基于Tesseract_OCR的化工包装袋喷码质量检测算法
2022-07-13张茂林叶轻舟
张茂林,叶轻舟,潘 鑫,陆 华
(1.福建工程学院 电子电气与物理学院,福建 福州350118;2.福建工程学院 计算机科学与数学学院,福建 福州350118;3.福州三龙喷码科技有限公司,福建 福州 350014)
化工包装袋上喷印的生产日期、批号等信息是产品不可或缺的一部分,对产品质量管控起着重要作用,但化工包装生产线常由于各种原因造成喷印信息模糊、发散或缺失。目前大部分生产线采用人工目视进行检查,但随着产能扩大,传统的人工方法已经无法满足日常生产需求,迫切需要建立一种化工包装袋喷印质量自动检测系统。
随着机器视觉技术研究的不断深入,机器视觉检测技术已在自动化检测中扮演了重要角色。文献[1]通过使用高效光谱图匹配算法,实现了对字符的分割与识别。文献[2]提出了基于语义分割网络的OCR(Optical Character Recognition)文字识别方法。文献[3]利用卷积神经网络(Convolutional Neural Network,CNN)体系结构,实现对单个单词的识别。文献[4]采用Halcon软件开展日化瓶瓶底喷码质量检测算法研究。文献[5]基于Tesseract_OCR引擎开展纸箱读码、OCR字符视觉检测研究。基于机器视觉的化工包装袋喷码质量检测算法主要包含图像预处理、图像定位、字符分割、字符识别和字符比对5个部分,其算法流程如图1所示。

图1 算法流程图
1 图像预处理
图像质量直接影响检测算法设计和测量精度,因此在图像分析前,需进行图像预处理来增强图像中的有用信息,为特征提取、分割等处理做准备。其中,图像滤波是图像预处理中的重要环节。常见图像滤波算法有均值滤波、中值滤波、高斯滤波和双边滤波等。
均值滤波是将整个窗口范围内的像素值取平均值,虽然不能较好地保护图像细节,但对高斯噪声表现较好。中值滤波是用非线性的方法,将窗口范围内的像素值进行排序并取用中心点像素值,能够保护图像尖锐的边缘,对椒盐噪声表现较好。高斯滤波通过二维离散高斯函数采样并归一化取得加权系数后,对图像进行加权平均,是一种线性平滑滤波,适用于消除高斯噪声。双边滤波是将该点邻域像素值的几何空间距离及像素差值的加权平均值替换每个像素值,能够较好地保存边缘和降噪平滑[6-7]。根据生成采集图像的特点,本文先采用中值滤波滤除一部分噪声后,再采用高斯双边滤波进行处理,以便在衰减噪声的同时有效地保持图像边缘信息。
2 基于局部统计的可变阈值字符区域定位
字符区域定位指从采集图像中提取目标对象区域。常见的字符区域提取方法可分为基于字符梯度、字符纹理和灰度直方图3种方法[8-9]。由于工厂环境中的光照往往存在较大波动,且不同喷码信息之间存在一定的差异,常用的边缘检测方法和基于全局均值的可变阈值法鲁棒性差,易引入其它噪声。因此,本文引入亮暗补偿函数,并在亮暗补偿函数后再进行局部统计灰度模式,算法表示为
(1)
式中
t′xy=m′xy-nxy
(2)
其中,m′xy表示以坐标点(x,y)为中心局部领域Sxy内所有像素点灰度值的高斯加权平均和;nxy=amxy,为点(x,y)局部领域的亮暗补偿函数;a为亮暗补偿系数;mxy为领域Sxy内像素点灰度值均值。亮度高的区域a加大,亮度低的区域a减小,以此来减少阈值像素点灰度值f(x,y)与计算阈值t′xy之间的差值,从而减少图像分割后的噪声点。字符区域定位结果如图2所示。
图2 基于局部统计的可变阈值字符区域定位
3 基于改进连通域的字符分割
字符分割是从包含多个字符的字符区域中分割只包含单个字符的子集图像。常用的字符分割算法有投影法、连通域法和聚类分析法等[10-11]。投影法利用灰度投影直方图的波峰和波谷特性来分割字符,根据投影方向的不同可分为垂直投影和水平投影。该算法对于图像质量要求较高,目标区域外的噪点、字符变形等因素均会影响分割效果[12]。连通域法将是将图像中具有相同像素值且像素点位置关系符合某种规则的区域进行字符分割,不适用于由离散点构成的大字符喷码[13-14]。实际应用中,喷码字符点与点的距离有可能大于字符之间的间隙大小,导致图像闭运算后多个字符黏连无法被正确分割。如图3所示为连通域法字符分割结果,图中第二个字符P被错误分割,且由于字符D8和00字符存在黏连,导致无法对其进行正确分割。

