材,替代粘土制砖。鼓励煤矸石建材及制品向多功能、多品种、高档次方向发展。积极利用煤矸石充填采空区、采煤沉陷区和露天矿坑,开展复垦造地。
表2展示模型在ACE2005中文数据集上的性能。“Shallow BA”模型采用两个独立的CRF模型来识别起点与终点边界,候选实体建立起来后,再对候选实体进行分类。“Cascading-out”模型每种实体被单独的识别,如果出现嵌套的相同类型的实体,则会识别最外层的实体。“Layering-out”模型是由两个独立的BERT-BiLSTM-CRF模型去识别外层的实体与内层的实体,“NNBA”模型通过两个BiLSTM-CRF模型分别识别实体的开始与结束位置,然后通过组合的方式生成候选实体再分类。本文模型的精确率较高,大幅度超过了之前的模型,这可能与堆叠多层的跨度语义增强模块有关。
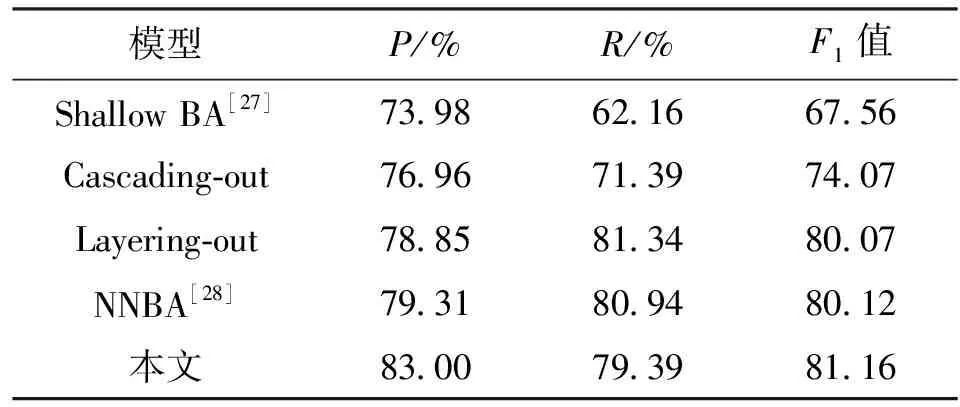
本文模型在两种语言的数据集上进行实验是为了验证不同语言上的适用性。整体上,本文的模型都取得了非常高的结果。
2.3 句子长度(字数)对模型性能影响分析
长句子会导致模型对实体信息不敏感
,提高模型对长句子中实体识别的能力对模型性能有积极的作用,因此探究去掉跨度语义增强模块对不同长度句子的性能影响。本实验在ACE2005英文数据集上分析不同长度句子对于跨度语义增强模块的影响,模型参数保持不变,其结果如图5所示。
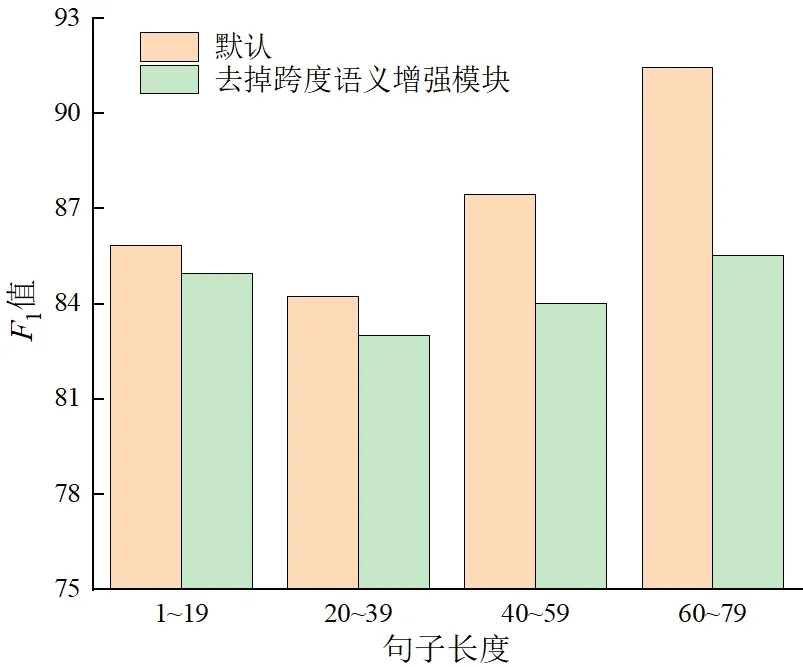
通过对两种方法进行对比,完整的模型比去掉跨度语义增强模块的模型在长句子的区间(40到59与60到79)上有了明显的性能提升。在较短句子的区间上,也有一定的提升。
2.4 注意力权重可视化
为了更好地探索注意力机制在模型中的作用,将注意力权重进行了可视化,如图6所示,使用bertvit工具进行可视化处理。为了更好地突出与self-attention的不同,同时也对模型进行了修改并做了self-attention的可视化。重点比较两种算法下的单词与单词之间的关系,模型的其他参数与之前保持一致,在此使用一个例子“We’re paying attention to all those details for us, Chris Plante at the pentagon.”来进行说明。这句话中有4个实体,即“we”“Chris Plante at the pentagon”“the pentagon”和“us”。
