信噪比自适应Turbo自编码器信道编译码技术
2022-07-18胡启蕾许佳龙钟章队
胡启蕾,许佳龙,李 伦,钟章队,3,艾 渤,4,陈 为,5*
(1.北京交通大学 轨道交通控制与安全国家重点实验室,北京100044;2.中兴通讯股份有限公司,广东 深圳518057;3.宽带移动信息通信铁路行业重点实验室,北京100044;4.智慧高铁系统前沿科学中心,北京100044;5.北京市高速铁路宽带移动通信工程技术研究中心,北京100044)
0 引言
信道编码通过对信源压缩后的信息序列添加校验和冗余,提高传输的可靠性。香农信道编码定理指出当信道传输率不超过信道容量时,采用合适的信道编码方法,可以实现无差错传输。经过不断的努力和探索,研究者们相继提出了汉明码[1]、卷积码[2]、Turbo码[3]、LDPC码[4]和Polar码[5]等信道编码,以期能够接近香农理论限。汉明码[1]是第一个实用的差错编码方案。卷积码[2]充分利用各个信息块之间的相关性,在维特比译码算法提出后,卷积码在通信系统得到了极为广泛的应用。Turbo码[3]和LDPC码[4]可以接近香农限,而Polar码[5]则是唯一被证明能达到香农限的编码方法。在传统的通信系统信道编译码算法设计中,首先通过优化编码器的某些数学特性(如最小码距)设计编码方案,然后根据最大后验概率(Maximum a Posteriori,MAP)原则得到最小化误码率时的译码算法。然而传统的信道编译码算法设计存在以下问题:译码器是在加性高斯白噪声(Additive White Gaussian Noise,AWGN)下设计的,当实际信道模型不为AWGN时,所设计的译码算法并不能达到最优性能。其次,只有在编码长度无限长时,才能保证信道编码的性能是最优的。实际中待编码的信息序列并非无限长,因此需要在中短码长上优化编码方法。此外,如何降低信道编译码算法的复杂度和误码率也是需要优化的。
深度学习(Deep Learning,DL)作为一种基于神经网络的数据驱动方法,已经在计算机视觉、自然语言处理等领域表现出卓越的性能。受此启发,通信研究者尝试使用深度学习解决无线通信的物理层问题[6],如信道编译码[7-8]、信道估计[9-10]、信道状态信息反馈[11]和信号检测[12-14]。现有基于DL的译码技术已对优化译码性能的问题进行了研究。文献[15]提出了一种基于循环神经网络(Recurrent Neural Network,RNN)结构的信道译码方法,该方法可以译码卷积码和Turbo码,在AWGN信道下达到接近最优的性能。文献[16]提出一种以置信传播(Belief Propagation,BP)算法为基础的迭代BP-CNN译码算法,利用卷积神经网络(Convolutional Neural Network,CNN)学习真实噪声与估计噪声之间的误差。实验表明,在噪声相关性较强时,提出的BP-CNN译码算法的性能优于BP算法。此外,由于CNN的高效性,BP-CNN结构也具有更低的译码复杂度。