图3 连通域法字符分割
本文提出了一种改进连通域的动态字符分割算法,可实现字符分割。其动态分割伪代码可表示为:
Input:待处理图像(src)。
Output:文件夹下的单个字符图像。
{
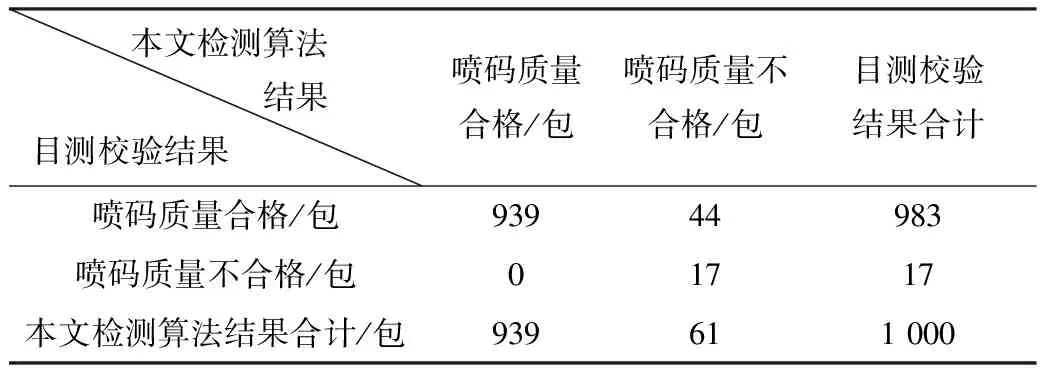
for(intj=0;j for(inti=0;i {统计每一列的黑像素点个数} if(相邻区域黑色像素点不连续0){ else{标记最左和最右列为疑似分割位置}} 计算每个疑似分割位置间隙,求取间隙众数和字符宽众数。 for(inti=0;i<字符个数;i++){ if(字符宽和字符宽众数相差较小) {分割位置正确,切割字符} else{ if(字符宽约为字符宽众数的倍数且相邻间隙与众数相近) {按众数计算倍数位置,搜索前后1/4,1/2众数区域,求最少黑色像素点位置并进行分割} if(字符宽小于字符宽众数且相邻间隙较小) {将当前字符与下个字符合并进行分割} }} } 改进连通域字符分割算法对字符定位区域重新进行字符分割的结果如图4所示。算法能够有效处理误分割字符及字符因黏连造成的漏分割,并可根据每个分割字符的最小包围矩形裁剪单个字符图像。 图4 改进连通域法字符分割 Tesseract是一款由HP实验室研发并由Google优化、维护的 OCR 引擎,可将各种格式的图像转化成超过60种语言(包括中文)的文本,并且支持用户不断训练字库,以提高字符识别准确率,是目前应用较为广泛的OCR引擎之一[15-17]。 Tesseract-OCR引擎自带的字库对特定的字符识别率不高,因此需对图像字符分割后的单个喷码字符进行训练,生成训练数据,从而提高单个字符识别准确率,其具体步骤如下: 步骤1选取tif格式的图片作为样本。将前期图像分割后的同一个字符或数字的单个字符图片合并成一张tif图片。为提升训练效果,确保选取样本图像是每个字符或数字,并保证至少有50个样本; 步骤2生成并调整BOX文件。通过Tesseract的makebox命令定位并识别字符,生成BOX文件。再通过jTessBoxEditor工具矫正识别出来的字符,并调整Box文件; 步骤3生成、合并训练文件。根据BOX文件和tif图片进行特征提取和字库训练,进而生成字符集文件,再通过聚类字符特征及合并训练文件来生成traineddataz格式的训练文件。 以图5和图6的实验为例,Tesseract-OCR引擎原始数据集将输入图像识别为“Ppit-TO35(L5E89)20201010D8007-806953”,其中4个字符识别错误,正确率为88.57%。使用训练数据集进行识别时,识别结果为“PPH-T035(L5E89)20201010D8007-B06953”,所有字符均识别正确。由实验可知,训练数据集的识别效果优于引擎原始的数据集。 图5 原始数据集字符识别结果 图6 训练数据集识别结果 本文实验选用CPU主频2.0 GHz,内存8 GB的PC机,以海康威视(HIKVISION)型号为MV-CE100-30GC的彩色 CMOS 千兆以太网工业相机和焦距为8~50 mm,光圈范围为F1.4-C的中联科创VM08050MP3镜头作为实验平台。本文实验对象选用经喷码机喷印信息的包装袋侧面,需检测的区域为800 mm×150 mm。考虑到检测范围较大、检测目标表面凹凸不平、包装侧面为圆弧形等特点,故选用两个140 mm×20 mm的条形白色光源组合,照明方式为前景光直接照明。 为验证算法的有效性,在聚丙乙烯生产车间,搭建化工包装袋喷印信息的质量检测测试平台。将喷码机的一组派码信息与图像识别字符进行逐一比对,若派码信息与识别字符完全一致,则判定喷码质量合格;若一个字符不一致,则判定喷码质量不合格,并以正确判定喷码质量是否合格的样本占总样本的比例作为评价指标。在生产线中使用该实验平台对1 000包聚丙乙烯包装袋的喷码质量进行检测。本文提出的检测算法与目测校验结果的对比如表1所示。 表1 结果对比 由表1可以看出,本文提出的检测算法对喷码质量合格的44件产品进行了错误判断,故喷码质量检测算法的精确度为 95.6%。被错误判断的44件产品中包装袋的喷码部分大部分存在比较明显的皱褶,字符畸变较为严重,因此导致字符识别率降低。 本文运用均值滤波与高斯双边滤波算法对采集图像进行预处理,并通过局部统计的可变阈值算法获取字符区域。针对喷码字符点与点的距离有可能大于字符之间的间隙大小,导致二值图像闭运算后多个字符黏连形成连通域的现象,本文提出了一种改进连通域的动态字符分割算法。最后,将分割的字符图像通过Tesseract_OCR引擎进行分类训练和识别。实验结果表明,该算法对喷码质量检测的实时性和准确性较高,能够满足化工包装袋喷码质量检测的要求。本研究的不足之处在于数据训练的数据不够,泛化能力不够。此外,由于化工包装袋存在褶皱,字符畸变较为严重,会降低本文提出的算法的精确度。因此,在之后的实验中将进一步扩大训练数据,并考虑加入卷积神经网络来提高算法的精确度。
4 基于Tesseract_OCR引擎的字符识别与训练


5 实验结果与分析
6 结束语
