结合信息保留的多头注意力图池化模型
2022-07-18叶海良曹飞龙
顾 昕,叶海良,杨 冰,曹飞龙
(中国计量大学 理学院,浙江 杭州 310018)
在社交媒体、生物工程和交通运输等领域存在许多具有图结构的数据,它们往往是不规则且无序的,因此,传统的卷积神经网络[1-2]难以直接对其进行处理。近年来,图神经网络(Graph Neural Networks, GNNs)[3]成功地将卷积运算推广到图数据上,有效地解决了这一问题。GNNs主要是利用节点特征信息及边信息来计算节点表示,应用于节点分类[4]及链接预测[5]等节点级别的任务。对于图分类、图生成等图级别的任务而言,没有池化层的GNNs无法获取图数据的图级表示,因此需要构建针对图数据的池化操作。
现有的图池化方法主要有基于核的方法和基于神经网络的方法。基于核的方法通常依据图的结构特性计算不同图之间的相似性,进而实现图分类。如随机游走核[6],它同时对两个待分类的图执行随机游走,然后计算两次游走产生的路径数,从而得到两个图的相似性。然而大多数基于核的方法没有特征提取,直接将图转换为固定长度的实值特征向量,造成图级表示学习不充分,而带有特征提取的核方法[7]计算复杂度高以及特征提取与分类器分离,不能以端到端的方式学习。
基于神经网络的方法主要有节点聚类和节点采样两种类型。对图中节点聚类实现图池化的代表工作有分层可微分图池化(Differentiable Pooling, DIFFPool)[8],它构造了一个可微池化层,根据图中节点的特征将其软分配给固定数量的类,由于要计算软聚类分配,因此计算复杂度较高。节点采样方法主要是依据节点的重要性保留一定数量的节点,构造一个新的粗化图。Zhang等[9]直接对每个节点的表示向量排序,将较大的节点表示向量保留生成池化图;Cangea等[10]和Gao等[11]利用可训练的投影向量对图中节点进行采样。首先将节点表示向量在投影向量上的投影得分作为节点的重要性得分,然后根据所设置的池化率k将得分较低的节点丢弃实现图池化。Lee等[12]提出自注意力图池化(Self-Attention Graph Pooling, SAGPool)方法,利用图卷积神经网络(Graph Convolutional Neural Networks, GCNConv)[13]自适应地计算注意力得分,并将其作为节点的重要性得分指导节点采样。
本文采取基于节点采样的图池化方法,虽然这方面的工作已取得了一定的成果,但它们仍存一些问题,有待进一步解决。现有的基于节点采样进行图池化的方法,对于没有被采样的节点采取直接丢弃的原则,然而被丢弃的节点也带有一定有效的信息,因此不可避免造成图信息的丢失。另外,学习节点重要性得分时并没有考虑每个节点与其邻居节点间的相关度,从而导致节点重要性得分的学习不全面。在丢弃重要性较低的节点时节点的边也被丢弃,图中容易形成孤立点,影响整个图结构的连通性。
