专利主题词的FW-LDA组合改进与关键词演化分析*
2022-07-18刘晋霞张志宇
刘晋霞 张志宇 王 芳
(太原科技大学经济与管理学院 太原 030024)
0 引 言
随着科学技术的不断发展创新,使得专利文献数量不断增加,产生了庞大的信息数据,对科研与技术人员把握技术发展前沿产生了很大困难。为及时掌握技术发展、辅助技术决策、提高科研效率,许多学者对相关领域展开了技术主题的挖掘与主题词的提取,其中以LDA概率主题模型的方法发展迅速,它能够通过概率统计定量分析和识别研究主题,得到文档所属主题与每个主题下对应的主题词。该模型被证实能够取得很好的主题建模效果,目前应用较为广泛,但其自身不能确定主题数会导致存在主题划分模糊,以及没有考虑文档中词语出现的顺序关系会缺乏上下文逻辑信息。
因此,本文提出一种基于FW(Filter words)-LDA组合改进方法,通过LDA模型提取每个主题及对应的主题词后,对主题词进行过滤(FW),以解决LDA模型主题划分模糊以及缺乏上下文逻辑关系的问题。并且将该组合改进方法应用于我国制氢技术专利数据集的演化分析,以把握技术发展规律。
1 相关研究工作概述
概率主题模型最早起源于潜在语义分析LSA(Latent Semantic Analysis)[1],之后发展为概率潜在语义分析PLSA(Probabilistic Latent Semantic Analysis)[2]以及在PLSA的基础上加入了贝叶斯先验分布的潜在狄利克雷分布LDA(Latent Dirichlet Allocation)[3],关于LDA概率主题模型改进的研究成果已有很多,主要可以分为三类:
第一类是对LDA模型本身的改进。这类方法主要是在LDA模型内部,通过调节分布或权重,更加准确地识别主题。如Blei等[4]提出的DTM模型是将文档按小时间尺度顺序分箱,对每个分箱内的LDA模型之间的全局变量通过指数分布进行连接,通过引入时间动态的概念,来更好地建模主题;BTM算法[5]结合层级Dirchlet语言模型和LDA,通过Biterm来建模,将词的顺序作为影响主题确定的因素;加权主题模型[6]对不同词进行权重的分配,解决LDA模型的分析结果向高频词倾斜而淹没能够代表主题的多数词问题。但是这类方法会因没有与外部信息相结合而缺乏主题语境信息,或通过调节权重来改变生成词概率时需要大量数据集进行验证及优化。第二类是LDA模型与其他外部结构或信息相结合的改进。如杨超等[7]基于SAO结构[8]的LDA主题模型方法,改善专利技术主题辨识度低等问题;廖列法等[9]在LDA算法上,通过引入IPC分类号来度量技术主题强度,实现了对主题强度、内容和技术主题强度三方面的演化研究;李昌等[10]引入IPC分类号作为语境信息,实现对专利主题更加明确的分类。但是这类方法会因只提取了部分文本词,而出现上下文逻辑缺失的问题,或只考虑加入语境,而对主题下的词语仍使用概率分布获得,缺乏上下文逻辑关系。