京津冀站点风温湿要素的机器学习订正方法
2022-07-14韩念霏陈明轩宋林烨曹伟华
韩念霏 杨 璐 陈明轩 宋林烨 曹伟华 韩 雷
1)(中国海洋大学, 青岛 266100) 2)(北京城市气象研究院, 北京 100089)
引 言
灾害性天气对我国乃至全球社会经济发展和人民生活均有较大影响,因此天气预报在日常出行、户外体育赛事举办、防灾减灾、交通运输及农业生产等方面作用越来越重要。数值天气预报是根据大气实际情况,在一定初值和边值条件下,通过大型计算机进行数值计算,求解描述天气演变过程的流体力学和热力学的方程组,预测未来一定时段大气运动状态和天气现象的方法。虽然目前制作日常天气预报的主要方法均来自于区域或全球尺度数值天气预报模式,但模式初始场、动力和物理过程的不确定性等因素,可能导致数值天气预报与实况间存在较大偏差[1]。
在海量数据背景下,人们开始研究采用多种误差订正方法[2-6]实现对单一数值预报结果准确率的进一步提升,其中人工智能显现出非常广阔的应用前景[7-8],越来越多的研究尝试采用新方法对模式产品进行误差订正,并取得理想结果。孙全德等[9]利用LASSO回归、随机森林(random forest,RF)和深度学习(deep learning,DL)3种机器学习算法,对欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)的华北地区近地面10 m风速预报进行订正,并与传统的模式输出统计(model output statistics,MOS)方法进行对比,表现出机器学习方法在改善局地气象精准预报方面的潜力。Han等[10-11]不仅借助支持向量机(support vector machine,SVM)模型预测风暴运动趋势和风暴增长,还在2021年采用深度学习模型CU-net对ECMWF全球数值预报系统 (ECMWF-IFS)2 m温度、2 m相对湿度、10 m风的24~240 h预报进行格点订正,为数值天气预报偏差订正研究和业务应用开辟了新途径。杨璐等[12]采用SVM建立雷暴大风天气识别模型,有效提高了雷暴大风预警预报准确率;谭江红等[13]采用lightGBM机器学习方法建立模型对湖北89个气象站的气温预报进行订正,准确率较数值预报产品明显提升,展现了lightGBM机器学习方法对于气象要素预报的良好应用前景。疏杏胜等[14]利用人工神经网络(artificial neural networks,ANN)、极限学习机(extreme learning machine,ELM)以及SVM模型对辽宁桓仁水库流域未来1~3 d降雨进行多模式集成预报,结果表明:基于机器学习模型的多模式降雨集成预报方法可行且能够提高短期预报降雨精度;Burke[15]在改善高分辨率的冰雹预报效果时采用RF方法,减小了模型偏差,冰雹预测准确率更高。
2016年Chen等[16]提出了XGBoost(eXtreme Gradient Boosting)方法,由于其优良性能及在各领域出色表现而广泛应用。韩丰等[17]基于XGBoost方法提高了短时强降水事件的预报准确率;毛开银等[18]在XGBoost方法的基础上提出CD-XGBoost(clustering and double XGBoost)算法,对中国2552个气象观测站观测数据与ECMWF数值模式逐3 h地面10 m风速预报进行站点订正,取得较高准确率;任萍等[19]采用XGBoost方法对北京地区快速更新循环数值系统的预报数据进行订正,有效减小了模式预报误差;徐磊等[20]提出结合XGBoost方法和奇异谱分析法(SSA)的SSA-XGBoost预测模型,试验结果表明,该模型对降水变化趋势预测具有指导意义。
