基于熵理论和BP神经网络的船舶柴油机磨损故障识别*
2022-07-14石新发邢广笑贺石中谢小鹏
石新发 邢广笑 贺石中 谢小鹏
(1.广州机械科学研究院有限公司 广东广州 510530;2.中国人民解放军92001部队 山东青岛 266000;3.华南理工大学机械与汽车工程学院 广东广州 510640)
船舶柴油机集成化、自动化程度以及功率密度不断提升,其运行可靠性、安全保障难度加大[1]。磨损是柴油机主要故障源之一,对其进行监测诊断,能够保证柴油机正常运行,延长其使用寿命[2]。油液监测作为船舶柴油机等往复式机械润滑磨损故障诊断的主要技术之一[3],随着船舶柴油机运行可靠性要求的增高,磨损监测与诊断需求增大,且特征属性数量的增加,使得油液监测多技术手段所获取的信息特征无论从量级、单位、粒度等均有很大的不同[4],因而在诊断过程中易受到无用或冗余数据的干扰,造成诊断决策过程的复杂程度增高[5]。特征约简是将大量无关和冗余的特征属性去除的有效方法[6-7],当前在对油液监测数据属性约简中,大都使用的是有监督方法,例如石新发和刘东风[8]应用的粗糙集理论,徐启圣等[9]应用的支持向量机,存在依赖专家经验的问题。同时,实现润滑磨损故障诊断智能化也是油液监测发展的重要趋势[12],BP神经网络作为相对成熟的模式识别与分类算法,具有结构设计简单、识别速度快的特点。
本文作者基于熵理论和BP神经网络组合,构建了一种能够实现诊断属性无监督约简和磨损故障模式智能识别的融合算法模型,并以某型船舶柴油机44个磨损监测数据样本为应用对象,对模型进行了应用验证,结果表明该模型在保证数据集分类特性的基础上,有效降低了冗余数据的干扰,提升了故障诊断的准确性。