第三类是LDA模型与其他模型的结合改进。如Zaheer M[11]等人将LDA模型中文档主题的Dirchlet(狄利克雷)分布改为LSTM的内容,以对序列文本进行建模;Xie X等[12]提出了一种基于RNN的聚类方案来学习标准LDA聚类标签随时间的自然相关性,解决了LDA模型在聚类中忽略相邻聚类之间转移和相关性的问题;庄穆妮等[13]将LDA主题模型与BERT词向量深度融合,来优化主题向量与文本主题聚类效果。这类方法能有效地进行文本词的训练并助力主题的划分聚类,提高主题识别的准确性。
综上所述,目前针对主题建模以及主题关键词的提取,主要利用LDA概率主题模型。大量学者针对其存在主题划分模糊、未考虑上下文逻辑关系的问题进行了多种方法的改进,但与其他模型结合,从过滤筛选主题词角度进行问题改进的相关工作较少。因此,本文以过滤处理主题词的角度,提出一种FW-LDA组合改进方法,对LDA模型输出做进一步的主题标识、训练词向量和建立相似度处理,使过滤出的主题关键词能够获得更好的主题划分泛化能力和主题聚类的效果。
2 方法构建
FW-LDA方法流程如下:①数据收集与预处理:在专利数据检索系统中,收集一段时间内的专利文献,选取出专利分类号和语料库,并对语料库预处理得到模型输入文本。②LDA概率主题识别:将模型输入文本作为LDA模型的输入,输出每项文档所属主题以及主题词。③定义主题标识词:通过对专利分类号的选取与定义解释、语料库以及LDA输出信息,定义LDA中输出的每个主题标识,得到主题标识词。④负采样模型过滤主题词:将模型输入文本和定义的主题标识词作为负采样模型的输入,过滤LDA模型中输出的主题词,得到主题关键词结果。如图1所示。
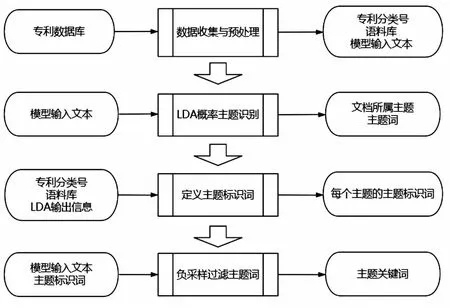
图1 FW-LDA方法流程
2.1 数据收集与预处理模块
本模块分为两个步骤:
第1步,文本数据选取。首先在专利平台中对专利类型进行选取,其次对选取的每项专利进行数据项的选取与文本项的选取,其中专利分类号作为数据项的选取结果;建立语料库作为文本项的选取结果。
第2步,文本预处理。对文本项中建立的语料库,进行中文停用词表的清洗,并对清洗后的文本建立自定义词典和分词,得到可用于LDA模型和负采样模型的输入文本。
2.2 LDA概率主题识别模块
LDA算法是一种无监督的机器学习技术,通过一个贝叶斯链式关系,公式为(1),概率生成文档主题的模型[3]。
(1)
将语料库中的所有词语进行分主题聚类,实现全自动地从数据集中抽取出每项文档所属主题wj|zk,以及文档中的每个词语所属主题zk|di,即主题词。