北京城市气象研究院于2017年开始研发建立睿图模式体系中的快速集成与无缝隙融合预报子系统——睿图-睿思系统(rapid-update multi-scale analysis and prediction system-rapid integration and seamless ensemble,RMAPS-RISE,简称RISE系统),该系统是一个多源气象数据快速集成与融合预报系统,可以实现逐10 min更新、覆盖京津冀全域500 m、北京冬奥重点赛区100 m网格分辨率的风场、温度、降水等的实时预报,并在数据融合、偏差订正、气候学订正等方面开展大量工作[21-25]。本文尝试采用线性回归方法、梯度提升回归(gradient boosting regression tree, GBRT)方法、XGBoost方法以及堆叠集成学习方法(Stacking方法)与RISE系统预报的高时空分辨率气象数据相结合,构建加入地形特征以及多源气象要素特征的误差分析模型对RISE系统各起报时次的站点预报进行逐小时间隔订正,探索机器学习方法在高分辨率预报误差订正方面的作用和效果,为业务应用提供参考。
1 数据及模型构建方法
1.1 数 据
1.1.1 数据简介
本文采用2020年12月—2021年11月RISE系统提供的时间分辨率为10 min、水平分辨率为500 m的京津冀网格化快速更新预报产品(简称RISE产品)。观测数据为同时段京津冀地区470个考核站的温度、湿度、风速、风向4种气象要素。RISE产品为网格数据,而本研究针对470个考核站进行订正,因此为了与自动气象站观测数据匹配,首先需要对格点数据采用欧氏距离插值法进行处理,针对470个考核站每个站点的经纬度坐标,同时遍历所有格点的经纬度坐标,通过欧式距离公式计算出每个站点与所有格点的距离,将最小距离的所对应格点预报数据插值保存为站点数据。对风场信息的预报与观测进行数据格式统一化后,以时间维度对所有时刻的自动气象站观测数据和RISE站点预报叠加,制作三维数据集的同时完成观测数据与预报在时间维度的对应,方便后续建模训练。
1.1.2 数据集划分
由于RISE产品在不同季节、不同气象要素误差表现不同,因此将RISE产品按季节分为春(2021年3—5月)、夏(2021年6—8月)、秋(2021年9—11月)、冬(2020年12月—2021年2月)4个季节构建样本集。图1为4个季节24个整点起报时次有效样本量,不同季节可用样本量均在20000以上,秋冬季样本量多于春夏季。
模型训练过程中,对数据集采用k折交叉验证[26]对各季节测试集进行评估:将所有的数据集分成k份子集,进行k轮测试过程,每次选取其中1份作为测试集,其余(k-1)份作为训练集训练模型,用保留的测试集计算预测误差;重复训练过程直到k个子集均被作为测试集使用过,计算k个模型的误差平均值作为该模型评分。k折交叉验证是估计模型准确性的可靠方法,本文对各模型进行5折交叉验证评估可以提供更准确的测试误差估计值,减少单一异常值对结果影响。

图1 不同季节各起报时次有效样本量Fig.1 Number of valid samples for each initial time in different seasons
1.2 模型构建