1 磨损故障识别特征子集构建
1.1 特征约简方法设计
在对一个系统状态数据进行分析时,一般需要对数据进行预处理,保留有用或者信息量较大的特征。文中应用信息熵方法对该型柴油机磨损诊断数据进行一次约简筛选。
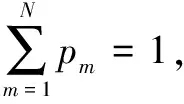
(1)
则系统总信息熵值为

(2)
为了更好地实现系统状态数据特征的优化选择,同时保留系统样本间的分类特性,引入熵度量理论,对能够表征系统分类特性的数据集优化,实现数据的二次约简降维。熵度量法是一种基于特征重要度的特征约简,以样本间的距离作为熵计算的基本要素,以此实现特征选择[12-13]。
熵度量算法基于一个相似性度量,该度量与样本之间的距离成反比[14],具体表示为
Sgh=e-aDgh
(3)
其中:g,h=1,2,…,N。
式(3)中Sgh表示样本Yg和Yh之间的相似度;Dgh为样本Yg和Yh之间的距离,一般用标准化的欧氏距离计算,其计算式为
(4)
式中:k=1,2,…,n,n为样本维数,maxYk和minYk分别表示样本集第k个属性的标准化数据最大值和最小值。
式(3)中a是一个参数,其计算式为
a=-(ln0.5)/D
(5)
对于包含N个数据样本的数据特征集,其熵按照式(6)计算。
(6)
当系统移除属性元素ci后引起已知数据集的信息熵的变化为
ΔE(ci)=|Eci-E(ci-{ci})|
(7)
ΔE(ci)是属性ci重要度的一个量化值,其值越大,说明属性ci对原始数据集越重要。
(8)
约简集合C′中最优约简子集C″定义为
(9)