传统信道编码基于AWGN信道进行设计以简化设计难度。而当实际通信信道不为AWGN信道时[17],信道编码的性能难以保证。其次,实际通信中编码长度有限,针对无限码长下设计的编码方案性能并非最优。在译码端,一旦编码方法已经确定,算法所能达到的最优性能接近MAP算法的性能。因此,考虑到译码的性能受到信道编码方案的影响,联合编译码器设计能够获得更多的性能增益。O′Shea等人将通信系统视为一个端到端的重构任务,在文献[18]中提出使用自编码器的网络结构来共同设计编码器和译码器。当编码器和译码器在相同的信噪比(Signal-to-Noise Ratio,SNR)下训练时,所提出的基于自编码器的(7,4)码编译码性能可达到(7,4)汉明码采用最大似然译码(Maximum Likelihood Decoding,MLD)的性能。此外,Xu等人在文献[19]中比较了自编码器和汉明码的性能,在真实的衰落信道下,所提出的自编码器的性能与汉明码采用MLD性能相近。在复杂的通信场景下,信道模型难以用数学模型精确描述[20]。Raj等人在信道状态信息(Channel State Information,CSI)未知的情况下,提出一种端到端通信系统的优化方法[21]。在无法准确估计瞬时信道传输的情况下,Ye等人在文献[22]中使用生成对抗神经网络(Generative Adversarial Network,GAN)来学习信道生成模型,结果表明,所提出的端到端编译码结构在AWGN信道、Rayleigh信道和频率选择性衰落信道中,该方法与传统方法相比可以达到类似或更好的性能。此外,文献[23]中提出了一种基于神经网络互信息估计器,在固定译码器的情况下,该估计器以达到最大互信息为目标去学习信道特征进而优化编码器。Jiang等人在文献[24]中提出了一个基于CNN的端到端信道编译码系统Turbo Autoencoder(TurboAE),该方法评估了中短码长(码长为100 bit)的TurboAE的性能,在-1~1 dB下,TurboAE的误码率低于Turbo码的误码率;在1~4 dB时,TurboAE的误码率与Turbo码的误码率相近。
然而,为了使训练好的TurboAE模型充分发挥其优势,在测试时需要匹配对应的信道状态,例如,在信道SNR为1 dB时训练的系统网络模型,在信道SNR为1 dB下传输信息,其性能才最好。在实际通信系统中,信道SNR并不是恒定的,这意味着TurboAE需要在一段SNR范围内进行训练并储存多个模型,不仅增加了训练的时间复杂性,也增加了系统模型存储量。本文设计了一个基于DL的端到端信道编译码系统,该系统可以在一段SNR范围内进行训练和测试,在仅用一个模型的情况下,就可以达到在单个SNR下训练的最优性能。