但是LDA模型存在一定的不足:第一,LDA方法本身不能生成最优主题数[14],而是要依靠Blei[3]提出使用困惑度的方法来设定,以困惑度最小值或拐点处对应的主题数作为模型的最优主题数,当设定的困惑度较高时,往往会导致主题划分不准确,泛化能力弱。第二,LDA能通过频率计算出词语所对应主题,但LDA模型是一个词袋模型,在词袋中一篇文档是由一组词构成的集合,词与词之间没有顺序,未能将词与词之间的关系纳入计算[15]。因此本文针对这两个不足,在专利语料库进行LDA概率主题识别的基础上,通过定义主题标识词、负采样模型过滤主题词的组合来改进LDA模型识别结果。
2.3 定义主题标识词模块
LDA模型对专利文本进行主题分类时,输出中没有每个分类主题的标识,但每个主题下的词语是由聚类产生,都有其隐含的标识词,因此通过寻找每个主题的含义定义主题标识词。数据库中的每项专利都有按照技术分配的专利分类号,其中的每个专利分类号都有特定的含义。专利分类号来源于国际专利分类系统体系,它是我国进行专利分类的常用体系,按照不同技术主题把整个技术领域分为5个不同层级:部、大类、小类、大组、小组[16],部是对技术领域最大的划分层级,其余层级是更细致的逐级划分,分类越细致则专利之间差异性越小[9]。因此,本文通过LDA模型输出信息和国际专利分类系统信息相结合,定义每个主题的标识词,过程如下:
第1步,提取每个主题信息。
在通过LDA模型对专利文本进行建模后,依据所输出的每项文档所属主题,提取每个主题对应的语料库以及专利分类号。
第2步,选择专利分类号。
由于使用最小困惑度来确定分类的最优主题数和使用国际专利分类系统的分类存在差距,因此在LDA模型输出每个主题所对应的文档中会有多个专利分类号,这使得对主题标识词的定义产生一定困难。选择合适的专利分类号可以减少定义的复杂度并且提高主题划分的准确度,本文建立两个指标选取专利号。第一,选择的专利分类号在某一主题下文档数的占比大于其他主题中文档数的占比,该指标能够对某一主题与其他主题进行区分,体现每个主题的特点,公式为(2)。
(2)
第二,选择的专利分类号在某一主题下所占的文档数最多,该指标能够体现某一专利分类号在该主题的重要程度,公式为(3)。
(3)
其中,Q代表专利号,Q=q代表第q个专利号,N代表主题,N=n代表第n个主题,MIPC为专利分类号数量,Mtext为专利文本数量。
第3步,结合语料库与LDA输出信息
通过选择出每个主题的专利分类号,以国际专利分类系统中对专利分类号的定义为基础,结合专利语料库信息与LDA输出的主题词,最终选择适合每个主题的词语作为主题标识词。
定义主题标识词是组合改进方法的基础和关键步骤。它既是对LDA模型中输出每个主题的概括,也是负采样过滤主题词模块时的输入文本,要使得经过过滤后得到的主题关键词,包含大部分属于LDA中原本输出的主题词,并且能够使主题划分更加清晰。与单独依据LDA模型中输出的主题词,主观定义主题标识词的方法相比,本文在此基础上,通过结合提取的专利语料库信息、LDA输出信息与国际专利分类系统对专利分类号的定义多方面考虑来定义,使效果更加准确。
2.4 负采样过滤主题词模块