磨损诊断属性集合经过2次约简后,所产生的新子集能够有效保留系统信息量和分类特性,降低后续诊断识别过程中的工作量和复杂程度。
1.2 特征子集构建流程
依据构建的润滑磨损特征选择方法,设计特征子集优选流程如图1所示。按照设计的流程,柴油机磨损故障诊断原始属性集经过2次特征属性约简,并按照自己选取条件优选新的特征集合。
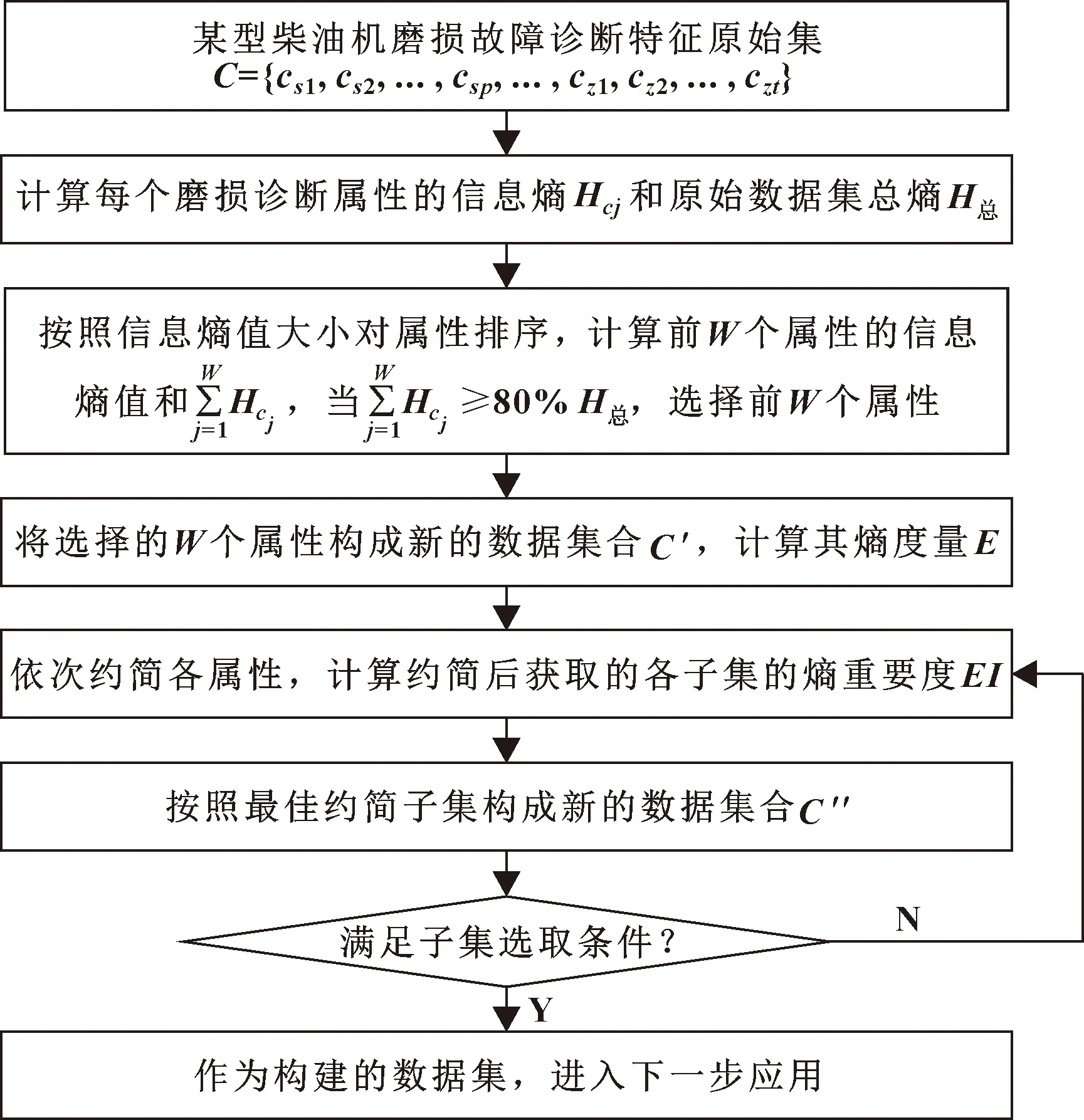
图1 磨损故障诊断特征子集优选流程
在第一次约简中,参照主成分特征提取的特征约简规则,以新特征集中属性的信息熵值和大于或等于原始特征集信息熵值的80%为选择规则,对属性集进行第一次选择。
1.3 特征子集选择实施
选择用于某型船舶柴油机磨损故障诊断研究的44个油样的磨损监测数据,其数据集可表示为
C={cs1,cs2,…,csp,…,cz1,cz2,…,czt}
其中:数据集包含发射光谱的Fe、Cr、Pb、Cu、Al、Si、Na、Mg、Ca、P、Zn等11种元素指标(属性),DL(大铁磁性颗粒)、DS(小铁磁性颗粒)、DL+DS、DL-DS、Is等5个直读铁谱指标(属性)。按照式(1)计算每个监测指标的信息熵,具体见图2。
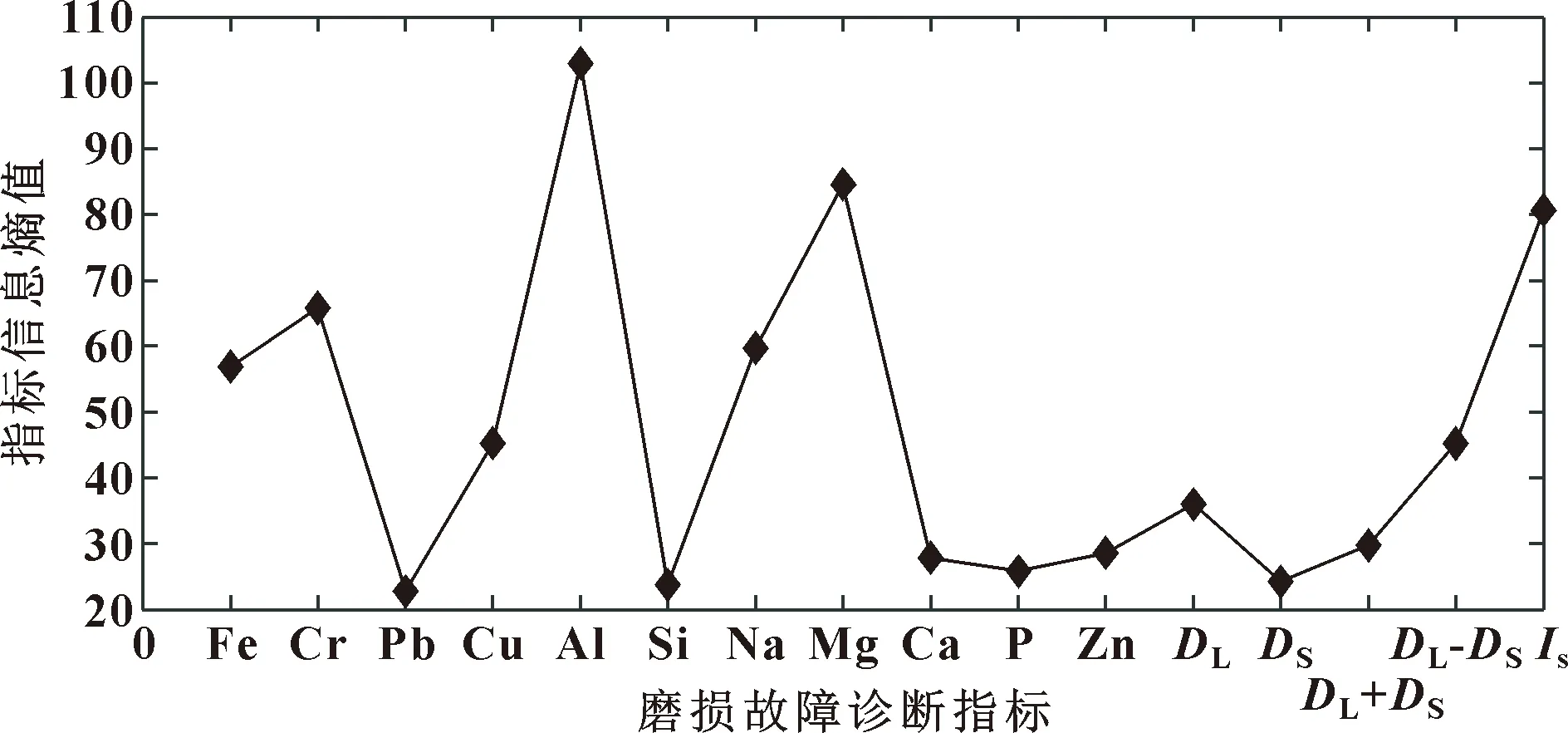
图2 某型船舶柴油机磨损故障诊断指标信息熵值
按照各磨损指标信息熵值从大到小累加,当累加至某个指标时,累加的信息熵值大于等与原监测数据集信息熵的80%时,选择用于累加的指标作为新的数据指标(属性)集,从原始数据集中选择10个指标构成新的数据集,具体如下:
C1={Fe,Cr,Cu,Al,Na,Mg,DL,DL+
DS,DL-DS,Is}