针对上述问题,本文做了以下工作:(1)提出信息保留模块,在丢弃节点前,对节点中有利于图分类的信息先进行聚合保留,从而保留丢弃节点中的有效信息。(2)采用多头注意力机制学习节点重要性得分,通过中心节点与其邻居节点间的相关度聚合邻域信息,从而更充分地学到节点的重要性得分。(3)在节点采样之后应用保持图连通性模块,将孤立点与其邻居节点相连,保证图结构的连通性。
1 结合信息保留的多头注意力图池化模型
1.1 特征提取
本文提出的结合信息保留的多头注意力图池化模型(Multi-head attention graph pooling model with information retention, MHAPool)完整结构如图1所示,对于输入的图,在提取初始特征阶段利用经典且被广泛使用的GCNConv[13]来提取初始特征,公式如下:
(1)

1.2 节点信息保留
通常,池化层只将被采样节点的信息保留,用作新图的特征。然而,被丢弃的节点也带有一定的有效信息,若直接丢弃节点则会造成图信息的损失。因此,本文设计节点信息保留模块,将丢弃节点中的有效信息保留下来。

图1 结合信息保留的多头注意图池化模型
在学到的节点表示向量中,最大的节点表示向量带有的特征往往最具判别性与代表性,更有利于图分类,因此我们将图中每个节点i依次作为中心节点,取其一阶邻居作为它的邻域N(i),在邻域N(i)中找出初始特征提取阶段得到的最大的节点表示向量mi,公式如下:
(2)
然后,计算邻域N(i)中每个节点与mi的余弦相似度:
χi,j=cos(mi,hj)。
(3)
式(3)中χi,j代表N(i)中每个节点的表示向量与最大的节点表示向量之间的相似度,相似度越高代表这个节点包含更多有利于图分类的信息,因此我们将得到的相似度作为权重与每一个节点表示向量相乘求和:
(4)
1.3 多头注意力机制学习节点重要性得分
本文采用多头注意力机制[14]学习节点重要性得分,如图2所示,每一头有三支输入,首先将节点i与一阶邻域中的节点j进行线性变换,公式如下:
qc,i=Wc,qhi+bc,q,kc,j=Wc,khj+bc,k。
(5)
式(5)中qc,i和kc,j分别为线性变换后中心节点i的表示向量与其邻域中节点j的表示向量,Wc,q,Wc,k,bc,q,bc,k表示可学习的权重和偏置,c表示注意力机制的头数。
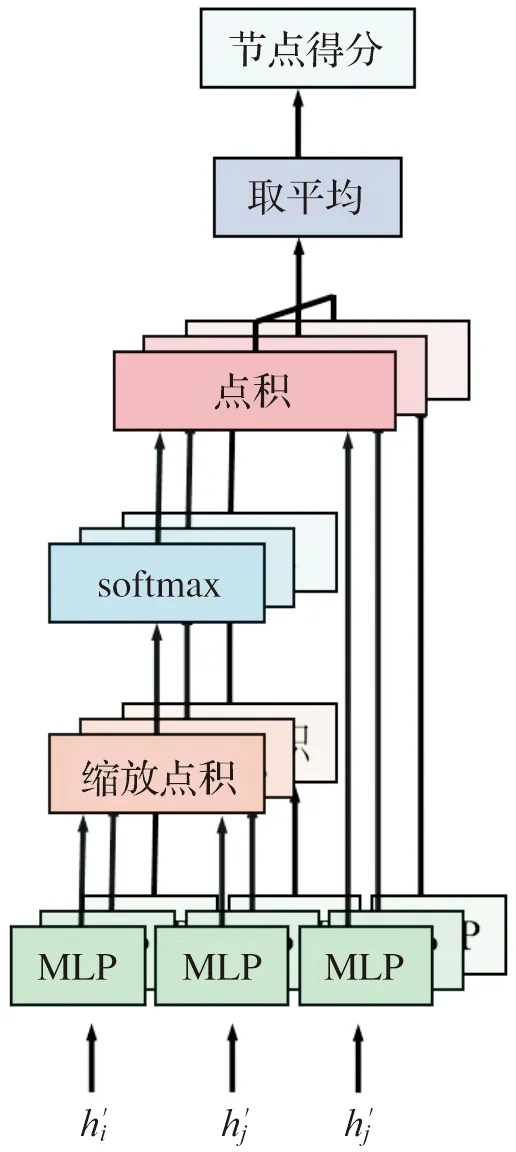
图2 以3头为例的多头注意力学习节点重要性得分示意图
得到qc,i和kc,j之后,使用缩放点积计算中心节点i与其邻域中节点j的多头注意力系数,公式如下:
(6)