负采样模型[17]是对Skip-Gram模型的改进,Skip-Gram模型是在Word2Vec[18]工具中,用来训练出低维词向量的模型[19]。但Skip-Gram模型在更新时,每次都要训练词典中的所有分词,概率也做相应调整。而在实际运行过程中,通过Softmax[20]运算得到概率值基本为零,全部更新就会消耗计算资源。因此,引进负采样模型,其本质是每次只选择正样本以及部分负样本进行训练与更新,减少Softmax的计算量,以更加迅速有效地得到词向量。
LDA主题识别模型不考虑上下文逻辑关系,负采样模型的一大特点正是对词语之间的关系进行描述,更加注重上下文逻辑[15]。利用负采样训练词向量并建立向量间的相似度量,以定义的主题标识词作为查词对象,计算并输出其相似词及相似系数,来筛选过滤LDA模型输出中的主题词。
3 实证研究
3.1 数据收集与预处理
3.1.1文本数据选取
本文研究对象为我国制氢技术领域的专利文献,检索平台选择“专利之星检索系统”,使用表格检索,检索式为“TX=制氢&制备氢”(TX表示关键词)、“AD=20010101>20191231”(AD表示申请日、20010101>20191231表示时间跨度为2001—2019年),共检索得到9 243篇专利文献。其中专利类型为发明的专利6753篇、实用新型专利2 403篇、外观设计专利87篇。由于发明专利具备突出的实质性特点、显著性进步、新颖性和创造性水平更高、保护年限长、保护产品方法与技术的优点,因此选择发明专利为研究对象。发明专利中的法律状态包括有效、审中和失效专利,其中有效专利2 372篇、失效专利3 150篇(失效但有过授权的专利为694篇)。由于专利会随着时间失效,但曾有专利的授权就说明该技术曾为有效专利,创新研究被认可,故选取法律状态为有效和已失效但曾有授权时间的专利。
根据以上选取条件,共检索得到3 066篇专利文献。将其导出后对专利权人、发明人名称规范与消歧[21]以及对重复文本剔除,经过筛选,共有2 665条专利记录。每项记录中包括发明人、标题、分类号、摘要、法律状态、专利类型等20项内容。由于专利的标题和摘要最能体现所用技术、方法和效果[22],所以选取标题和摘要作为文本项的语料库,并且在定义主题标识词时,要利用专利分类号,故选取专利分类号作为数据项。
3.1.2文本预处理
对语料库进行信息整合后进行预处理工作,得到模型输入文本。
a.以标点符号和在每项专利摘要中出现的“本发明”“一项”“公开”等不影响上下文逻辑关系、高频无用的词语建立停用词表。
b.以文献关键词和搜狗词库中下载相关的专利词语词库来建立自定义词典。
c.使用中文分词组件Jieba(可由https://github.com/fxsjy/jieba下载)和人工分词相结合的方法对语料库进行分词,提高分词准确性。
3.2 LDA概率主题识别
使用Python3作为开发平台,选用Scikit-Learn中的LDA主题模型,其主要基于变分推断EM算法进行参数估计[23]。