按照式(5)—式(8)对经过一次约简的新子集C1进行二次约简,计算筛选过程中的各磨损诊断指标的熵重要度EI结果见表1。表中约简第一、二、三维表示将C1依次减少一维的计算过程,表中的EI是约简过程中计算的各熵重要度。按照式(9)选择每减少一维的最优子集,进入下一步约简优化。

表1 特征约简过程中各指标的熵重要度
按照专家提供的约简规则,对C1约简3维后获得的新子集为
C″={Fe,Cu,Al,Na,Mg,DL-DS,Is}
新的子集各指标数据见图3、图4,分别为原子发射光谱数据和直读铁谱数据。
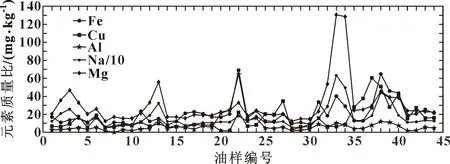
图3 油样原子发射光谱数据
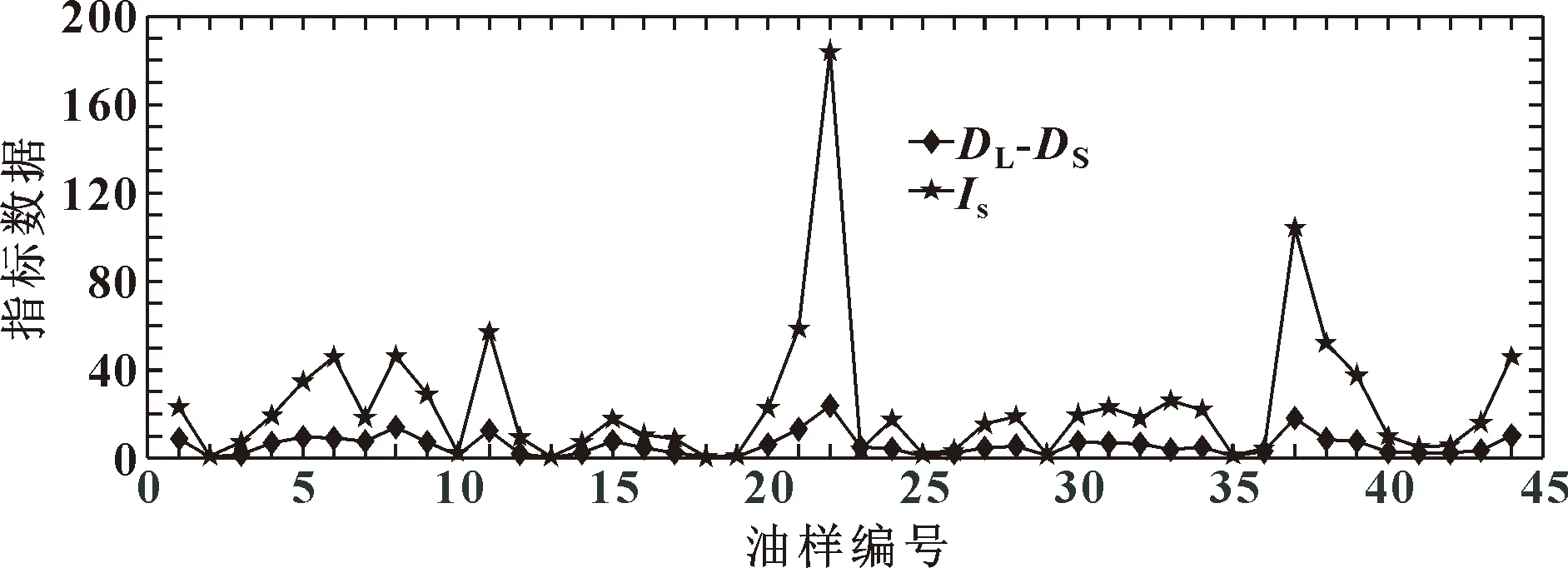
图4 油样直读铁谱数据
2 基于BP神经网络的润滑磨损故障识别
2.1 润滑磨损故障识别网络设计
BP神经网络是多层前向传播的网络,由输入层、隐含层(可能有多层)、输出层构成,3层神经网络可以很好地解决一般的模式识别问题[15]。由于该网络被大量应用,文中不再对网络的基本结构、算法过程等赘述。经过2次约简,获取的该型柴油机磨损诊断指标(属性)集为7维。按照网络构建的规则,一般隐含层神经元的个数为2,因此,将神经网络的层数设计为3层,网络输入层神经元数为7个,输出层神经元数为6个,则隐含层神经元个数为15个,网络输入向量范围为[0,1],隐含层传递函数选择tansig,输出层传递函数选择logsig,训练函数选择trainlm,最大训练次数为100,网络误差0.001,网络结构见图5。
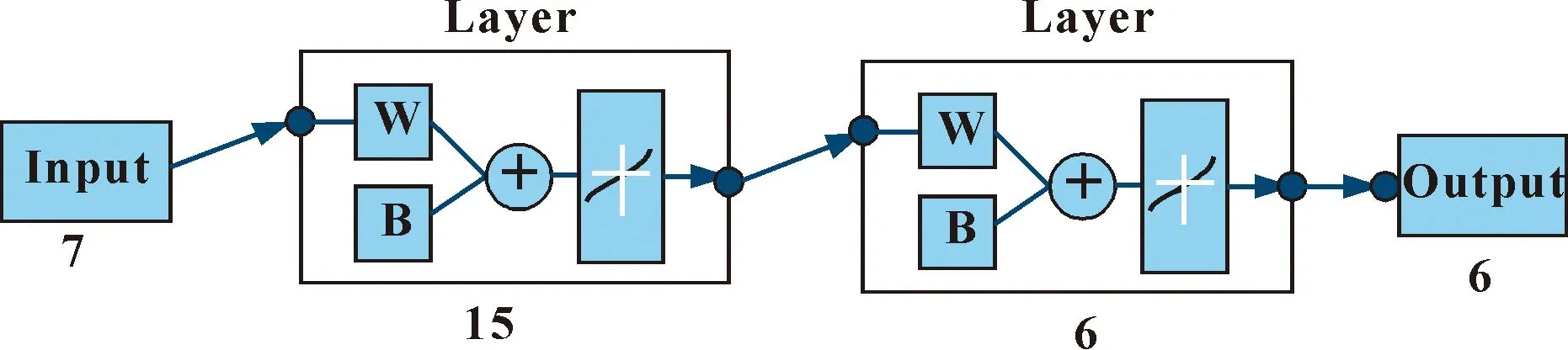