考虑到RISE系统不同季节、不同起报时次误差分布特征不同,本文采用误差分析的建模思路针对RISE产品的4个季节以及24个整点起报时次(00:00—23:00,世界时,下同)分别构建样本进行订正,起报时次是指开始发出预报的时次,RISE产品中每个起报时次均对未来1~12 h的每个整点发出对应12个时刻预报(也称为预报时效分别为1~12 h 预报),由于RISE系统前2 h预报准确率已较高,因此本文分别对所有起报时次未来3~12 h预报进行订正,提高各起报时次预报准确率。本建模方法订正2 m温度、2 m相对湿度、10 m风速和10 m 风向4种气象要素,所有建模特征的提取均需要滚动遍历训练集所有相邻前后两日数据进行误差分析,对于各要素按照不同起报时次分别建模进行订正,模型特征与标签由以下几部分构成:①收集前一日所有不同起报时次对未来3~12 h的各气象要素预报,并与自动气象站对应的观测数据相减,计算前一日预报偏差作为特征;②收集当日不同起报时次对未来3~12 h多种气象要素的预报作为特征,这是由于多种气象要素相互影响,将多要素预报作为特征能够更全面学习天气变化。如在温度预报中,加入湿度和风场信息预报,其他要素亦然;③每个样本对应的站点高度特征;④标签为所订正气象要素预报对应时间的自动气象站观测数据。
考虑到每个起报时次对未来3~12 h的预报误差会随着预报时效增加而出现不同的变化趋势,为了更好地对前一日预报误差进行学习,本建模方法将每个起报时次的预报时效分为两段单独进行训练,以达到更好的学习效果,第1段采用预报时效为3~6 h的所有样本训练,第2段采用预报时效为7~12 h的所有样本训练。
2 机器学习方法
2.1 线性回归方法
线性回归方法是机器学习中属于监督学习的基础且常用的方法之一。气象要素预报受多个变量影响,因此选用多元线性回归模型,根据不同建模方法寻找观测数据与所选特征变量之间的线性关系。
2.2 梯度提升回归方法(GBRT方法)
梯度提升回归方法(GBRT方法)是机器学习Boosting算法家族中应用较广泛的树型算法之一,是一种具有高预测精度和强可解释性的机器学习方法。GBRT方法每次计算的目的是减少上一次计算的残差(利用残差学模型),为了消除残差,在残差减少的梯度方向上创建一个新的模型。GBRT方法可以看作M棵树组成的加法模型。
2.3 XGBoost方法
XGBoost方法是一种开源机器学习算法。XGBoost方法相比于GBRT方法将损失函数(预测值和真实值的误差)变得更复杂,同时XGBoost方法针对过拟合这一关键问题也进行改善:在代价函数增加了正则化项,不仅控制模型复杂度,还可以降低模型偏差,有效防止过拟合,得到学习能力极强的模型。除此之外,引入阈值限制深度优化、叶节点分裂和树形生长过程。在XGBoost方法训练过程中,从第2棵树开始,每棵树的目标值设定为上一棵树预测值与真实值的误差,以不断提高对错误样本的学习能力。同大部分机器学习模型一样XGBoost方法的目标函数可以用损失函数和正则项之和表示,对模型的准确度和复杂度进行控制和优化。
2.4 堆叠集成学习方法(Stacking方法)
集成学习的思想1979年由Dasarathy等[27]提出,广泛用于分类和回归任务。集成学习往往通过一些结合策略将多个学习器的结果进行合成从而得到集成学习器的结果,相对于单一机器学习模型,该方法通过选取不同的结合策略对得到的多个学习器进行组合得到最终结果,充分利用各个机器学习方法的优势,提高泛化能力,避免单一学习器可能因误选而导致预测效果不佳的情况。其中典型代表为一种异质集成学习算法堆叠法(简称Stacking方法)[28],在Stacking方法中将个体学习器称为初级学习器,用于结合的学习器称为次学习器或元学习器,该方法首先从初始数据集训练出初级学习器,生成一个新的数据集用于训练次级学习器。近年人们尝试将该方法应用于各个领域,其预测结果相比单模型均展现出良好的学习能力[29-31]。