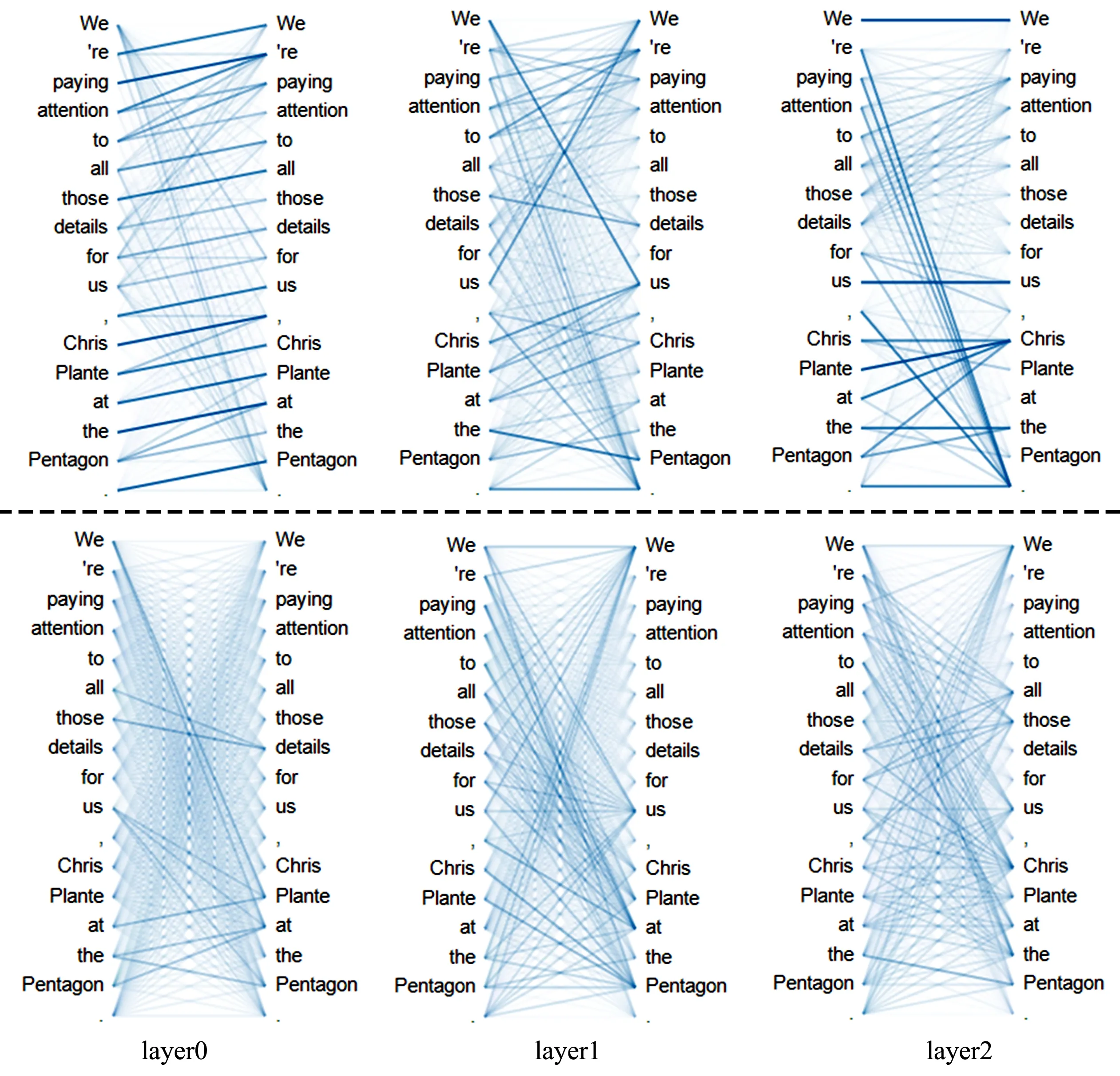
在图6中深色的线代表相对较高的注意权重,右侧的层数代表着堆叠的跨度增强模块的层数,可以看出,不同层之间注意力关注到的内容是不同的,“Chris”对“we”“us”和“Plante”的注意权重较高,它们的实体类型是相同的,同一类型的实体彼此之间有相对较高的相似度。因此,同一类型的实体之间的注意权重是相互关联的,与self-attention算法相比,self-attention的关注重点不够突出,即图中的深色线不够明显。由此可以证明,本模型的注意力算法优于原始的算法,并且可以关注到同种类型实体之间的关系。
2.5 消融实验
为了验证注意力机制和MD-RNN的有效性,本文设计了消融实验,结果如表3所示,w/o表示去掉某模块。注意力机制在模型中用于梳理跨度信息的权重,在去掉注意力机制后表格内的序列信息会不可避免的产生一定的混乱,这对于实体的准确性有较大的影响。在去掉跨度引导的注意力模块后,模型性能有了明显下降。
In conclusion, pain in pancreatic cancer has a complex physiopathology. It eminently implies a neuronal invasion and a neurogenic inflammation.
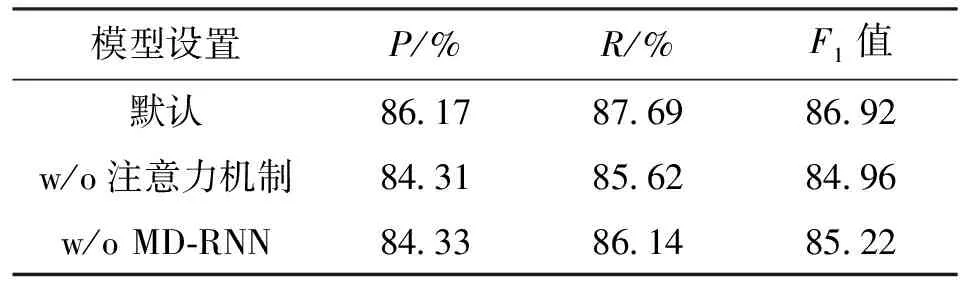
MD-RNN在模型中用于进行跨度语义增强,并且融合跨度级语义特征信息,去掉MD-RNN后性能有所下降,这证明了跨度信息增强对于模型性能提升有帮助。跨度语义信息的增强可以补充因利用边界信息导致丢失的部分语义信息,并且跨度信息对于嵌套实体识别有着较大的帮助。
捷达车稳稳驶停学校古城墙旁,小女新开业的书店仍然灯火辉煌,我匆匆下车。丁香花摇下车窗玻璃探出头来忽然问我,“老龚,昆明是春城,它很美吧!” 我正欲回答,那车,却像一阵风一样远了。
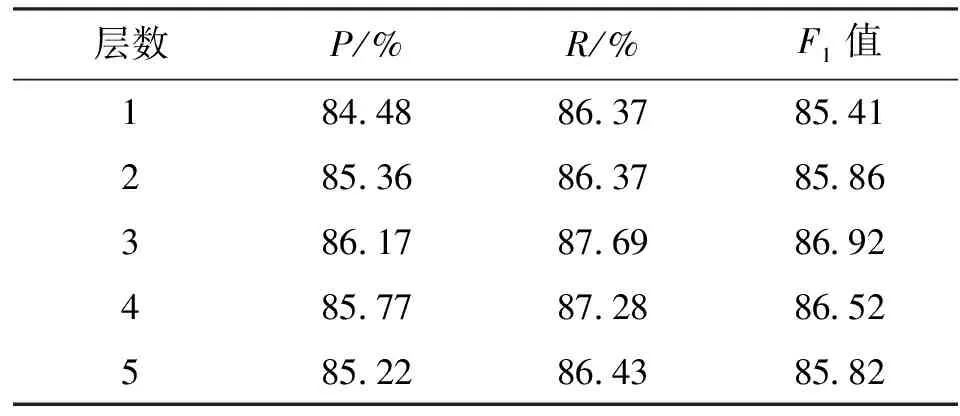
2.6 层数与性能