图5 BP神经网络结构
2.2 识别规则建立
文中研究的柴油机在使用中故障模式主要有以下几种类型:①主轴承异常磨损S2;②活塞异常磨损S3;③润滑油进海水S4;④铁质摩擦副异常磨损S5;⑤综合磨损状态较差S6等5种。
通过希尔变量(0或者1)来实现故障模式征兆的表达,加上正常状态,故障模式向量由6个元素组成,即为V={S1,S2,S3,S4,S5,S6},如果某种故障模式存在,则向量对应的元素为1,其余为0。由此以上故障模式可以表达为
正常状态:S1={1,0,0,0,0,0};
主轴承异常磨损:S2={0,1,0,0,0,0};
活塞异常磨损:S3={0,0,1,0,0,0};
润滑油进海水:S4={0,0,0,1,0,0};
铁磁性颗粒较多:S5={0,0,0,0,1,0};
综合磨损状态较差:S6={0,0,0,0,0,1};
对于多种故障现象的存在,则需要将故障模式表征向量对应的元素同时为1,例如同时存在活塞异常磨损征兆和润滑油进海水故障时,表示为
S多={0,0,1,1,0,0}
该型柴油机磨损诊断数据集,经过特征选择与优化后得到的特征子集为
C″={Fe,Cu,Al,Na,Mg,DL-Ds,Is}
2.3 磨损故障识别
将该型柴油机的44个油样的磨损监测数据通过故障诊断专家分类,进行故障类别标识。将标识后的样本选取30个作为训练样本,14个作为测试样本,应用选择的子集和设计的BP神经网络验证文中构建的识别模型的有效性。被识别的14个磨损故障测试样本的神经网络类编码见表2。

表2 测试样本识别的神经网络编码
