基于无监督学习的无线网络性能异常检测方法
2022-07-18吴艳芹胡华伟
张 乐,吴艳芹,杨 昊,张 平,胡华伟
(1.中国电信股份有限公司研究院,北京 102209;2.中国电信股份有限公司福建分公司,福建 福州 350001)
0 引言
无线网络作为运营商网络中重要的一部分,一旦发生性能劣化,会对用户体验带来较大影响,实时监控网络运行的状况,电信运营需要发现潜在的问题并对已发生问题的区域和设备进行准确、及时的定位分析。由于人工筛查性能异常具有滞后性,难以早期发现,且已有的案例和经验难以复用和扩展,因此规则高度依赖于运营专家的经验,而且维护难度大。
鉴于以上问题,本文利用无监督学习及统计分析技术对性能指标数据进行诊断识别,对性能异常实现早期快速识别,进一步提升用户体验以及网络质量。
1 问题描述
性能异常问题主要包含如何定义性能劣化、性能雪崩,以及如何根据不同场景、不同时段、不同指标合理设定阈值。如图1所示,性能劣化和性能雪崩的定义并无明确的界限,主要在于性能指标异常程度的不同,通常情况下性能雪崩相对于性能劣化的异常程度更严重,而如何合理设定阈值则是本文希望解决的问题。
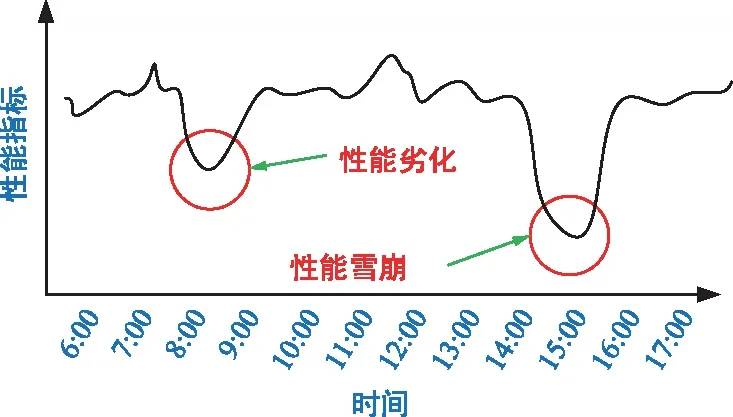
图1 性能劣化与性能雪崩
现今对于性能劣化的判断规则,无一例外均高度依赖于运营专家的经验,需要长年累月的积累,形成过程耗时耗力,且并不一定完全合理。而且规则中告警/预警准确度比较高的同时伴有一定滞后性,无法做到提前发现和提前预警,且各地运营规则不同,不易形成一套具有普适性的规则阈值生成方法。
2 性能异常检测算法
相对于现有性能异常问题诊断方法,智能算法通过对小区的关键性能指标的数据进行分析,采用统计学方法、聚类算法等获取更加合理的性能异常门限[1]。本文提出的算法大体上可以分为三类:一类为基于统计学特征(如3-sigma检测、同比/环比检测等);第二类为基于密度(如异常点/离群点检测算法、孤立森林算法等);第三类为基于聚类(如K均值算法+异常点/离群点检测算法等)。
2.1 基于统计特征的异常检测
(1) 3-sigma检测
基于3-sigma的异常检测算法(Anomaly Detection Algorithm),其算法的核心思想是[2-4]:假定数据集满足正态分布,计算数据集的数学期望μ和方差σ2,并且利用少量的Cross Validation集来确定一个阈值ε;当给出一个新的点时,定义异常值的方法为,若该值与平均值的偏差超过ε,则判断为异常点。
(2) 同比/环比检测
通过设置规则和阈值[5-7],可以对指标同比突降、指标环比下降等进行监控,增加指标检测手段。
2.2 基于密度的异常检测
2.2.1 LOF检测法
LOF(Local Outlier Factor)算法主要涉及的概念[8-9]:
①d(p,o):两点p和o之间的距离。
②k-distance:第k距离。
对于点p的第k距离dk(p)定义如下:dk(p)=d(p,o),并且满足:
a.在数据集中至少有不包括p在内的k个点o′∈C{x≠p},满足d(p,o′)≤d(p,o);