本文将前3种机器学习方法(线性回归方法、GBRT方法以及XGBoost方法)作为Stacking方法中的初级学习器,选用3种方法中泛化能力最强的模型作为元学习器,利用Stacking方法,通过对前3种单一订正方法进行有效集成和二次学习订正,充分发挥各方法的优势,训练过程如下:首先,将训练集按照初始建模选取的特征量F(x1,x2,…,xn),采用线性回归方法、GBRT方法、XGBoost方法3种方法输入特征标签进行模型训练,并采用训练数据对应输入训练后的3个模型,得到3个模型的预报值tlr,tgb,txgb;其次,将得到的3个预报值加入到原始训练数据特征,构建新的训练数据特征量F(tlr,tgb,txgb,x1,…,xn),将新的数据集采用3种方法中表现相对较好的方法作为元学习器再进行一次训练,得到元学习器最终训练模型;最后,采用测试集重复以上步骤,得到初级学习器的预报值后,构建新的测试数据特征量,并输入元学习器的最终训练模型,得到最终预报并进行对比分析。
3 试验结果
3.1 2 m温度
图2为春季00:00,06:00,12:00,18:00 4个不同起报时次,采用上述4种方法对RISE系统的2 m温度站点预报订正前后均方根误差对比。图2中4条虚线分别对应不同方法3~12 h预报时效均方根误差平均值。由图2可见,不同起报时次的RISE温度预报呈不同的误差状态。其他3个季节(图略)同春季展示的情况相似,均在12:00起报的未来10~12 h(对应北京时间为06:00—08:00)预报误差最大。这是由于RISE系统所用背景场为中国气象局北京快速更新循环数值预报系统(CMA-BJ)预报产品,该系统预报误差有明显的日变化特征,在早上和傍晚时段受太阳辐射等影响导致误差较大[32]。

图2 RISE系统春季2 m温度预报订正前后均方根误差对比Fig.2 Comparison of 2 m temperature root mean square error of RISE in spring before and after correction

续图2
表1为4种方法采用误差分析建模后,对2 m温度的季节订正结果。可以看到,经过机器学习方法订正后,4个季节的所有起报时次温度预报误差相比RISE产品误差均明显降低。其中,Stacking方法订正效果在4个季节中均表现最佳,订正后春、夏、秋、冬4个季节相对于RISE产品的均方根误差分别降低35.4%,37.12%,40.25%和40.40%。单一方法订正中,XGBoost方法表现最佳,均方根误差降低20%~35%,其次为GBRT方法,线性回归方法相对最低,但仍有明显效果。
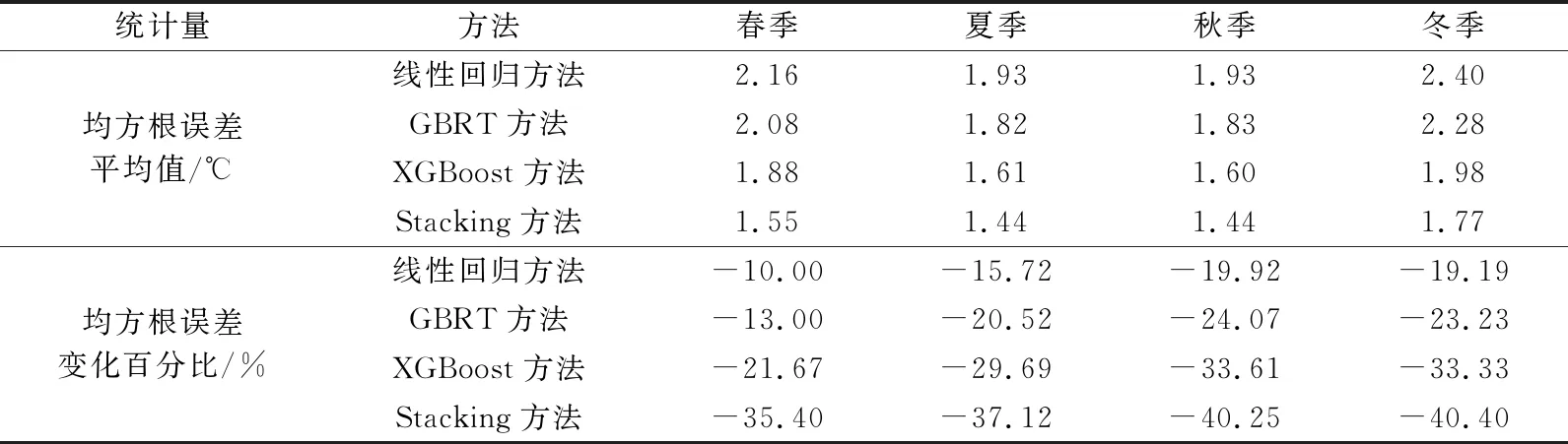
表1 4种方法对2 m温度预报的季节订正结果Table 1 Corrected results for 2 m temperature based on four methods in each season
3.2 2 m相对湿度
由于RISE系统的温度和相对湿度预报技术路线基本一致,因此文中仅给出基于误差分析建模,采用4种方法对4个季节所有起报时次未来3~12 h的2 m相对湿度预报均方根误差对比,其中4条虚线为对应订正方法的3~12 h预报时效均方根误差的平均值(图3),采用4种方法对4个季节2 m相对湿度的季节订正结果见表2。由图3可见,4个季节所有起报时次对未来3~8 h的2 m相对湿度预报均方根误差均随着预报时效的增加而增大,达到最大后趋于平稳,订正后的误差变化规律与原始预报的变化规律保持一致,但幅度较小。同时可以看到,Stacking方法订正结果优势最明显,其次是XGBoost方法、GBRT方法、线性回归方法。由表2可知Stacking方法在4个季节RISE产品2 m相对湿度预报订正中,使均方根误差降低35%~45%,改善效果明显。