将测试样本的神经网络编码与该型柴油机故障模式表达的希尔变量对应,虽然部分油样识别编码的希尔变量表征存在不足1,在数值上为0.8、0.75,但也可基本认定为属于对应的故障模式。
为验证特征约简对润滑磨损故障识别效能的提升,应用所构建的BP神经网络直接对以上44个样本的原始数据集进行训练与测试,结果见表3。

表3 未进行特征约简的测试样本识别的神经网络编码
表3给出了未进行特征选择的14个磨损故障测试样本的神经网络识别编码。与表2相比,测试样本识别结果的准确性和识别编码的规则性均较差。例如:9号样本,表2中的识别结果为主轴承异常磨损,而表3中的识别结果在3个故障模式的编码均为0.9以上,造成了识别混乱,实际反馈9号样本对应的设备确实发生了主轴承异常磨损。
从与专家给出的故障分类对比整体上看,表2中的测试样本油样神经网络编码对应的故障模式与故障诊断专家的分类标识基本一致,说明了所构建的特征属性约简和BP神经网络组合模型的有效性。
3 结论
(1)应用熵理论,构建了某型船舶柴油机磨损故障诊断特征无监督约简算法,该算法经过基于信息熵值的特征集一次约简和基于度量熵的特征子集二次约简,在保证数据集分类特性的基础上,有效降低磨损故障识别的特征指标维度。
(2)在特征约简的基础上,应用设计BP神经网络和磨损故障模式识别规则对某型船舶柴油机44个油样磨损监测数据进行磨损故障识别分析,以其中的30个油样数据为训练样本,以剩余14个为测试样本,识别结果与专家的分类基本一致。
(3)经过对实施特征约简前后的识别结果对比验证,所构建的柴油机磨损故障识别模型,实现了从特征集选择到故障模式识别的融合应用,有效降低了模型构建的复杂程度和无用数据的干扰,提升了故障识别的准确性。