1 系统模型
本文所采用的系统模型如图1所示。在编码端,u∈{0,1}n为待编码的信息序列,其中n为信息序列的长度。在编码端,在已知的信道信噪比s∈的情况下,信息序列u经过信道编码后被映射为码字x∈k,其中k为码字的长度,信道编码的码率为R=n/k。信道编码的过程可以表示为:

图1 基于SNR信息的端到端信道编译码系统
x=fθ(u,s),
(1)
式中,θ表示编码器的参数集。令编码器的输出x满足软功率约束,即(x)=0与(x2)=1。
考虑系统处于独立同分布(identically and independently distributed,i.i.d.)的AWGN信道下,则译码端接收到的信号y∈k可以表示为:

(2)
噪声w∈k服从高斯分布(0,σ2),其中,σ2为噪声功率,与信道SNR的关系可以表示为:
(3)
本文提出的方法也适用于瑞利衰落信道。则译码端接收到的信号y∈k可以表示为:

(4)
式中,h表示信道增益。
在沙河的一个小河叉边,两个人老远就闻到一股恶臭,对面的岸边浮着一具已经泡胀的尸体,没有衣服,面朝下。汤翠腿一软,哆哆嗦嗦地瘫坐到地上。侯大同没有犹豫,跳下水,径直扑到尸体跟前。那情景,完全是奋不顾身的诠释。苍蝇散开,侯大同小心地翻转尸体,不是汤莲!汤翠心里其实充满了遗憾。找了这么多天,汤翠身心疲惫,她已经不怕面对姐姐罹难的现实了。
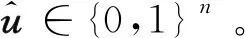
(5)
式中,φ表示译码器的参数集。与现代通信系统的模块化设计结构相比,本文使用的编码器包含信道编码模块和调制模块的功能,译码器包含信道译码模块和解调模块的功能。
因此,对于基于DL的端到端信道编译码系统,当码长n和码率R固定时,优化目标是找到使误差最小化时的编码器和译码器的最优参数集θ*和φ*。该优化问题可以被建模为:
(6)
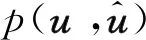
(7)

2 Attention-TurboAE结构
Jiang等人在文献[24]中提出了一个基于一维CNN的端到端信道编译码系统TurboAE。在AWGN信道下,该系统在中短码长(码长为100 bit)上表现出接近或优于使用Bahl-Cocke-Jelinek-Raviv译码算法的Turbo码的性能。但是,为了使TurboAE在各种信道条件下都能达到最优性能,需要针对不同的信道SNR下训练不同的TurboAE模型,并在实际的信道SNR下采用相匹配的训练模型。在实际移动通信系统中,信道复杂多变,信道的SNR难以维持恒定不变,为保证系统的最优性,对于不同的SNR,需要训练并储存多个模型,以应对信道的变化,然而,该策略增加了对实际通信设备存储容量的需求。因此,本文提出一种自适应SNR的端到端信道编译码结构Attention-TurboAE,在确保编译码性能的同时,大幅减少了模型的存储容量。