首先,通过计算困惑度来确定最优主题数,图2为1~50个主题时分别对应的困惑度值,最终选取困惑度最低点对应的Number of Topic作为模型的最优主题数,故设置K=17进行建模,参数α和β使用默认值。其次在理论上,困惑度越小,泛化能力越强,但其学习效果与迭代次数密切相关,随着迭代次数增加,收敛速度无明显变化[14],因此将文档迭代次数设置为1000次。

图2 1-50主题下的困惑度值
通过LDA对语料库的训练,输出每个文本对应的最大概率主题和每个主题下按照概率大小排列的词语。对于一个主题下的词语,与该主题的距离越大,概率越小,聚类程度降低,因此设置每个主题下的概率前100的词语(n_top_words=100),并将其作为负采样模型进行过滤的对象。
3.3 定义主题标识词
通过两个指标选取每个主题专利分类号。在专利之星检索系统中,提取出的专利分类号层级为小组层级,可以将其分解为任何需要的层级。根据国际专利分类表,不同的分类层级会对标识词的设定产生不同的效果[24],故提取10%数量的文本,对它们所对应的大类、小类和小组专利分类号进行效果对比分析,结果发现,基于大类进行设定时,会使标识词过于粗泛,使得不同的主题有相同的标识词,主题间相似度偏大;而基于大组或小组的主题词会使得每个主题下的分类过多,找不准聚类词语。因此,实验以小类层级为标准来辅助定义主题的标识词,使主题划分更加明确。经过信息的结合,定义出每个主题的主题标识词如表1。

表1 主题标识词
3.4 负采样模型过滤主题词
实验使用Python3作为开发平台,选用Gensim工具包中的负采样模型训练词向量。通过实验,输出不重复的词语数量共有17 704个。
3.4.1参数设定
本实验将维度参数设置为50,负样本的个数设置为5,滑动窗口大小设置为4。其中,在维度参数设置时,通过学者的大量实验得出,降维至50~300维的范围为最佳,在此范围内,若设置为50维,计算速度相对快,若设置为300维,计算相对更加准确。本实验随机抽取10%的文本,分别将维度参数设置为50、100、200、300,通过查词的效果比较发现,维度为50维时,计算速度快,并且与100维、200维和300维时的相似词基本相同,因此,本实验设置维度参数Feature_Number=50,并且通过训练出的低维词向量,建立词语之间的相似度量。
3.4.2主题关键词的过滤
以主题标识词为查词对象,设定Vocabulary_Similar(“标识词”,100),以此计算出与主题标识词相似系数高的前100的词,依据这些词对3.2中设置的每个主题下前100个主题词,通过选择两者的前20个相同词的方法过滤出主题关键词。由于LDA模型输出的主题词是根据词频,而负采样模型是根据上下文逻辑关系,所以两者出现相同词的顺序不同,因此有两种标准,第一种是以LDA中主题词为准,选取LDA中与负采样模型中输出的前20位相同词,第二种是以负采样模型中输出词为准,选取其与LDA主题中词的前20位相同词,作为选词结果,由于考虑到第二种选词方式会导致聚类程度过大,在关键词演化过程中出现相同意义词演化的情况,因此选择使用第一种选词方式。