b.在数据集中最多存在不包含p点在内的k-1个点o′∈C{x≠p},满足d(p,o′) 其中点p的第k距离,即距离p点第k远的点的距离值,不包含p,如下图2(a)。 (a) 第k距离 ③ 第k距离邻域,点p的第k距离邻域Nk(p),就是点p的第k距离半径内的所有的点,包括第k距离所对应的点,因此,p的第k邻域点的个数|Nk(p)|≥k。 ④ 可达距离,点o到点p的第k可达距离定义为: k(p,o)=max{k-distance(o),d(p,o)}, 其中,k(p,o)表示o点到p点的第k可达距离,至少是o的第k距离,或者为o、p间的真实距离。如图2(b),o1到p的第5可达距离为d5(p,o1),o2到p的第5可达距离为d5(p,o2)。 ⑤ 局部可达密度,点p的局部可达密度表示为: 其中,点p的局部可达密度越高,点p越有可能与当前的领域内其他的点属于同一簇,密度越低,点p越可能是离群点。 ⑥ 局部离群因子,点p的局部离群因子表示为: 局部离群因子的值约接近1,标识点p的与邻域内的其他点越有可能是同一簇;局部离群因子的值越大,则表明点p的密度值越小,与p的邻域内其他点的密度越不一致,则点p越可能是异常点[10-12]。 2.2.2 孤立森林算法(Ifortst) 以二维数据为例,如图3所示,图中A点和B点为离群点,希望将点A和点B单独切分出来[13]。先随机指定一个维度,当前维度的取值区间捏随机选择一个切割点p,按照该切割点将数据集进行左右切割,切割为两个子集,将小于p点的节点放在左子集,大于等于p点的节点放在右子集。然后,在左右两组子集中,重复上述步骤,不断指定维度对数据集进行切分,构造新的子集,直到每个数据子集仅剩一个数据点,无法再继续分割,或者剩下的数据全部相同为止。 图3 孤立森林算法异常点切割 由图3可知,点B处在较为稀疏的位置,与其他的点距离较远,通过少量的分割就可以将点B分割出来,点A处在较为稀疏的位置,需要的分割次数更多一些。孤立森林算法采用二叉树去对数据集进行分割,被分割的数据点在二叉树中所处的深度反应了该条数据的“疏离”程度。整个算法大致可以分为两步: 步骤1训练:在总数据集中,随机抽取多个样本,作为构建多棵二叉树的训练集。 构建一棵二叉树时,先从总数据集中抽取样本容量为n的样本集,然后随机选择一个特征维度作为该样本集的根节点,并随机在特征的取值区间选择一个值,将样本集划分为左右子集,然后分别在左右子集中,重复上述步骤,直到满足如下条件: ① 数据不可再分,即只包含一条数据,或者全部数据相同。 ② 二叉树达到限定的最大深度。 步骤2预测:根据多棵二叉树的结果,计算每个数据点的异常分值。 数据x的异常分值计算:先要估算x在每棵二叉树中的深度,即从根节点到叶子节点经过的边的个数。设二叉树的训练样本中落在x所在叶子节点的样本数为T.size,则数据x在这棵二叉树上的路径长度h(x),可以用这个公式计算: h(x)=e+C(T.size), 其中,e为数据x在二叉树深度,C(T.size)为一个修正值,它表示该二叉树的平均路径长度。一般的,C(n)的计算公式如下: 其中,H(n-1)可用ln(n-1)+0.5772156649估算,此处的常数是欧拉常数。结合多棵二叉树,数据x最终的异常分值如下: 其中,E(h(x))表示数据x在多棵二叉树的深度的平均值,需对多棵树的结果进行归一化。 从上述对异常分值的计算可以看出,如果数据x在每棵树中的平均深度越短,得分越接近1,则数据点x越异常;如果平均深度越短,得分越接近0,则x越可能是个正常点。 KMeans算法原理简单,容易实现,可解释度较强,故此采用KMeans算法做聚类分析。 KMeans聚类算法:选择初始化的k个样本作为聚类中心,其中k为聚类的类别数。计算数据集中每个样本到k个聚类中心的距离,将样本归类到距离最近的类中,然后重新计算每个类的质心,重复以上步骤,直到迭代次数,或者最小误差小于特定阈值为止。这样最终确定每个样本所属的类及每个类的质心。 实验中所用的性能数据为选定市区2021年6月-8月的数据,包括RRC连接成功率、E-RAB连接成功率、eNodeB内切换成功率、X2接口切换成功率及S1接口切换成功率等性能指标。 