2.1 TurboAE

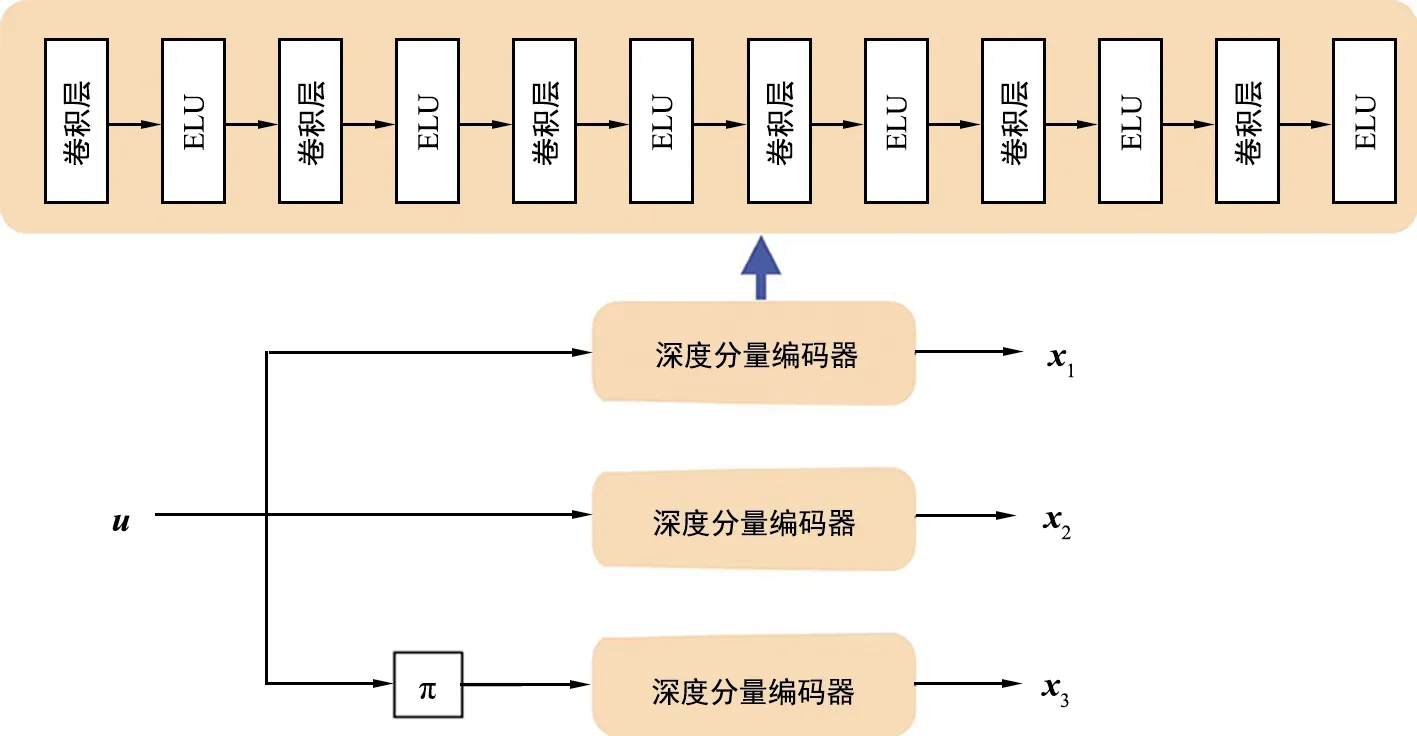
(a) TurboAE编码器结构
(8)
接收机收到带有噪声的接收序列后,进行译码。类比于TurboAE编码器的设计,译码器采用基于CNN的深度分量译码器替代原有Turbo译码器中分量译码器。卷积层和ELU激活函数迭代5次后,经过一层线性层,构成了深度分量译码器,如图2(b)所示。将接收序列y首先拆分为对应的y1、y2和y3。y1、y2与先验p(第一次迭代置为0)作为每一次迭代中第一分量译码器的输入,产生后验q。交织后的y1、y3与交织后的q作为第二分量译码器的输入,产生先验p。经过去交织操作的p作为下一次迭代的输入。进行多次迭代后,通过Sigmoid激活函数(如式9所示),将输出控制在(0,1)范围内,表示估计的原始信息比特为1的概率。
(9)
为了达到最优性能,TurboAE需要在单个SNR下训练模型,并在相同的SNR下进行测试。然而,当SNR发生变化时,所训练的模型不再保证其是最优的。因此,考虑设计一个自适应SNR的编译码方法,能够根据不同的SNR,自适应进行模型的调整,以达到在不同的SNR下,系统性能都是最优的。由于TurboAE优越的性能和良好的设计,本文将TurboAE的编码器和译码器结构作为Attention-TurboAE的基础编码器和译码器结构,以设计信噪比自适应的Turbo自编码器信道编译码系统。
2.2 基于注意力机制的自适应SNR设计
Xu等人在文献[24]中提出Attention DJSCC(ADJSCC)结构,将注意力机制引入基于DL的联合信源信道编码(DL Based Joint Source Channel Coding,DJSCC)中。在不同的信道SNR下,ADJSCC可以动态调整信源编码压缩率和信道编码率。受此启发,本文提出基于注意力机制的自适应SNR模块,用以感知信道SNR的变化。在不同的信道条件下,通过对码字分配不同的贡献度,生成与信道条件相匹配的编码码字。
基于注意力机制的自适应SNR模块设计如图3所示。自适应SNR模块主要包括三部分:特征提取、贡献度预测和贡献度分配。其中,特征提取模块通过平均池化操作提取特征,引入信道SNR作为特征的一部分。贡献度预测模块用以感知信道SNR,学习不同SNR下各个特征图中通道之间的非线性关系。在实际中,可以达到不同的信道条件下,自适应调整各个特征之间的关系,进而预测出不同的贡献度。最后,预测的贡献度与原始特征图进行运算,完成贡献度的分配,生成与信道条件相匹配的码字。
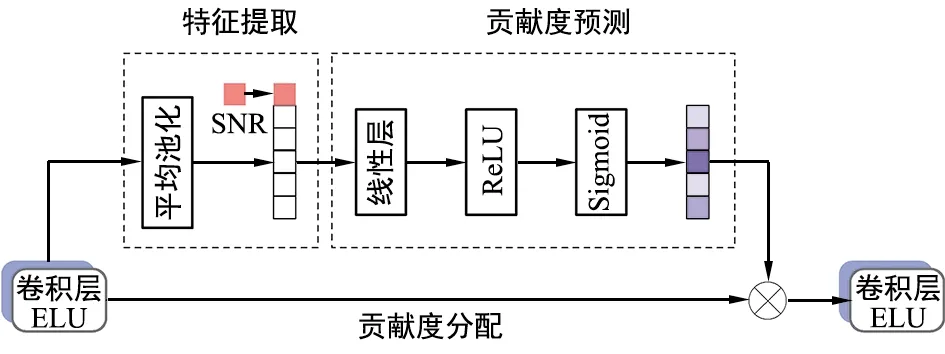
图3 基于注意力机制的自适应SNR模块结构
本文提出的自适应SNR模块连接于卷积层之间。在特征提取模块中,首先使用全局平均池化操作获取全局描述特征Gi,操作过程可表示为:
(10)
式中,AVG(·)表示全局平均池化操作,F=[F1,F2,…,Fc]∈n×c为卷积层输出的特征图,其中,c为特征图通道的数量,fi为Fi中的元素。信道信噪比s作为全局描述特征的一部分被引入,产生特征信息G,过程可表示为:
(11)
贡献度预测模块P(·)用来预测不同特征的贡献度。该模块由两层线性层组成,第一层线性层连接Relu激活函数,第二层线性层连接Sigmoid激活函数。Sigmoid激活函数使输出介于0和1之间,表示预测的贡献度C,其过程可表示为:
(12)
式中,α和β分别表示激活函数Sigmoid和ReLU,w1和b1分别表示第一层线性层的权重和偏差,w2和b2分别表示第二层线性层的权重和偏差。
最后,在贡献度分配模块中,将预测的贡献度与原始特征图相乘,使模型对不同特征有更多的辨别能力,很好地学习不同信道SNR下特征图之间的关系。重新分配后的特征图F′可以表示为:
(13)
将上述自适应SNR模块应用于TurboAE编码器和译码器中,所得到的Attention-TurboAE结构如图4所示。

(a) Attention-TurboAE编码器结构
3 实验结果
本节通过对TurboAE和Attention-TurboAE进行实验仿真,以证明注意力机制在自适应信道SNR的信道编译码方案中的可行性和有效性。首先,在AWGN信道和瑞利衰落信道下,分别对比Attention-TurboAE和TurboAE的性能。其次,对Attention-TurboAE的扩展性进行了实验,即将在固定码长下训练的模型,在不同码长上测试。最后,对自适应SNR模块的作用效果给出了相应的解释。
实验在Linux服务器上进行,该服务器包括12个8核Intel(R) Xeon(R) Silver 4110 CPU和16个GTX 1080Ti GPU,每次实验使用1个GPU。实验在Python3.6的环境下采用PyTorch 1.0版本。使用初始学习率为0.000 1的Adam优化器来搜索最佳网络参数。随机生成100 000个码长为100的二进制数据样本作为训练集,随机生成100 000个码长为100的二进制数据样本作为测试集,训练800次以保存最佳参数模型。Attention-TurboAE与TurboAE编码器码率R都设置为1/3,译码器中的迭代次数为6次,特征图的通道数为100。
3.1 AWGN信道
在AWGN信道下,分别采用图2所示的TurboAE结构和图4所示的Attention-TurboAE结构进行实验。当码长为100时,在信道SNR为0~4 dB内训练并测试Attention-TurboAE,在SNR分别为0,1,2,3,4 dB下训练Turbo模型,并在SNR为0~4 dB范围内测试,实验结果如图5所示。
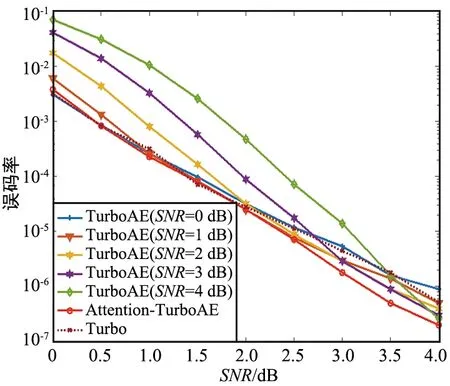