4 效果对比验证
本文将相同主题数下,FW-LDA方法、LDA模型与TF-IDF算法、BTM模型所输出的主题相互对应。通过对主题词展示以及逐点互信息、Pearson(皮尔逊)相关系数的方法,从主题词和混淆效果、聚类效果三个方面,对比验证FW-LDA方法的有效性与准确性。
4.1 主题词对比验证
主题词对比验证的对象,是四种模型输出的每个主题前20个关键词。由于TF-IDF算法、BTM模型与LDA模型中的主题词差距较小,因此本文仅以LDA模型和FW-LDA方法为例,如表2中的Topic3和表3中的Topic13。可以发现,在经过FW-LDA方法后,可以过滤掉LDA模型中主题辨别能力差以及与该主题相关性小的关键词。

表2 Topic3效果对比

表3 Topic13效果对比
4.2 混淆效果验证
混淆效果体现在主题之间,逐点互信息PMI(Pointwise Mutual Information)指标是可以作为衡量主题相关性的评估指标,为避免计算中出现-∞,通常计算PPMI(Positive PMI),其公式为(4)。本文通过该指标,度量四种模型中某一主题与其他主题之间的相似程度。
(4)
其中,tk,tj分别表示第k个主题和第j个主题,Xtk,Xtj表示两个不同主题之间相同词的个数。
为清晰地比较结果,本文将计算每个主题的AN-PPMI值,其公式为(5)。三个模型的AN-PPMI值比较结果如图3所示。

图3 AN-PPMI值比较结果
(5)
其中,n表示主题总数量,N-PPMI值表示对每一主题的PPMI值进行归一化,得到该主题与其他各个主题之间的相关系数。
由图3可知,在大多数的主题下,FW-LDA方法中的AN-PPMI数值低于其他三种模型,说明主题之间的混淆程度降低,主题划分更加明确。
4.3 聚类效果验证
聚类效果体现在主题内部的关键词中,本文根据负采样模型训练出的词向量,运用Pearson(皮尔逊)相关系数的方法,计算主题内部关键词之间的相关系数,其公式如(13),通过比较四种模型中的Pearson最小相关系数以及平均相关系数,来验证主题内部聚类效果。因篇幅有限,无一一罗列两种模型的Pearson相关系数,这里仅以四种模型相互对应主题后的Topic0至Topic3为例进行对比。结果为表4,min和avg分别表示主题内关键词之间的Pearson最小相关系数和平均相关系数。
(6)
其中,X、Y表示两个词向量。
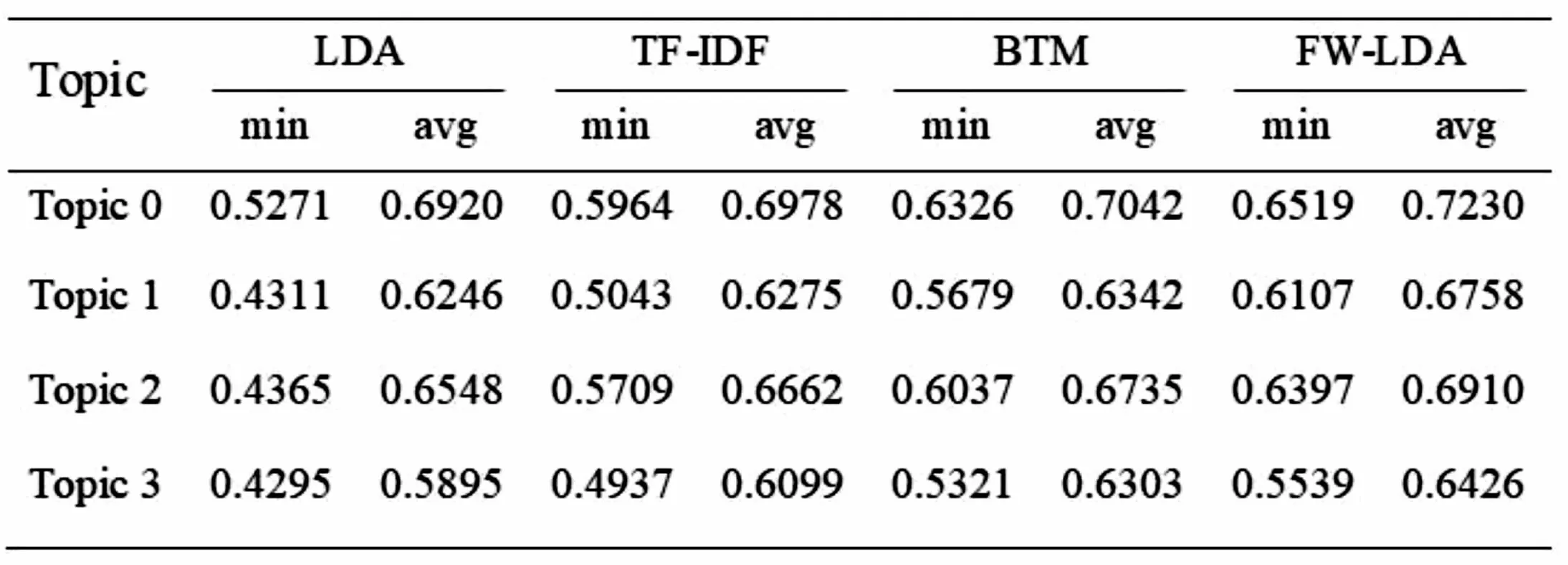
表4 四种模型的Pearson系数
由Pearson相关系数的比较可知,FW-LDA中主题内关键词之间的相关系数大,方法的改进产生聚类效果。