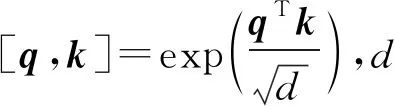
得到每个节点与相邻节点的多头注意力系数后,我们对邻域中的节点再进行一次线性变换如下:
vc,j=Wc,vhj+bc,v。
(7)
式(7)中vc,j为线性变换后节点j的表示向量,Wc,v,bc,v表示可学习的权重和偏置。
我们将变换后的邻居节点表示vc,j与多头注意力系数相乘之后取平均得到每个节点的重要性得分,公式如下:
(8)
式(8)中Z={z1,z2,…,zn}∈Rn×1,其中zi为节点i的重要性得分,C表示实际所取的注意力机制的头数。
1.4 节点采样及保持连通
在学到节点重要性得分之后,设定池化率k并结合节点的重要性得分来生成索引,
idx=top-k(Z,|kN|)。
(9)
式(9)中|·|表示向下取整,N表示输入图的节点数,top-k表示生成向量Z中前|kN|个值的索引,idx表示生成的索引。
随后,根据生成的索引对图中节点进行采样,实现图池化。如图1所示,在节点采样时直接丢弃节点,与节点相连的边也随之被丢弃,导致部分节点成为没有边连接的孤立点,影响整个图的连通性。受Ying等[8]的启发,为保持图的连通性,本文采用如下方式进行采样:
M=A(:,idx),A′=MTAM,H′=H(idx,:)。
(10)
式(10)中H(idx,:)表示对图的特征矩阵H执行行提取,形成池化图的特征矩阵,对于图的邻接矩阵A,首先对其列提取得到M,然后通过MTAM得到池化图的邻接矩阵A′,此操作可以使得孤立点与邻居节点相连,进而保证整个图的连通性。
1.5 模型架构
本文构建分层图池化模型实现图分类。图3是一个以三层为例的图池化模型架构图,每一层可分为3个部分:特征提取、图池化和读出操作。首先,通过GCNConv对输入图进行特征提取;随后,对节点作信息保留,同时利用多头注意力机制学习节点重要性得分,并据此实现节点采样;之后再将孤立点与邻居节点相连保持图的连通性;接着,在读出操作中对采样后的图表示取平均和最大,并进行拼接;最后,将各层读出操作的输出相加,传至图分类器,完成图分类任务。
1.6 与已有方法的比较
已有的图池化方法中最具代表性的有DIFFPool[8]和SAGPool[12],其中DIFFPool[8]学习节点分配矩阵,将原图中的每个节点以指定的概率分配给新图中的不同类,重复多次将图中节点聚合为一个超级节点,这是一种通过聚合节点实现图池化的方法。本文提出的MHAPool学习节点重要性得分,是一种依据节点重要性得分丢弃节点实现图池化的方法。SAGPool[12]同为学习节点重要性得分,进而丢弃节点实现图池化的方法,但其学习节点得分时只是通过一层GCNConv[13]。而本文提出的MHAPool采用多头注意力机制学习节点重要性得分,通过中心节点与其邻居节点间的相关度聚合邻域信息,更充分地学到节点的重要性得分,并且设置信息保留模块,从而保留被丢弃节点中的有效信息。