图5 AWGN信道下,100码长训练并测试时,Attention-TurboAE与TurboAE性能对比
实验证明,在特定SNR下训练的TurboAE模型只有在相同的SNR下测试时才能展示出其最佳性能。为了满足信道编译码系统的性能在一段SNR范围内都能达到最优,需要训练多个模型,进而导致存储量的增加。然而对于实际通信来说,系统需要能够自适应不同的信道条件,产生相匹配的编码码字。Attention-TurboAE虽然在一段SNR范围内进行训练,却可以达到TurboAE单个SNR下训练和测试时的最优性能,大大减少了通信系统的储存量。此外,实验设置码长100、码率1/3的Turbo码作对照,实验结果(图6)表明Attention-TurboAE在低SNR(0~2 dB)下接近Turbo码性能,在高SNR(2~4 dB)优于Turbo码性能。
3.2 瑞利衰落信道
瑞利衰落信道(Rayleigh Fading Channel)模型假设信号通过无线信道之后,其信号幅度是随机的,并且其包络服从瑞利分布。考虑信道为瑞利衰落信道时,在100码长下,对Attention-TurboAE和TurboAE的性能进行对比。采用基于3.1节中在AWGN信道上训练好的Attention-TurboAE和TurboAE模型进行微调(Fine-tune)。此外,设置瑞利衰落信道下的Turbo码性能作为对照,实验结果如图6所示。Attention-TurboAE在瑞利衰落信道下,也基本可以达到Turbo码单个SNR下训练的性能。与Turbo码相比,Attention-TurboAE在2~4 dB下性能略低。这是因为,Attention-TurboAE是在基于AWGN信道下训练好的模型进行微调,因此,在较高SNR下,性能比Turbo码较低。
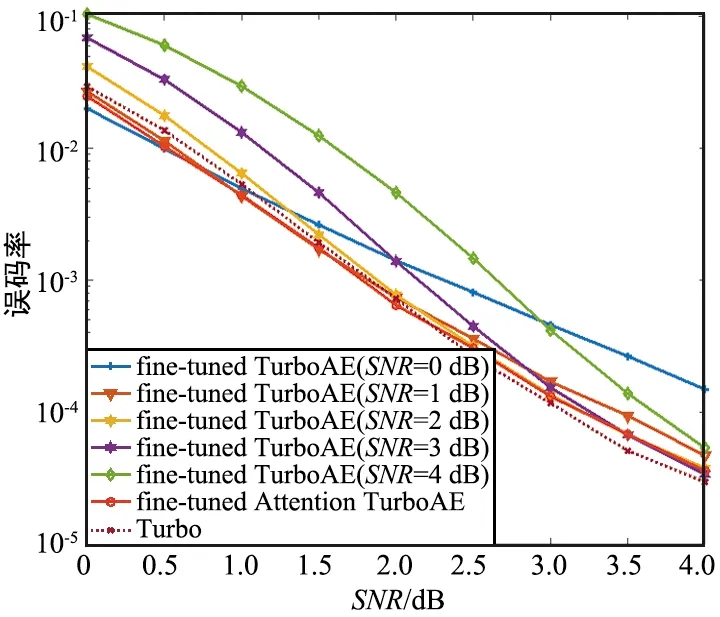
图6 瑞利衰落信道下,100码长下训练时,Attention-TurboAE与Turbo性能对比
3.3 扩展性
当实际系统模型的输入与训练模型时的输入不匹配时,例如,对于一个在特定码长下训练的系统,如果输入码长发生了变化,我们仍然希望其性能较优。因此,在信道SNR分别为0,1,2,3,4 dB,码长为100时训练TurboAE;而在SNR为0~4 dB,码长分别为50和200进行测试。对于Attention-TurboAE结构,在信道SNR为0~4 dB、码长为100时进行训练,并分别在码长为50和200的情况下进行测试。设置码长分别为50和200的Turbo码作为对照实验。
图7(a)展示了TurboAE和Attention-TurboAE在码长为100时训练,码长为50时的测试结果;图7(b)展示了TurboAE和Attention-TurboAE在码长为100时训练,码长为200时的测试结果。实验结果显示无论输入码长的大小,Attention-TurboAE的性能基本能达到单个SNR下训练TurboAE的性能。