综上所述,通过对输出主题词、主题间混淆关系以及主题关键词内部聚类效果的对比验证可以得出,相比LDA模型、TF-IDF算法和BTM模型,FW-LDA方法能够使主题之间混淆度降低、划分更加准确,主题内部的关键词相关性增强、结果更加聚类。
5 演化分析
通过对不同主题关键词的演化分析,可以及时把握技术发展动态,挖掘技术创新规律。本文对2001—2019年的专利文本进行演化分析,在时间切片后,利用FW-LDA的方法选取每个时间切片最优主题数下的主题关键词;将这些词进行去重,并通过负采样模型建立的相似度量,设置关键词之间的相似度阈值,确定有演化关系的词语作为演化关键词结果。其流程如图4所示。
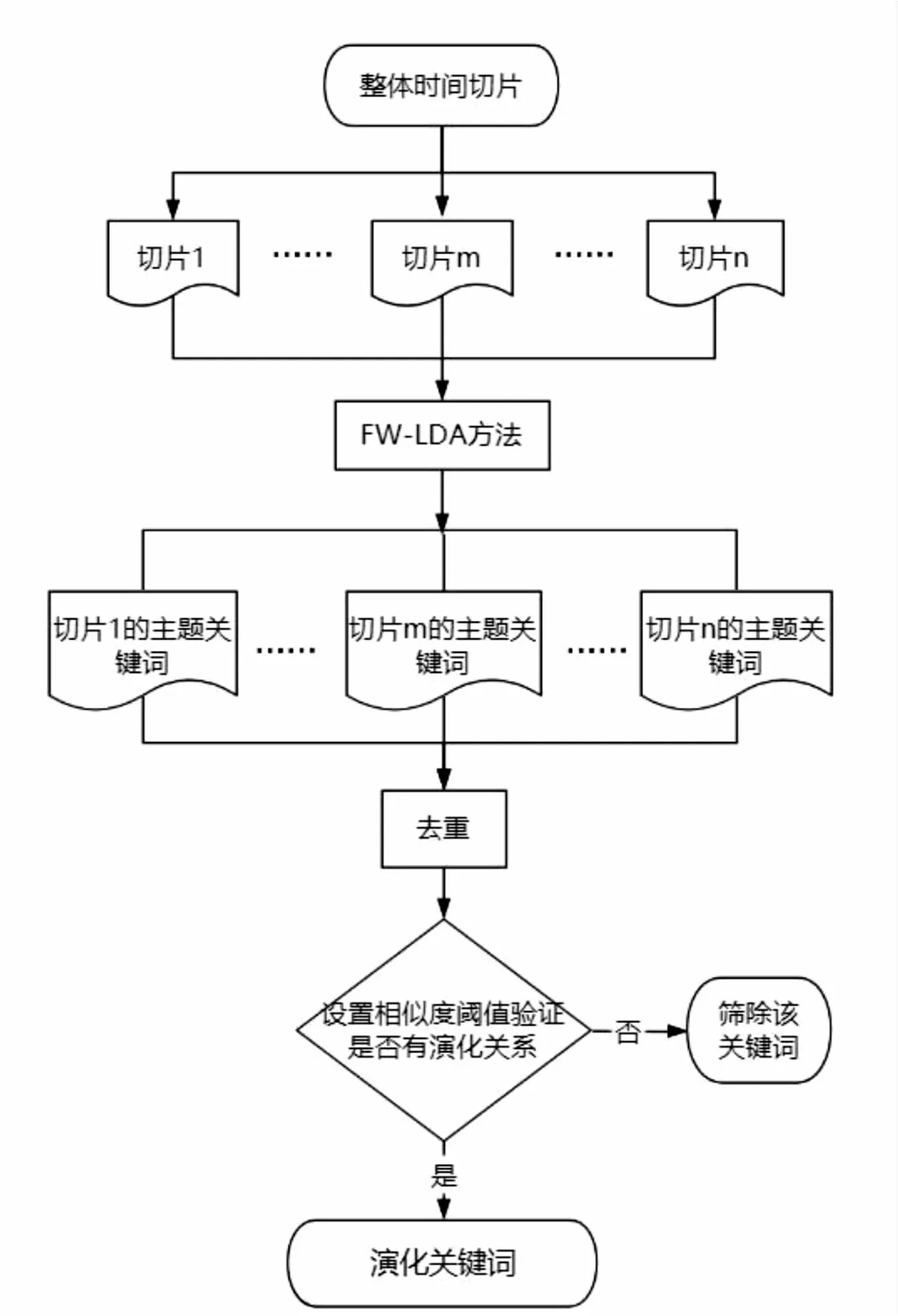
图4 演化流程
5.1 时间切片
本文将2001—2019年分为5个时间切片,由于前7年专利数目较少,因此将其作为一个时间切片,其他以3年为单位进行时间切片。最终切片结果为2001—2007年、2008—2010年、2011—2013年、2014—2016年和2017—2019年。
5.2 主题关键词选取
对每个时间切片下的语料库进行困惑度计算,选择困惑度最小所对应的主题数作为该时间切片下的最优主题数Kt,5个时间切片的最优主题数分别为K2001—2007=11,K2008-2010=3,K2011-2013=12,K2014-2016=18,K2017-2019=7。
利用FW-LDA方法进行演化前的主题关键词选取。对每个时间切片下所有主题,先计算输出LDA模型中词频位于前100的词语,再应用国际专利分类系统中对应专利分类号的小类层级含义、LDA输出信息、语料库相结合定义主题标识词,并将其作为查词对象,利用负采样模型构建的相似度量计算其相似词及相似系数,对LDA模型中的主题词进行过滤筛选,过滤出与标识词相关系数大的前20个词,作为主题关键词的选取结果。
5.3 演化关键词选取
本文演化的目的是分析主题关键词出现的最早时间,因此,演化关键词的选取对象为主题关键词中的不同词,对5.2中得到的主题关键词再进行两次筛选。第一次筛选是去重筛选,将每个时间切片所有主题关键词,先是进行时间切片内关键词去重,再按照相邻时间切片进行依次去重。第二次筛选是相似度筛选,通过负采样模型建立的相似度量,进行相邻时间切片词与词之间的相似度查询,以相似度系数0.78作为阈值,相似度系数小于0.78视为没有演化关系的词语,不进行演化分析。相似度系数的设定从两方面考虑:一方面,相似度系数过小会导致相似词过多,演化结果不清晰;另一方面,相似度系数过大会导致一些主要关键词找不到相似词。因此将相似系数设定为0.78,这样既能保证演化清晰度,也能保证主要关键词可以找到相邻时间切片的相似词,经过两次筛词后,得到每个时间切片的演化关键词,其数量分别为54、20、34、42、16。
依据演化关键词的特点,可以将其大致分解为5个分支,分别为操作(环境)、材料、装置、制备方法和目标,如图5所示。