如表4所示,探讨了表填充和跨度引导注意力机制层数与模型性能之间的关系。为了保持与前面实验的一致性,选择ACE2005英文数据集进行实验,除了编码器的层数之外其他的超参数均保持不变。一般来说,增加编码器数量可以提高模型的性能,但当编码器的数量超过一个范围时,性能将开始下降。在实验中选择编码器层数为1、2、3、4、5。通过对实验结果进行分析发现,在层数大于3之后,模型的性能就已经开始下降,这应该是由过拟合而导致的性能下降。
3 结 语
本文提出一种跨度语义增强的命名实体识别方法,解决了命名实体识别中出现的语义不足、召回率不高等问题,并将传统的一维文本信息拼接成二维的表格信息,使用MD-RNN和注意力模型作为跨度语义增强模块,进而有效增强了跨度之间的联系。实验结果表明,本文提出的方法相比之前基于跨度模型的嵌套命名实体识别方法有着明显优势。
透雾,也称视频图像增透技术。大华透雾技术主要分为电子透雾和光学透雾两种。大华电子透雾基于ISP上算法实现,适用于一般的轻度雾霾环境使用,主要优势有:
在下一步的工作中,将探究如何将跨度语义增强方法应用到其他领域,以及探究一种新的跨度语义融合机制去融合跨度间的语义信息。
:
[1] 黄铭, 刘捷, 戴齐. 融合字词特征的中文嵌套命名实体识别 [J]. 现代计算机, 2021, 27(34): 21-28.
HUANG Ming, LIU Jie, DAI Qi. Chinese Nested named entity recognition integrating improved representation learning method [J]. Modern Computer, 2021, 27(34): 21-28.
[2] XIONG Chenyan, LIU Zhengzhong, CALLAN J, et al. Towards better text understanding and retrieval through kernel entity salience modeling [C]∥The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. New York, NY, USA: ACM, 2018: 575-584.
[3] ZHOU Qingyu, YANG Nan, WEI Furu, et al. Neural question generation from text: a preliminary study [C]∥Natural Language Processing and Chinese Computing. Berlin: Springer, 2018: 662-671.
[4] GUPTA N, SINGH S, ROTH D. Entity linking via joint encoding of types, descriptions, and context [C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: ACL, 2017: 2681-2690.
[5] JU Meizhi, MIWA M, ANANIADOU S. A neural layered model for nested named entity recognition [C]∥Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, Washington, USA: ACL, 2018: 1446-1459.
[6] FISHER J, VLACHOS A. Merge and label: a novel neural network architecture for nested NER [C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Seattle, Washington, USA: ACL, 2019: 5840-5850.
[7] WANG Jue, SHOU Lidan, CHEN Ke, et al. Pyramid: a layered model for nested named entity recognition [C]∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle, Washington, USA: ACL, 2020: 5918-5928.
[8] SHIBUYA T, HOVY E. Nested named entity recognition via second-best sequence learning and decoding [J]. Transactions of the Association for Computational Linguistics, 2020, 8: 605-620.