2 实 验
本章介绍了数据集、对比方法和实验设置,展示了本文提出的MHAPool对比实验和消融实验的结果,并对模型中的关键参数进行了讨论。
2.1 数据集
本文在4个生物信息数据集(DD[15], PROTEINS[16],NCI1[17]和NCI109[17])和3个社交网络数据集(IMDB-BINARY[18],IMDB-MULTI[18]和COLLAB[19])上评估所提出模型的性能,具体介绍如下:DD[15]和PROTEINS[16]中的每个图皆表示某种蛋白质结构,其标签是每个图所表示的蛋白质是否为酶。NCI1[17]是美国国家癌症研究所(National Cancer Institute, NCI)发布的用于癌细胞活性分类的生物信息数据集,其标签为细胞是否可以抑制癌细胞的生长。NCI109[17]中每个图表示卵巢癌细胞的化学结构,图分类对应于卵巢癌细胞的活性筛选。IMDB-BINARY[18]是电影演员合作数据集,由出演动作电影和浪漫电影的演员组成。IMDB-MULTI[18]和IMDB-BINARY类似,它由出演喜剧电影、浪漫电影和科幻电影3种类别电影演员组成,图分类是对出演不同类别电影的演员的进行分类。COLLAB[19]是来自高能物理、凝聚态物理和天体物理这3个领域的科学家社交网络数据集,图分类是将每位科学家所属的领域分类。
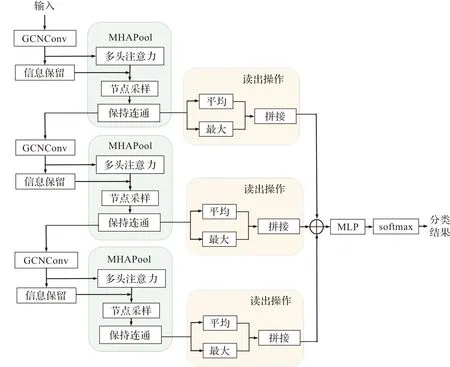
图3 图池化模型架构
2.2 对比方法
本文所提出的方法与以下两种类别的图分类方法比较。
基于核的方法:威斯费勒-莱曼核(Weisfeiler-Lehman Kernels, WL)[7],最短路径核(Shortest-path Kernels, SP)[20],图核(Graphlet Kernels, GK)[21],深度图核(Deep Graph Kernels, DGK)[22],和匿名游走嵌入(Anonymous Walk Embeddings, AWE)[23]。
基于图神经网络的方法:DIFFPool[8],gPool[11],SAGPool[12],EigenPool[24],基于信息的图池化(Information-Based Pooling, iPool)[25],结构学习分层图池化(Hierarchical graph pooling with structure learning, SLPool)[26],基于ARMA滤波的图神经网络(ARMA)[27],用于图学习的瓦瑟斯坦嵌入(Wasserstein Embedding for Graph Learning, WEGL)[28],图多集池化(Graph Multiset Pooling, GMT)[29],和空间卷积神经网络(Spatial Convolutional Neural Networks, SCNN)[30]。