(a) 测试码长为50
此外,当测试码长为50时,Attention-TurboAE在1.5~4 dB下的性能优于Turbo码。对比测试码长为200时的性能,随着码长的增加,Attention-TurboAE的误码率越低,例如,在SNR为2 dB下,Attention-TurboAE在测试码长为200时的误码率比测试码长为50时的误码率低。由于测试环境(测试码长为200)与训练环境(训练码长为100)并不匹配,且Attention-TurboAE是自适应信道SNR的编译码系统,并非自适应码长,因此,在测试码长为200时,与Turbo码相比性能略差;且码长越长,SNR越高时,Turbo码的性能会越好。
3.4 解释
为了探索在不同的SNR下,自适应SNR模块是如何根据不同的信道噪声影响特征图中各个通道的贡献度,实验基于码长为100下训练的Attention-TurboAE模型。首先比较分析了不同信道噪声下Attention-TurboAE编码器中第3个自适应SNR模块产生的贡献度,结果如图8所示。可以看出,在训练和测试码长都为100时,针对不同的信道SNR,贡献度是不同的,这意味着对于不同的信道条件,本文所提出的自适应SNR结构将生成不同的编码码字。此外,为了分析Attention-TurboAE的扩展性,当训练码长为100时,分别在SNR为2 dB下选取测试码长为50、100、200下第3个自适应SNR模块的贡献度,结果如图9所示。可以发现,对于相同的SNR,不同测试码长对贡献度的影响很小,注意力机制只对不同的SNR起作用。通过引入SNR自适应模块,Attention-TurboAE可以更加关注信道SNR的影响,根据信道条件,为特征图中不同的通道分配不同的贡献度。

图8 训练和测试码长都为100时,不同SNR下各个通道的贡献度
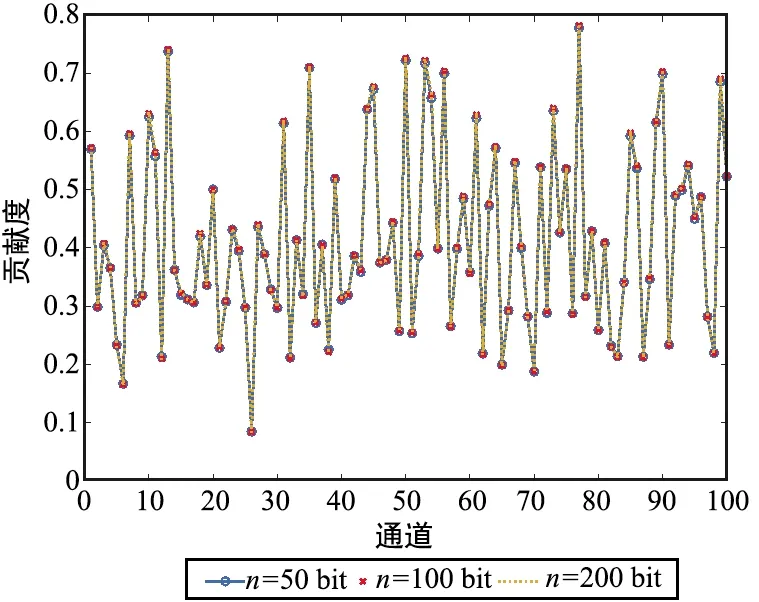
图9 SNR=2 dB、训练码长为100时,不同测试码长下各个通道的贡献度
4 结论
本文分析了TurboAE的结构,并通过引入注意力机制提出了信噪比自适应Turbo自编码器信道编译码方案Attention-TurboAE。尽管TurboAE在AWGN信道下比Turbo码有更好的性能,但在实际部署中,训练好的模型只有在相匹配的信道条件下才能达到最优性能。通过在信道编译码中引入注意力机制,提出的自适应信道SNR结构可以根据不同的信道条件,生成与之匹配的编码码字。在一段SNR范围内训练的系统模型可以达到在单个SNR下训练的TurboAE的性能,大大减少了设备端的存储量。此外,Attention-TurboAE展示出了注意力机制在自适应SNR信道编译码系统中的有效性。