[9] XIA Congying, ZHANG Chenwei, YANG Tao, et al. Multi-grained named entity recognition [C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Seattle, Washington, USA: ACL, 2019: 1430-1440.
[10] XU Mingbin, JIANG Hui, WATCHARAWITTAYAKUL S. A local detection approach for named entity recognition and mention detection [C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Seattle, Washington, USA: ACL, 2017: 1237-1247.
[11] SOHRAB M G, MIWA M. Deep exhaustive model for nested named entity recognition [C]∥Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: ACL, 2018: 2843-2849.
[12] LUAN Yi, WADDEN D, HE Luheng, et al. A general framework for information extraction using dynamic span graphs [C]∥Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Volume 1 Human Language Technologies. Seattle, Washington, USA: ACL, 2019: 3036-3046.
[13] LU Wei, ROTH D. Joint mention extraction and classification with mention hypergraphs [C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: ACL, 2015: 857-867.
[14] MUIS A O, LU Wei. Labeling gaps between words: recognizing overlapping mentions with mention separators [C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: ACL, 2017: 2608-2618.
[15] 张西宁, 郭清林, 刘书语. 深度学习技术及其故障诊断应用分析与展望 [J]. 西安交通大学学报, 2020, 54(12): 1-13.
ZHANG Xining, GUO Qinglin, LIU Shuyu. Analysis and prospect of deep learning technology and its fault diagnosis application [J]. Journal of Xi’an Jiaotong University, 2020, 54(12): 1-13.
[16] DU Yong, WANG Wei, WANG Liang. Hierarchical recurrent neural network for skeleton based action recognition [C]∥2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2015: 1110-1118.
[17] TANG Duyu, QIN Bing, LIU Ting. Document modeling with gated recurrent neural network for sentiment classification [C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: ACL, 2015: 1422-1432.
[18] WANG Yiren, TIAN Fei. Recurrent residual learning for sequence classification [C]∥Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: ACL, 2016: 938-943.
[20] GRAVES A, MOHAMED A R, HINTON G. Speech recognition with deep recurrent neural networks [C]∥2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ, USA: IEEE, 2013: 6645-6649.
[21] GRAVES A, SCHMIDHUBER J. Offline handwriting recognition with multidimensional recurrent neural networks [C]∥Proceedings of the 21st International Conference on Neural Information Processing Systems. New York, NY, USA: ACM, 2008: 545-552.
[22] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. New York, NY, USA: ACM, 2017: 6000-6010.
[23] 方军, 管业鹏. 基于双编码器的会话型推荐模型 [J]. 西安交通大学学报, 2021, 55(8): 166-174.
FANG Jun, GUAN Yepeng. A session recommendation model based on dual encoders [J]. Journal of Xi’an Jiaotong University, 2021, 55(8): 166-174.
[24] 李军怀, 陈苗苗, 王怀军, 等. 基于ALBERT-BGRU-CRF的中文命名实体识别方法 [J/OL]. 计算机工程 [2021-10-01]. https:∥doi.org/10.19678/j.issn.100 0-3428.00616 30.
LI Junhuai, CHEN Miaomiao, WANG Huaijun, et al. Chinese named entity recognition method based on ALBERT-BGRU-CRF [J/OL]. Computer Engineering [2021-10-01]. https:∥doi.org/10.19678/j.issn.100 0-3428.00616 30.
[25] YU Juntao, BOHNET B, POESIO M. Named entity recognition as dependency parsing [C]∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle, Washington, USA: ACL, 2020: 6470-6476.
[26] SHEN Yongliang, MA Xinyin, TAN Zeqi, et al. Locate and label: a two-stage identifier for nested named entity recognition [C]∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Volume 1. Seattle, Washington, USA: ACL, 2021: 2782-2794.
[27] CHEN Yanping, ZHENG Qinghua, CHEN Ping. A boundary assembling method for Chinese entity-mention recognition [J]. IEEE Intelligent Systems, 2015, 30(6): 50-58.
[28] CHEN Yanping, WU Yuefei, QIN Yongbin, et al. Recognizing nested named entity based on the neural network boundary assembling model [J]. IEEE Intelligent Systems, 2020, 35(1): 74-81.