2.3 实验设置
实验中将每个数据集随机分成3部分:80%作为训练集,10%作为验证集,其余10%作为测试集,将数据集随机拆分过程重复10次,取10次实验精度的平均值和标准差作为结果。本文使用作者提供的源码得到对比方法的结果,同时为了公平比较,对本文所提出的方法和已有的方法使用相同的模型架构,并将节点表示维度都设为128。本文在PyTorch框架下实现了MHAPool,并使用Adam优化器[31]对模型进行优化。MLP由3个全连接层组成,每层的神经元数量依次设为256、128、64,最后接上softmax分类器,完成图分类。在训练过程中采用了提前停止准则,即若验证损失在连续50个时期内没有减少,将提前停止训练。
2.4 对比实验结果
本文在图分类精度方面将所提出的MHAPool与其他模型进行比较,结果如表1和表2所示,最佳模型以粗体突出显示,次优模型以下划线显示。
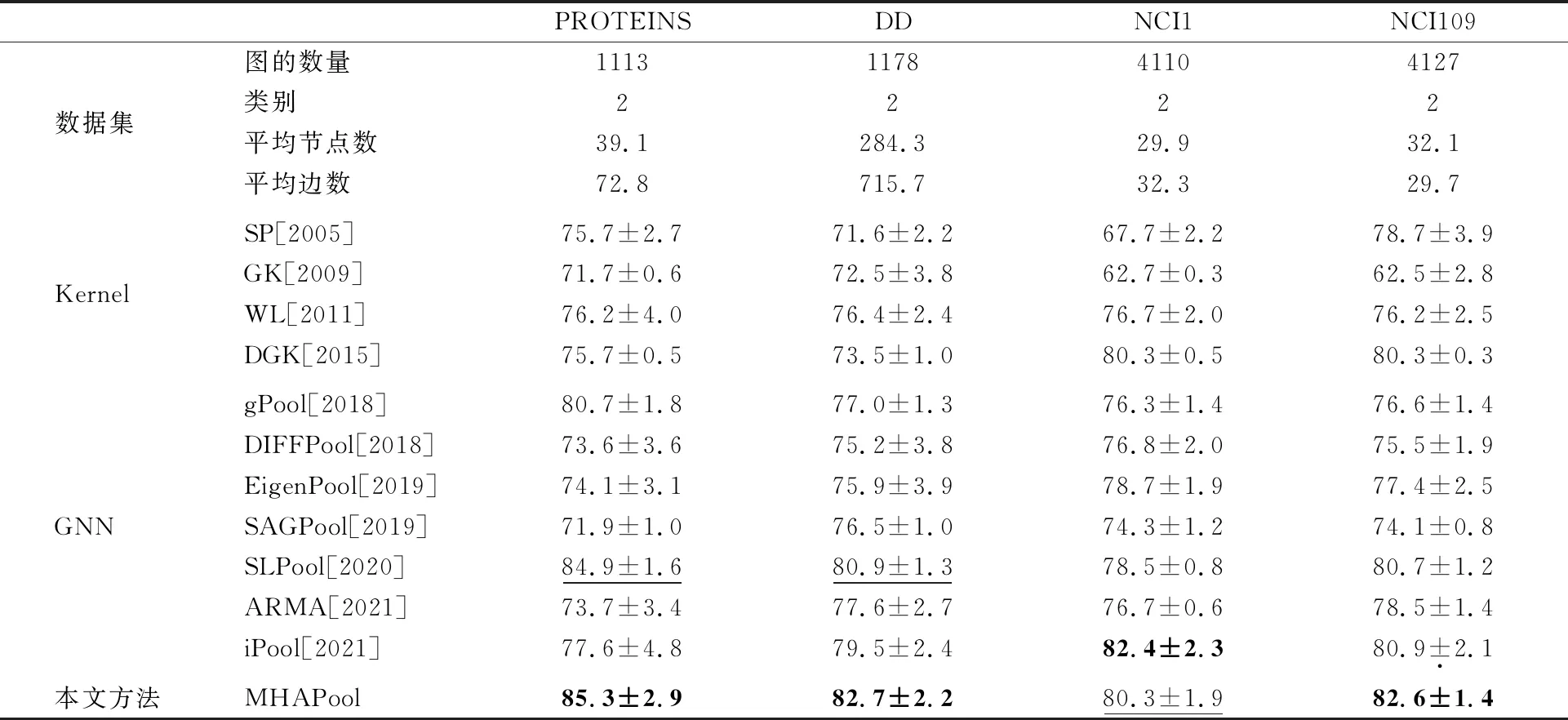
表1 4个生物信息数据集的统计信息以及MHAPool与对比方法在图分类实验上的比较结果

表2 3个社交网络数据集的统计信息以及MHAPool与对比方法在图分类实验上的比较结果
表1总结整理了4个生物信息学数据集PROTEINS、DD、NCI1和NCI109的统计信息以及与对比方法的比较结果,表2归纳整理了3个社交网络数据集IMDB-MULTI、IMDB-BINARY和COLLAB的统计信息以及与其他图分类模型的比较结果。从实验结果可以看出,MHAPool在PROTEINS,DD和NCI109这3个生物信息学数据集取得了最好的结果。特别是单个图上节点数较多的数据集DD,本模型的图分类精度达到最高,这说明了MHAPool具有较好的处理复杂数据的能力。在3个社交网络数据集中,本模型在IMDB-MULTI,IMDB-BINARY这两个数据集上比现有的最优结果分别高出3.0%和1.4%。
2.5 消融实验
对节点重要性得分学习方式的分析。对已有的使用GCNConv学习节点重要性得分与本文提出的多头注意力机制(Multi-head Attentation,MHA)学习节点重要性得分在7个数据集上进行图分类实验,实验结果见表3,从实验结果可以看出使用MHA的模型图分类实验的精度更高,结果表明多头注意机制相比GCNConv学习到的节点重要性得分更全面,准确。
对信息保留模块的分析。为了说明信息保留模块(Information Retention, IR)的作用,在图分类数据集上对是否设置信息保留模块的模型进行实验。实验结果见表3,结果表明信息保留模块保留了图中节点的有效信息,解决了直接丢弃节点造成有效信息的丢失。