图3 RISE系统4个季节2 m相对湿度预报订正前后均方根误差对比Fig.3 Comparison of 2 m relative humidity root mean square error of RISE in four seasons before and after correction

表2 4种方法对2 m相对湿度的季节订正结果Table 2 Corrected results for 2 m relative humidity based on four methods in each season
3.3 10 m风速
限于篇幅,图4仅给出夏季和在00:00,06:00,12:00,18:00 4个起报时次采用4种机器学习方法对RISE 10 m风速预报订正前后的均方根误差对比,其中4条虚线为对应订正方法的3~12 h预报时效均方根误差平均值。表3给出4种机器学习方法采用误差分析建模对10 m风速的季节订正结果。综合对比图4和表3可以看到,经过4种机器学习方法订正后不同起报时次、不同季节和不同预报时效的风速预报误差相比RISE系统预报误差均明显降低。4个季节中,秋冬季均方根误差较大,为1.5~2 m·s-1,订正后大部分预报时效均方根误差低于1 m·s-1,Stacking方法订正效果最佳,使均方根误差分别减小47.44%和46.81%;春夏季RISE产品均方根误差较小,不超过1.5 m·s-1,Stacking方法订正后,均方根误差分别降低32.17%和36.80%。
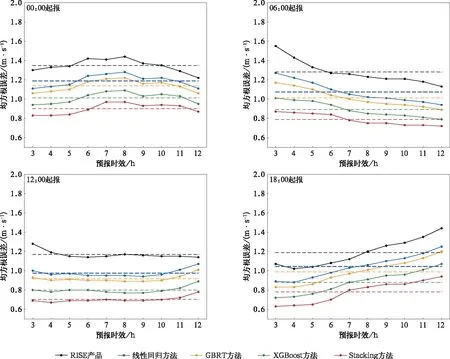
图4 RISE系统夏季10 m风速预报订正前后均方根误差对比Fig.4 Comparison of 10 m wind speed root mean square error of RISE in summer before and after correction

表3 4种方法对10 m风速的季节订正结果Table 3 Corrected results for 10 m wind speed based on four methods in each season
3.4 10 m风向
参考中国气象局对风向的检验标准《QXT 229—2014风预报检验方法》,对风向进行处理后采用平均绝对偏差对订正结果进行检验。表4分别给出4种机器学习方法采用误差分析建模对10 m风向所有起报时次的季节订正结果。可以看到,线性回归方法对于春季、夏季和冬季的风向订正效果不明显,对于RISE产品平均绝对偏差仅降低10%左右,而Stacking方法对于这3个季节RISE产品平均绝对偏差分别降低16.95%,18.75%和23.89%。RISE系统预报秋季10 m风向误差最大,平均绝对偏差为88.56°,Stacking方法订正后平均绝对偏差为64.88°,降低26.74%,在4个季节中订正效果最明显。对于RISE系统10 m风向预报的订正效果仍是Stacking方法最佳,XGBoost方法效果次之,GBRT方法与线性回归方法较差,但4种方法对RISE系统10 m风向预报均有提升效果。
3.5 个例分析