图5 演化关键词的分支结果
由于制备方法和制备材料之间的关键词联系密切,能够较直接地体现发展技术,并且它们的演化关键词和演化关系较为复杂,因此本文在图5的5个分支中,聚焦制备方法和制备材料两个方面的演化关键词,分析技术发展状态。两者之间的联系与演化如图6所示,每个时间切片中加粗字体是制氢方法的演化关键词,浅色字体代表制氢材料的演化关键词,空白处表示没有对应的演化关键词,即没有方法或材料的发展。
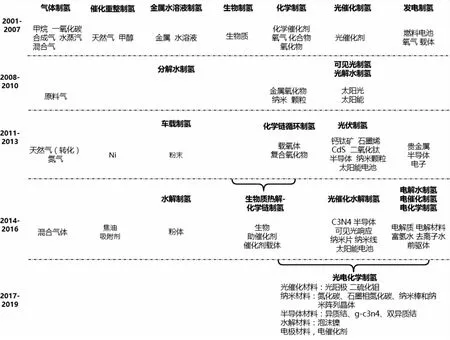
图6 制备方法与材料的演化
根据2001—2007年期间的演化关键词,发现主要有气体制氢、催化重整制氢、金属水溶液制氢、生物制氢、化学制氢、光催化制氢以及发电制氢的方法以及所对应材料,在之后的时间段对其不断发展。2008—2010年期间,发展气体制氢、化学制氢及光催化制氢的材料,并且在光催化制氢上发展可见光制氢与光解水制氢方法,在金属水溶液制氢上发展分解水制氢方法;2011—2013年期间,在可见光制氢、光解水制氢上发展光伏制氢方法,分解水制氢上发展车载制氢方法,化学制氢上发展化学链循环制氢方法,并对这几种方法以及气体制氢、催化重整制氢、发电制氢发展新材料;2014—2016年期间,在光伏制氢上发展光催化水解制氢的方法与材料,在车载制氢上发展水解制氢方法,在发电制氢上发展电解水制氢、电催化制氢和电化学制氢的方法和材料,气体制氢和催化重整制氢的材料,与此同时发展生物质制氢与化学链制氢相结合的方法与材料;2017—2019年期间,主要将化学链制氢、光催化水解制氢以及电催化、电解水、电化学制氢结合,发展光电化学制氢的制备方法和材料。从整体来说,2008—2019年期间对2001—2007年期间的制氢方法与材料都有相应的发展,尤其以化学制氢、光催化制氢与发电制氢发展迅速。
5 结语
LDA概率主题模型进行建模时,存在主题划分模糊、未考虑上下文逻辑关系的问题,针对这两个问题,本文以过滤输出主题词的角度提出一种FW-LDA组合改进方法。在LDA输出的基础上,首先通过对专利分类号的选择,辅助定义每个主题的主题标识词;其次运用负采样模型能够考虑上下文逻辑关系的特点,训练每个词语的低维词向量,并建立相似度量来计算主题标识词的相似词和相似系数,对LDA模型中输出的主题词进行过滤。以2001—2019年制氢领域的整体专利文献为实证对象,通过模型的对比验证发现,FW-LDA组合改进方法能够使主题之间的混淆程度更加准确,主题划分清晰,并且使得主题内关键词起到聚类的效果。在实证分析及效果验证后,本文利用FW-LDA方法,对整体文本进行时间切片,输出每个时间切片的主题关键词;通过去重筛选和相似度筛选得到演化关键词;并利用这些词进行演化分析,挖掘该领域的技术发展状态。本文在演化分析进行时间切片时,仅以文章数量为切片条件,未来尝试不断调整切片时间,以得到发展技术内容的具体时间点而非时间段。