对图连通性保持的分析。为了说明图连通性保持模块(Maintain Graph Connectivity, MGC)的作用,分别训练了是否带有图连通性保持模块的模型。实验结果见表3,结果表明在节点采样之后加上图连通性保持模块,可以将由于节点采样形成的孤立点与其邻居节点相连保证图结构的连通性,使得图分类实验效果更好。

表3 MHAPool在图分类数据集上的消融实验结果
2.6 超参数分析
本节进一步探究了关键超参数取不同值时对实验效果的影响,分别为:图池化模型的网络层数L和学习节点重要性得分时多头注意力机制的头数c。在社交网络和生物信息两个领域中取大小各异的3个数据集COLLAB,NCI109和IMDB-BINARY作为代表,在这3个数据集上研究两个超参数L和c取不同值时对图分类性能的影响,这3个数据集的实验结果见图4。
IMDB-BINARY,NCI109和COLLAB这3个数据集中平均每个图的节点数分别为13,32.1和74.5。在实验中设置网络层数L=1,2,3,4,5,在IMDB-BINARY数据集上,当L取1时达到最好的实验精度,而对于NCI109和COLLAB,L分别取2和4时达到最好的图分类实验效果,这表明对于较小的数据集,浅层的网络就可以学习到图表示,并达到较好的效果。在较大的数据集上需要加深网络层数才能充分学习图表示。对于较小的数据集随着网络层数的加深,实验效果变差,这主要是因为每一层中都有GCNConv模块,叠加多层GCNConv造成过平滑问题。
对于多头注意力机制的头数c,从实验结果上来看,节点较少的数据集IMDB-BINARY,c取2时实验精度达到最大值,对于NCI109和COLLAB,c分别取3和4时达到最好的图分类结果。多头注意力机制用于计算节点的重要性得分,在节点数较少的数据集上,头数c取较小值即可学得较好的节点重要性得分,而对于节点数较多的数据集COLLAB,需要更多的头数才能全面地学习节点重要性得分达到最优的结果。
3 结 语
本文提出一种结合信息保留的多头注意力图池化方法,具有较好的图分类性能。首先,通过信息保留模块,在丢弃节点时保留图中有效信息,解决因直接丢弃未被采样的节点,造成图信息损失的问题。其次,本文采用多头注意力机制,考虑每个节点与其邻居节点间的相关度,有效聚合邻域信息,从而更充分地学习各节点的重要性得分。在节点采样之后,设置图连通性保持模块,将孤立点与其邻居节点相连,保证整个图结构的连通性。最后,在多个数据集上的图分类实验结果验证了所提出方法的先进性。
在未来的工作中,我们将考虑开发图特征提取的方法,改善多层GCNConv易造成的过平滑问题。
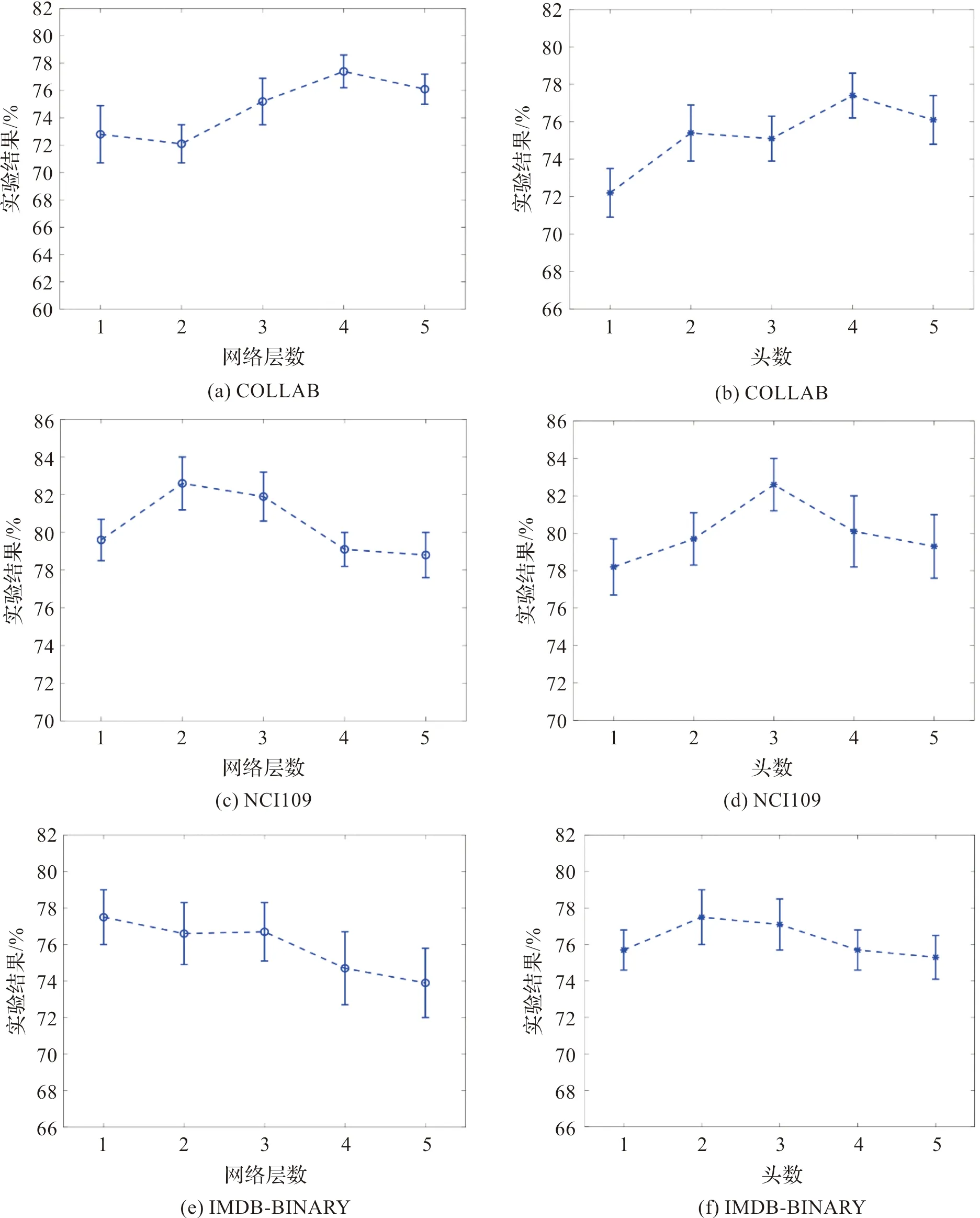
图4 超参数分析