图5和图6分别给出2022年2月19日和3月4日两次大风天气个例中北京延庆佛爷顶站00:00与09:00起报基于Stacking方法及RISE系统2 m温度与10 m风速预报对比。
由图5可以看到,RISE系统2月19日00:00起报对温度的预报较实况偏低,09:00起报对温度预报较实况偏高,而经Stacking方法订正后温度始终与实况保持相同的变化趋势,且在数值上也更接近,有效改善了RISE系统的温度预报结果。由10 m 风速变化可知,RISE系统00:00起报风速经Stacking方法订正后与实况变化趋势一致,在9 h预报时效时风速均出现增大的趋势,而RISE系统预报风速逐渐减小;RISE系统09:00起报的风速预报始终偏小,而经Stacking方法订正后的风速与实况变化更吻合,表现出机器学习方法对于风速预报有较为稳定的正向订正效果。
由图6可以看到,RISE系统3月4日00:00和09:00起报的温度预报较实况整体偏低,未能准确预报升温趋势,而经Stacking方法订正后的温度在大部分时效与实况更为接近。RISE系统00:00起报风速存在明显的减小趋势,而实况则为增大趋势,Stacking方法订正后风速也呈减小趋势,在数值上与实况更为接近。RISE系统08:00起报的风速始终低于5 m·s-1,而实况为7~10 m·s-1,经Stacking方法订正后,风速与实况更接近,因此Stacking方法对大风天气的变化敏感,对改善RISE系统预报有实际应用价值。

图5 2022年2月19日2 m温度(柱状)与10 m风速(折线)订正对比Fig.5 Comparison of 2 m temperature(the bar) and 10 m wind speed(the line) on 19 Feb 2022

图6 如图5,但为2022年3月4日订正对比Fig.6 The same as in Fig.5,but for 4 Mar 2022
4 结论与讨论
本文基于线性回归方法、GBRT方法、XGBoost方法和Stacking方法4种机器学习订正方法,采用气象要素客观预报误差分析的建模思路,对北京城市气象研究院研发的睿图-睿思系统的风温湿要素预报产品开展站点订正研究,结论如下:
1) 以RISE系统500 m分辨率格点预报为基础,插值得到站点预报,并与自动气象站观测数据匹配作为真实标签数据,针对RISE系统每日24个起报时次对未来3~12 h的站点预报,基于上述4种机器学习方法构建预报误差模型进行订正,可以更好地拟合不同起报时次地面气象要素的误差特征,有效降低原始预报误差。由于秋冬季的可用样本量多于春夏季,因此整体上多种要素订正试验效果为秋冬季好于春夏季。
2) 基于Stacking方法,构建适合于误差分析模型的集成学习订正模型,充分集成3种机器学习方法的优势,结果表明:该方法对4个季节的风温湿要素预报效果改善最明显。基于线性回归方法、GBRT方法和XGBoost方法3种机器学习方法构建的预报误差订正模型中,相较RISE产品而言,均有较为明显的正向提升效果,其中XGBoost方法效果最佳,其后依次是GBRT方法、线性回归方法。
总体上,机器学习方法可以有效减小RISE系统高分辨率气象要素预报误差,在客观预报误差订正方面具有广阔的应用前景。在今后工作中,将从复杂地形角度出发,将山区和平原地区不同类型站点分类建模进行订正试验,提升复杂地形下的客观预报误差订正效果;同时可以在保证当前预报效果前提下,尝试训练更长预报时效的订正模型。随着预报系统产品不断积累,可以尝试增加训练样本,进一步提高机器学习模型订正效果。