基于统计特征的性能异常检测方法利用各异常指标的质量信息的均值和标准差来划定阈值,将“质量信息小于百分比均值-(a*标准差)”划定为异常(a为系数,此处等于3),与原始标定的结果(小时粒度达到门限)做比较。 其部分结果和案例如表1所示,通过表1不难发现尽管各异常指标质量信息分布有所不同,但通过调整样本的分布,可以使得划定的阈值满足各异常指标的检测结果,均可达到较好效果。 表1 基于统计特征的性能异常检测结果和案例 3.3.1 基于LOF算法 (1) 原始数据异常检测 采集某市区两个月运行的现网数据中字段列表1的38种性能数据作为样本集,随机选取70%作为训练集,剩余30%作为测试集,利用LOF算法进行建模,调整参数使得模型尽可能学习到更多有效特征。 为了方便评价模型的好坏,样本集需要进行标注,相当于半监督学习。在参数n_neighbors= 3 000时效果最好,AUC值为0.580 3。 (2) 归一化数据后异常检测 此处只将数值型特征进行归一化处理,百分比型特征不做处理,构成新的数据集用于训练模型,分别尝试了3种不同的归一化方法:分位数归一、正则归一和10为底的log函数归一化处理。 经过归一化处理以后,数据的分布更加合理,模型的泛化能力更强,分位数归一在参数n_neighbors= 40时,AUC最大值达到了0.946 5;正则化归一在参数n_neighbors= 180时,AUC最大值达到了0.930 4;10为底的log函数归一化处理在参数n_neighbors= 22时,AUC最大值达到了0.905 7,归一化效果明显。 3.3.2 基于IForest算法 训练集与测试集LOF算法所用训练集与测试集归一化前一样,利用LOF算法进行建模,调整参数使得模型尽可能学习到更多有效特征。 在参数n_estimators=200,contamination= 0.15时效果最好,AUC为0.620 7。 基于密度的算法中用量信息数值往往很大,对密度结果影响也很大,鉴于此,先对各异常指标的用量信息处理归一化后做KMeans聚类分析[14-15],将聚得的类再进行LOF异常值检测。 其中聚类类别分为8类时效果最好,AUC值为0.970 6,准确率为0.994 1,相对于基于密度的方法有了较大提高。 以效果最好的基于聚类的异常检测方法为例,分别统计了RRC连接成功率、ERAB连接成功率、eNodeB站内切换成功率、X2内切换成功率和S1内切换成功率5类指标的异常检测结果,具体如图4所示。 由图4可知,基于聚类的异常检测算法对各项指标的异常判断较为均衡,同时准确率高,达到了对于性能异常检测的预期。 图4 聚类异常检测部分指标结果 本文针对无线网络性能异常检测问题,提出了3种无监督异常检测方法,分别为基于统计特征的异常检测、基于密度的异常检测、基于聚类的异常检测,并采用实际性能数据对各种异常检测方法进行测试。实验结果表明,异常检测算法中基于聚类的算法效果最好,AUC值为0.970 6,准确率为0.994 1。本文通过将AI 技术应用于无线网络性能预测,帮助运维人员及时掌握无线网络的运行状况与趋势,实现性能劣化预测预判,增强主动运维能力,防患于未然,有效提升客户体验。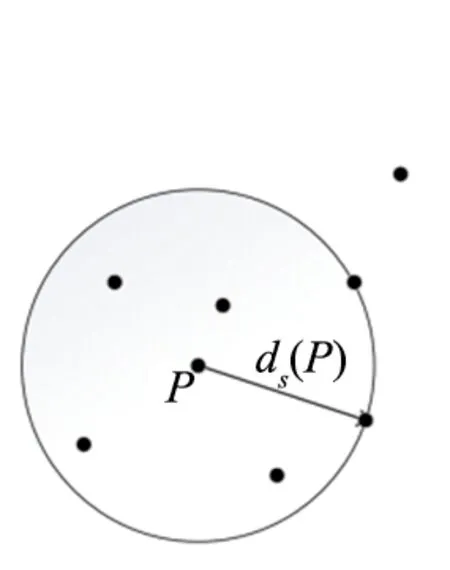

2.3 基于聚类的异常检测
3 算法实验及结果分析
3.1 数据准备
3.2 基于统计特征实验分析

3.3 基于密度的实验分析
3.4 基于聚类的实验分析
3.5 结果分析

4 结论
